小白笔记:对MLP多层感知机概念、结构、超参数的理解 |
您所在的位置:网站首页 › 爆米花机的结构图 › 小白笔记:对MLP多层感知机概念、结构、超参数的理解 |
小白笔记:对MLP多层感知机概念、结构、超参数的理解
|
目录 概述 1.多层感知机的概念与基本组成 1.1 感知机、多层感知机的概念 1.2 多层感知机的结构 1.2.1 多层感知机的层次 1.2.2 Dense Layer(全连接层) 2. 如何由线性结构变为多为多层感知机 3.MLP中的一些超参数 3.1 隐藏层的数量 3.2 隐藏层的输出大小(节点数) 3.3 其他超参数 3.4 更新节点权重 4. 思考 概述在深度学习领域,针对最开始的线性模型,分类任务的发展可以理解为:从手工提取特征(即利用人的知识对原始特征进行特征提取)——到利用神经网络来自动提取特征。下图展示了这一发展变化:
事实上,对于机器而言,神经网络(可能更懂机器学习)来提取可能对后面的线性或softmax回归可能会更好一些。因为不需要人的思维干预,直接把原始数据给机器,让机器用神经网络自动提取它“喜欢”的数据,但“世界上没有免费的午餐”,如果利用神经网络来提取特征的话,计算量和数量都会比手工提取要大很多数量级(是上千上万倍的增加数据)。但是我们可以使用不同的神经网络的架构(Neural Networks)来克服数据量大的弊端,更有效地提取特征: (1)多层感知机(MLP/ANN) (2)卷积神经网络(CNN) (3)循环神经网络(RNN) (4)Transformers(新兴起) 这里就出现了我们要了解的多层感知机(MLP),那么如何从之前的线性方法到多层感知机呢?现在我们一起回顾一下多层感知机的概念与结构吧! 1.多层感知机的概念与基本组成 1.1 感知机、多层感知机的概念(1)感知机(PLA,Perceptron Learning Algorithm):只有输入和输出层,这两层共同组成了一个简单的神经元,即单个神经元模型,是较大神经网络的前身。它是一个线性的二分类器,但它对非线性的数据并不能进行有效的分类。因此我们可以加深这个神经元的网络层次,理论上来说,多层网络可以模拟任何复杂的函数。以下是感知机的概念公式:
(2)多层感知机(MLP,Multi-Layer Perceptron):由感知机推广而来,它最主要的特点就是有多个神经元层,因此 MLP 也被称为人工神经网络(Artificial Neural Network,ANN)。MLP 是一种特定类型的人工神经网络,它由多个神经元组成,通常包括一个输入层、一个或多个隐藏层以及一个输出层。相对而言,ANN 是一个更广泛的术语,它包括了所有由神经元组成的网络,而 MLP 则是 ANN 中的一个特例,指代具有多个层的前馈神经网络。所以在讨论上,MLP 和 ANN 可以互换使用。 1.2 多层感知机的结构神经网络的预测能力来自网络的分层或多层结构,所以神经网络的层次结构很重要。 1.2.1 多层感知机的层次多层感知机是指具有至少三层节点:(1)输入层(接收数据),(2)一些中间层(一个或多个隐藏层,计算数据),(3)输出层(输出结果)的神经网络。(MLP并没有限定隐层的数量,对于输出层神经元的个数也没有限制,所以我们可以根据各自的需求选择合适的隐层层数。)那么感知机与多层感知机的结构是什么样的呢?(左图为感知机,右图为多层感知机)
