2021 年“泰迪杯”数据分析技能赛 B 题 肥料登记数据分析 |
您所在的位置:网站首页 › 泰迪杯选题经验 › 2021 年“泰迪杯”数据分析技能赛 B 题 肥料登记数据分析 |
2021 年“泰迪杯”数据分析技能赛 B 题 肥料登记数据分析
|
2021年“泰迪杯”数据分析技能
B题
肥料登记数据分析赛题*
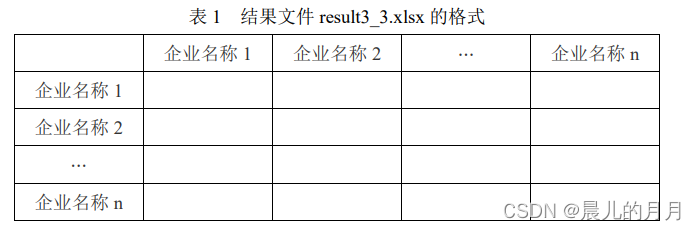
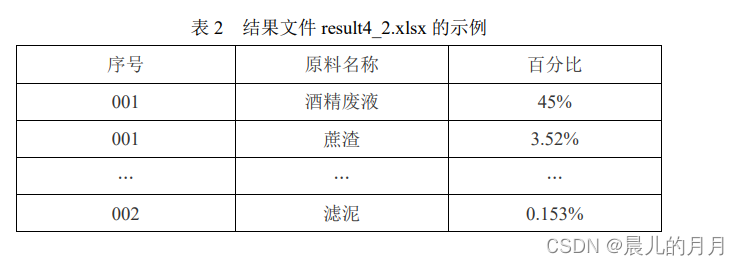
一、背景 肥料是农业生产中一种重要的生产资料,其生产销售必须遵循《肥料登记管 理办法》,依法在农业行政管理部门进行登记。各省、自治区、直辖市人民政府 农业行政主管部门主要负责本行政区域内销售的肥料登记工作,相关数据可从政 府网站上自由下载。 二、目标 对肥料登记数据进行预处理。根据养分的百分比对肥料产品进行细分。从省份、日期、生产商、肥料构成等维度对肥料登记数据进行对比分析。对非结构化数据进行结构化处理。三、任务 请根据附件 1~附件 4 中提供的数据,自行选择分析工具完成以下任务,并 撰写报告。 任务 1 数据的预处理 任务 1.1 附件 1 的产品通用名称存在不规范的情况。 请按照复混肥料(掺 混肥料归入这一类)、有机-无机复混肥料、有机肥料和床土调酸剂这 4 种类别 对附件 1 进行规范化处理。请在报告中给出处理思路、过程及必要的结果,同时 将完整的结果保存到文件**“result1_1.xlsx”**中。 import pandas as pd import numpy as np import datetime import re dfa= pd.read_excel('./附件1.xlsx') #首先查看有哪些产品通用名称 dfa['产品通用名称'].unique() #去除换行符和空白符 dfa['产品通用名称'] = dfa['产品通用名称'].str.strip('\n') strinfo = re.compile(' ') dfa['产品通用名称'] = dfa['产品通用名称'].apply(lambda x :strinfo.sub("",x)) #将掺混肥料替换为复混肥料 # 将稻苗床土调酸剂替换为床土调酸剂 # 将有机无机 复混肥料替换为有机无机-复混肥料 dfa['产品通用名称'] = dfa['产品通用名称'].replace('掺混肥料','复混肥料') dfa['产品通用名称'] = dfa['产品通用名称'].replace('稻苗床土调酸剂','床土调酸剂') dfa['产品通用名称'] = dfa['产品通用名称'].replace('有机无机 复混肥料','有机无机复混肥料') dfa['产品通用名称'] = dfa['产品通用名称'].replace('有机-无机复混肥料','有机-无机复混肥料') dfa['产品通用名称'] = dfa['产品通用名称'].replace('有机无机复混肥料','有机-无机复混肥料')查看处理后的产品通用名称 dfa["产品通用名称"].unique() time = '2021-3-8' time_ = '2021-3-17' dfa.iloc[2919:-1,-1] = pd.to_datetime(time)+datetime.timedelta(365*5) dfa.iloc[-1,-1] = pd.to_datetime(time_)+datetime.timedelta(365*5) # 用to_datetime规范化日期格式 dfa['有效期'] = pd.to_datetime(dfa['有效期'])任务 1.2 计算附件 1 中各肥料产品的氮、磷、钾养分百分比之和,称为总 无机养分百分比。请在报告中给出处理思路、过程及必要的结果,同时将完整的 结果保存到文件**“result1_2.xlsx”**中,结果保留 3 位小数(例如 1.0%,即 0.010)。 dfa['总无极养分百分比'] = (dfa['总氮百分比']+dfa['P2O5百分比']+dfa['K2O百分比'])*100 #保存结果 dfa.to_csv('./result1_2.xlsx',index=False,float_format='%.3f')任务 2 肥料产品的数据分析 任务 2.1 从附件 2 中筛选出复混肥料的产品,将所有复混肥料按照总无机 养分百分比的取值等距分为 10 组。