汽车保险欺诈预测 |
您所在的位置:网站首页 › 法国公开向美国索赔 › 汽车保险欺诈预测 |
汽车保险欺诈预测
|
Dear Readers, This is my very first article on Medium. This is about an auto insurance fraud prediction. Fraud predictions are usually an Imbalanced dataset with more legit claims than fraudulent Claims. 尊敬的读者,这是我关于Medium的第一篇文章。 这是关于汽车保险欺诈预测的。 欺诈预测通常是不合法的数据集,其合法性主张要比欺诈性主张多。 Problem Statement: 问题陈述: These days lot of insurance companies , deal with fraudulent claims. The frauds can be at different stages , either at the stage of filling the proposal or at the time of claims like staging an accident or claiming pre-existing Damages. Frauds are committed to achieving personal gains. The data set I worked on has is called an imbalanced dataset with legit claims being far come as compared to fraudulent Claims. According to the FBI, non-health insurance fraud costs an estimated $40 billion per year, which increases the premiums for the average U.S. family between $400 and $700 annually 这些天很多保险公司,处理欺诈性索赔。 欺诈可以处于不同的阶段,可以在填写提案的阶段,也可以在索赔时(例如上演事故或索赔预先存在的损害赔偿)。 欺诈致力于实现个人利益。 我处理的数据集被称为不平衡数据集,与欺诈性索赔相比,合法索赔远远没有达到。 根据联邦调查局的数据,非健康保险欺诈每年估计造成400亿美元的损失,这使美国普通家庭的保费每年增加了400美元至700美元 About the Dataset: 关于数据集: The dataset has 1000 observations with 39 features. The dataset contains information about fraudulent claims from 01-Jan-2015 to 01-March-2015 in the state of Ohio,Indiana,Illinois. The data given does not mention the insurance company. So we are not aware that whether it is from an single insurance or multiple insurance companies. The obvious drawback about this dataset is that it has only 1000 observations. 该数据集具有1000个具有39个特征的观测值。 数据集包含有关伊利诺伊州印第安纳州俄亥俄州从2015年1月1日至2015年3月1日的欺诈性索赔的信息。 给出的数据没有提及保险公司。 因此,我们不知道它来自单个保险公司还是多个保险公司。 此数据集的明显缺点是它只有1000个观测值。 EDA(Exploratory Data Analysis) EDA(探索性数据分析) The given Dataset has 1000 observations and 39 features,with the column fraud reported being the dependent variable(the variable that we wish to predict). The dependent Variable has 753 non-fraudulent cases and 247 fraudulent cases. 给定的数据集具有1000个观测值和39个特征,其中报告的列欺诈是因变量(我们希望预测的变量)。 因变量有753个非欺诈案件和247个欺诈案件。 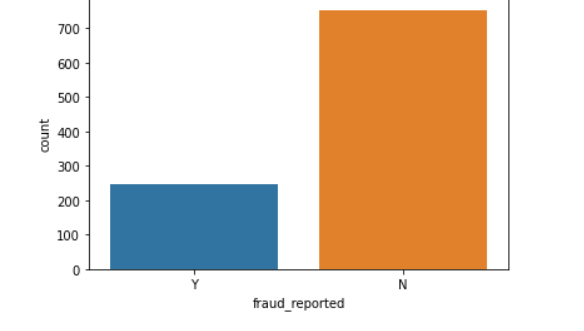 No of Fradulent vs Non Fraudulent Cases.
欺诈案件与非欺诈案件的数量。
No of Fradulent vs Non Fraudulent Cases.
欺诈案件与非欺诈案件的数量。
Correlations among variables 变量之间的相关性 There was |
【本文地址】
今日新闻 |
推荐新闻 |