Python 爬虫实战:某蜂窝网游记爬虫 |
您所在的位置:网站首页 › 游记的作者和简历 › Python 爬虫实战:某蜂窝网游记爬虫 |
Python 爬虫实战:某蜂窝网游记爬虫
|
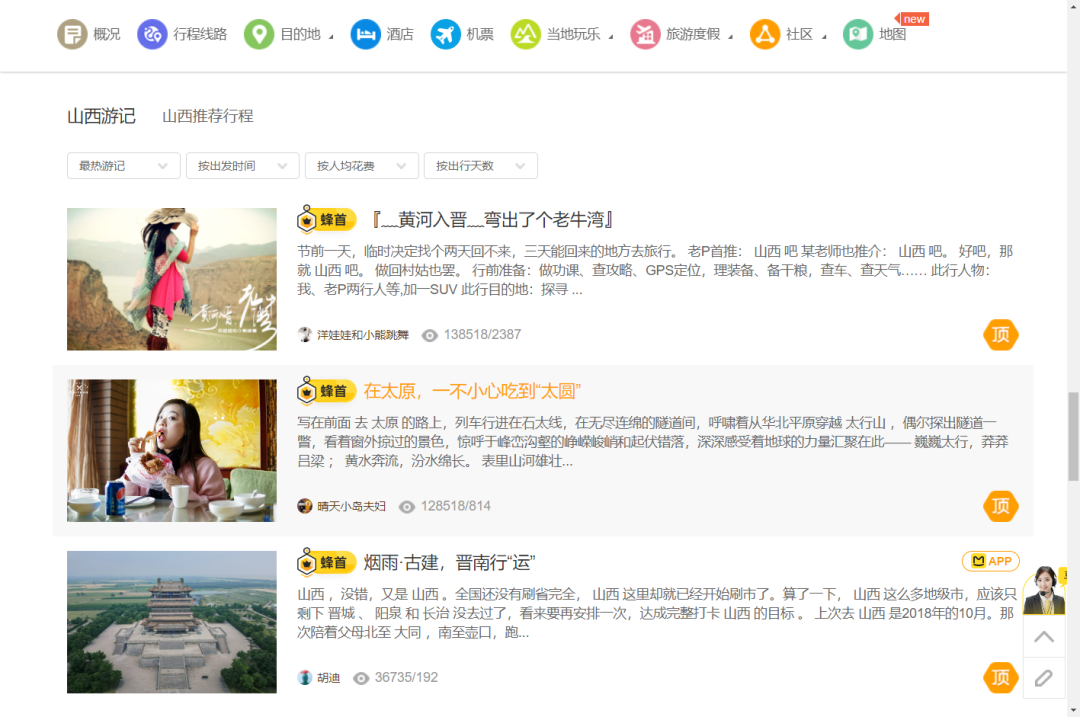
大家好,我是程序员晓晓。 今天给大家分享 某蜂窝网游记 的爬虫及爬取思路。 示例网址:aHR0cHMlM0EvL3d3dy5tYWZlbmd3by5jbi90cmF2ZWwtc2NlbmljLXNwb3QvbWFmZW5nd28vMTMwMzMuaHRtbA== 我们以 山西 为例。打开网址,页面向下翻,便可以看到 山西游记 区域。
写过爬虫的大家都知道,写爬虫第一步,需要观察目标网站。 具体观察哪些东西呢?主要有两个方面,目标数据 和 页面结构。 1.1观察目标数据这一步主要是为了确定,我们可以获取到哪些 数据项,以及大概的 数据量 。
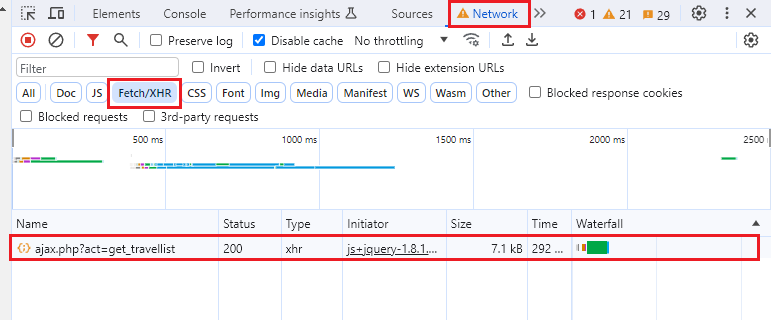
如图可以看到,从游记列表中,我们可以得到游记的 标题、题图、摘要、作者、浏览量、评论量 等数据。此外,通过分析源代码,我们还可以得到游记的 id 和 链接。 观察游记列表的翻页区,我们可以得知游记的 总页数 和 总条数 ,如山西游记有 3355 页,33544 条。 经过实际测试,无论是通过爬虫抓取,还是手动翻页,游记数据最多只能访问 100 页,1000条数据。 1.2观察页面结构观察页面结构,主要是为了确定两件事情: 翻页方式(瀑布流还是按钮翻页) 数据加载方式(动态还是静态) 因为不同的翻页方式和数据加载方式,会影响后续我们抓取数据、解析数据的方式。 简单观察网页以后不难发现, 列表底部有 翻页按钮 ,点击后可以跳转至对应页码。 翻页时,仅游记列表区域数据发生了更新(网页整体没有刷新),很明显是使用了 Ajax 动态加载 数据。 Part2抓包测试 2.1抓包知道网站是动态加载数据以后,我们直接开始抓包。 按F12键打开浏览器的 开发者工具,切换到 Network ,过滤器选择 Fetch/XHR。
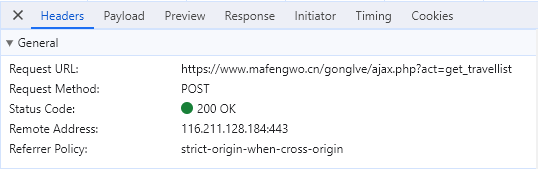
点击 翻页 按钮,抓到一条请求包,点击这条 ajax.php?act=get_travellist 请求包以后,可以看到它的详细情况。 在 Headers 中可以看到它的请求地址 Request URL 和请求方法 Request Method 。
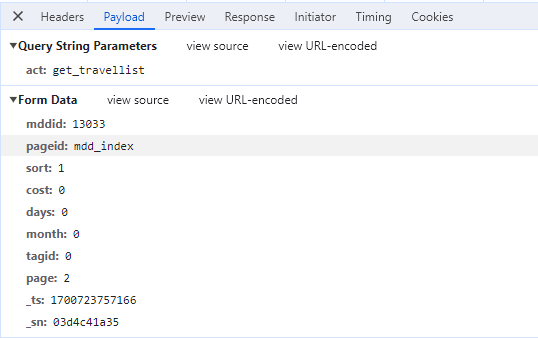
在 Payload 中可以看到它的请求参数。
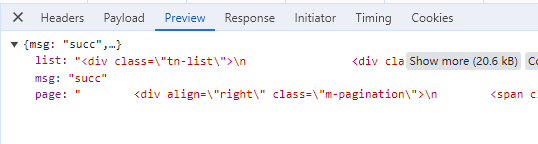
在 Preview 和 Response 中可以看到它的响应内容。
为了确认抓到的包对不对,我们需要检查请求的响应内容,看其中是否包含了我们需要的数据。 抓到正确的请求包以后,我们接下来要做的就是,用代码模拟发起请求。 2.2反爬测试我们简单写一段测试代码,尝试获取数据,顺便检查一下网站的反爬机制。 # 请求地址 url = "https://www.mafengwo.cn/gonglve/ajax.php?act=get_travellist" # 请求头 headers = { "Accept": "application/json, text/javascript, */*; q=0.01", "Accept-Encoding": "gzip, deflate, br, zstd", "Accept-Language": "zh-CN,zh;q=0.9", "Cache-Control": "no-cache", "Content-Length": "105", "Content-Type": "application/x-www-form-urlencoded; charset=UTF-8", "Cookie": "your own cookie", "Origin": "https://www.mafengwo.cn", "Pragma": "no-cache", "Referer": "https://www.mafengwo.cn/travel-scenic-spot/mafengwo/13033.html", "Sec-Ch-Ua": "\"Google