根据每个产品所在的分组,为其打上分组标 签(标签用 1~10 表示),将完整的结果保存到文件**“result2_1.xlsx**”中。分析复 混肥料产品的分布特点,在报告中绘制产品登记数量的直方图,给出处理思路及 过程,并按登记数量从大到小列出登记数量最大的前 3 个分组及相应的产品登记 数量。 import pandas as pd import numpy as np import warnings warnings.filterwarnings('ignore') import matplotlib.pyplot as plt import matplotlib import seaborn as sns plt.rcParams['font.sans-serif'] =['Microsoft YaHei'] plt.rcParams['axes.unicode_minus'] = False from pyecharts import options as opts from pyecharts.charts import Bar,Timeline,Pie from pyecharts.globals import ThemeType from sklearn import cluster dfb= pd.read_excel('./附件2.xlsx') # 根据条件筛选出 条复混肥料数据 df= dfb[dfb['产品通用名称']=='复混肥料'] print('根据条件筛选出{}条复混肥料数据'.format(len(fh)))采取od.cut的方法 labels = [i for i in range(1,11)] df['总无机养分百分比'] = pd.cut(list(fh['总无机养分百分比']),10,labels=labels)结果为 #保存结果 df.to_excel('./result2/result2_1.xlsx',index=False)该任务需要分析复混肥料产品的特点:将广西和湖北的名称列出来再统计分析 gx_city = ['南宁','柳州','桂林','梧州','北海','钦州','贺州','河池','百色','来宾','崇左','玉林','防城港','贵港'] gx_num = [i for i in range(len(gx_city))] hb_city = ["武汉","黄石","襄阳","荆州","宜昌","十堰","孝感","荆门","鄂州","黄冈","咸宁","随州"] hb_num = [i for i in range(len(hb_city))] #统计广西的分布情况 for name in fh['企业名称']: for k in range(len(gx_city)): if gx_city[k] in name: gx_num[k] += 1 #统计湖北的分布情况 for name in fh['企业名称']: for k in range(len(hb_city)): if hb_city[k] in name: hb_num[k] += 1 print('在湖北总分布数{}'.format(sum(hb_num))) print('在广西总分布数{}'.format(sum(gx_num))) #在湖北总分布数583 #在广西总分布数654画出分布饼状图 fig1 , ax1 = plt.subplots() plt.title('附件2复混肥料分布情况') explode = [0,0.1] labels = ['湖北','广西'] colors = ['yellowgreen', 'gold'] ax1.pie(['583','654'],explode=explode,labels=labels,colors=colors,autopct='%1.1f%%',shadow=True,startangle=90) plt.savefig('附件2复混肥料分布情况.png') plt.show()画出分布柱状图 #分布柱状图 bar = ( Bar(init_opts=opts.InitOpts(width="600px")) .add_xaxis(gx_city) .add_yaxis('城市分布总数', gx_num) .set_global_opts(title_opts=opts.TitleOpts(title='广西复混肥料城市分布情况'), xaxis_opts=opts.AxisOpts(name='城市')) ) # bar.render('广西复混肥料城市分布情况.html') bar.render_notebook() 