机器学习 |
您所在的位置:网站首页 › 激活函数具有哪些性质和作用 › 机器学习 |
机器学习
|
1 引言
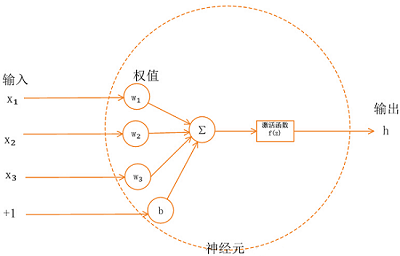
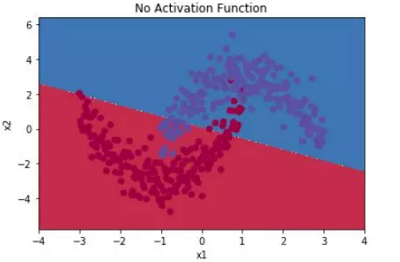
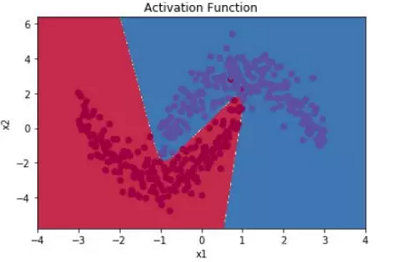
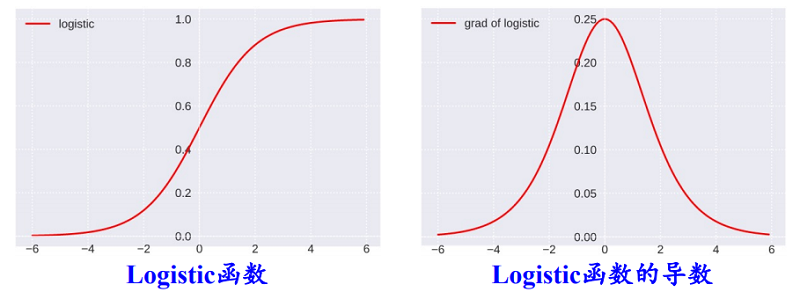
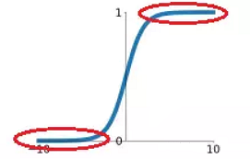
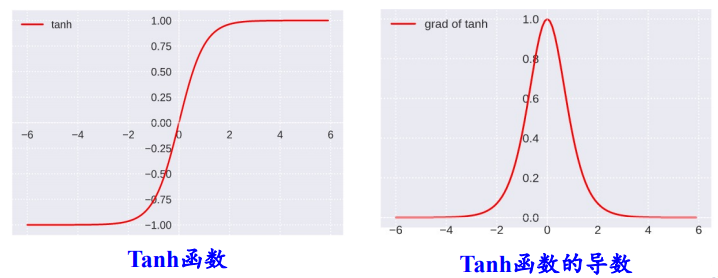
学习神经网络的时候总是听到激活函数这个词,常用的激活函数,比如Sigmoid函数、tanh函数、Relu函数。学习激活函数之前,先问几个问题: 什么是激活函数? 为什么需要激活函数? 有哪些激活函数,都有什么性质和特点? 应用中如何选择合适的激活函数? 2 什么是激活函数?首先要了解神经网络的基本模型: 神经网络中的每个神经元节点接受上一层神经元的输出值作为本神经元的输入值,并将输入值传递给下一层,输入层神经元节点会将输入属性值直接传递给下一层(隐层或输出层)。在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数(又称激励函数)。 3 为什么需要激活函数?如果不用激励函数(其实相当于激励函数是 $f(x) = x$ ),在这种情况下每一层节点的输入都是上层输出的线性函数,无论神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)。正因为上面的原因,引入非线性函数作为激励函数,这样深层神经网络表达能力就更加强大,不再是输入的线性组合,而是几乎可以逼近任意函数。 举个简单的例子,二分类问题,如果不使用激活函数,例如使用简单的逻辑回归,只能作简单的线性划分,如下图所示: 如果使用激活函数,则可以实现非线性划分,如下图所示: 为什么激活函数一般都是非线性的,而不能是线性的呢? 从反面来说,如果所有激活函数都是线性的,则激活函数 $g(z)=z$,即 $a=z$。那么,以两层神经网络为例,最终的输出为: $\begin{aligned} A^{[2]} &=Z^{[2]} \\ &=W^{[2]} A^{[1]}+b^{[2]} \\ &=W^{[2]}\left(W^{[1]} X+b^{[1]}\right)+b^{[2]} \\ &=\left(W^{[2]} W^{[1]}\right) X+\left(W^{[2]} b^{[1]}+b^{[2]}\right) \\ &=W^{\prime} X+b^{\prime} \end{aligned}$ 经过推导发现网络输出仍是 $X$ 的线性组合。这表明,使用神经网络与直接使用线性模型的效果没什么两样。即便是包含多层隐藏层的神经网络,如果使用线性函数作为激活函数,最终的输出仍然是线性模型,这样神经网络就没有任何作用。因此,隐藏层的激活函数必须要是非线性的。 如果所有的隐藏层全部使用线性激活函数,只有输出层使用非线性激活函数,那么整个神经网络的结构就类似于一个简单的逻辑回归模型,效果与单个神经元无异。另外,如果是拟合问题而不是分类问题,输出层的激活函数可以使用线性函数。 4 有哪些激活函数,性质和特点?连续并可导(允许少数点上不可导)的非线性函数.可导的激活函数可以直接利用数值优化的方法来学习网络参数。激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。 4.1 Logistic 函数函数Sigmoid 型函数是指一类 S 型曲线函数,为两端饱和函数.常用的 Sigmoid 型函数有 Logistic 函数和 Tanh 函数. Logistic 函数 是常用的非线性的激活函数,Sigmoid型函数指一类S型曲线函数,为两端饱和函数。