Chrome\";v=\"119\", \"Chromium\";v=\"119\", \"Not?A_Brand\";v=\"24\"", "Sec-Ch-Ua-Mobile": "?0", "Sec-Ch-Ua-Platform": "\"Windows\"", "Sec-Fetch-Dest": "empty", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Site": "same-origin", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36", "X-Requested-With": "XMLHttpRequest" } # 请求参数 payload = { "mddid": "13033", "pageid": "mdd_index", "sort": "1", "cost": "0", "days": "0", "month": "0", "tagid": "0", "page": "2", "_ts": "1701158589677", "_sn": "d65ae26004" }从开发者工具中,我们找到 请求地址、请求头、请求参数 等,格式化后粘贴到代码中。 # 导入包 import requests # 发起 post 请求 r = requests.post(url, headers=headers, data=payload) # 打印数据 print(r.json())运行代码,发起网络请求,发现可以成功获取数据。
此时 headers 和 payload 里的参数还是比较多的,但是这些参数并不是每项都必要。所以我们可以进行简化,将不必要的参数删掉。 简化的方法比较简单粗暴,就是逐个删除参数,并运行代码。 如果删除某个参数后,运行结果没有变化,说明该参数不是必要的,可以删掉;如果删掉某个参数后,运行结果为空或者报错了,说明该参数是必须的,不能删除。 最终简化后的代码如下: # 请求地址 url = "https://www.mafengwo.cn/gonglve/ajax.php?act=get_travellist" # 请求头 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36", } # 请求参数 payload = { "mddid": "13033", "pageid": "mdd_index", "sort": "1", "page": "2", } # 导入包 import requests # 发起 post 请求 r = requests.post(url, headers=headers, data=payload) # 打印数据 print(r.json()) Part3编写代码搞定了抓包和反爬测试以后,我们就可以开始编写代码了。 3.1网络请求将前面的网络请求的测试代码封装一下。 # 导入包 import requests def fetchUrl(cityId, page): """ cityId: 城市 id page: 页码 """ # 请求地址 url = "https://www.mafengwo.cn/gonglve/ajax.php?act=get_travellist" # 请求头 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36", } # 请求参数 payload = { "mddid": cityId, "pageid": "mdd_index", "sort": "1", "page": page, } # 发起 post 请求 r = requests.post(url, headers=headers, data=payload) # 返回数据 return r.json() # 调用函数 fetchUrl(13033, 2) 3.2解析数据数据获取到后,接下来就是解析数据了。 该请求返回的数据,格式如下: { list: "游记列表的 html 内容", msg: "succ", page: "翻页按钮的 html 内容" }我们需要的数据以 html 的格式存放在 list 下。 可以通过以下方式将其解析出来。 jsonObj = fetchUrl(13033, 2) # 解析游记列表的 html 内容 html = jsonObj["list"]现在我们得到了游记列表的 html 文本内容,格式如下: 题图 标题 摘要 作者 浏览量/评论数 ......接下来我们可以使用 BeautifulSoup 库来进行解析。 # 导入库 from bs4 import BeautifulSoup # 实例化 bs 对象 bsObj = BeautifulSoup(html, "html.parser") # 获取所有的游记 item tn_items = bsObj.find_all("div", attrs={"class": "tn-item"}) # 循环解析每一个 item for item in tn_items: # 题图 headImage = item.find("div", attrs={"class": "tn-image"}).a.img["data-original"] # 标题 titleNode = item.dt.find_all("a")[-1] title = titleNode.text # 链接 link = "https://www.mafengwo.cn" + titleNode["href"] # 摘要 desc = item.dd.text # 作者 author = item.find("span", attrs={"class": "tn-user"}).text nums = item.find("span", attrs={"class": "tn-nums"}).text.strip().split("/") # 浏览量 views = nums[0] # 评论数 comments = nums[1] # 测试打印 print("题图:", headImage) print("标题:", title) print("链接:", link) print("作者:", author) print("浏览量:", views) print("评论数:", comments) print("摘要:", desc) print("---"*10)运行结果
最后将代码简单封装一下即可。 def parseHtml(html): # 实例化 bs 对象 bsObj = BeautifulSoup(html, "html.parser") # 获取所有的游记 item tn_items = bsObj.find_all("div", attrs={"class": "tn-item"}) itemList = [] # 循环解析每一个 item for item in tn_items: # 题图 headImage = item.find("div", attrs={"class": "tn-image"}).a.img["data-original"] # 标题 titleNode = item.dt.find_all("a")[-1] title = titleNode.text # 链接 link = "https://www.mafengwo.cn" + titleNode["href"] # 摘要 desc = item.dd.text # 作者 author = item.find("span", attrs={"class": "tn-user"}).text # 浏览量 nums = item.find("span", attrs={"class": "tn-nums"}).text.strip().split("/") views = nums[0] # 评论数 comments = nums[1] itemList.append([title, link, author, views, comments, headImage, desc]) # # 测试打印 # print("题图:", headImage) # print("标题:", title) # print("链接:", link) # print("作者:", author) # print("浏览量:", views) # print("评论数:", comments) # print("摘要:", desc) # print("---"*10) return itemList 3.3存储数据我们准备用 csv 格式文件来存储数据。 这里使用了第三方库 pandas。 # 导入包 import pandas as pd def saveData(filename, data): """ filename: 文件名 data: 要存储的数据 """ dataframe = pd.DataFrame(data) dataframe.to_csv(filename, encoding='utf_8_sig', mode='a', index=False, sep=',', header=False) 3.4主函数最后,在主函数中写一个 for 循环,启动爬虫即可。 