开发一款浏览器内核需要学习哪些方面的知识? |
您所在的位置:网站首页 › 浏览器内核用什么语言开发 › 开发一款浏览器内核需要学习哪些方面的知识? |
开发一款浏览器内核需要学习哪些方面的知识?
|
我突然也想就这个问题做个解答,因为我毕设也做了这个东西。不过,做的很渣啊……基本功能都没有实现啊……但是我却发现这个东西非常有意思。 首先,毫无疑问,浏览器是个非常复杂的系统。但是任何复杂软件系统都可以通过层层抽象来简化设计,这个也就是我们平常熟悉的自顶向下的设计方式。 那么我们首先就要对浏览器进行拆解。现在的浏览器都有一个叫做浏览器内核的关键部分(也称作排版引擎),而这个部分相对于浏览器本身来说就是一个黑箱,提供接口,给出结果。另外对现代浏览器来说,书签管理等功能则独立于排版引擎而存在。那么你在做的时候,重点也就在排版引擎。 那排版引擎主要做什么功能呢?简单讲就是根据URL获取资源的字节流,然后根据字节流和资源类型交给相关的解析器进行处理。这个时候需要考虑我们到底需要处理几种资源,各种资源如何处理。所谓的资源处理就是将无结构的字节流变成结构化数据。因为计算机能够处理是结构化数据。拿到结构化数据,便可以根据结构化数据继续处理。 那我们先看URL获取的这个部分。你可以通过给内核模块封装一个调用接口,从浏览外壳传递URL字符串到内核接口,然后根据URI的相关标准(http://www.ietf.org/rfc/rfc3986.txt)来处理就好了。因为这里面涉及各种协议,比如file协议,比如http/https协议,你可能还需要封装一个自己的协议,用来获取内核自带的一些资源路径,比如默认的404页面。 处理好URI之后,你就可以根据URI的结构,交给相关网络模块来处理。我在做的时候,直接扔给了libcurl。但是libcurl在iOS上面,不是最好的实现方法,这个时候你可以继续抽象,提供统一的网络接口,对接操作系统提供的网络相关API。 网络模块的主要任务就是抓取字节流,抓取回来字节流之后,这个时候你可以直接处理,但是很容易阻塞。所以你可以去实现一个缓存机制,把抓取到的字节流缓存在本地,形成一个资源池。这个地方的实现我没有具体研究过,原谅我直接使用了静态变量来做…… 你把资源抓回来了,你就需要看这个这个资源的类型,是图像的,你可以放在那里等着回头用的之后直接调取,是HTML、CSS或者脚本文件,你可以首先判断文件类型,这个一般根据网络请求的Header中的content-type来决定。 那么你现在拿到HTML的源代码了,又知道源代码的编码格式了,那就处理呗。不过为了更好的开发,一般会将HTML的编码转换成UTF-8,反正《HTML5规范》中是这么写的(我只是粗略的读了,可能是我理解错了?)。正如前面的答案给出的,HTML解析就是一个自动机模型,虽然是这么说,但是写起来还是很不容易的。《HTML5规范》中有详细的算法:8 The HTML syntax 补充点不相关的内容:如果你想看Google Gumbo的代码,别去直接看代码了,用doxygen,顺便打开自动生成UML的功能,写论文都靠它了。 DOM Tree是HTML的结构化依托的数据结构,HTML其实可以表示成多种数据结构,但是《HTML 5规范》中直接采用了DOM Tree,或许由于已经成为事实上的标准了。但是,我们都知道《HTML 5规范》并非W3C嫡出……(扯远了) 生成DOM Tree,其实规范中也是有详细算法描述的,参见 8 The HTML syntax 。简单描述就是采用一个栈结构。HTML的解析需要考虑各种不规范的情况……什么嵌套结构有错,标签没有正确闭合等等。好在规范都给出了算法。 DOM Tree也是网页的对外接口。CSS的样式化,JavaScript对于HTML文件的操作都是操作DOM Tree。 至于CSS,看标准呗。Cascading Style Sheets Level 2 Revision 1 (CSS 2.1) Specification 标准中直接给出了CSS的语言描述,可以采用YACC/LEX直接生成。但是我卡在这里了,后面的也就都没有做,只是看了下如何实现的。 至于JavaScript,我都还不会写JavaScript,就不涉及了。不过你可以调用V8嘛! 你获取了DOM结构和CSS的结构,就可以根据CSS的规则,按照CSS的选择器遍历DOM Tree找到相关节点,然后把样式信息写过去。这个时候,CSS是有三层的,一层是浏览器给各类标签定义的默认样式,一般也是用CSS来描述的,一种是网页作者提供的CSS样式,一种是用户定义的样式。这个时候根据优先级,融合这三种CSS,然后对DOM Tree进行样式化。样式话无非就是一个遍历的过程而已。 经过样式化之后,你会得到一个经过样式话的DOM Tree,也就是各个DOM节点带了这个节点的样式信息。