它的数学形式如下: ${\large \sigma(x)=\frac{1}{1+e^{-x}}} $ 数学小知识 | 饱和 对于函数 $f(x)$ , 若 $x \rightarrow-\infty$ 时, 其导数 $f^{\prime}(x) \rightarrow 0 $, 则称其为左饱和. 若 $x \rightarrow+\infty$ 时, 其导数 $f^{\prime}(x) \rightarrow 0$ , 则称其为右饱和. 当同时满足左、右饱和时, 就称为两端饱和. Logistic 的几何图像如下: 优点 具有“挤压”功能:把一个实数域的输入“挤压”到 (0, 1).当输入值在 0 附近时,Logistic 型函数近似为线性函数;当输入值靠近两端 时,对输入进行抑制.输入越小,越接近于 0;输入越大,越接近于 1。这样的特点 也和生物神经元类似,对一些输入会产生兴奋(输出为 1),对另一些输入产生抑 制(输出为 0).和感知器使用的阶跃激活函数相比,Logistic 函数是连续可导的, 其数学性质更好. 输出可看作概率分布:在数学上, Logistic 激活函数为每个类输出提供独立的概率。 非零中心化的输出会使得其后一层神经元的输入发生偏置偏移(Bias Shift),并进一步使得梯度下降的收敛速度变慢。参考《神经网络:激活函数非0中心导致的问题》缺点1: Logistic 函数容易饱和,导致训练结果不佳。 饱和区如下图所示: 上图中红色椭圆标注的饱和区曲线平缓,梯度的值很小,近似为零。而且 Sigmoid 函数的饱和区范围很广,例如除了 $[-5,5]$,其余区域都近似饱和区。这种情况很容易造成梯度消失,梯度消失会增大神经网络训练难度,影响神经网络模型的性能。 缺点2: Sigmoid 函数输出是非零对称的,即输出恒大于零。这是不可取的,因为这会导致后一层的神经元将得到上一层输出的非 $0$ 均值的信号作为输入。 产生的一个结果就是: 输入 $x>0$ , $f=w^{T} x+b$ 这会产生什么影响呢?假如 Sigmoid 函数的输出为 $\sigma(\mathrm{Wx}+\mathrm{b})$,且满足 $00$。 若神经元的输入 $x>$0,则无论 $d\sigma$ 正负如何,总能得到 $d W$ 恒为正或者恒为负。也就是说参数矩阵 $W$ 的每个元素都会朝着同一个方向变化,同为正或同为负。这对于神经网络训练是不利的,所有的 $W$ 都朝着同一符号方向变化会减小训练速度,增加模型训练时间。 值得一提的是,针对 Logistic 函数的这一问题,神经元的输入 $x$ 常会做预处理,即将均值归一化到零值。这样也能有效避免 $d W$ 恒为正或者恒为负。 缺点3: 解析式中含有幂运算,机求解时相对来讲比较耗时。 4.2 tanh函数Tanh 函数也是一种 Sigmoid 型函数.其定义为 ${\large \tanh (x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}} $ Tanh 函数可以看作放大并平移的 Logistic 函数,其值域是 (−1, 1). $\tanh (x)=2 \sigma(2 x)-1$ tanh函数及其导数的几何图像如下图: 优点: 零中心化,可提升收敛速度。 缺点: 没有改变Sigmoid函数由饱和性引起的梯度消失问题。 4.3 Hard-Logistic函数Logistic 函数和 Tanh 函数都是 Sigmoid 型函数,具有饱和性,但是计算开销 较大.因为这两个函数都是在中间(0 附近)近似线性,两端饱和.因此,这两个函 数可以通过分段函数来近似。 Logistic函数和Tanh函数都是Sigmoid型函数,具有饱和性,但是计算开销较大。 Logistic函数在0附近的一阶泰勒展开为 $g_l(x){\approx}{\sigma}(0)+x*{\sigma}'(0) = 0.25x+0.5$ 这样Logistic函数可以用分段函数hard-logistic(x)来近似 $\begin{equation} hard-logistic(x)=\left \{ \begin{array}{ll} 1 & g_l(x) \ge 1 \\ g_l & 0 |
【本文地址】
今日新闻 |
推荐新闻 |