插入代码片 #分布柱状图 bar = ( Bar(init_opts=opts.InitOpts(width="800px")) .add_xaxis(hb_city) .add_yaxis('城市分布总数', hb_num) .set_global_opts(title_opts=opts.TitleOpts(title='湖北复混肥料城市分布情况'), xaxis_opts=opts.AxisOpts(name='城市')) ) # bar.render('湖北复混肥料城市分布情况.html') bar.render_notebook()绘制产品登记的数据直方图 data = df['总无机养分百分比'].value_counts() plt.title('各分组产品登记情况') plt.bar([i for i in range(1,11)],[3,0,0,373,1154,1470,2098,841,14,1],align='center',color='r',alpha=0.6) for a,b in zip([i for i in range(1,11)],[3,0,0,373,1154,1470,2098,841,14,1]): plt.text(a,b+0.05,'%.0f'%b,ha='center') plt.xlabel('分组标签') plt.ylabel('产品登记数量') # plt.savefig('各分组产品登记情况.png') plt.show()并按登记数量从大到小列出登记数量最大的前 3 个分组及相应的产品登记 data=fh["总无机养分百分比"].value_counts() data任务 2.2 从附件 2 中筛选出有机肥料的产品,将产品按照总无机养分百分 比和有机质百分比分别等距分为 10 组,并为每个产品打上分组标签 (1,1), (1,2), ⋯, (10,10),将完整的结果保存到文件“result2_2.xlsx”中。请在报告中给出处理 思路及过程,并根据分组情况绘制有机肥料产品的分布热力图,其中横轴代表总 无机养分分组,纵轴代表有机质分组。在此基础上,分析有机肥料产品的分布特 点,并按登记数量从大到小列出登记数量最大的前 3 个分组及相应的产品登记数 量。 d = dfb[dfb['产品通用名称']=='有机肥料'] # labels1 = [(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10)] d['总无机养分百分比'] = pd.cut(list(d['总无机养分百分比']),10,labels=[i for i in range(1,11)]) d['有机质百分比'] = pd.cut(list(d['有机质百分比']),10,labels=[i for i in range(1,11)]) #用元祖表示两组标签 tu = pd.DataFrame() tu['总无机养分百分比'] = d['总无机养分百分比'] tu['有机质百分比'] = d['有机质百分比'] tu = tu.apply(lambda x :tuple(x),axis=1) d['分组标签'] = tu保存结果 yj.to_excel('./result2/result2_2.xlsx',index=False)画出热力分布图 yj_list = [8,0,0,0,0,903,97,27,7,3] wj_list = [936,97,11,0,0,0,0,0,0,1] # plt.figure(figsize=(5,6)) ax = sns.heatmap(np.array([wj_list,yj_list])) ax.set_xticklabels([i for i in range(1,11)]) ax.set_yticklabels([i for i in range(1,11)]) plt.title('有机肥料产品分布热力图') plt.savefig('有机肥料产品分布热力图.png') plt.show()任务 2.3 从附件 2 中筛选出复混肥料的产品,按照氮、磷、钾养分的百分 比,使用聚类算法将这些产品分为 4 类。