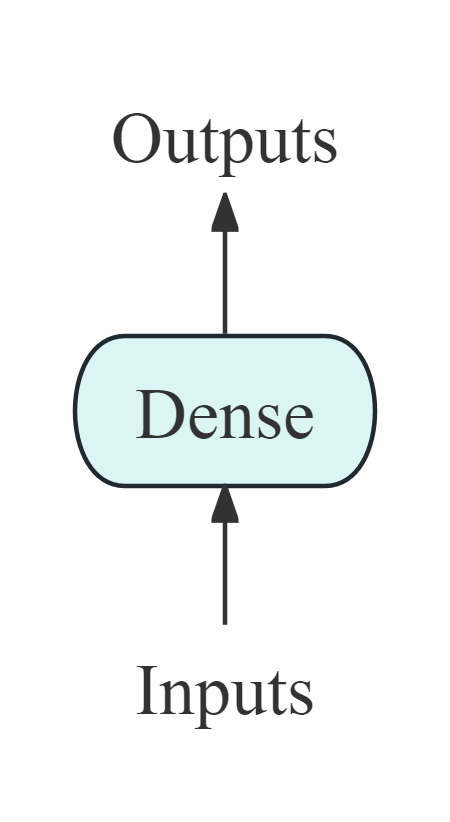
从结构图中我们可以看出,多层感知机这三类给定层(输入、中间、输出层)中的每个节点都会连接到相邻层中的每个节点(全连接),所以这里有一个MLP中最重要的一个组成就是Dense Layer(全连接层、线性层、稠密层,在本文中我称之为全连接层),它在MLP中发挥的是什么样的作用呢? 1.2.2 Dense Layer(全连接层)全连接层中有一个可以学习的参数 w(mxn,n:输入特征的维度,m:输出的向量的长度),还有一个参数 b(偏置,长为m),所以在这一层我们会对输入的数据 x 进行下面的公式计算,得到输出 y。(y也是一个长为m的向量) 那么之前我们所了解到的线性回归,本质上就可以认为是一个全连接层,但是只有一个输出,即m=1,在神经网络中,我们通常将线性结构表示为下图:(事实上,我认为这就是一个单层的感知机PLA,注意将这幅图与下面的MLP进行对比,你可以发现到底哪些是隐藏层)
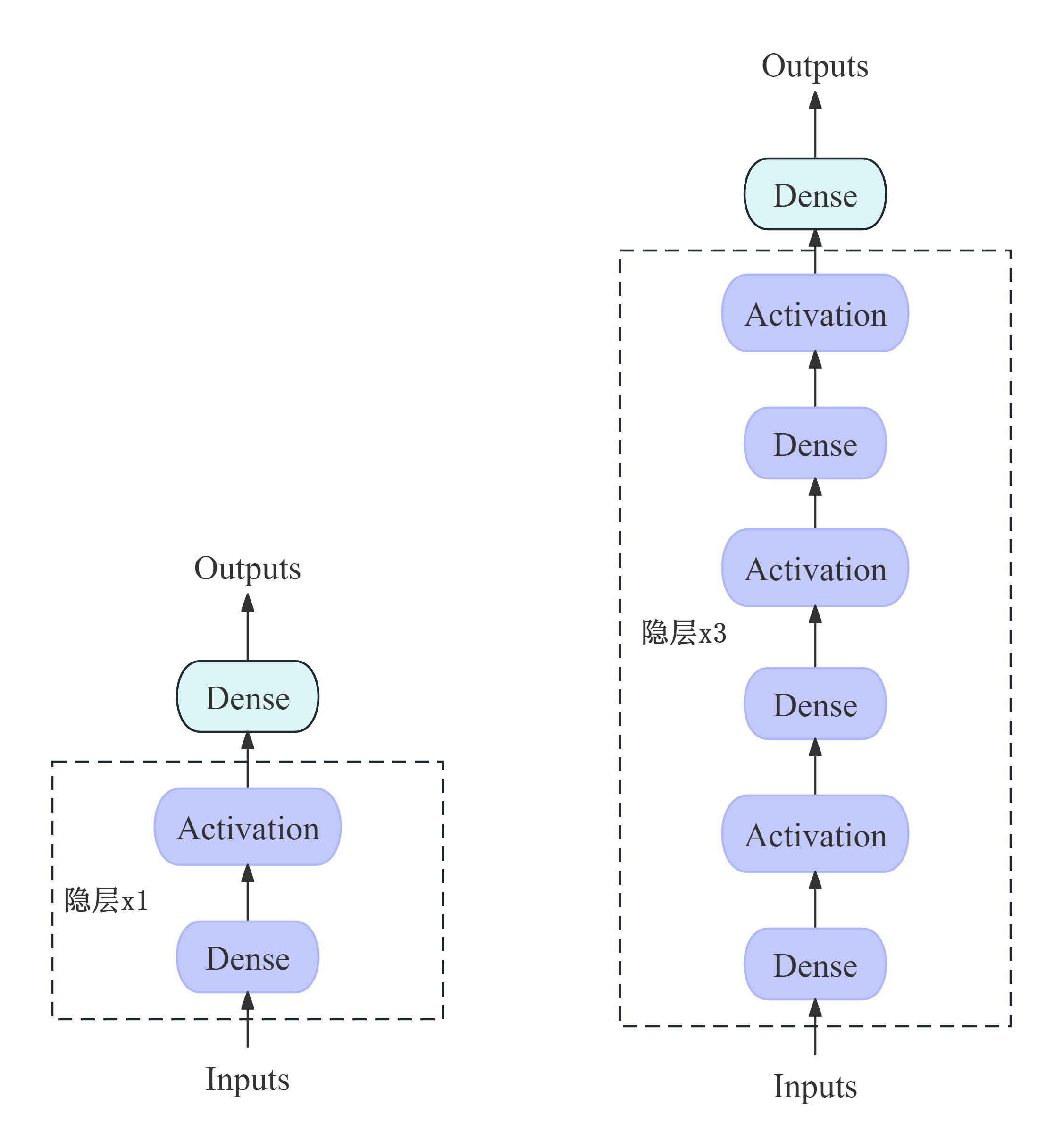
我们了解了线性回归,知道了多层感知机有三个层次,那么如何将线性结构变为多层的感知机呢?——重点就是:全连接(Dense) + 激活函数(引入非线性)。 因为想做到非线性,那我们可以尝试使用多个全连接层,但是将全连接层简单的叠加在一起还是线性的,所以要加入非线性的东西在里面,也就是激活函数(比如sigmoid、Relu等),才能实现我们想要的非线性(去拟合各种各样的函数,更具现实意义)。以下是具有一层隐藏层的MLP(左)和具有三层隐藏层的MLP(右)结构示图:
神经网络的强大之处在于它们能够学习训练数据中的表示,以及如何将其与想要预测的输出变量联系起来。从数学上讲,它们能够学习任何映射函数,并且已经被证明是一种通用的近似算法。 3.MLP中的一些超参数在隐藏层中有一些超参数:需要选用多少个隐藏层?隐藏层的输出大小为多少? 3.1 隐藏层的数量隐藏层的数量:确定模型中隐藏层的数量。通常情况下,隐藏层的数量是一个可以调整的超参数。较深的模型可能会提供更多的表示能力,但也会增加训练和计算成本。 在理论上,增加隐藏层的数量可以增加模型的表示能力,使得 MLP 能够逼近任意复杂的非线性函数。因此,增加隐藏层的数量可能会增加模型对非线性问题的适应能力。 然而,在实际应用中,隐藏层数量增加并不总是会带来更好的效果,因为隐藏层数量的增加也会增加模型的复杂度,从而增加了模型的训练时间、计算成本和过拟合的风险。此外,增加隐藏层的数量也会增加超参数搜索的复杂度。 一般来说,对于大部分非线性问题,一个包含有几个隐藏层的 MLP (比如我们上述真是的三个隐藏层的MLP)应该能够取得不错的效果。