pytorch中Dataloader的制作 |
您所在的位置:网站首页 › 滴酒不沾的男人突然喝酒 › pytorch中Dataloader的制作 |
pytorch中Dataloader的制作
|
Dataloader是pytorch框架下所支持的数据集格式,一般使用基于pytorch的模型读取的数据都是dataLoader,有必要学习一下DataLoader的制作,以便于后续在模型中处理数据,毕竟相比于改源码,改数据要更简单一点。 通常情况下,训练数据都是被放在了一起,测试数据也被放在了一起,有一个单独的文件记录每种数据的标签。
编写一个函数负责读取标签,以获取训练集标签为例: def load_annotation(ann_file): data = {} with open(ann_file, 'r') as f: re = [content.strip().split(' ') for content in f.readlines()] for file_name, gt_label in re: data[file_name] = np.array(gt_label, dtype=np.int64) return data最终返回一个字典,字典的键是图片的名称,字典的值是图片的标签 如果已经知道图片的上级路径(root_dir),那就可以构建图片路径列表了。 数据增强部分数据需要进行数据增强,数据增强通常采用图片反转、修改对比度饱和度等操作、图片裁剪等方式,这里使用列表写了一个针对训练集和测试集的数据增强方法: from torchvision import transforms class FlowerData(Dataset): def __init__(self, ann_file, root_dir, transform): self.ann_file = ann_file # 路径 self.root_dir = root_dir # 图片路径 self.data_info = self.load_annotation(ann_file) self.img = [os.path.join(self.root_dir, img) for img in list(self.data_info.keys())] # 标签路径 self.label = [la for la in list(self.data_info.values())] # 数据增强 self.transfrom = transform def __len__(self): return len(self.img) # 重写item方法,定义获取数据, item是数据的随机序号 def __getitem__(self, item): img = Image.open(self.img[item]) lab = self.label[item] if self.transfrom: img = self.transfrom(img) else: img = torch.from_numpy(img) lab = torch.from_numpy(lab) return img, lab def load_annotation(self, ann_file): data = {} with open(ann_file, 'r') as f: re = [content.strip().split(' ') for content in f.readlines()] for