你会爬虫吗,我来教你爬海关蜀黍 |
您所在的位置:网站首页 › 海关总署报关单查询平台 › 你会爬虫吗,我来教你爬海关蜀黍 |
你会爬虫吗,我来教你爬海关蜀黍
|
爬虫是近年来一直比较流行的,今天无聊就来和你聊聊爬虫.在例子中讲解,让你学会使用爬虫.并将自己爬取的数据保存在excel中,首先来看看网站页面 就是下面这样,不得不说这个页面做的还是比较好看的
在准备工作做完之后该进入正题了,我主要是要爬去网站上以问答形式的段落,主要就是交流互动 首先F12查看网站的源html代码,然后找到主题下问题的msgDataId,然后再前往另一个页面爬取答案.同样的找到答案的html位置.不好说,我直接上代码好了 html_frist = "http://www.customs.gov.cn/eportal/ui?currentPage=1&moduleId=76777400f8cf4a66807d98d442234e97&pageId=374089" html = requests.get(html_frist) print html_frist html.encoding="utf-8" title = re.findall("target=\"_blank\" href=\"(.*)\" style",html.text) for each in title: #print each count+=1 html_url = "http://www.customs.gov.cn"+each print "\t",html_url html1 = requests.get(html_url) html1.encoding = "utf-8" sensece = html1.text soup = BeautifulSoup(html1.text, 'html.parser') # 文档对象 str1="" for k in soup.findAll("div",class_="easysite-info-con"): str1 += str(k).replace("","").replace("","").replace("","").replace(" ","").replace("\n","").strip()+"@#$^@" print str1这样就获取到了网页上的数据并存在字符串里了,然后再教你python操作excel的方法,依旧用代码说事: book3 = xlwt.Workbook(encoding='utf-8', style_compression=0) sheet_target3 = book3.add_sheet('test', cell_overwrite_ok=True) sheet_target3.write(count, 1, q)#q,a是截取的上面str1 sheet_target3.write(count,2,a) book3.save("ceshi.xls")总结其来就是这样罗 #encoding=utf-8 import re from bs4 import BeautifulSoup import datetime import requests import sys import xlwt reload(sys) sys.setdefaultencoding("utf-8") start = datetime.datetime.now() count=0 book3 = xlwt.Workbook(encoding='utf-8', style_compression=0) sheet_target3 = book3.add_sheet('test', cell_overwrite_ok=True) try: for i in range(500): html_frist = "http://www.customs.gov.cn/eportal/ui?currentPage="+str(i)+"&moduleId=76777400f8cf4a66807d98d442234e97&pageId=374089" try: html = requests.get(html_frist) except: print "垃圾" print html_frist html.encoding="utf-8" title = re.findall("target=\"_blank\" href=\"(.*)\" style",html.text) for each in title: #print each count+=1 html_url = "http://www.customs.gov.cn"+each print "\t",html_url html1 = requests.get(html_url) html1.encoding = "utf-8" sensece = html1.text soup = BeautifulSoup(html1.text, 'html.parser') # 文档对象 str1="" for k in soup.findAll("div",class_="easysite-info-con"): str1 += str(k).replace("","").replace("","").replace("","").replace(" ","").replace("\n","").strip()+"@#$^@" #print str1[:-5] q = str1.split("@#$^@")[0] a = str1.split("@#$^@")[1] sheet_target3.write(count, 1, q) sheet_target3.write(count,2,a) book3.save("ceshi.xls") print count print "q",q print "w",a except: print ("hh") end = datetime.datetime.now() print ("耗时:%s S"%((end-start).seconds))其实爬虫很简单的,不会用soup,就可以只使用request,其中request中的get和post还没涉及到,期待下次我的杰作. 下次就会讲解具体: 还是简要介绍一下吧: Get是从服务器上获取数据 Post是向服务器传送数据 Get通过构造url中的参数来实现功能 Post将数据放在header提交数据. |
 现在进入正题,首先的导入利用到的库咯 re,正则表达式;bs4,request和对excel文件夹进行操作的xlwt库.
现在进入正题,首先的导入利用到的库咯 re,正则表达式;bs4,request和对excel文件夹进行操作的xlwt库.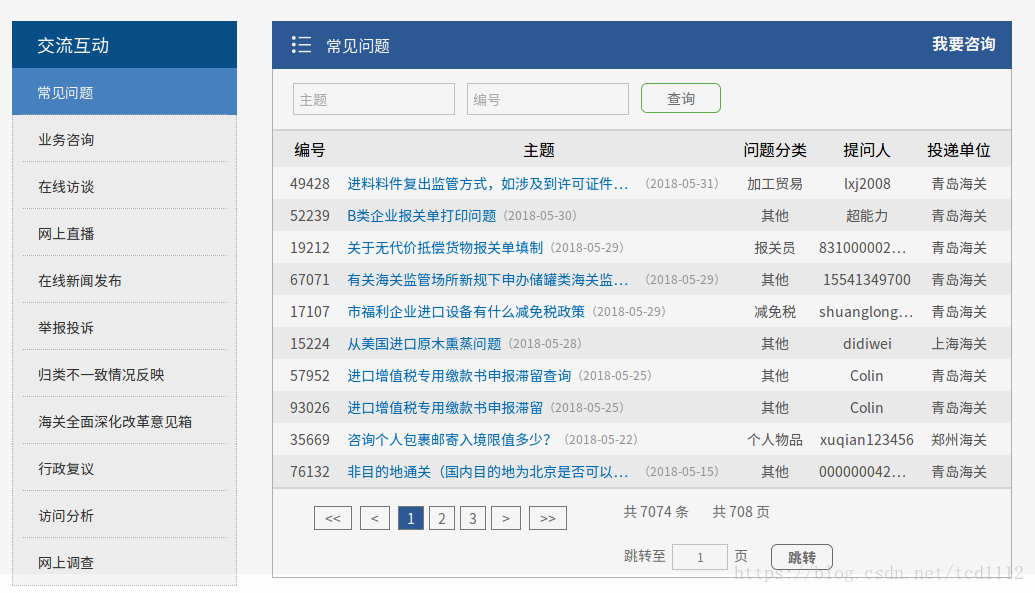
【本文地址】
今日新闻 |
推荐新闻 |