if __name__ == "__main__": cityId = 13033 filename = "山西.csv" totalPage = 100 # 保存标题行 header = [["标题","链接","作者","浏览量","评论数","题图","摘要"]] saveData(filename, header) # 循环爬取数据 for page in range(1, totalPage + 1): # 请求数据 jsonObj = fetchUrl(cityId, page) # 解析数据 data = parseHtml(jsonObj["list"]) # 保存数据 saveData(filename, data)至此,我们的爬虫主体已经全部完成了。 3.5查改 BUG实际运行中会发现,虽然我们的爬虫已经完成,可以成功抓取到数据,但是非常容易报错崩溃。 因为前面为了追求效率而写的很多并不严谨的代码,导致程序非常的脆弱。 比如这一句代码,用于解析游记的题图链接。 headImage = item.find("div", attrs={"class": "tn-image"}).a.img["data-original"]实际执行时,抓取到某些游记时,会发生报错。
究其原因,是因为在游记列表中,游记的题图标签有两种写法。 代码中如果直接获取标签的 data-original 属性,则遇上 写法 2 的标签便会报错。 因此我们在获取标签属性前,需要先判断属性是否存在。 # 获取题图,代码优化示例 imageNode = item.find("div", attrs={"class": "tn-image"}).a.img if imageNode.has_attr("src"): headImage = imageNode["src"] elif imageNode.has_attr("data-original"): headImage = imageNode["data-original"] else: headImage = ""以上作为查改BUG 和优化代码的示例,给大家参考。 在爬取大量数据的时候,还会遇到更多兼容性方面的 bug,需要大家逐一优化。 3.6运行效果将代码完善后,运行结果如下:
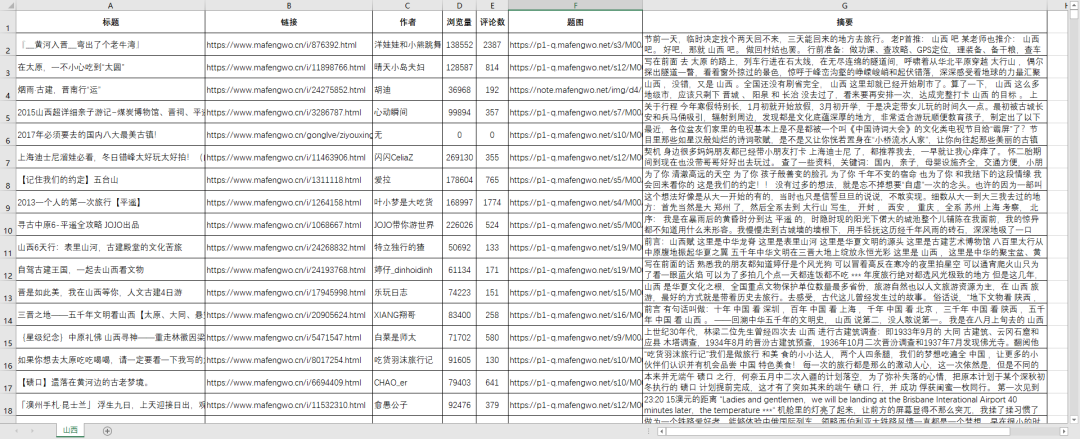
保存好的 csv 文件用 excel 打开,简单整理格式后效果如下:
爬取游记需要填写城市的 ID,这一步对于有爬虫基础的同学应该问题不大。 不知道如何获取城市 id 的同学,我这里也提供了一段脚本,可以根据城市名字自动获取城市 ID。 import requests import re def getCityCode(city): url = 'https://www.mafengwo.cn/search/q.php?q=%s' % city headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36", } r = requests.get(url, headers=headers) # 正则提取城市编码 code = re.findall("type=10&id=([0-9]+)", r.text) # 正则提取城市名称 title = re.findall(''' (.*)''', r.text) if len(code) > 0 and len(title) > 0: return (title[0], code[0]) else: return (city, "找不到该城市!") # 测试代码 a = getCityCode("山西") print(a)运行结果: ('山西', '13033')经测试,在输入的城市名有错别字,甚至是拼音的情况下,代码也可以顺利获取城市 ID。
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。 一、Python所有方向的学习路线 Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具 工具都帮大家整理好了,安装就可直接上手! 三、最新Python学习笔记 当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、Python视频合集 观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例 纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典

 若有侵权,请联系删除 若有侵权,请联系删除
|















【本文地址】
今日新闻 |
推荐新闻 |