ResNet与注意力机制完美结合!11个创新方案让模型性能倍增 |
您所在的位置:网站首页 › 注意力的衰减模型 › ResNet与注意力机制完美结合!11个创新方案让模型性能倍增 |
ResNet与注意力机制完美结合!11个创新方案让模型性能倍增
|
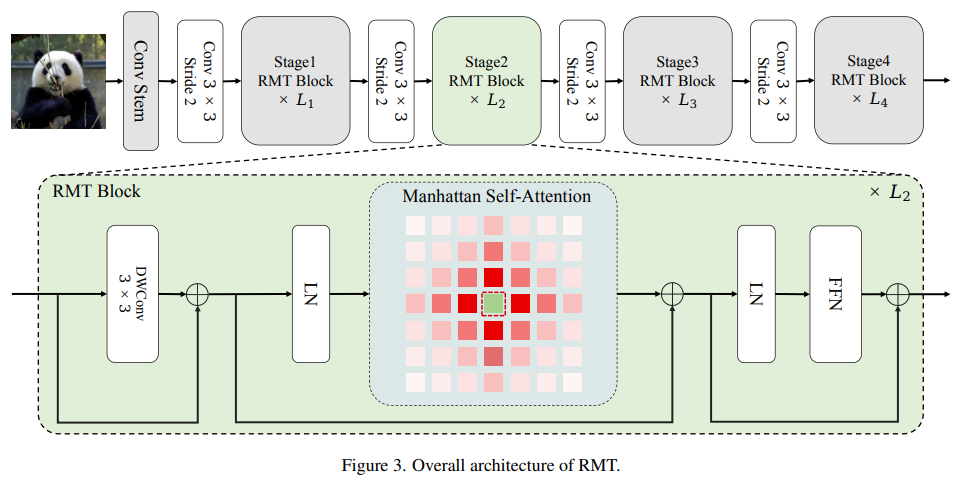
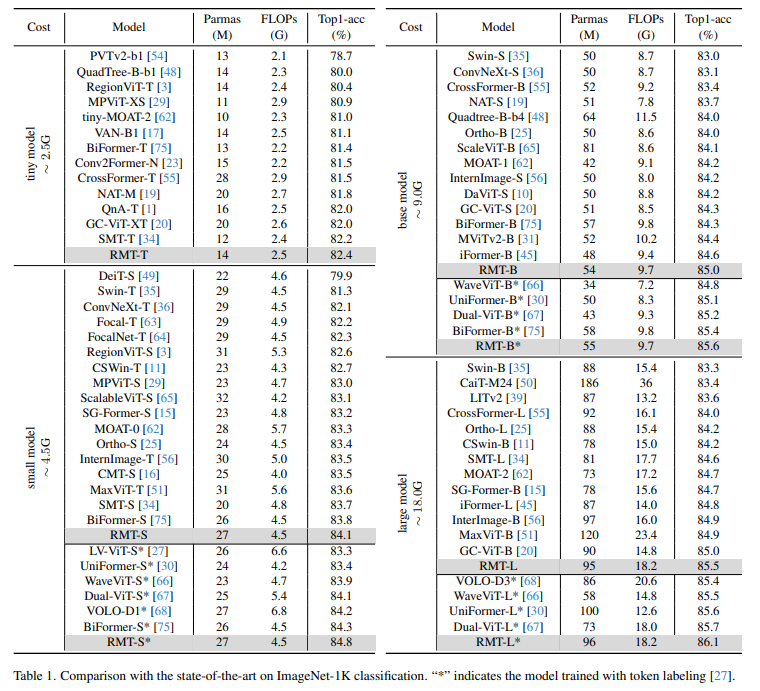
残差网络(ResNet)结合注意力机制可以在保持网络深度的同时,提高模型对任务相关特征的识别和利用能力,以及对关键信息的捕捉能力。 具体来说,结合的方式通常是在ResNet的基础上添加注意力模块。这些模块(自注意力机制/通道注意力机制)通过对特征图进行分析,为不同的特征或特征通道分配不同的权重,从而突出重要的信息并抑制不重要的信息。 这种结合策略不仅能够提高模型的性能,还能让模型更加专注于数据的关键部分,从而提高模型的解释性和泛化能力。因此,ResNet结合注意力机制已经成为深度学习领域的一个研究热点。 本文整理了11种ResNet+注意力机制创新方案,每种方案可参考的方法以及创新点我也做了简单介绍,希望能给各位的论文添砖加瓦。 论文原文以及开源代码需要的同学看文末 RMT RMT: Retentive Networks Meet Vision Transformers方法:论文提出一种新的视觉骨干网络(RMT),该网络通过引入显式的空间先验和注意力分解形式来改进自注意机制的性能。作者还引入了本地上下文增强模块,进一步提升了MaSA的局部表达能力。
创新点: 将RetNet的时间衰减机制扩展到空间领域,开发了基于曼哈顿距离的二维双向空间衰减矩阵,为图像数据引入了明确的空间先验。 提出了一种适应明确空间先验的注意力分解形式,以减轻全局建模的计算负担,同时不破坏空间衰减矩阵。 引入了MaSA(曼哈顿自注意力)机制,通过分解自注意力和空间衰减矩阵,以线性复杂度稀疏地建模全局信息,并提供比其他自注意力机制更丰富的空间先验。
方法:论文引入了一种创新的残余注意力视觉变换器(ReViT)网络,通过将残余注意力学习整合到视觉变换器(ViT)架构中,来增强对视觉特征的提取。该方法有效地传输和累积来自查询和键的注意力信息,跨越连续的多头自注意力(MHSA)层。这种残余连接防止了低级视觉特征的减少。此外,它通过减缓注意力机制的全球化,在学习新特征时赋予模型利用先前提取的特征的能力。
