Kaggle泰坦尼克号比赛项目详解 |
您所在的位置:网站首页 › 泰坦尼克号的姐妹是什么号 › Kaggle泰坦尼克号比赛项目详解 |
Kaggle泰坦尼克号比赛项目详解
Kaggle泰坦尼克号比赛项目详解
项目背景目标数据字典一、基础字段二、衍生字段(部分,在后续代码中补充)
特征工程特征分析一、导入必要库二、导入数据三、查看数据四、查看字段信息五、查看字段统计数据六、查看船舱等级与幸存量的关系七、查看性别与幸存情况的关系八、查看乘客年龄与幸存情况的关系九、查看兄弟姐妹及配偶数量与幸存情况关系十、查看父母与孩子数量与幸存情况的关系十一、查看不同票价对应与幸存情况的关系
特征清洗1.NameLength (名字长度)2.HasCabin(是否有船舱)3.Title 称号字段4.sex 性别字段5.Age 年龄字段6. IsChildren (是否为儿童)7.FamilySize (将兄弟姐妹或配偶总数以及父母或孩子总数合并成一个特征)8.IsAlone (是否为单独一人)9.Embarked (港口因素)9.Fare (票价)10.特征相关性可视化
建模和优化1.逻辑回归2.SVC(支持向量机)3.KNN(K近邻分类算法)4.GNB(贝叶斯分类算法)5.Perceptron模型6.Linear SVC7.SGD模型8.决策树模型9.随机森林算法10.kfold交叉验证模型
模型效果比较保存结果1.保存随机森林模型预测结果2.保存决策树模型预测结果3.保存KNN模型预测结果4.保存SVC(支持向量机模型)预测结果5.保存SGD模型预测结果6.保存Linear SVC模型预测结果7.保存逻辑回归模型预测结果
结果文件
 数据链接:
https://pan.baidu.com/s/1gE4JvsgK5XV-G9dGpylcew
提取码:y409
项目背景
数据链接:
https://pan.baidu.com/s/1gE4JvsgK5XV-G9dGpylcew
提取码:y409
项目背景
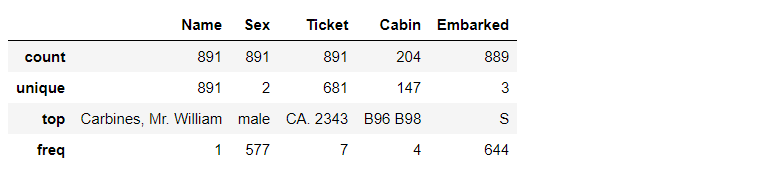
1、泰坦尼克号:英国白星航运公司下辖的一艘奥林匹克级邮轮,于1909年3月31日在爱尔兰贝尔法斯特港的哈兰德与沃尔夫造船厂动工建造,1911年5月31日下水,1912年4月2日完工试航。 2、首航时间:1912年4月10日 3、航线:从英国南安普敦出发,途经法国瑟堡-奥克特维尔以及爱尔兰昆士敦,驶向美国纽约。 4、沉船:1912年4月15日(1912年4月14日23时40分左右撞击冰山) 船员+乘客人数:2224 5、遇难人数:1502(67.5%) 目标根据训练集中各位乘客的特征及是否获救标志的对应关系训练模型,预测测试集中的乘客是否获救。(二元分类问题) 数据字典 一、基础字段PassengerId 乘客id: 训练集891(1- 891),测试集418(892 - 1309) Survived 是否获救: 1=是,0=不是 获救:38% 遇难:62%(实际遇难比例:67.5%) Pclass 船票级别: 代表社会经济地位。 1=高级,2=中级,3=低级 1 : 2 : 3 = 0.24 : 0.21 : 0.55 Name 姓名: 示例:Futrelle, Mrs. Jacques Heath (Lily May Peel) 示例:Heikkinen, Miss. Laina Sex 性别: male 男 577,female 女 314 男 : 女 = 0.65 : 0.35 Age 年龄(缺少20%数据): 训练集:714/891 = 80% 测试集:332/418 = 79% SibSp 同行的兄弟姐妹或配偶总数: 68%无,23%有1个 … 最多8个 Parch 同行的父母或孩子总数: 76%无,13%有1个,9%有2个 … 最多6个 Some children travelled only with a nanny, therefore parch=0 for them. Ticket 票号(格式不统一): 示例:A/5 21171 示例:STON/O2. 