使用YOLOV5训练口罩检测模型 |
您所在的位置:网站首页 › 深海猎人血脉相连 › 使用YOLOV5训练口罩检测模型 |
使用YOLOV5训练口罩检测模型
|
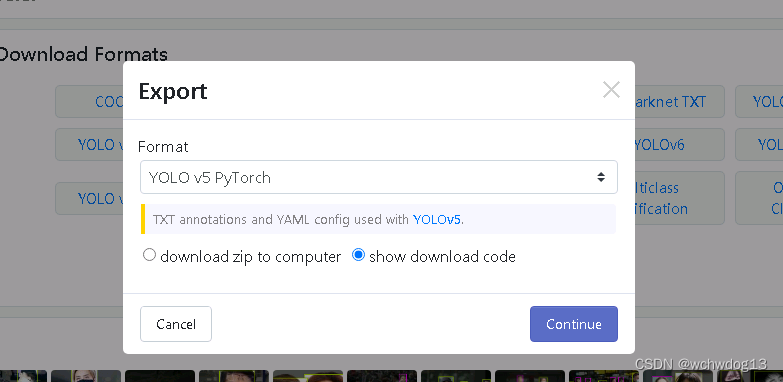
一、YOLOV5源码和口罩数据集的下载与导入 我是在github上下载的,地址是GitHub - ultralytics/yolov5 at v7.0,下载之后,我将其导入pycharm环境中, 数据集在roboflow上面下载的,地址是Computer Vision Datasets,点击如下图 然后将数据集导出,到处时需要选择数据集的YOLOV5格式,如下
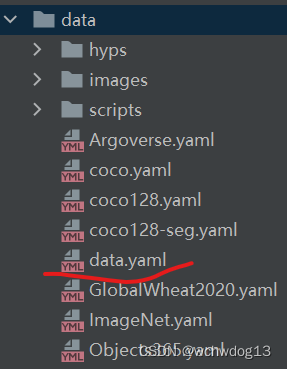
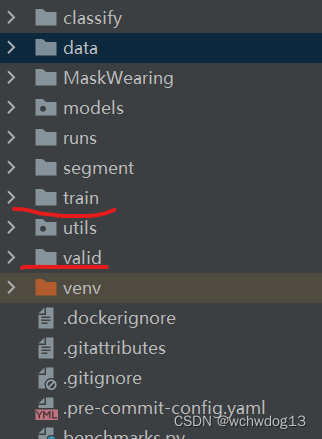
下载下来后,我将数据集放入了pycharm的YOLOV5项目中,其中,口罩数据集中的data.yaml文件放到了data目录中,口罩数据集中的训练数据和校验数据(train和valid目录)到了YOLOV5项目的直接目录中,如下
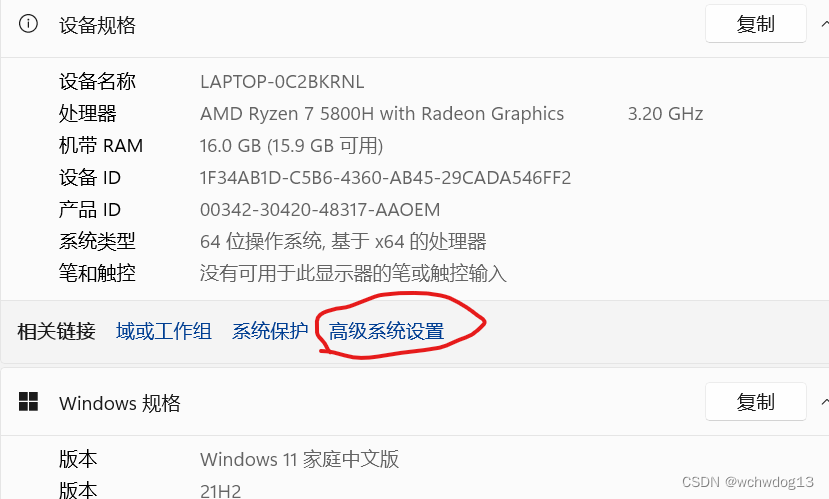
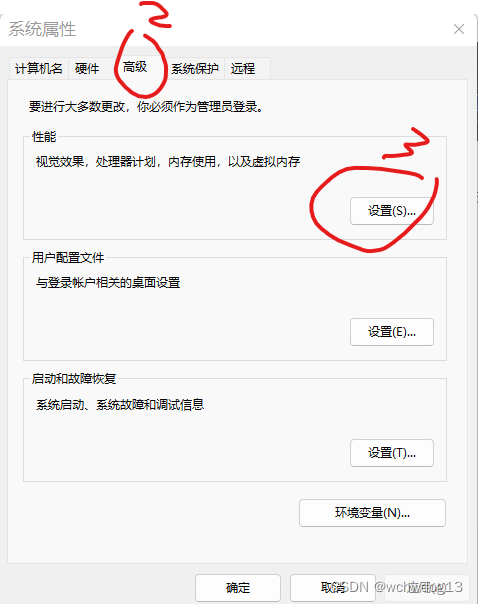
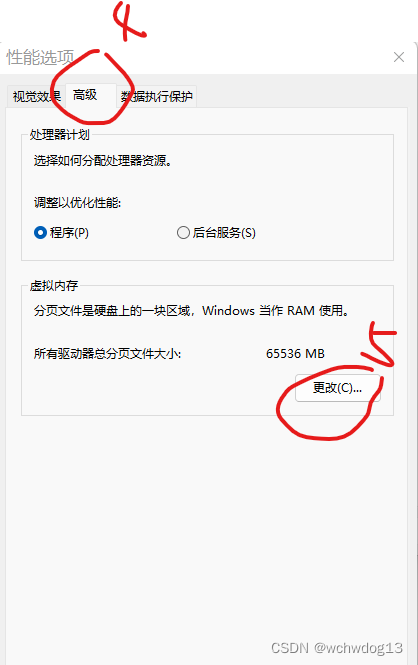
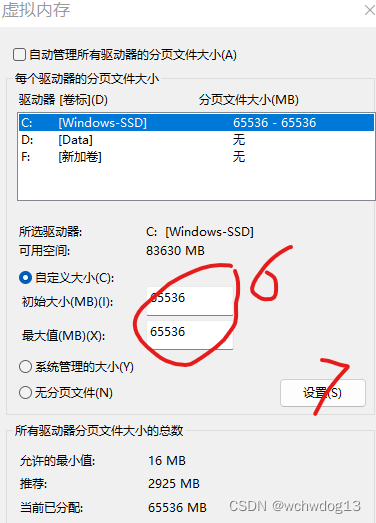
