【C语言数据结构】图的创建和遍历(简单详细!) |
您所在的位置:网站首页 › 温度计的结构图怎么画 › 【C语言数据结构】图的创建和遍历(简单详细!) |
【C语言数据结构】图的创建和遍历(简单详细!)
|
一.前言:
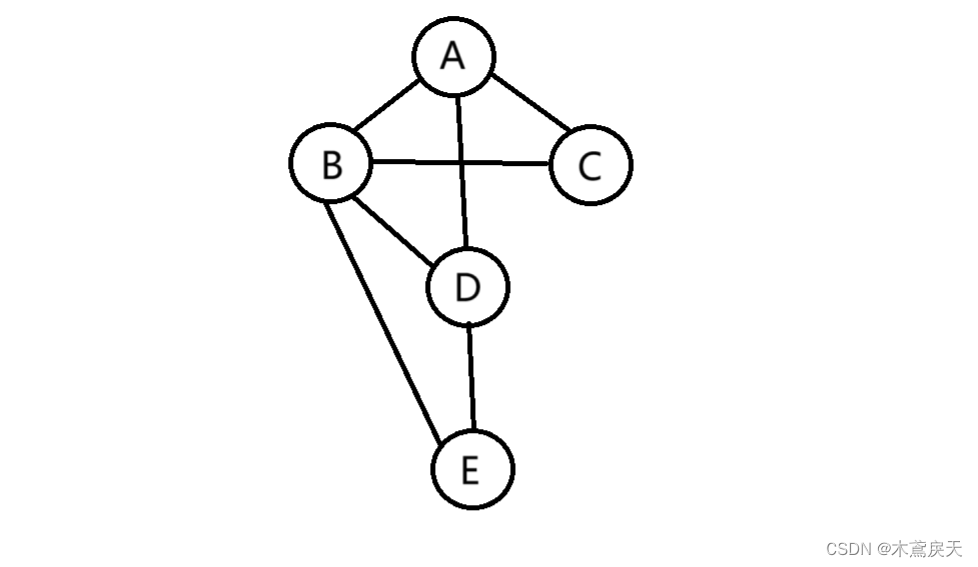
学习这一节之前,我们需要弄懂一些基础的概念,不然会在学后面的时候有点迷糊。 1.顶点:线性表中我们把数据元素叫元素,在树中叫结点,在图中叫顶点(Vertex)。 2.邻接矩阵:(无向图)一种用于表示图的数据结构。它是一个二维数组,其中的元素表示图中顶点之间的连接关系。对于一个有n个顶点的图,邻接矩阵是一个大小为n×n的二维数组。要是图中有两个顶点(假设是第1个和第2个顶点)相连(存在一条边),那么他们对应在邻接矩阵中的第1行第2列和第2行第1列位置为1,其他没有相连的用0表示。 如下图表示:(下面都用以下图举栗子)
我们把有相连边的顶点拿出来:AB,AC,AD,BC,BD,DE,BE(不分先后) 因为顶点顺序为ABCDE,然后我们可以作出它的邻接矩阵: 邻接矩阵ABCDEA01110B10111C11000D11001E01010观察发现无向图邻接矩阵是关于主对角线对称的,这使得后面可以通过邻接矩阵的对称性了解和运用图的一些性质。 »»具体图的基本概念还不熟悉的同学可以看这位大佬的文章,了解了直接往下看代码举例 数据结构与算法(C语言) | 图的基本定义及存储结构 解释:DFS叫深度优先遍历,这种遍历方式主要思路是从图中一个未访问的顶点V开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底,不断递归重复此过程,直到所有的顶点都遍历完成。它的特点是不撞南墙不回头,先走完一条路,再换一条路继续走。还是没有理解的同学可以看下面的遍历的分解过程。 函数体: void DFS(Graph* G,int* flag,int index)//深度优先遍历 { printf("%c\t",G->vexs[index]); flag[index]=1;//已经访问过顶点标记为1,之后不会再访问 for(int i=0;ivexNum;i++) { if(G->arcs[index][i]==1&&!flag[i]) { DFS(G,flag,i); } } }遍历过程如下: 此时由A到B,发现A有到B的边,则遍历到B处,B可以输出 ABCDEA0①110B10111C11000D11001E01010由B继续往后遍历,B有到C的边,则C可以输出 ABCDEA01110B10①11C11000D11001E01010到C顶点处,没有下一个未访问的顶点了,正常来说按顺序是到D的,结果C到D没有边,则递归返回到B顶点,由B继续走未走过的边遍历未访问的顶点,于是到了D顶点,D输出 ABCDEA01110B101①1C11000D11001E01010D继续往后走,发现到E有路了,于是E输出 ABCDEA01110B10111C11000D1100①E01010总结:通过以上的图像分步遍历示意,同学们应该知道规律了。