但是,并没有一个固定的规则来确定隐藏层的数量,因为最佳的隐藏层数量取决于具体的数据集、问题的复杂度和其他超参数的选择。因此,在实践中,可能需要通过交叉验证等方法来确定最佳的隐藏层数量。 3.2 隐藏层的输出大小(节点数)MLP 中隐藏层的输出大小(或者说是隐藏层的神经元数量)是由节点数决定的。隐藏层的每个神经元都会产生一个输出,因此隐藏层的输出大小等于隐藏层中神经元的数量。 在 MLP 中,隐藏层的每个神经元都会接收上一层的输出,并对其进行加权求和并通过激活函数进行处理,从而产生隐藏层的输出。这些隐藏层的输出再传递给下一层,直到到达输出层为止。 因此,隐藏层的输出大小是一个重要的超参数,它直接影响着模型的表示能力和学习能力。通常情况下,隐藏层的输出大小是可以调整的,可以根据任务的复杂度和数据集的特征来确定。较大的隐藏层输出大小可能会增加模型的表示能力,但也会增加过拟合的风险。较小的隐藏层输出大小可能会减少模型的参数数量,从而降低模型的复杂度,但也可能会限制模型的表达能力。因此,选择合适的隐藏层输出大小是一项具有挑战性的任务,需要在实践中进行多次实验和调整。 3.3 其他超参数除了上述两个超参数之外,还有激活函数、学习率等超参数: (1)激活函数:确定每个神经元的激活函数。常用的激活函数包括 Sigmoid、ReLU、Tanh 等。不同的激活函数对模型的学习能力和训练速度都会产生影响。(关于它们的图像、优缺点等都是很关键的知识点,后续再慢慢掌握) (2)学习率:确定模型在训练过程中参数更新的步长。学习率过大可能导致不稳定的训练过程,学习率过小可能导致训练速度过慢。 (3)正则化参数:用于控制模型的复杂度,包括 L1 正则化和 L2 正则化等。正则化参数的选择可以影响模型的泛化能力。 (4)批大小(Batch Size):确定每次输入模型的样本数量。批大小的选择会影响模型训练的稳定性和收敛速度。 (5)优化器:确定用于更新模型参数的优化算法,如随机梯度下降(SGD)、Adam、RMSProp 等。 而确定这些超参数的方法通常包括: (1)经验调整:根据经验和直觉来调整超参数。这种方法可能需要多次尝试和调整,但在某些情况下可以得到不错的结果。 (2)网格搜索(Grid Search):通过指定超参数的一组候选值,对所有可能的超参数组合进行搜索,以找到最优的超参数组合。这种方法适用于超参数空间较小的情况。 (3)随机搜索(Random Search):与网格搜索类似,但是在超参数空间中随机采样一组候选值,以减少搜索的计算量。这种方法在超参数空间较大时更有效。 (4)自动调参算法:利用机器学习算法自动优化超参数,如贝叶斯优化、遗传算法等。这些方法可以在较大的超参数空间中高效地搜索,并且通常能够找到较好的超参数组合。 综合考虑模型的复杂度、数据集的特点以及计算资源等因素,选择合适的超参数组合是一项具有挑战性的任务。通常需要在实践中进行多次实验和调整,以找到最优的超参数组合。 3.4 更新节点权重MLP(多层感知机)是通过反向传播算法(Backpropagation)来调节节点权重的。