3101282 Fare 票价: 测试集缺一个数据 Cabin 船舱号: 训练集只有204条数据,测试集有91条数据 示例:C85 Embarked 登船港口: C = Cherbourg(瑟堡)19%, Q = Queenstown(皇后镇)9%, S = Southampton(南安普敦)72% 训练集少两个数据 二、衍生字段(部分,在后续代码中补充)Title 称谓: dataset.Name.str.extract( “ ([A-Za-z]+).”, expand = False) 从姓名中提取,与姓名和社会地位相关 FamilySize 家庭规模: Parch + SibSp + 1 用于计算是否独自出行IsAlone特征的中间特征,暂且保留 IsAlone 独自一人: FamilySize == 1 是否独自出行 HasCabin 有独立舱室: 不确定没CabinId的样本是没有舱室还是数据确实 特征工程Classifying: 样本分类或分级 Correlating: 样本预测结果和特征的关联程度,特征之间的关联程度 Converting: 特征转换(向量化) Completing: 特征缺失值预估完善、 Correcting: 对于明显离群或会造成预测结果明显倾斜的异常数据,进行修正或排除 Creating: 根据现有特征衍生新的特征,以满足关联性、向量化以及完整度等目标上的要求 Charting: 根据数据性质和问题目标选择正确的可视化图表 特征分析 一、导入必要库 # 导入库 # 数据分析和探索 import pandas as pd import numpy as np import random as rnd # 可视化 import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline # 消除警告 import warnings warnings.filterwarnings('ignore') # 机器学习模型 # 逻辑回归模型 from sklearn.linear_model import LogisticRegression # 线性分类支持向量机 from sklearn.svm import SVC, LinearSVC # 随机森林分类模型 from sklearn.ensemble import RandomForestClassifier # K近邻分类模型 from sklearn.neighbors import KNeighborsClassifier # 贝叶斯分类模型 from sklearn.naive_bayes import GaussianNB # 感知机模型 from sklearn.linear_model import Perceptron # 梯度下降算法 from sklearn.linear_model import SGDClassifier # 决策树模型 from sklearn.tree import DecisionTreeClassifier 二、导入数据 # 获取数据,训练集train_df,测试集test_df train_df = pd.read_csv('E:/PythonData/titanic/train.csv') test_df = pd.read_csv('E:/PythonData/titanic/test.csv') combine = [train_df, test_df]将train_df和test_df合并为combine(便于对特征进行处理时统一处理:for df in combine:) 三、查看数据 # 探索数据 # 查看字段结构、类型及head示例 train_df.head()
1. 创建船舱等级与生存量列联表 #生成Pclass_Survived的列联表 Pclass_Survived = pd.crosstab(train_df['Pclass'], train_df['Survived'])
1.创建性别与生存量列联表 #生成性别与生存列联表 Sex_Survived = pd.crosstab(train_df['Sex'],train_df['Survived'])
