SPSS 教程 写医学研究SCI文章,不能不了解混杂因素与混杂偏倚! |
您所在的位置:网站首页 › 混杂偏倚如何计算 › SPSS 教程 写医学研究SCI文章,不能不了解混杂因素与混杂偏倚! |
SPSS 教程 写医学研究SCI文章,不能不了解混杂因素与混杂偏倚!
|
选择偏倚 由于选入的研究对象与未选入的研究对象在某些特征上存在差异而引起的误差。常发生在设计阶段。主要造成研究人群对总体的代表性不足。 信息偏倚 又称测量偏倚、观察偏倚。是在收集信息过程中由于测量暴露与结局的方法有缺陷,使采集到的信息不准确,从而引起偏倚。错分是测量不准确导致的最直接的结果。 混杂偏倚 研究某个因素与某种疾病的关联时,由于某个既与疾病有制约关系,又与所研究的暴露因素有联系的外来因素的影响,掩盖或夸大了所研究的暴露因素与疾病的联系特点:不易识别,不易确定,需认真细致地去解决控制方法。 无论何种研究,都可能遇到上述三种类型的偏倚,我们以RCT研究为例。我们都知道RCT研究是临床研究证据可靠性最强的一类研究。为什么? RCT研究最大的优点,或者被认为可靠性最强,因为它是混杂偏倚最小。 但是RCT研究也会受到信息偏倚的影响,在测量指标上容易受到人为主观的影响,因此,RCT研究有一个措施来应对,盲法原则,患者、测量者者甚至统计分析人员都不能知道谁是处理组,谁是对照组。 RCT研究最大的问题是选择偏倚。现在RCT研究越来越被人质疑,是因为它在人群选择上,太挑了,总是挑一些比较单一、标准严格限定、特征差异性小的一些病人(这样容易得到阳性结果),但是这样的人群却没有代表性!因此近十年来才不断有人呼吁,用真实世界研究来代替一部分RCT研究。RCT研究结果没法真正代表广大的总体人群,所以往往很多药物在临床试验是有效的,但是真正开展使用时,效果就不突出。对于这点,RCT的相应补救措施是多中心临床研究、大样本人群研究,但还是无法完全避免选择偏倚。 观察性研究,除去信息偏倚与选择偏倚之外,普遍存在着的是混杂偏倚。 2. 混杂偏倚与混杂因素混杂偏倚是指暴露因素与疾病发生或者疾病结局的相关(关联)程度受到其他因素(混杂因素)的歪曲或干扰。 比如,观察性研究某药物(X)的治疗肿瘤的效果(Z),由于非随机,药物(X)的使用还受到患者人口学、社会、经济因素(C)的影响。 例如:由于分组不均衡,药物组多为中青年人群,对照组多为中老年人。 如果药物组效果较好,有效率较高,这个结果可否要证明X与是否有真实关系?
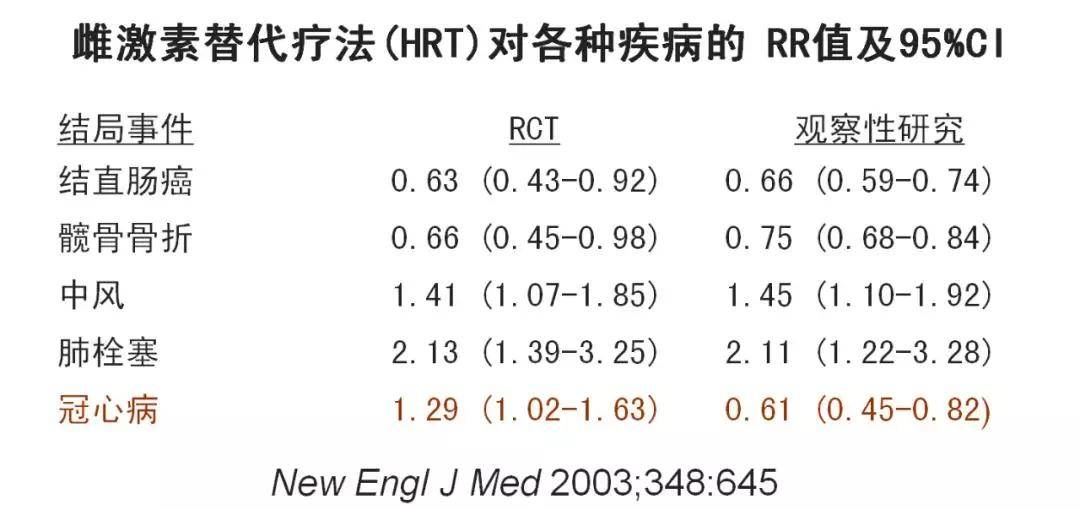
不能,为什么要药物组效果好?药物组比对照组效果好的可能原因包括两种可能 1) 药物效果确实好 2) 年轻人效果比老年人效果好,所以年轻人比例高的药物组,比老年人比例高的对照组生存率高。 所以,最终反应的效果指标比如RR值(本例为1.47),是药物效果和年龄效果混杂一起的值,不能完全归功于药物。年龄就是混杂因素,它造成的偏差称之为混杂偏倚。 3. 混杂偏倚一般如何会产生?混杂偏倚在医学研究的主要产生原因是分组不均衡。 分组均衡的情况的情况下,比如假如上述例子是分组均衡的,那么药物组和对照组年龄结构都是一样的,那么两组人群年龄的效果是完全一样,年龄对药物因素的干扰作用为 0 ,这就是我们之前说的两组具有可比性。完全可比的人群没有混杂偏倚。 因此, RCT 研究往往基本不存在着混杂偏倚,它采用的随机化分组,因此,各组基本特征相似,具有可比性,分组均衡。 观察性研究,分组不均衡,那么就可能其他因素的分布是不可比的,不可比的情况,就可能存在混杂因素,可能会造成混杂偏倚。 新英格兰医学杂志 2003 年发表一篇综述,系统总结观察性研究和 RCT 研究在论证 雌激素替代疗法(HRT)对冠心病有保护作用吗?