file_name, gt_label in re: data[file_name] = np.array(gt_label, dtype=np.int64) return data 实例化DataLoader train_data = FlowerData('../flower_data/train.txt', '../flower_data/train_filelist', data_transforms['train']) val_data = FlowerData('../flower_data/val.txt', '../flower_data/val_filelist', data_transforms['valid']) train_loader = DataLoader(train_data, batch_size=64, shuffle=True) val_loader = DataLoader(val_data, batch_size=64, shuffle=True)在DataLoader()中需要加入定义Dataset的实例化对象、batch_size、shuffle 制作的DataLoader可以用于,模型训练,下面就是一个写的例子 def train(model, optimizer, crition, num_epochs, train_loader): since = time.time() model.to(device) for epoch in range(num_epochs): print('Epoch {}/{}'.format(epoch, num_epochs - 1)) print('-' * 10) running_loss = 0.0 model.train() for data, label in train_loader: data = data.to(device) label = label.to(device) optimizer.zero_grad() pred = model(data) loss = crition(pred, label) loss.backward() optimizer.step() running_loss += loss.item() * data.size(0) epoch_loss = running_loss / len(train_loader.dataset) time_elapsed = time.time() - since print('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60)) print('Epoch {}/{},loss:{:.4f}'.format(epoch, num_epochs - 1, epoch_loss)) print('-'*10)DataLoader中的路径和标签可以是列表,也可以是其他的,不过官方给出了示例是用列表做的,一般也都用列表。 |
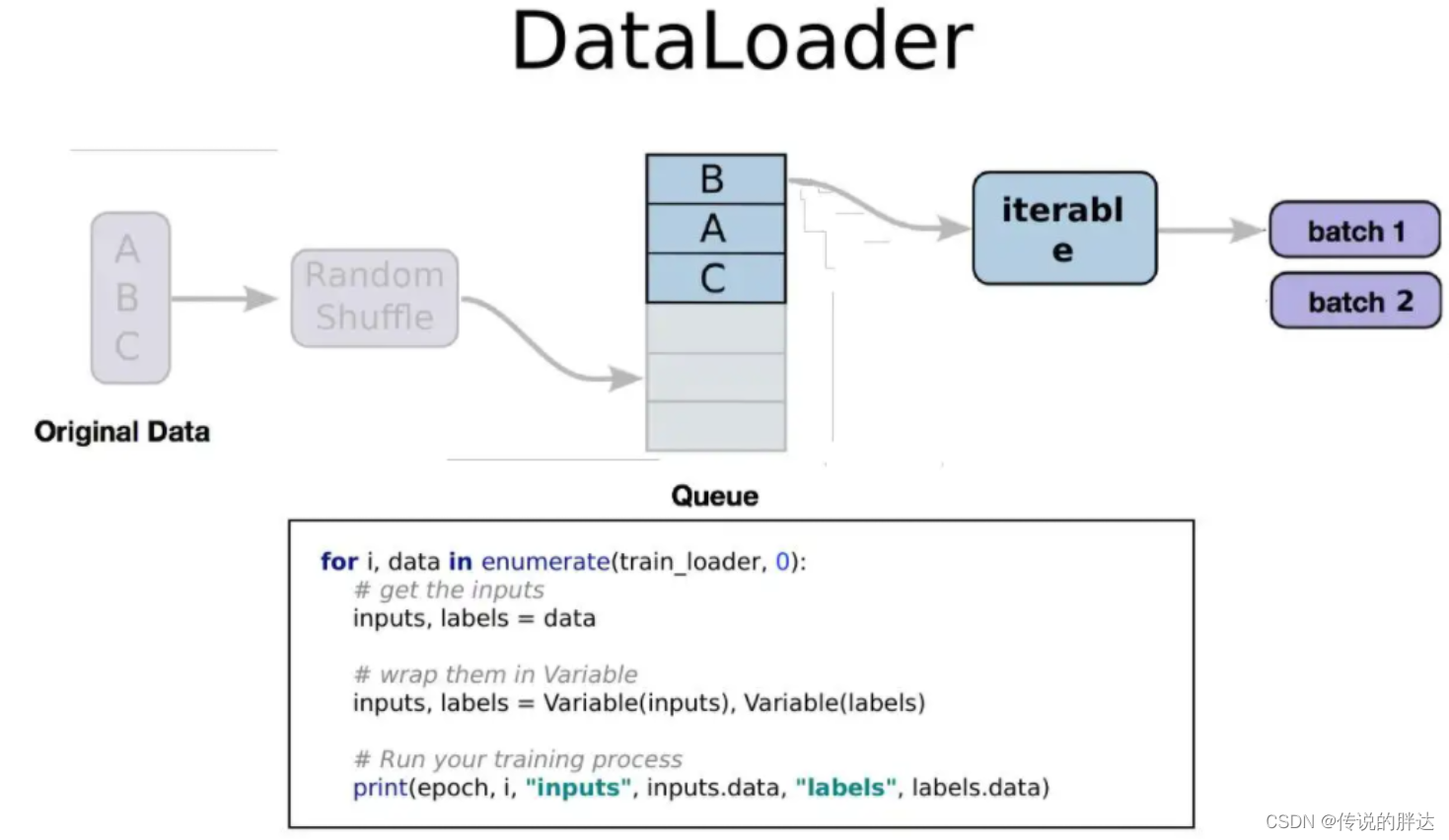 DataLoder的制作需要两个列表:第一个列表中存储所有图片数据的路径;第二个列表中存储所有标签,之后需要重写Dataset类。
DataLoder的制作需要两个列表:第一个列表中存储所有图片数据的路径;第二个列表中存储所有标签,之后需要重写Dataset类。【本文地址】
今日新闻 |
推荐新闻 |