kaggle泰坦尼克号生存预测(附代码、数据集和答案) |
您所在的位置:网站首页 › 泰坦尼克号情头欧美情头 › kaggle泰坦尼克号生存预测(附代码、数据集和答案) |
kaggle泰坦尼克号生存预测(附代码、数据集和答案)
|
kaggle泰坦尼克号生存预测(附代码、数据集和答案)
之前总结的数据预处理方法:https://blog.csdn.net/qq_43012160/article/details/98462307 先看一下数据集: 显然这次的特征是有缺失值的,读入数据集,看一下训练集和测试集的长度及各特征的缺失情况: 发现最后有一个空白的特征列,多半是数据集存储的时候格式出了问题,把数据集的目录打出来看一下,果然,换行符\r被当作一个单独的列读了进来,后面要删掉: 观察数据,首先船舱号Cabin的缺失值太多了,缺失80%左右,这样有两种选择: 一是给所有的缺失值补上记号UNKOWN作为缺失标记, 二是直接删掉这一列。 出于船舱号本身较为复杂、难以分析且考虑到降维的需要,这里选择直接删掉Cabin. 训练集有两个特征会有缺失值,一个是登船地点Embarked,另一个是年龄Age。总共占训练集的20%左右, 对于训练集可以认为,在缺失数据不很多的情况下,存在缺失值的样本即坏样本,可以直接抛弃: #训练集有缺失的都是坏数据,删了: train_data.dropna(axis=0,inplace=True) trainLen=len(train_data) testLen=len(test_data) 测试集缺失值的处理测试集因为需要预测,有缺失值就不能删了,对于确实不多的Fare列,我看了一下测试集和训练集数据的分布,在8左右有一个很明显的众数,所以就用测试集的众数来填补Fare的缺失值: #处理一下测试集里的缺失值,测试集的缺失数据不能删 #处理Fare,先看一下分布,发现明显有个众数非常突出,且训练集和测试集众数接近: test_data['Fare']=test_data['Fare'].fillna(test_data['Fare'].dropna().mode()[0])由于Age是比较重要的数据(从后面的相关系数也可以看出),我们利用训练集和测试集中的其他特征对缺失的Age进行预测,然后补全。 在预测Age之前,先对数据进行编码和归一化。 编码和归一化考虑到数据间的量纲问题,对数据进行编码和归一化: #把训练集和测试集合起来编码: combineData=train_data.append(test_data) #先编码后拆分: def getReview(data,changeColumns): ResultReview=[] listReview=data le = LabelEncoder() for column in changeColumns: listData=[] for review in data[column]: listData.append(review) listReview[column]=le.fit_transform(listData) #向量化(需要一个个的append): for i in range(len(data)): rowVec=[] for j in range(0,len(data.columns)): rowVec.append(listReview.iloc[i,j]) ResultReview.append(rowVec) return ResultReview changeColumns=['Sex','Embarked'] combine_Review=np.array(getReview(combineData,changeColumns)) scl = MinMaxScaler() combineReview=scl.fit_transform(combine_Review) trainReview=combineReview[0:trainLen] testReview=combineReview[trainLen:trainLen+testLen]之前一直有一个误区,就是会把训练集和测试集分开编码,其实这样是不对的,至少对于fit过程测试集和训练集是一定要在一起fit的,不然可能会出现这种情况; 训练集:[2,2,3]->编码:2为0;3为1 测试集:[3,3,2]->编码:3为0;2为1 即两者可能会采取不同的编码方式,导致正确率下降。 所以应该把测试集和训练集合在一起作为“词袋”一起训练编码器,然后在分开编码,或者先合在一起编码之后再拆开。 预测Age由于是预测Age,所以我们可以将训练集和测试集中所有Age不为空的样本作为训练集,来预测Age为空的样本。Age的预测不是一个分类问题,而是一个回归问题,所以要用回归器而不是分类器进行预测,这里选择GradientBoostingRegressor和MLPRegressor进行预测之后取平均,重复三次之后再取平均作为最终Age的预测结果。 #处理Age缺失值: #获取空元素下标: isNull=test_data['Age'].isnull().get_values() listAgeTrain=[] listAgeTest=[] for elem in trainReview:listAgeTrain.append(elem) for i in range(0,len(isNull)): if isNull[i]==False:listAgeTrain.append(testReview[i]) else: listAgeTest.append(testReview[i]) ageTrain = np.array(listAgeTrain) ageTest=np.array(listAgeTest) ageLable=ageTrain[:,2] ageTrain=np.delete(ageTrain,2,axis=1) ageTest=np.delete(ageTest,2,axis=1) #预测Age: print('预测测试集Age:') model1 = GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None, learning_rate=0.03, loss='huber', max_depth=15, max_features='sqrt', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=10, min_samples_split=40, min_weight_fraction_leaf=0.0, n_estimators=300, presort='auto', random_state=10, subsample=0.8, verbose=0, warm_start=False)#创建mlp神经网络对象 model2=MLPRegressor(activation='tanh', learning_rate='adaptive') age_sum = [] for i in range(0,3): print(i,'th training:') model1.fit(ageTrain,ageLable)#模型训练 age_model1 = model1.predict(ageTest)#模型预测 model2.fit(ageTrain,ageLable)#模型训练 age_model2 = model2.predict(ageTest)#模型预测 age_sum.append(age_model1*0.5+age_model2*0.5) age_model=[] for i in range(len(ageTest)): asum=0 for j in range(0,3): asum=asum+age_sum[j][i] age_model.append(asum/3) print(age_model) #把求出来的age填回去: #先把空值的位置找出来: nullIndex=[] for i in range(0,len(isNull)): if isNull[i]==True:nullIndex.append(i) for i in range(0,len(nullIndex)): testReview[nullIndex[i],2]=age_model[i] 去除离群点这里使用一个简单的基于概率分布的去除离群点的方法,即将各个特征的首尾部分的数据去掉,砍头去尾。 这里就要谈到我对高维离群点的一些思考,多维空间中的离群点必然具备一个条件,即他会有至少一维大大偏离其他数据。即有至少一维大大偏离其他数据是点是离群点的必要不充分条件,因此在。程序中当某一个样本的任意特征属于前后6%,就会被删掉。这里的6%是我调参调出来的,一般在1%-5%左右: #去除离群点: rowLen=trainReview.shape[1] shallDel=[] for i in range(0,len(trainReview)):shallDel.append(0) for j in range(0,rowLen): min=np.percentile(trainReview[:,j],6) max = np.percentile(trainReview[:, j], 94) for i in range(0, len(trainReview)): if (trainReview[i,j]max):shallDel[i]=1 for i in range(len(trainReview)-1,-1,-1): if shallDel[i]==1: trainReview=np.delete(trainReview,i,axis=0) trainLable = np.delete(trainLable, i, axis=0) 相关系数和方差看一下剩下的各组数据和Survived标签的相关系数,常用的三大相关系数是pearson相关系数、kendall相关系数和spearman相关系数,pearson相关系数更多的是反应线性关系,在面对形如y=x^2这种非线性关系的时候表现得差强人意,经过测试发现kendall相关系数的表现是很不错的。 