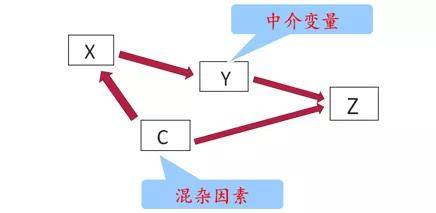
我们就会发现,在冠心病的研究分析上,观察性研究与 RCT 研究得到了截然不同的结果(一个是保护因素,一个是危险因素) 由于这个原因,观察性研究采用一般的统计学方法,虽然能克服随机误差,但无法克服混杂偏倚: 横截面研究的不同组别某项指标比较 横截面研究的两变量相关分析 病例对照研究--OR值(卡方检验):病例对照分组不均衡 队列研究-RR值(卡方检验):暴露和不暴露分组不均衡、治疗组和对照组分组不均衡 4. 什么样的因素才可以称之为混杂偏倚实际上混杂因素不仅要分组是否均衡,它总共要满足3个条件: 1) 与研究因素存在着相关或因果关系(本条件即为分组不均衡的结果) 2) 与结局存在因果关系 3) 不在研究因素与结局因果链上的之间(如果是,那么即为我们之前提过的中介变量) 比如:研究某药物X的治疗肿瘤的效果(Z),同时发现,药物X可能通过改变体内的物质Y而影响疗效 由于非随机,药物X的使用还受到患者人口学、社会、经济因素(C)的影响。 例如:由于分组不均衡,药物组多为中青年人群,对照组多为中老年人。如果药物效果较好,生存率较高,则年龄是典型的混杂因素(C),而Y是中介变量。
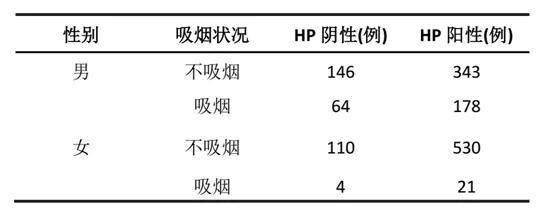
混杂因素三个条件,其中第1)和第2)条件一般可以通过统计学方法来解决,第三个条件则主要基于专业知识判断。 1)与研究因素存在着相关或因果关系 ☆采用t、卡方、方差、秩和 2)与结局存在因果关系 ☆采用线性(t检验)、logistic(卡方)、COX回归 3) 不在研究因素与结局因果链上的之间 ☆ 主要是专业判断 举例:分析性别、吸烟对幽门螺杆菌(HP)的影响,判断性别是否是混杂因素。
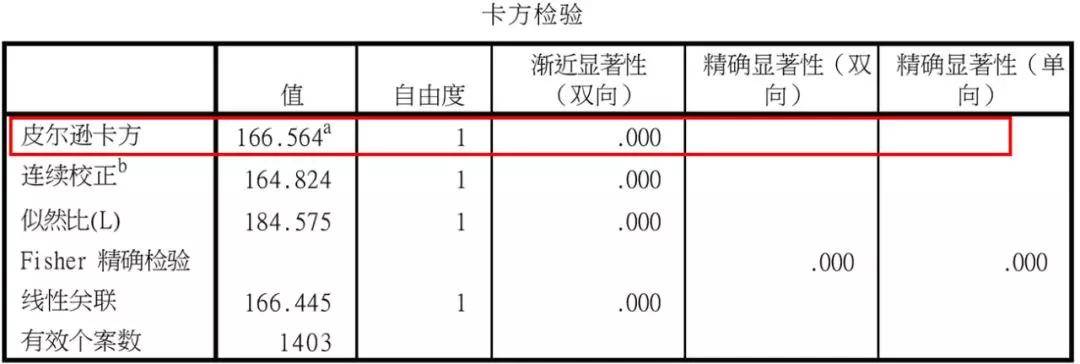
1)判断吸烟在不同性别中分布是否不同:卡方检验:结果显示,吸烟在性别中分布不同,男性中比例更高
2)判断性别是否对Hp有影响:单因素logistic回归。结果显示,性别对HP影响有统计学意义(P |

【本文地址】
今日新闻 |
推荐新闻 |