方言听不懂,手把手教你用 Milvus 搭建方言翻译器! |
您所在的位置:网站首页 › 沪语翻译器 › 方言听不懂,手把手教你用 Milvus 搭建方言翻译器! |
方言听不懂,手把手教你用 Milvus 搭建方言翻译器!
|
坐在上海的公交车上,我有时会遇到这样的烦恼:稍一分神,没能听见普通话报站,支棱起耳朵,却听不懂沪语报站。为了解决这个问题,我决定——学习沪语?No, 作为一名数据工程师,我索性搭建了一个方言翻译器,帮助大家轻松听懂地方方言,再也不会错过公交车站。 在本次的项目中,我会手把手教你使用 Milvus 搭建方言翻译器。通过这个项目,你能收获: 熟悉开源数据集,在日常的模型训练中应用这些数据集 亲自动手搭建 Demo,真正解决实际生活场景中问题 学会使用 Milvus 后,还有更多的可以结合 Milvus 的应用场景等着你去发现 如果你是初次了解 Milvus 和 MagicHub 的小伙伴,我们为你准备了一个简短的介绍: Milvus Milvus 是基于 FAISS、Annoy、HNSW 等向量搜索库构建,核心是解决稠密向量相似度检索的问题。最近, Milvus 2.0 版本已经发布了,在向量检索库的基础上,Milvus 支持了数据分区分片、持久化、增量数据摄取、标量向量混合查询、Time Travel 等功能,同时大幅优化了向量检索的性能。推荐用户使用 Kubernetes 部署 Milvus ,以获得最佳的可用性和弹性。 MagicHub MagicHub.com 是爱数智慧发布的一个开源社区。爱数智慧为从事语音识别、语音合成、自然语言理解等人工智能领域研发与应用研究的企业、科研机构提供数据服务。MagicHub 开源数据覆盖多个场景、行业、语种。自 2021 年 4 月 15 日正式发布以来,已经覆盖 3000+ 全球开发者,累计下载超过 15 万小时数据集。目前开源 50 多种用于人工智能训练/测试的数据集,包括方言和小语种。数据集种类包含 NLP、ASR、TTS 数据集和 LEX 发音词典等。MagicHub 帮助 AI 开发者快速找到适合自己模型的数据集,用开源数据加速创新。 1. 数据准备本项目中,我们选择了 MagicHub 社区中提供的上海话数据集(来源详见文末链接[1]),你也可以根据自己的需要使用其他方言的数据集。 上海话朗读音频数据集-日常用语 此数据集包含了 4.23 个小时的上海话朗读音频和转写文本,有 4,819 条由 10 名说话人提供的日常用语语料。 录音环境 : 室内 录音语料 : 日常口语句子 文件格式 : WAV, TXT 语音参数 : 16 kHz/16 bits 录音设备 : 手机 适用领域 : 语音识别 版权所有者 : 爱数智慧
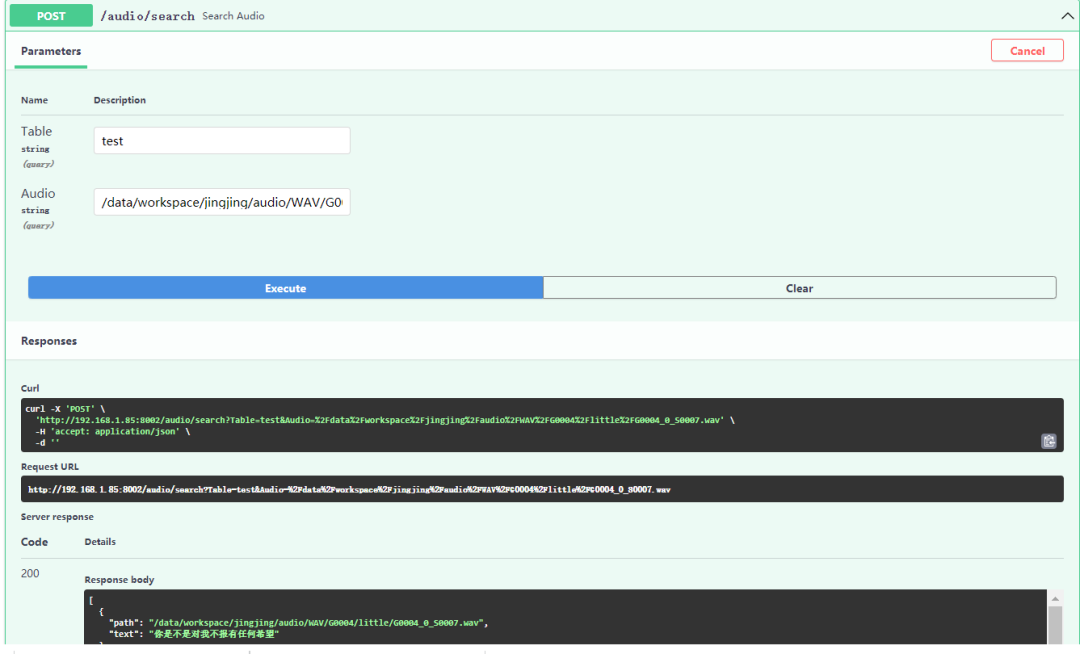
下载数据集,解压完成后可以看到这几个文件:WAV - 音频文件夹,README.txt - 数据集版权介绍文件,SPKINFO.txt - 每个音频的录音设备,性别,年龄,区域,录音频道的介绍文件,UTTRANSINFO.txt - 音频的文本内容,包含普通话和上海话。这里我们主要用到的是音频文本内容普通话部分。这里将 UTTRANSINFO.txt 文件转成了 CSV 的形式,有利于我们后续数据处理。 def loadDataSet(test_dir): f = open(test_dir,'r',encoding='utf-8') fname ='ts.csv' with open(fname,'w') as fine: for line in f.readlines(): line1 =line.split() PROMPT=line1[3] linew = PROMPT+"\n" fine.write(linew) 2. 音频检索音频搜索项目中,首先,将音频文件用 Panns-Inference 模型转成特征向量存储到 Milvus 2.0,并返回对应的 ID;接着,在 MySQL 数据库中存储 ID 、音频文件的路径 ,以及文本内容对应关系;随后,在 Milvus 2.0 中检索得出与其相似的音频文件,并返回最相似的前 N 个结果;最后,根据返回的 ID 结果,在数据库中搜索到对应的音频文件和文本内容。 使用 Milvus 2.0 最新音频检索项目,只需要修改少量代码,就可以对上海话音频进行检索,返回上海话的音频和音频内容。 