根据聚类结果为每个产品打上聚类标签 (标签用 1~4 表示),并将完整的结果保存到文件**“result2_3.xlsx**”中。请在报 告中给出处理思路及过程,根据聚类标签绘制肥料产品的三维散点图和散点图矩 阵,并通过绘制聚类结果的雷达图分析每个聚类的特征。 #筛选数据 new_fh = fh.iloc[:,4:7] #DBSCAN聚类 from sklearn.cluster import DBSCAN db = DBSCAN(eps=0.3, min_samples=10) db.fit(new_fh) DBSCAN(algorithm='auto', eps=0.3, leaf_size=40, metric='euclidean', metric_params=None, min_samples=10, n_jobs=4, p=None) label_db = db.labels_ new_fh['label'] = label_db # 计算轮廓系数 from sklearn import metrics metrics.silhouette_score(new_fh.iloc[:,:3],label_db, metric='euclidean') #euclidean欧几里得度量 #保存结果 new_fh.to_excel('./result2_3.xlsx',index=False)画出散点图 aa = pd.read_excel('./result2_3.xlsx') import seaborn as sns sns.pairplot(aa) # plt.savefig('散点矩阵图.png') plt.show()活出3D散点图 import random from pyecharts import options as opts from pyecharts.charts import Scatter3D from pyecharts.faker import Faker Scatter_data = [(aa['总氮百分比'][i],aa['P2O5百分比'][i],aa['K2O百分比'][i]) for i in range(len(aa))] piece=[ {'value': 0,'label': '1','color':'#e57c27'}, {'value': 1, 'label': '2','color':'#72a93f'}, {'value': 2, 'label': '3','color':'#368dc4'}, {'value': 3, 'label': '4','color':'pink'} ] scatter = ( Scatter3D(init_opts = opts.InitOpts(width='900px',height='600px')) #初始化 .add("",Scatter_data, grid3d_opts=opts.Grid3DOpts( width=100, depth=100, rotate_speed=10, is_rotate=True )) #设置全局配置项 .set_global_opts( title_opts=opts.TitleOpts(title="3D散点图"), visualmap_opts=opts.VisualMapOpts( pos_top=50 ) ) .render("3D散点图.html") )任务 3 肥料产品的多维度对比分析 任务 3.1 从文件**“result2_1.xlsx”**中提取发证日期中的年份,分析比较复混 肥料中各组别不同年份产品登记数量的变化趋势。请在报告中给出处理思路及分 析过程,使用合适的图表对结果进行可视化。 