反向传播算法是一种基于梯度下降的优化算法,它通过计算损失函数对模型参数(即节点权重)的梯度,然后沿着梯度的方向更新参数,从而使得模型在训练数据上的预测误差最小化。具体来说,反向传播算法的步骤如下: (1)前向传播(Forward Propagation):首先,通过前向传播计算模型的输出。从输入层开始,逐层计算每个隐藏层和输出层的输出,直到得到模型的预测结果。 (2)计算损失(Compute Loss):然后,计算模型在训练数据上的损失,通常使用某种损失函数来度量模型的预测值与真实值之间的差异。常见的损失函数包括均方误差(MSE)、交叉熵损失等。 (3)反向传播误差(Backward Propagation of Error):接下来,利用反向传播算法计算损失函数对模型参数的梯度。具体地,从输出层开始,逐层计算每个参数的梯度,然后将梯度沿着网络反向传播,直到计算出输入层的参数梯度。 (4)更新参数(Update Parameters):最后,根据计算得到的梯度,使用梯度下降或其他优化算法来更新模型的参数(即节点权重)。通常情况下,参数更新的步长由学习率控制,学习率越大,参数更新的幅度就越大,学习速度也越快;但是如果学习率过大,可能会导致优化过程不稳定,甚至发散。 重复以上步骤,直到达到停止条件为止,例如达到预定的迭代次数或损失函数的收敛阈值。 总之,MLP 是通过不断地计算损失函数对模型参数的梯度,并利用梯度下降算法来更新参数,从而不断调节节点权重,使得模型在训练数据上的预测效果不断提升。 4. 思考最后一个小问题:看完这篇文章,想必小伙伴对多层感知机的结构已经有了一定的了解,但是或许还会有一个疑问:输入层不会有激活函数,隐藏层肯定有激活函数,那么输出层到底有没有激活函数呢?事实上,MLP 的输出层是否使用激活函数取决于具体的任务和模型设计。在一些情况下,输出层会应用激活函数,而在其他情况下则不会。 (1)分类任务:对于分类任务,输出层通常会应用激活函数,以确保输出的值位于某个特定的范围内,以便表示类别的概率分布。常见的分类任务的激活函数包括 Softmax 函数,它可以将输出转换为表示各个类别概率的向量。 (2)回归任务:对于回归任务,输出层通常不会应用激活函数,因为我们希望模型的输出可以直接表示预测的值。在这种情况下,输出层通常只是一个线性层,输出的值没有经过激活函数的转换。 (3)其他任务:对于其他类型的任务,如生成对抗网络(GAN)、强化学习等,输出层的激活函数的选择也可能会有所不同,具体取决于任务的要求和模型的设计。 综上所述,MLP 的输出层是否有激活函数取决于具体的任务和模型设计。在分类任务中,常见的输出层激活函数是 Softmax 函数;而在回归任务中,输出层通常不会应用激活函数。 在最最后,特别声明,作为一名纯小白,渴望学习新知识,文章中可能出现理解不当的地方,若有所见解或异议可在下方评论,谢谢!!!一起进步吧!
|

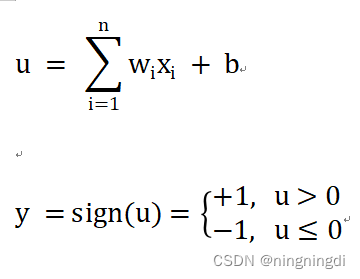


【本文地址】
今日新闻 |
推荐新闻 |