这个时候就开始进行布局计算了。布局计算,说白了就是从DOM Tree构建一个子树,我们称为Rendering Tree。Rendering Tree的各个节点都是将来要在屏幕上画出来的,因此一般只涉及里面的内容。这个就是渲染过程的开始部分了,所有隐藏的元素其实都是不会进入到Rendering Tree的,例如具有CSS的display:none属性的,都是不会显示的,自然也就无法进入Rendering Tree。对于渲染,可以去读如下的五篇文章,讲的非常好:Rendering:Very useful series of posts by Dave Hyatt:WebCore Rendering I – The BasicsWebCore Rendering II – Blocks and InlinesWebCore Rendering III – Layout BasicsWebCore Rendering IV – Absolute/Fixed and Relative PositioningWebCore Rendering V – FloatsRender Layers and The Rendering paths – “WebKit Rendering Basics” section explains it very well. 拿到Rendering Tree之后,就是渲染了,这个时候就可以调用操作系统提供的各种API绘制文字、图片和视频等。各种Form空间就可以绑定到原生控件。然后显示出来。还记得刚开始翻WebKit代码时,就看到貌似采用了一个NSScorllView作为画布,进行绘制。 整个浏览器内核的工作原理也就是这些,说起来容易,写起来,则需要各种考量。自己写一个,不一定能写出多少东西,但是整个研究过程,会学习到很多设计模式的精髓什么的。虽然我的毕设混过去了,但是我准备再好好重构重写这个内核,真的很有趣。(自立Flag) 你做的是浏览器内核,那么最好的参考材料其实是W3C出的各种规范,各种RFC以及现有的浏览器内核的开源实现。印象最深的一句话就是RFC和具体实现其实是相辅相成,互相描述的。 另外,排版引擎的功能不止在这里,写iOS的时候,意识到其实窗口管理器喝各种UI本质上和HTML的排版是类似的,其本质也是利用各种数据结构来记录处理各UI控件之间的关系。 总之,计算机的各层抽象隐藏了很多细节,但是往往这些细节都是优美的,我们看到的往往是水面上的冰山。附上一些做毕设的时候的研究资料,供参考(原谅我直接从论文文献拷贝出来了): Let's build a browser engine! Part 1: Getting started. 朱永盛. WebKit 技术内幕 [M]. 北京 : 电子工业出版社, 2014. GARSIEL T, IRISH P. How Browsers Work: Behind the scenes of modern web browsers[EB/OL]. [2014-08-28]. How Browsers Work: Behind the scenes of modern web browsers. |
 除了判定资源的类型以外,你还需要判断文件的编码格式,是UTF-8呢,还是GB2312呢?这个有多种方法,包括解析Meta标签,或者采取《HTML5规范》中给出的算法来进行判定。参考:2 Common infrastructure8 The HTML syntax
除了判定资源的类型以外,你还需要判断文件的编码格式,是UTF-8呢,还是GB2312呢?这个有多种方法,包括解析Meta标签,或者采取《HTML5规范》中给出的算法来进行判定。参考:2 Common infrastructure8 The HTML syntax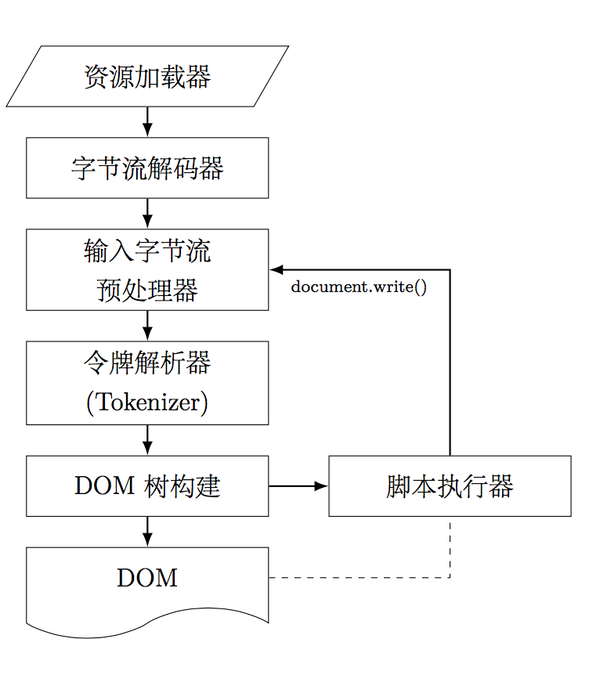 貌似总共有大概232个判断条件?反正我尝试写了一个之后,果断放弃了,而是采用了 google/gumbo-parser · GitHub 。所以如果你感兴趣HTML的解析,可以参考Google的实现,自己写一个也是可以的,只不过要耐心点。Google Gumbo本身给你实现一个类似DOM Tree的数据结构,但是如果自己调用的话貌似有些问题,因为你需要首先清楚他们的数据结构。
貌似总共有大概232个判断条件?反正我尝试写了一个之后,果断放弃了,而是采用了 google/gumbo-parser · GitHub 。所以如果你感兴趣HTML的解析,可以参考Google的实现,自己写一个也是可以的,只不过要耐心点。Google Gumbo本身给你实现一个类似DOM Tree的数据结构,但是如果自己调用的话貌似有些问题,因为你需要首先清楚他们的数据结构。【本文地址】
今日新闻 |
推荐新闻 |