import pandas as pd import numpy as np import warnings warnings.filterwarnings('ignore') import matplotlib.pyplot as plt import matplotlib import seaborn as sns plt.rcParams['font.sans-serif'] =['Microsoft YaHei'] plt.rcParams['axes.unicode_minus'] = False from pyecharts import options as opts from pyecharts.charts import Bar,Timeline,Pie from pyecharts.globals import ThemeType import datetime data = pd.read_excel('result2_1.xlsx') # dt.year取出年份 data['年份'] = pd.to_datetime(data['发证日期']).dt.year data3_1 = data.groupby(['总无机养分百分比','年份'],as_index=False)['正式登记证号'].agg({'产品登记数量':'count'}) B = list(data3_1['总无机养分百分比'].unique()) for i in B: new_data = data3_1[data3_1['总无机养分百分比']==i] plt.title('组别{}各年份产品登记数量'.format(i)) plt.bar(new_data['年份'],new_data['产品登记数量'],align='center',color='r',alpha=0.6,width=0.5) for a,b in zip(new_data['年份'],new_data['产品登记数量']): plt.text(a,b+0.05,'%.0f'%b,ha='center') plt.plot(new_data['年份'],new_data['产品登记数量'],'o-',alpha=0.4,color='r') plt.xlabel('年份') plt.ylabel('产品登记数量(单位:个)') plt.savefig('组别{}各年份产品登记数量.png'.format(i)) plt.show()任务 3.2 从文件**“result2_2.xlsx**”中提取 2021 年 9 月 30 日仍有效的有机 肥料产品,将完整的结果保存到文件**“result3_2.xlsx”**中。从有效产品中分别筛 选出广西和湖北(根据正式登记证号区分)产品登记数量在前 5 的组别,分析两 个省份上述组别的分布差异。请在报告中给出处理过程及分析结果。 data3_2 = pd.read_excel('./result2_2.xlsx') data3_2['有效期'] = pd.to_datetime(data3_2['有效期']) #保存结果 data3_2[data3_2['有效期']'产品登记数量':'count'}) data_任务 3.3 从附件 3 中提取产品登记数量大于 10 的肥料企业,给出这些企业 所用到的原料集合(发酵菌剂除外)。以各企业用到的原料作为特征,计算企业 之间的杰卡德相似系数矩阵,并将结果(保留4位小数)保存到文件**“result3_3.xlsx”** 中(不提供模板文件,格式见表 1)。请在报告中给出处理思路、过程及相似系 数矩阵。 注 集合 𝐴 与 𝐵 的杰卡德相似系数定义为 𝐽(𝐴, 𝐵) = |𝐴∩𝐵| |𝐴∪𝐵| ,其中 |S| 表示 集合 𝑆 中元素的个数。 表 1 结果文件 result3_3.xlsx 的格式 计算相似系数矩阵 for i in name: value_list = [] for j in name: value = len(list(set(i).intersection(set(j))))/len(list(set(i).union(set(j))) ) #并集 value_list.append(value) print(value_list)任务 4 肥料产品的多维度对比分析 任务 4.1 设计算法或处理流程,从附件 4 技术指标中提取出氮、磷、钾养 分和有机质的百分比,以及肥料含氯的程度。请在报告中给出处理思路及过程, 并将结果保存到文件**“result4_1.xlsx”**中。 注 如果技术指标中只给出总养分百分比(“≥”按照“=”处理)而无明 细数据,则氮、磷、钾养分的百分比按照总百分比的 1/3 来计算,结果保留 3 位 小数(例如 1.0%,即 0.010)。复混肥料属于无机肥料,它的有机质百分比设定 为 0。含氯情况分为“无氯”、“低氯”、“中氯”和“高氯”4 种。