灰色关联法 |
您所在的位置:网站首页 › 灰色关联度参考序列怎么设置的 › 灰色关联法 |
灰色关联法
|
目录 1.简介 2.算法详解 2.1 数据标准化 2.2 计算灰色相关系数 2.3 计算灰色关联度系数 3.实例分析 3.1 读取数据 3.2 数据标准化 3.3 绘制 x1,x4,x5,x6,x7 的折线图 3.4 计算灰色相关系数 完整代码 1.简介对于两个系统之间的因素,其随时间或不同对象而变化的关联性大小的量度,称为关联度。在系统发展过程中,若两个因素变化的趋势具有一致性,即同步变化程度较高,即可谓二者关联程度较高;反之,则较低。因此,灰色关联分析方法,是根据因素之间发展趋势的相似或相异程度,亦即“灰色关联度”,作为衡量因素间关联程度的一种方法。 灰色关联分析可以用于衡量因素相关程度的同时,也有论文将其用于综合评价,其原理思想和TOPSIS法是比较相似的。 2.算法详解 2.1 数据标准化因为每个指标的数量级不一样,需要把它们化到同一个范围内再比较。标准化的方法比较多,这里仅用最大最小值标准化方法。 设标准化后的数据矩阵元素为rij,由上可得指标正向化后数据矩阵元素为 (Xij)'
我们常见的灰色相关系数表达式如下:
Xo(k)为参考列,p为分辨系数。它的范围为(0~1),它的作用为控制区分度,它的值越小,区分度越大,它的值越大,区分度越小。 常常取0.5。乍一看这个公式还是有些难懂,接下来详细介绍一下它的原理。 2.3 计算灰色关联度系数 参考向量的选择例如研究x2指标与x1指标之间的灰色关联度。所以将x1列作为参考向量,即要研究与谁的关系,就将谁作为参考。设参考向量为Y1=x1,生成新的数据矩阵 X1=x2. 生成绝对值矩阵设生成的绝对值矩阵为A A=[X1-Y1],亦是A=[x2-x1] 设dmax为绝对值矩阵A的最大值,dmin为绝对值矩阵A的最小值。 计算灰色关联矩阵 设灰色关联矩阵为B
其中指标,x1:货物运输量;x2:港口货物吞吐量;x3:货物周转量;x4:GDP;x5:财政收入x6:城市居民人均可支配收入;x7:农村居民人均净收入。现研究x4-x7指标与x1指标之间的灰色关联度。数据表格如下: 年份x1x2x3x4x5x6x72007225782756949872567.7267.981.54291.1722008256982948450483131348.511.85461.25142009278963158951293858.2429.12.03691.02542010295403489455694417.7541.292.25891.1892011310583647857835158.1647.252.42761.42132012359803869560456150.1736.452.56781.53042013394834074662597002.88502.85461.7421 3.1 读取数据 #导入数据 data=pd.read_excel('D:\桌面\huiseguanlian.xlsx') print(data) #提取变量名 x1 -- x7 label_need=data.keys()[1:] print(label_need) #提取上面变量名下的数据 data1=data[label_need].values print(data1)返回:
返回:
返回:
从图中可以看出,这几个指标的趋势大致相同 3.4 计算灰色相关系数3.4.1 得到其他列和参考列相等的绝对值 # 得到其他列和参考列相等的绝对值 for i in range(3,7): data3[:,i]=np.abs(data3[:,i]-data3[:,0])3.4.2 得到绝对值矩阵的全局最大值和最小值 #得到绝对值矩阵的全局最大值和最小值 data4=data3[:,3:7] d_max=np.max(data4) d_min=np.min(data4)3.4.3 定义分辨系数 a=0.53.4.4 计算灰色关联矩阵 data4=(d_min+a*d_max)/(data4+a*d_max) xishu=np.mean(data4, axis=0) print(' x4,x5,x6,x7 与 x1之间的灰色关联度分别为:') print(xishu)返回:
|

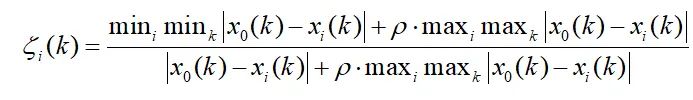
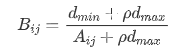
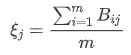




【本文地址】
今日新闻 |
推荐新闻 |