1.处年年龄缺失情况(用中位数数代替缺失数据) # 用年龄的中位数代替年龄缺失值 Agemedian = train_df['Age'].median() #在当前表填充缺失值 train_df.Age.fillna(Agemedian, inplace = True) #重置索引 train_df.reset_index(inplace = True)2.对年龄进行分组,绘制年龄与幸存数量条形图 #对Age进行分组: 2**10>891分成10组, 组距为(最大值80-最小值0)/10 =8取9 bins = [0, 9, 18, 27, 36, 45, 54, 63, 72, 81, 90] train_df['GroupAge'] = pd.cut(train_df.Age, bins) GroupAge_Survived = pd.crosstab(train_df['GroupAge'], train_df['Survived']) GroupAge_Survived.plot(kind = 'bar',figsize=(10,6)) plt.xticks(rotation=360) plt.title('Survived status by GroupAge')
1.创建兄弟姐妹及配偶数量与生存量列联表 # 生成列联表 SibSp_Survived = pd.crosstab(train_df['SibSp'], train_df['Survived']) SibSp_Survived
1.创建父母与孩子数量与生存量列联表 创建列联表 Parch_Survived = pd.crosstab(train_df['Parch'], train_df['Survived']) Parch_Survived
1.划分船票价格,创建不同船票对应生存量列联表 #对Fare进行分组: 2**10>891分成10组, 组距为(最大值512.3292-最小值0)/10取值60 bins = [0, 60, 120, 180, 240, 300, 360, 420, 480, 540, 600] train_df['GroupFare'] = pd.cut(train_df.Fare, bins, right = False) GroupFare_Survived = pd.crosstab(train_df['GroupFare'], train_df['Survived']) GroupFare_Survived
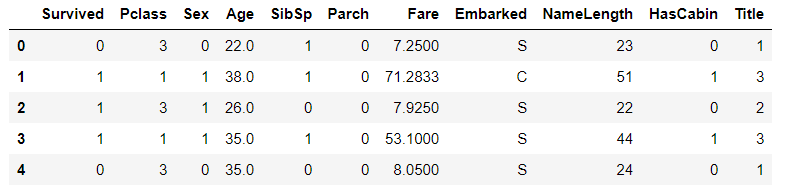
注:这里解释一下Kaggle作者使用名称字段作为特征之一,原因在于姓名里带有该乘客的头衔,名字长度越长对应的头衔越多。即相对应的社会地位较高。 2.HasCabin(是否有船舱)将乘客是否有船舱归为两类 # 使用匿名函数,NaN为浮点型,为浮点型的为0,否则为1(即没有船舱的为0,有船舱的为1) train_df['HasCabin'] = train_df["Cabin"].apply(lambda x: 0 if type(x) == float else 1) test_df['HasCabin'] = test_df["Cabin"].apply(lambda x: 0 if type(x) == float else 1) train_df.head()
删除Ticket和Cabin字段,原因在于Ticket字段表示船票的名称。与乘客的生存率无关联。删除Cabin是因为通过HasCabin来代替Cabin字段。 # 剔除Ticket(人为判断无关联)和Cabin(有效数据太少)两个特征 train_df = train_df.drop(["Ticket","Cabin"],axis=1) test_df = test_df.drop(["Ticket","Cabin"],axis=1) combine = [train_df,test_df] print(train_df.shape,test_df.shape,combine[0].shape,combine[1].shape)
绘制不同称号对应的存活率 # 按Title汇总计算Survived均值,查看相关性 T_S = train_df[["Title","Survived"]].groupby(["Title"],as_index=False).mean().sort_values(by='Survived',ascending=True) plt.figure(figsize=(10,6)) plt.bar(T_S['Title'],T_S['Survived'])