找下一个相邻顶点时看行,有没有边看行列相交处是否为1,有边是1,无边为0。 1.BFS遍历函数解释:BFS叫广度优先遍历,它从图的起始节点开始,首先访问所有与起始节点直接相连的节点,然后再访问与这些节点直接相连的所有未被访问过的节点,这个过程会持续到所有的节点都被访问过。这种遍历方式类似于波纹在水面上扩散的过程。在BFS广度遍历中,通常使用队列来存储待访问的节点。还是没有理解的同学可以看下面的遍历的分解过程。 函数体: void BFS(Graph* G,int* flag,int index)//广度优先遍历(队列) { Queue* Q=initQueue(); printf("%c\t",G->vexs[index]);//开始:那一个顶点出来(A) flag[index]=1;//标记A列无顶点输出了,也就是A已经输出 enQueue(Q,index);//开始:下标0入队 while(!isEmpty(Q))//队不空 { int i=deQueue(Q);//开始:0出队,i=0,所以到A行 for(int j=0;jvexNum;j++)//就将邻接矩阵每一行有1的顶点先输出,输出完了再转到刚刚有1的顶点的那一行,再看此行有没有1的顶点,接着输出 { if(G->arcs[i][j]==1&&!flag[j]) { printf("%c\t",G->vexs[j]); flag[j]=1; enQueue(Q,j); } } } }遍历过程如下: 先输出顶点A,此时flag[0]=1,表示第一列(j=0)已经有顶点A输出,这里保证每个顶点都输出的话,就要做这个标记,之后就不会再来这一列(j=0)找顶点了 i\j→(j) 01234↓(i)ABCDE0A0 flag[0]=1 11101B101112C110003D110014E01010输出顶点A后,继续在A行里面找1,B,C,D都有1,所以顶点都输出,并将其顶点对应的下标j值存入队列中,之后会访问这些j下标的行。另外还flag[1]=flag[2]=flag[3]=1,标志着BCD列都没有顶点输出了。 i\j→(j) 01234↓(i)ABCDE0A0 flag[0]=1 1 flag[1]=1 1 flag[2]=2 1 flag[3]=3 0 1B101112C110003D110014E01010之后出队的是1,i=1,就来到了B行,B中ABCD列顶点都标记输出过了,E列有1,未标记,表示有边,输出E,之后j=4这个下标入队。到C行之后每一行就没有顶点了输出,因为列全标记了,遍历才结束。 i\j→(j) 01234↓(i)ABCDE0A0 flag[0]=1 1 flag[1]=1 1 flag[2]=1 1 flag[3]=1 0 1B10111 flag[4]=1 2C110003D110014E01010总结:flag是用来标记列的,可以这样认为:一列代表一个顶点,要是全部的列标记了就可以证明遍历结束了。另外,行只是用来看是否有到达下一个顶点的条件(有1就有边),这里行的执行顺序是按入队出队顺序决定的。 NO.33 【已修改代码注释漏洞】 如果这篇文章有帮助到你,希望给个免费的点赞支持,感谢🌹 |
【本文地址】