如果肥料 产品的技术指标中没有给出含氯情况,则视为“无氯”;如果注明“含氯”,则 视为“低氯”。 任务 4.2 设计算法或处理流程,从附件 4 原料与百分比中提取各种原料的 名称及其百分比。请在报告中给出处理思路及过程,并将结果保存到文件 “result4_2.xlsx”中(参见表 2)。 四、数据说明 附件 1~附件 4 的数据收集自农业部门官方网站,部分数据细节与实际有差 别,仅供比赛使用。 附件 1 为安徽肥料登记数据,附件 2 为广西、湖北肥料登记数据。这两个附 件中表的主要字段有企业名称、产品通用名称、正式登记证编号、发证日期、有 效时间、产品形态、营养成分百分比、含氯情况等。其中产品通用名称实际上是 肥料产品的类型,需要在省级农业行政主管部门登记的肥料有复混肥料(包括掺 混肥料)、有机-无机复混肥料、有机肥料和床土调酸剂这 4 类。肥料的营养成 分百分比指标,通常标记出属于无机成分的氮、磷、钾的含量,以及有机质的含 量。我国规定,氮肥成分以总氮的质量来计算含量,磷肥成分按磷元素的量折算 成五氧化二磷(P2O5)的质量来计算含量,钾肥成分按钾元素的量折算成氧化钾 (K2O)的质量来计算含量。注意,肥料正式登记证有效期为 5 年,可以续期, 会出现有效期距发证日期大于 5 年的情况。 附件 3 给出了某省登记肥料的产品配方,相比附件 1 和附件 2 增加了关于肥 料原料的信息。 附件 4 给出了某省肥料登记数据中营养成分及原料构成的原始数据。字段技 术指标以字符串的形式给出了肥料的营养成分的百分比。例如某复混肥料的技术 指标字段取值为“N+P2O5+K2O≥20%(7-10-3) 有机质≥20% 含氯”,表示肥 料中氮磷钾三大元素的总养分含量不小于 20%;“(7-10-3)”指的是氮磷钾的 配比,氮含量为 7%,磷肥成分(折算为 P2O5)含量为 10%,钾肥成分(折算为 K2O)含量为 3%;“有机质≥20%”表示肥料中有机质的含量不小于 20%;“含 氯”表示肥料中含有氯元素。有机肥料由于不含无机养分或含量较少,有些产品 只在技术指标中标明“总养分≥…%”,没有给出氮、磷、钾 3 大元素的具体含 量。字段原料与百分比以字符串的形式给出了肥料的原料构成及质量百分比,例 如某有机肥料的原料与百分比字段取值为“糖蜜酒精废液 (占 25%),发酵菌种 (占 1%),木糠 (占 25%),滤泥 (占 49%)”,表明了该有机肥料由蜜糖酒精废液、 发酵菌种、木糠和滤泥四种原料构成,质量百分比分别是 25%、1%、25%及 49%。 注 本赛题中,不同的正式登记证号代表不同的产品。 五、关于竞赛成果提交的说明 1. 登录方式 请使用队长的账号登录数睿思网站(www.tipdm.org),进入第四届技能赛页 面(https://www.tipdm.org:10010/#/competition/1422385224767152128/introduce)。 为保证成功提交,请使用谷歌浏览器无痕模式。 2. 作品提交 报告以 PDF 格式提交,文件名为**“report.pdf”**,要求逻辑清晰、条理分 明,内容包括每个任务的完成思路、操作步骤、必要的中间过程、任务的结果 及分析。 3. 附件提交 3.1 如使用编程实现,将任务 1、2、3、4 的源程序分别保存到 “program1”,“program2”,“program3”,“program4”文件夹,然后存放 到“program”文件夹中。 3.2 将任务 1、2、3、4 所得到的结果文件存放到“result”文件夹中。 3.3 将程序文件夹“program”、结果文件夹“result”以及报告的 word 版本打包成“appendix.zip”,作为附件提交。 4. 提交界面 4.1 找到赛题提交入口。 4.3 选择需要上传的对应文件,点击“打开”。 4.4 进度条加载完成后会有“上传成功”提示。 |
 4.2 点击“点击上传”按钮。
4.2 点击“点击上传”按钮。 
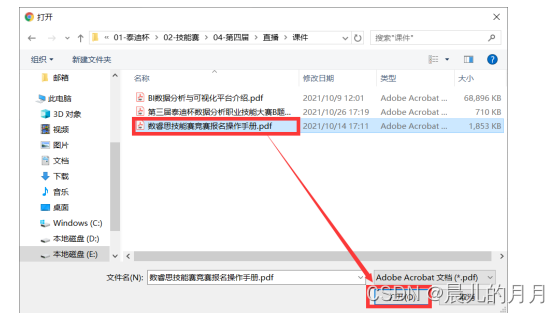
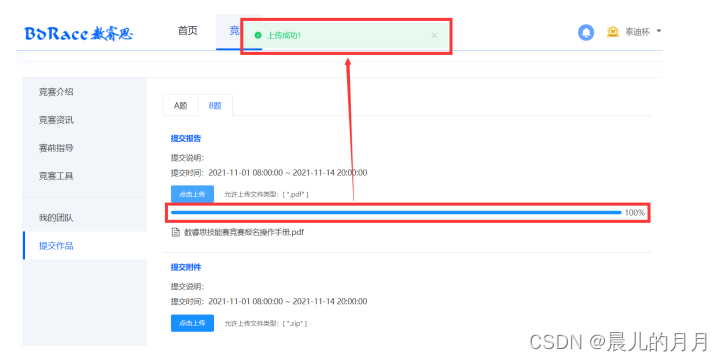 4.5 页面如下图即为上传提交成功,多次提交会以最后一次为准
4.5 页面如下图即为上传提交成功,多次提交会以最后一次为准 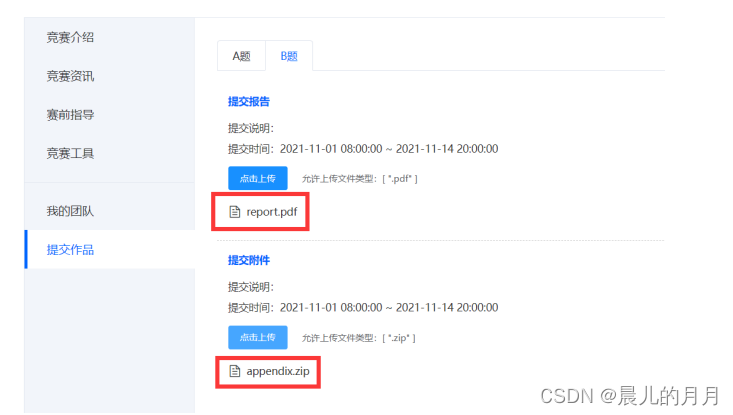
【本文地址】
今日新闻 |
推荐新闻 |