创新点: 基于残差注意力模块的ViT架构:引入了一种新颖的ViT架构,利用残差注意力模块将重要的低层视觉特征融入到学习表示中,同时保持提取全局上下文的能力,从而增强了网络深层中的特征多样性。 残差注意力对ViT的鲁棒性增强:通过对Oxford Flowers-102和Oxford-IIIT Pet数据集上的图像分类任务进行综合评估,以实验证明残差注意力提高了ViT对平移不变性的鲁棒性。
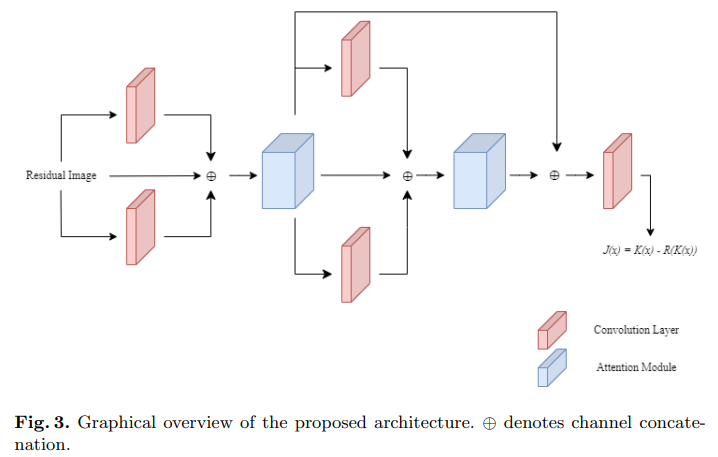
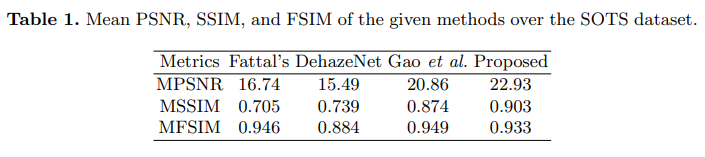
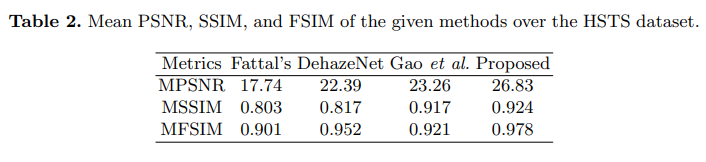
方法:论文提出了一种基于注意力模块的残差学习变压器的图像去雾网络。通常,获取无雾图像的方法依赖于近似计算透射矩阵和大气光。由于这是一个病态问题,估计这些变量容易导致误估计。本文中,残差模块学习这些变量。通道注意网络和变压器中的池化空间图进一步提高了残差主干的性能。
创新点: 残差学习变压器模块:通过残差模块学习这些变量,提高了去雾网络的性能。同时,引入的通道注意力网络和变压器的空间映射进一步增强了残差模块的性能。 图像去雾变压器网络:通过CNN逼近传输矩阵,将其与受雾图像的比值作为残差网络的输入,输出为受雾输入图像和潜在去雾图像之间的差值。此外,注意力模块利用变压器编码器考虑了图像的全局上下文和场景深度,来推断残差图像的通道属性。最后,通过近似空间注意力和特征图的连接,估计最终的去雾图像。
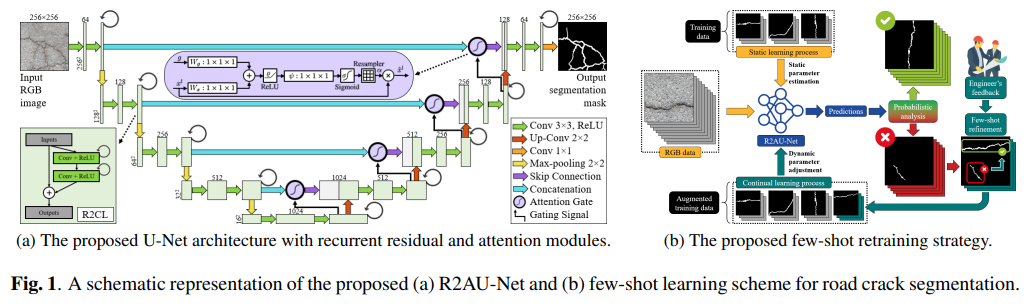
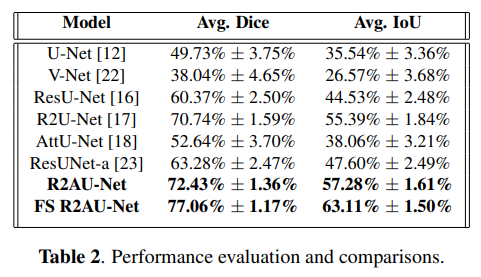
方法:论文介绍了一种针对道路裂缝分割的少样本学习策略。该方法基于带有循环残差和注意力模块的U-Net结构(R2AU-Net)。通过重新训练策略,随着少量新的修正样本输入分类器,动态微调U-Net的权重。
创新点: 引入循环残差卷积层 (R2CL),以提高分割任务的特征表示能力。 引入注意力门机制,用于突出显著特征,并通过跳跃连接传递。 在分割任务中引入了循环残差和注意力机制,以捕获更丰富的全局上下文信息和本地语义特征。 采用少样本精调过程,通过将少量矫正样本输入到算法中,动态更新网络权重,从而在新公开的CrackMap数据集上实现了最先进的性能。
关注下方《学姐带你玩AI》🚀🚀🚀 回复“残差注意力”获取全部论文+代码 码字不易,欢迎大家点赞评论收藏 |


【本文地址】