泰勒公式 |
您所在的位置:网站首页 › 泰勒展开如何确定阶数 › 泰勒公式 |
泰勒公式
|
一、概念
1.一句话概括泰勒展开式: 用多项式去无限逼近一个函数,就是将某个函数在一个点上泰勒展开。 泰勒级数是把一个函数展开,化成次方项相加的形式,目的是用相对简单的函数去拟合复杂函数,此时相对简单是看你需要的,一阶指展开的次数最高为1,二阶指展开次数最高为2。 泰勒公式的几何意义是利用多项式函数来逼近原函数,由于多项式函数可以任意次求导,易于计算,且便于求解极值或者判断函数的性质,因此可以通过泰勒公式获取函数的信息,同时,对于这种近似,必须提供误差分析,来提供近似的可靠性。
2.为什么需要展开?(泰勒展开有什么用?) a.方便求一些函数值,因为泰勒展开是多项式,而多项式的值一般都很好求,只要代入变量,就可求出因变量。而很多函数的函数值很难求,例如sinx,lnx这类的。 b.方便计算,简化问题:
3.泰勒公式的余项 泰勒公式的余项有两类:一类是定性的皮亚诺余项,另一类是定量的拉格朗日余项。这两类余项本质相同,但是作用不同。一般来说,当不需要定量讨论余项时,可用皮亚诺余项(如求未定式极限及估计无穷小阶数等问题);当需要定量讨论余项时,要用拉格朗日余项(如利用泰勒公式近似计算函数值) 二、应用1.一阶泰勒展开 梯度下降法和一阶泰勒展开 泰勒展开就包含了梯度,从梯度的定义(方向导数最大)出发就可以得出优化方向:负梯度,这个有手推公式,下次补上。 顺便提一嘴:为什么要用梯度下降? 在机器学习领域中,建模需要loss损失函数,模型越优,loss越小,函数求导=0找极值。 机器学习中,有两种求极值的办法,一种是解析解,一种是梯度下降(特征维度超多时,如one-hot后用) 当你建模的特这个x的维度特别大,超过1000维度,那么解析解计算就很费事,所以借助梯度下降来牺牲时间 换空间的方式来计算,得到一个近似解 那为什么梯度下降就可以使得我这个x越来越靠近极值点,为什么不朝着其他的方向尽进行下降, 重点:梯度下降具有最快下降到极值点的性能。具有最快的下降速度 这个就用到一阶泰勒展开
2.二阶泰勒展开 xgboost和二阶泰勒,以及二阶泰勒的优势 因为这样做使得我们可以很清楚地理解整个目标是什么,并且一步一步推导出如何进行树的学习。这一个抽象的形式对于实现机器学习工具也是非常有帮助的。传统的GBDT可能大家可以理解如优化平法残差,但是这样一个形式包含可所有可以求导的目标函数。 xgboost使用二阶泰勒展开的目的和优势有一下两方面: 1、xgboost是以mse为基础推导出来的,在mse的情况下,xgboost的目标函数展开就是一阶项+二阶项的形式,而其他类似logloss这样的目标函数不能表示成这种形式。为了后续推导的统一,所以将目标函数进行二阶泰勒展开,就可以直接自定义损失函数了,只要二阶可导即可,增强了模型的扩展性。 2、二阶信息能够让梯度收敛的更快,类似牛顿法比SGD收敛更快。一阶信息描述梯度变化方向,二阶信息可以描述梯度变化方向是如何变化的。 二阶泰勒展开的优势是相对于一阶而言的,和牛顿方法相对于梯度下降类似,都是为了更准确的找到最优解,重点。 |
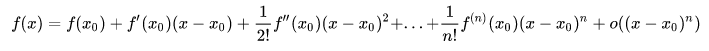
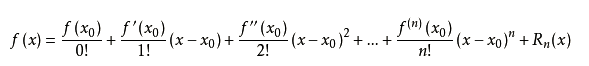


【本文地址】