train和valid目录之所以这么放置,是因为data.yaml的内容如下 train: ../train/images val: ../valid/images nc: 2 names: ['mask', 'no-mask']二、YOLOV5口罩检测模型训练 训练前需进行相应的配置,在train.py中需进行相应的修改,我的修改如下,在parse_opt方法中, 设置网络结构,如下 parser.add_argument('--cfg', type=str, default=ROOT / 'models/yolov5s.yaml', help='model.yaml path')设置数据集,如下 parser.add_argument('--data', type=str, default=ROOT / 'data/data.yaml', help='dataset.yaml path')其他的设置的选的默认。 我点击运行后,结果系统提示“OSError: [WinError 1455] 页面文件太小,无法完成操作”的异常,对于该异常,我做了以下的事情进行排除: 一是将dataloaders.py中的num_workers设置为0,如下 return InfiniteDataLoader(dataset, batch_size=batch_size, shuffle=shuffle and sampler is None, num_workers=0,#nw, sampler=sampler, pin_memory=PIN_MEMORY, worker_init_fn=seed_worker, generator=generator) # or DataLoader(persistent_workers=True) return loader(dataset, batch_size=batch_size, shuffle=shuffle and sampler is None, num_workers=0,#nw, sampler=sampler, pin_memory=PIN_MEMORY, collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn, worker_init_fn=seed_worker, generator=generator), dataset二是设置虚拟内存分页大小,我将分页大小设置为65536M,具体设置步骤如下
再次点击运行,即可开始训练,如下
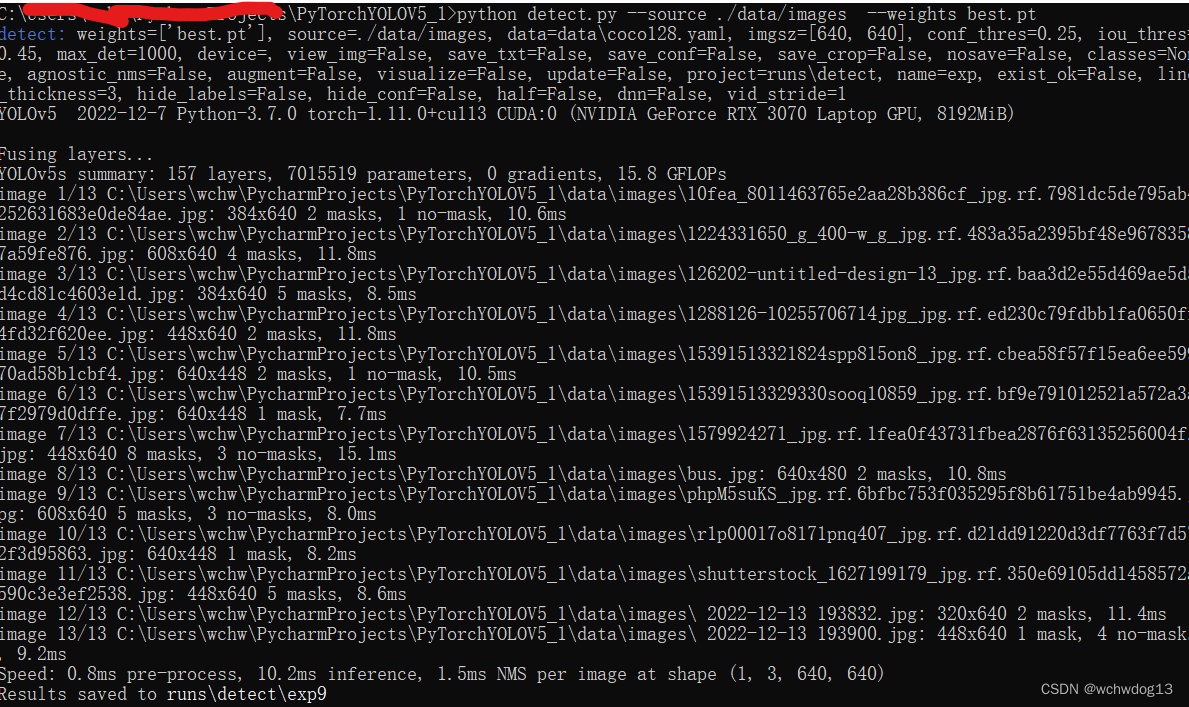
训练完成后,训练好的模型默认保存在runs\train路径下面。同时已将该模型上传,下载地址(19条消息) 使用yolov5训练好的口罩检测模型-深度学习文档类资源-CSDN文库 三、对训练完成的口罩检测模型进行测试 开始对训练完成的口罩检测模型进行测试,我将模型(训练好的模型文件名为best.pt)放到YOLOV5项目的直接目录下(当然也可以放其他地方),我将待检测的图片放到data\images目录下,然后通过cmd进入到YOLOV5项目中,执行下面命令: python detect.py --source ./data/images --weights best.pt运行结果
结果图片默认保存在runs\detect路径下,打开一张检测好的图片看一下:
|


【本文地址】
今日新闻 |
推荐新闻 |