【精选】这个假发太逼真!GAN帮你换发型,毫无违和感! |
您所在的位置:网站首页 › 照片换服装发型软件 › 【精选】这个假发太逼真!GAN帮你换发型,毫无违和感! |
【精选】这个假发太逼真!GAN帮你换发型,毫无违和感!
|
理发总是差强人意? 醒醒吧!有些发型不适合你!
如果能在理发前,把这几个发型「试用」就好了。
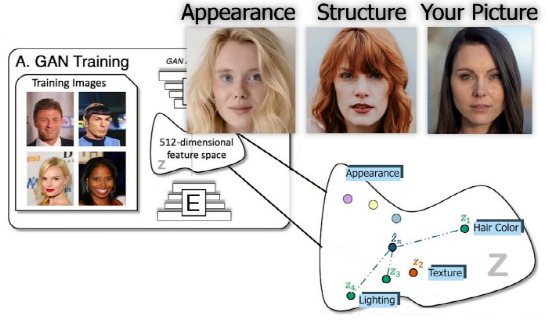
Tony老师无法给你的,GAN给你。 最近,一个基于GAN的项目Barbershop火了!它不仅可以改变你的头发风格,还可以从多个图像实例中改变颜色。
重要的是,不同于一般的换头发AI,这次的效果让你的脸与新头发完美融合。 一头逼真的「假发」:发型、颜色任你选 把这三样东西交给算法,你就能看到自己的发型合不合适。 1 自己的照片; 2 一张你想拥有的发型的人的照片; 3 另一张你想尝试的头发颜色的照片(或同一张) 例如,我的原生发型是这样的:
来试验一下别样的发型:
换个直发试试?
颜色太显老?换一个试试!
怎么样是不是新发型与您的头完美融合?再也没有生硬感? 为了确定这个项目符合大众审美,作者还对396名参与者进行了用户研究。答案是:GAN给出的解决方案在95%的情况下都是他们首选的!
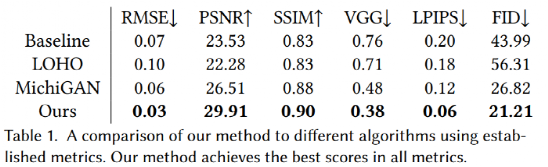
量化结果 这是如何做到的? 去掉生硬感!在GAN中加入对齐(alignment)步骤 GAN架构可以学习将一个图像的特定特征或风格移植到另一个图像上。虽然它并不是一项新技术了,但是关于它的应用一种充满新鲜劲儿。 但也有一些细节给GAN的应用带来挑战,譬如:光线的差异带来了遮挡,在两张照片中的头部可能会出现不同,会带来生硬感。
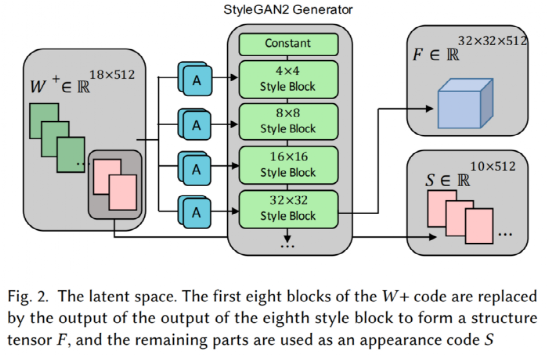
通常情况下,这些使用GANs的技术会试图对图片信息进行编码,并在此编码中明确识别与头发属性相关的区域来切换它们。但只有当两张照片的拍摄条件类似时,这种换头发的效果才会很好——不过,这很难。 因此,作者不得不想点办法。 首先,将换头发分为两个层级:结构(structure)和外观(appearance)。 结构是指头发的几何形状——卷曲的、波浪的还是直的。外观指的是深度编码的信息,包括头发颜色、纹理和照明。
这里的目标是将特定图片的发型和颜色移植到自己的图片上,同时按照图片的光照和属性改变结果,使其一次就能达到令人信服的真实效果,减少步骤和错误来源。
StyleGAN2架构 为了实现这一目标,作者在GANs中增加了一个缺失但必不可少的对齐(alignment)步骤。 事实上,它不是简单地对图像进行编码和合并,而是按照不同的分割掩码稍微改变编码,使两幅图像的潜伏代码更加相似。正如前面提到的,它们都可以编辑头发的结构和风格或外观。
我们知道,GANs使用卷积对信息进行编码。这意味着它使用卷积核来降低每一层的信息规模,并使其越来越小,从而迭代地去除空间细节,同时对所产生的输出的一般信息给予越来越多的价值。 这些信息是从不同的图像中提取的,但现在,如何合并这些信息,才使结果看起来逼真些呢?
