数据结构与算法 |
您所在的位置:网站首页 › 深度优先算法和广度优先算法的应用 › 数据结构与算法 |
数据结构与算法
|
广度/深度优先搜索
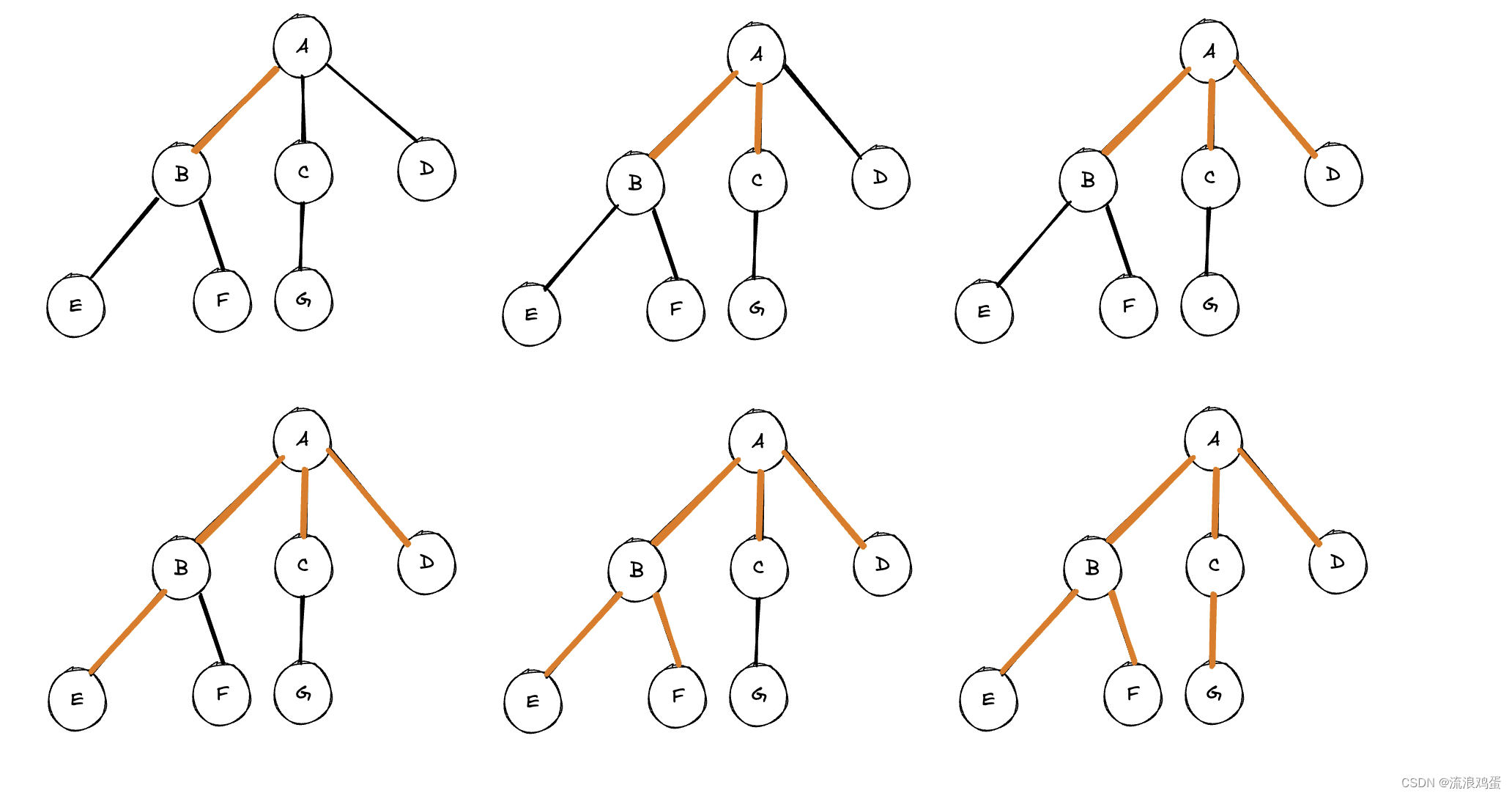
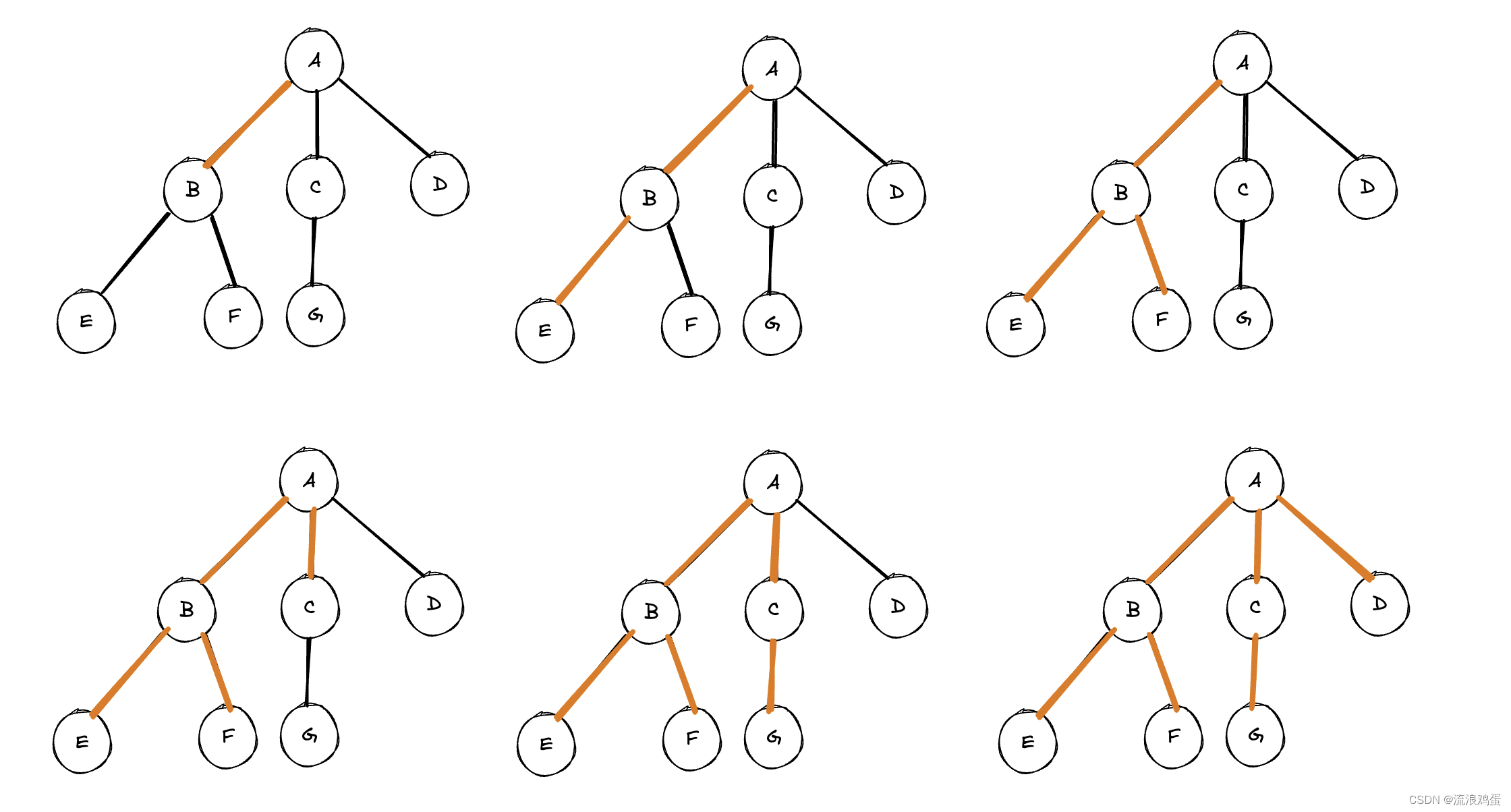
在上一章我们讲到了关于图的基本知识,没有看过的小伙伴可以看看,先对图有个简单的认识。 在本章中,我们将继续向下挖掘一下图的搜索算法。 文章目录介绍 一、广度优先搜索(Breadth-First Search 简称BFS) 1. 概念 2. 实现思路 二、深度优先搜索(Depth-First Search 简称DFS) 1. 概念 2. 实现思路 三、python代码实现 四、时间复杂度分析 总结 介绍图的搜索算法:图的搜索是指从图的某个顶点出发,沿着边连接的其他顶点,最后到达目标顶点的过程。根据搜索过程中访问节点的顺序,图搜索算法可以分为“广度优先搜索”和“深度优先搜索”两类。 一、广度优先搜索(Breadth-First Search 简称BFS) 1. 概念BFS算法首先需要访问与起始顶点距离为k的所有顶点然后在访问距离为k+1的顶点。也就是说,它是一层一层的访问,并且它并不考虑结果的可能位置,而是彻底地搜索整张图,直到找到结果为止。一般用队列(queue)来实现此算法。 1. 首先需要创建一个空的集合(set或者list都可以)用于存储已访问过的节点。还需要创建一个队列,用于存储待访问的节点,并需要将起始节点加入队列。 2. 在初始化完成之后,需要循环访问队列中的节点,如果队列不为空,则让队列第一个元素出队(在第一次循环中就是起始顶点,因为在初始化中就已经将起始节点加入队列),如果出队的节点还没有被访问过,则将该节点加入已访问过的节点集合,并访问该节点的邻接节点,然后在将该节点的邻接节点加入到队列中,然后重新开始循环。