将Title特征映射成数值 title_mapping = {"Mr":1,"Miss":2,"Mrs":3,"Master":4,"Rare_Female":5,"Rare_Male":6} for dataset in combine: dataset["Title"] = dataset["Title"].map(title_mapping) dataset["Title"] = dataset["Title"].fillna(0) # 为了避免有空数据的常规操作 train_df.head()
将性别字段转换成数值,将女性设置为0,男性设置为1 # sex特征映射为数值 for dataset in combine: dataset["Sex"] = dataset["Sex"].map({"female":1,"male":0}).astype(int) # 后面加astype(int)是为了避免处理为布尔型? train_df.head()
将年龄小于等于12的视为儿童,其余的为非儿童。分别用1,0来表示 #创建是否儿童特征 for dataset in combine: dataset.loc[dataset["Age"] > 12,"IsChildren"] = 0 dataset.loc[dataset["Age"] |




 2.绘制船舱等级与生存量条形图
2.绘制船舱等级与生存量条形图 3.查看不同船舱等级生存率条形图
3.查看不同船舱等级生存率条形图 分析: 1,2,3分别表示1等,2等,3等船舱等级。富人和中等阶层有更高的生还率,底层生还率低。
分析: 1,2,3分别表示1等,2等,3等船舱等级。富人和中等阶层有更高的生还率,底层生还率低。 2.绘制性别与生存量条形图
2.绘制性别与生存量条形图 3.不同性别与生存率表格如下:
3.不同性别与生存率表格如下: 分析:性别和是否生还强相关,女性用户的生还率明显高于男性。
分析:性别和是否生还强相关,女性用户的生还率明显高于男性。 3.绘制不同年龄对应生存率折线图
3.绘制不同年龄对应生存率折线图 分析:年龄段在0-9以及72-81岁时,对应的幸存率较高。说明在逃生时老人小孩优先。但63-72对应的幸存率是最低,猜测时对应年龄段的人数太少导致。
分析:年龄段在0-9以及72-81岁时,对应的幸存率较高。说明在逃生时老人小孩优先。但63-72对应的幸存率是最低,猜测时对应年龄段的人数太少导致。 2.绘制兄弟姐妹及配偶数量与生存量条形图
2.绘制兄弟姐妹及配偶数量与生存量条形图 3.绘制兄弟姐妹及配偶数量与存活率折线图
3.绘制兄弟姐妹及配偶数量与存活率折线图 分析:兄弟姐妹与配偶数量从在1-2时对应的生存率较高,其他相对较低。
分析:兄弟姐妹与配偶数量从在1-2时对应的生存率较高,其他相对较低。 2.绘制父母与孩子数量与生存量柱状图
2.绘制父母与孩子数量与生存量柱状图 3.绘制父母与孩子数与存活率折线图
3.绘制父母与孩子数与存活率折线图 分析:父母与孩子数在1-3时对应的生存率较高,其他相对较低
分析:父母与孩子数在1-3时对应的生存率较高,其他相对较低 2.绘制不同船票价格对应幸存量簇状柱形图
2.绘制不同船票价格对应幸存量簇状柱形图
 3.绘制不票价对应生存率折线图
3.绘制不票价对应生存率折线图 分析:票价在120-180以及480-540时对应的生存率较高,且票价与生存率总体上呈正相关趋势。
分析:票价在120-180以及480-540时对应的生存率较高,且票价与生存率总体上呈正相关趋势。 移除index,GroupAge,GroupFare等字段
移除index,GroupAge,GroupFare等字段
 删除Ticket和Cabin
删除Ticket和Cabin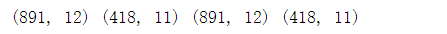
 将不同称号的乘客进行归类
将不同称号的乘客进行归类 分析:称号为Miss、Mrs、Rare_Female乘客的存活率居高,说明在逃生时,大家遵循女士优先的原则。
分析:称号为Miss、Mrs、Rare_Female乘客的存活率居高,说明在逃生时,大家遵循女士优先的原则。 删除姓名字段
删除姓名字段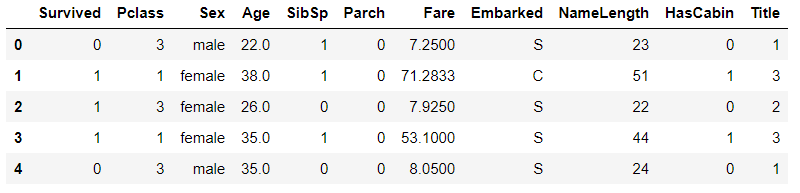
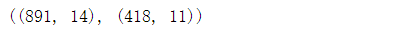
 对年龄字段进行空值处理(使用相同Pclass和Title的Age中位数来填充)
对年龄字段进行空值处理(使用相同Pclass和Title的Age中位数来填充)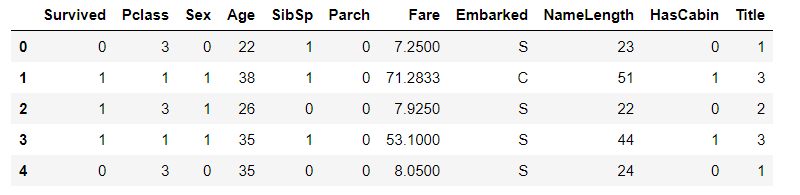
【本文地址】