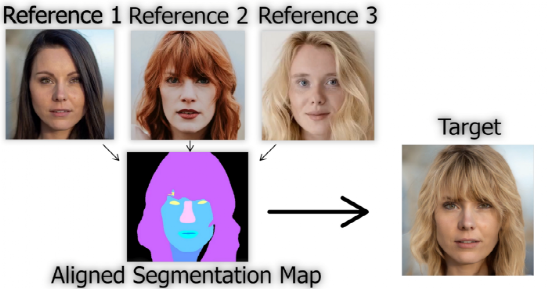
流程示意图 这是用图像的分割图完成的。更准确地说,是在我们的目标和参考图像的对齐版本的基础上,生成这个想要的新图像。参考图像是我们自己的图像,而目标图像是我们想要应用的发型。这些分割图告诉我们图像包含什么以及它在哪里,头发、皮肤、眼睛、鼻子等。
分割图 利用这些来自不同图像的信息,他们可以在将图像发送到网络进行编码之前,使用基于StyleGAN2的改良架构,按照目标图像结构对齐。 然后,对于外观和光照问题,他们从目标图像和参考图像中找到这些外观编码的适当混合比例,用于相同的分割区域,使其看起来尽可能的真实。 对比一下就知道效果:左是没有对齐的结果,右是本文的方法。
是不是顺眼很多? 当然,这个过程有点复杂,具体细节都可以在论文中找到。 但请注意,就像大多数GANs的实现一样,他们的架构需要被训练。在这里,他们使用了一个在FFHQ数据集上训练的StyleGAN2基础的网络。然后,由于他们做了许多修改,正如刚才讨论的,他们用198对图像作为发型转移的例子,第二次训练他们修改后的StleGAN2网络,以优化模型外观混合比例和结构编码。
Fail examples. 具体细节参见: GitHub地址:https://github.com/ZPdesu/Barbershop 论文:https://arxiv.org/pdf/2106.01505.pdf 推荐阅读【重磅】斯坦福李飞飞《注意力与Transformer》总结,84页ppt开放下载! 只需两行代码,2080Ti 就能当 V100用,这个炼丹神器真牛! 20亿参数,大型视觉Transformer来了,刷新ImageNet Top1 Deepfake文字版横空出世:AI高仿你的笔迹只需1个词! 2021年,深度学习还有哪些未饱和、有潜力且处于上升期的研究方向? 最强通道注意力来啦!金字塔分割注意力模块,即插即用,效果显著,已开源! 分层级联Transformer!苏黎世联邦提出TransCNN: 显著降低了计算/空间复杂度! 注意力可以使MLP完全替代CNN吗? 未来有哪些研究方向? 清华鲁继文团队提出DynamicViT:一种高效的动态稀疏化Token的ViT 并非所有图像都值16x16个词--- 清华&华为提出一种自适应序列长度的动态ViT DLer-计算机视觉交流3群已成立! 大家好,这是DLer-计算机视觉微信交流3群!首先非常感谢大家的支持和鼓励,我们的计算机视觉交流群正在不断扩大人员规模!希望以后能提供更多的资源福利给到大家!欢迎各位Cver加入DLer-计算机视觉微信交流大家庭 。 本群旨在学习交流图像分类、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。希望能给大家提供一个更精准的研讨交流平台!!! 进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)
???? 长按识别添加,即可进群! |














【本文地址】
今日新闻 |
推荐新闻 |