当然你也可以看一下各特征和Age的相关系数,或者特征的方差,然后做一下特征筛选: 值得注意的是方差也好、相关系数也好,只能作为特征和结果关系的一个参考。并不是说相关系数高就一定有关,相关系数低就一定无关,放一下我写的测试程序: import pandas as pd import math x=[] y=[] for i in range(1,101): x.append(i) y.append(math.log(i**2+math.log(i**0.5+40*i))+i**2+i**6+i**math.log(i**math.sqrt(2*i))) print(pd.Series(x).corr(pd.Series(y),method='pearson')) print(pd.Series(x).corr(pd.Series(y),method='kendall')) print(pd.Series(x).corr(pd.Series(y),method='spearman'))运行结果,可以发现kendall确实优秀: 可以发现结果一下就差了许多: 选用逻辑回归算法: print('建模:') model =LogisticRegression() model.fit(trainReview, trainLable) print('预测:') pred_model = model.predict(testReview) score = metrics.accuracy_score(testLable, pred_model) matrix = metrics.confusion_matrix(testLable, pred_model) print('>>>准确率\n', score) print('\n>>>混淆矩阵\n', matrix)结果(人生巅峰): 代码、数据集和答案集: 链接:https://pan.baidu.com/s/1HkE_91neYHtN5EfftnLFeg 提取码:v3l5 |
 这次需要分类的标签被存储在了训练集的Survived列里,1表示生还,0表示遇难。
这次需要分类的标签被存储在了训练集的Survived列里,1表示生还,0表示遇难。


 PassengerId肯定是和结果没关系的,删掉 Ticket票号和Cabin一样情况复杂难以分析,删掉 Name比较特殊,他其中是有一些有用的信息的,比如Mr和Mrs就蕴含了性别信息,而诸如master之类的尊称又可以反映社会地位(一定程度上和船舱号、消费等有关),因而其实是可以保留的。但是以来分析起来比较复杂,二来其携带的性别、社会地位、消费能力等信息可以从Sex、Fare等特征中得到反映,所以这里选择直接删掉。
PassengerId肯定是和结果没关系的,删掉 Ticket票号和Cabin一样情况复杂难以分析,删掉 Name比较特殊,他其中是有一些有用的信息的,比如Mr和Mrs就蕴含了性别信息,而诸如master之类的尊称又可以反映社会地位(一定程度上和船舱号、消费等有关),因而其实是可以保留的。但是以来分析起来比较复杂,二来其携带的性别、社会地位、消费能力等信息可以从Sex、Fare等特征中得到反映,所以这里选择直接删掉。
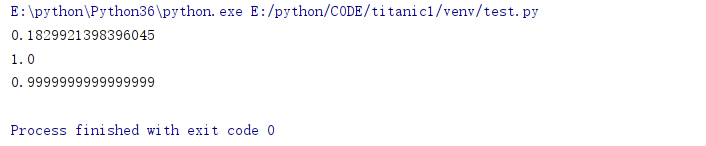 然而如果我在函数关系式里加入三角函数:
然而如果我在函数关系式里加入三角函数: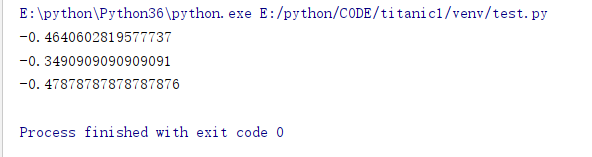 所以方差也好、相关系数也好,只能作为特征和结果关系的一个参考。并不是说相关系数高就一定有关,相关系数低就一定无关。每个特征,特别是这种处理、脱敏后数据集的特征,都是含有信息的,如果不是降维或者可视化的迫切需要,最好还是不要乱删数据。 前几天打了一下阿里天池的蒸汽预测·,就是降维降猛了,不太理想。 当然你也可以用PCA降维。 考虑到被我东删西删,现在就剩7维了,虽然Age的数据不太好看,也就不删了。
所以方差也好、相关系数也好,只能作为特征和结果关系的一个参考。并不是说相关系数高就一定有关,相关系数低就一定无关。每个特征,特别是这种处理、脱敏后数据集的特征,都是含有信息的,如果不是降维或者可视化的迫切需要,最好还是不要乱删数据。 前几天打了一下阿里天池的蒸汽预测·,就是降维降猛了,不太理想。 当然你也可以用PCA降维。 考虑到被我东删西删,现在就剩7维了,虽然Age的数据不太好看,也就不删了。 这里有另一篇博文讲的比较详细,后面打算按他的方法复现一遍,然后做个对比: https://tianchi.aliyun.com/notebook-ai/detail?spm=5176.12282042.0.0.1dce2042NBc6J6&postId=6772
这里有另一篇博文讲的比较详细,后面打算按他的方法复现一遍,然后做个对比: https://tianchi.aliyun.com/notebook-ai/detail?spm=5176.12282042.0.0.1dce2042NBc6J6&postId=6772【本文地址】
今日新闻 |
推荐新闻 |