JS逆向 |
您所在的位置:网站首页 › 爬取爱奇艺vip视频 › JS逆向 |
JS逆向
|
仅限技术交流和学习记录,严禁用于任何商业用途,否则后果自负,侵删 个人觉得坑还挺多,但难度不算大的一篇js逆向。 来吧,先分析。 起初解析pc网页端,感觉有点难度,然后就转到移动网页端了,其实是一模一样的,除了接口和接口非加密参数不一样。所以没啥区别,这里就还是按照移动网页端来解析。 1,第一步,打开网页找接口。
我们在上图已经找到了目标接口和视频真实链接,这是个m3u8链接,图里截取了部分。 2,对接口参数做解析。
可以看到,对该接口发起了post请求,我们接着看参数:
好了,我们的目标很明确了,就是上图的sign。 第三步,我们开始搜。ctrl+shift+f 开始全局搜索 搜什么?搜sign吗?我们试试:
有四个js文件里有sign呀,一个个去看吗?算了。 这里说一下,我一开始也是搜sign,但是不止一个接口用到sign,而且不同接口用到的sign的加密方式还不一样,所以这里不推荐大家搜sign。 这里推荐大家把接口截取一部分作为搜索目标 ,试一下:
只有一个,好的,我们进去看看:
打开js之后,格式化,我们继续搜接口的一部分参数,可以看到上图,芜湖,是不是要出来了? o好像就是请求的参数,那么o的生成方法也在上图注明了,我们打个断点调试:
刷新一下:
可以看到参数都出来了,o是走了一个方法,这个方法需要传入几个参数: a 20149570 暂时不知道是啥,这个其实是每个视频有个不一样的point_id,在网页源码可以搜到,就不多赘述了,详见下面代码 n n就是我们前面post请求需要的参数did i 时间戳很明显了 我们往下调试一下,就可以看到
我们看看o的加密:window.ub98484234 我们在控制台打印一下,回车看看
它指向了一个方法,我们点进去看看:
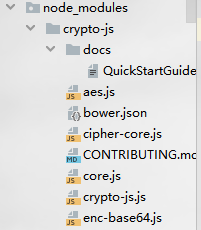
理论上,我们把这个方法复制下来,做个js文件,每次传入参数执行这个js文件,就可以拿到参数了,我也确实这样坐了,但是后续在测试时,发现只能解析这一个视频,换个链接,就无法解析了,也就是说,这个js,不具备通用性。这是一个大坑,我在这里卡了半天。 其实,这段js的位置,是在页面源码里,因此,每个链接的js都是不一样的,所以js才不能写死,不具备通用性,搞懂了这点,我们可以把这块js匹配出来,执行,就可以了,上代码吧。 import datetime import re import time import execjs import requests phone_headers = { 'user-agent': 'Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Mobile Safari/537.36', } # 对页面发起请求,请求失败次数为3 def get_resp(url): """ :param url: 接受一个链接 :return: 返回该链接页面的源码 """ times = 3 content = '' while times: try: resp = requests.get(url, headers=phone_headers) content = resp.text # 正常获取页面 跳出循环 if resp.status_code == 200 and len(content) > 1000: break # 未正常返回页面,次数减一 else: times -= 1 # 异常时次数减一 except: times -= 1 return content # 解析页面及参数,获取接口需要的所有参数 def get_by_api(content): """ :param content: 接受一个页面的源码内容 :return: 返回解析结果 """ # pc网页端的接口和参数不同,但使用的加密是相同的,该方法解析移动端网页版 # 每个视频的js代码使用同一套算法,但略有不同,无法整理出一个统一的js文件 # 从源码获取到js # 如果页面没有正常返回数据,则无法解析,直接return if not content: return False try: js_info = re.search("(var vdwdae325w_64we.*?return eval.*?)", content, re.S).group(1).strip() except: js_info = '' # # js无法执行,报错 execjs._exceptions.ProgramError: ReferenceError: CryptoJS is not defined # 原因是在原文js中,执行了md5,但该代码并不在js中,加入以下代码,并将crypto-js下载后,复制到node_modules文件夹下 js = """ const CryptoJS = require('crypto-js'); """ # js获取完毕 js = js + js_info try: vid = re.search('"vid":"(.*?)"', content).group(1).strip() except: vid = '' try: point_id = re.search('"point_id":(\d+)', content).group(1).strip() except: point_id = '' # 三个缺一不可,缺失任何一个,则无法解析,直接return if not vid or not point_id or not js_info: return False # 参数 a:point_id, tt:时间戳, did:定值, v:2203+当前日期(年月日), vid:视频id a = point_id tt = str(int(time.time())) did = 'AND-CHR|91-726049481625560928531' now_date = str(datetime.datetime.now()).split(' ')[0].replace('-', '') v = "2203" + now_date # 执行时指定一下crypto-js的路径 ctx = execjs.compile(js, cwd=r"node_modules") sign = ctx.call('ub98484234', a, did, tt) # 匹配到sign sign = re.search('sign=(.*)', sign).group(1).strip() url = 'https://vmobile.域名.com/video/getInfo?vid=%s' % vid data = { 'v': v, 'did': did, 'tt': tt, 'sign': sign, 'vid': vid, } resp = requests.post(url, data=data, headers=phone_headers) try: real_url = resp.json()['data']['video_url'] except: real_url = '' return real_url # 主方法,开始解析 def parse(): url = 'https://v.域名.com/show/worZv0kgndlWJBk3' content = get_resp(url) real_url = get_by_api(content) if real_url: print(real_url) if __name__ == '__main__': parse()在代码的注释里写的很清楚了 值得注意的是一个报错: execjs._exceptions.ProgramError: ReferenceError: CryptoJS is not defined这也是一个很大的坑,所以在源码匹配到js后,需要做一定的处理,放在代码里了,就不在赘述。 还需要下载 crypto-js 的源码文件,放在 node_modules 文件夹下,跟py脚本同级,否则就写绝对路径好了。 结构如下
node_modules和脚本是同级的。 结束,一一,芜湖 |


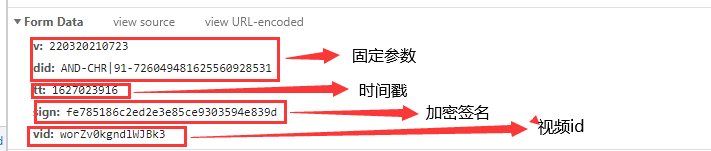




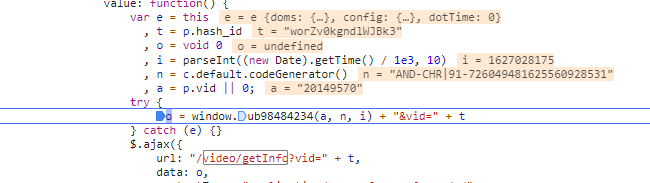
 o就出来了,这个o里,就有我们需要的sign
o就出来了,这个o里,就有我们需要的sign

【本文地址】