(具体实现请参考python代码实现) 3. 当队列为空时,也就意味着所有节点都被访问过了,此时循环结束。 二、深度优先搜索(Depth-First Search 简称DFS) 1. 概念DFS算法首先会沿着一条路径不断往下搜索,直至走到了尽头,然后在折返回上一个节点开始搜索另外一条路径。也就是说,它是一列一列的访问,一般用栈(stack)来实现此算法。
与广度优先搜索非常相似,唯一不同的地方就是选择下一个节点的不同。 深度优先搜索是选择当前节点的未被访问的子节点为下一个节点。 具体实现以及差别请参考python代码实现 三、python代码实现BFS: from collections import defaultdict, deque # 广度优先搜索的实现 def bfs(graph, start): visited = set() # 用于存储已访问过的节点 queue = deque([start]) # 创建一个队列,并将起始节点加入队列 while queue: current_node = queue.popleft() # 从队列中取出第一个节点 if current_node not in visited: print(current_node, end=" ") # 输出当前节点 visited.add(current_node) # 将当前节点加入已访问节点集合 # 将当前节点的邻接节点加入队列 for neighbor in graph.graph[current_node]: if neighbor not in visited: queue.append(neighbor)DFS: from collections import defaultdict # 深度优先搜索实现 def dfs(graph, start): visited = set() # 用于存储已访问过的节点 stack = [start] # 创建一个栈,并将起始节点压入栈 while stack: current_node = stack.pop() # 从栈顶取出一个节点 if current_node not in visited: print(current_node, end=" ") # 输出当前节点 visited.add(current_node) # 将当前节点加入已访问节点集合 # 将当前节点的邻接节点压入栈(逆序处理) for neighbor in reversed(graph.graph[current_node]): if neighbor not in visited: stack.append(neighbor)ps. 将当前节点的邻接节点压入栈的时候要注意,一定要做逆序处理。因为这样的话在弹出栈顶元素时,才能先访问它的正确顺序的邻接节点。 可以看出来这两种算法的实现非常的相似,差别就在于BFS是让最左边的元素出队,而DFS是弹出最右边的元素。 四、时间复杂度分析用队列实现广度优先搜索的时间复杂度为 O(V+E),其中 V 是顶点数,E 是边数。每个顶点最多被访问一次,每条边最多会被访问两次(一次在起点,一次在终点),因此总共的时间复杂度是 O(V+E)。 用栈实现深度优先搜索的时间复杂度也为 O(V+E)。每个顶点最多被访问一次,每条边最多也会被访问两次,因此总共的时间复杂度也是 O(V+E)。 总结这两种搜索算法的核心操作都是搜索和扩展节点,只是在选择下一个节点的方式上有所不同。广度优先搜索选择最近扩展的节点的相邻节点作为下一个要扩展的节点,而深度优先搜索则选择当前节点的一个未被访问的子节点作为下一个要扩展的节点。 以上就是本章要讲的内容,介绍广度和深度优先搜索的思路及其实现,如果本章中有不准确或有待改进之处,欢迎大家指出。 下一章会介绍最短路径算法和最小生成树。 |
【本文地址】
今日新闻 |
推荐新闻 |