下面是音频检索项目中需要修改的代码,在 load.py 中读取 CSV 的数据 def do_load(table_name, audio_dir,text_dir, model, milvus_client, mysql_cli): if not table_name: table_name = DEFAULT_TABLE vectors, names = extract_features(audio_dir, model) ids = milvus_client.insert(table_name, vectors) loadDataSet(text_dir) data = pd.read_csv("ts.csv") text = data['PROMPT'].tolist() milvus_client.create_index(table_name) mysql_cli.create_mysql_table(table_name) mysql_cli.load_data_to_mysql(table_name, format_data(ids, names,text)) return len(ids)在 search.py 中需要修改以下的代码部分: def do_search(host,table_name, audio_path, model, milvus_client, mysql_cli): try: if not table_name: table_name = DEFAULT_TABLE feat = get_audio_embedding(audio_path) vectors = milvus_client.search_vectors(table_name, [feat], TOP_K) vids = [str(x.id) for x in vectors[0]] paths,text = mysql_cli.search_by_milvus_ids(vids, table_name) distances = [x.distance for x in vectors[0]] for i in range(len(paths)): tmp = "http://" + str(host) + "/data?audio_path=" + str(paths[i]) paths[i] = tmp return vids, paths, distances,text except Exception as e: LOGGER.error(" Error with search : {}".format(e)) sys.exit(1)在 mysql_helpers.py 文件中修改以下代码: def create_mysql_table(self, table_name): sql = "create table if not exists " + table_name + "(milvus_id TEXT, audio_path TEXT,text TEXT) ENGINE=InnoDB DEFAULT CHARSET=utf8;" try: self.cursor.execute(sql) LOGGER.debug("MYSQL create table: {} with sql: {}".format(table_name, sql)) except Exception as e: LOGGER.error("MYSQL ERROR: {} with sql: {}".format(e, sql)) sys.exit(1) def load_data_to_mysql(self, table_name, data): sql = "insert into " + table_name + " (milvus_id,audio_path,text) values (%s,%s,%s);" try: self.cursor.executemany(sql, data) self.conn.commit() LOGGER.debug("MYSQL loads data to table: {} successfully".format(table_name)) except Exception as e: LOGGER.error("MYSQL ERROR: {} with sql: {}".format(e, sql)) sys.exit(1) def search_by_milvus_ids(self, ids, table_name): str_ids = str(ids).replace('[', '').replace(']', '') sql = "select * from " + table_name + " where milvus_id in (" + str_ids + ") order by field (milvus_id," + str_ids + ");" try: self.cursor.execute(sql) results = self.cursor.fetchall() results_path=[res[1] for res in results] results_text=[res[2] for res in results] LOGGER.debug("MYSQL search by milvus id.") return results_path,results_text except Exception as e: LOGGER.error("MYSQL ERROR: {} with sql: {}".format(e, sql)) sys.exit(1)以及修改相关的接口,在 main.py 中修改以下代码: class Item(BaseModel): Table: Optional[str] = None File:str Text:str @app.post('/audio/load') async def load_audios(item: Item): # Insert all the audio files under the file path to Milvus/MySQL try: total_num = do_load(item.Table, item.File,item.Text,MODEL, MILVUS_CLI, MYSQL_CLI) LOGGER.info("Successfully loaded data, total count: {}".format(total_num)) return {'status': True, 'msg': "Successfully loaded data!"} except Exception as e: LOGGER.error(e) return {'status': False, 'msg': e}, 400 @app.post('/audio/search') async def search_audio(request: Request,Table: str = None, audio: UploadFile = File(...)): # Search the uploaded audio in Milvus/MySQL try: # Save the upload data to server. content = await audio.read() audio_path = os.path.join(UPLOAD_PATH, audio.filename) with open(audio_path, "wb+") as f: f.write(content) host = request.headers['host'] ids, paths,text, distances= do_search(host,Table, audio_path, MODEL, MILVUS_CLI, MYSQL_CLI) names=[] names = text res = dict(zip(paths, zip(names, distances))) #res = sorted(res.items(), key=lambda item: item[1][1]) LOGGER.info("Successfully searched similar audio!") return res except Exception as e: LOGGER.error(e) return {'status': False, 'msg': e}, 400 3. 测试运行现在,修改完上述代码以后,参考 Github 中 Audio_similar_search 的 Readme 文档(来源详见文末链接[2])启动 FastAPI ,从 FastAPI 中验证代码是否成功运行,在浏览器中输入 localhost:8002/docs 可以看到如图所示 FastAPI 的页面, 在 Load API 中分别输入 Table 的名称,音频文件的路径,音频对应的文本的路径,然后点击 Excute 的按钮,图中显示数据插入成功。
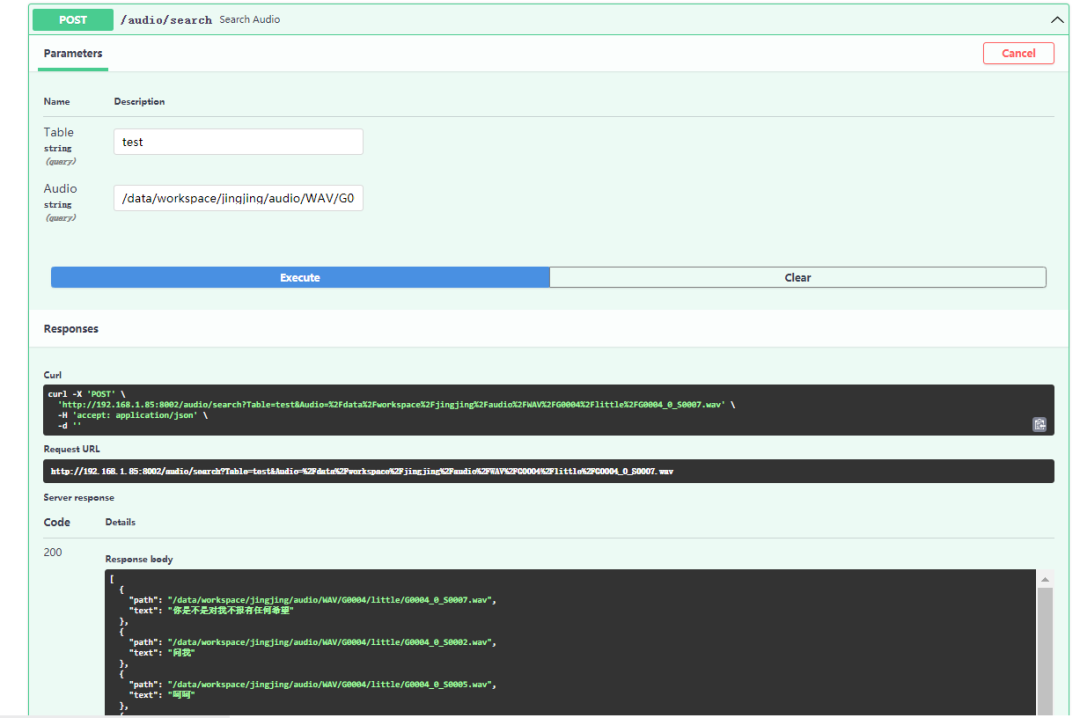
然后,在 Search API 中输入对应的 Table 名称和需要检索的音频路径,点击 Excute 按钮进行检索。如下图所示,就可以看到相应的音频和其对应的文本内容了。
最后,感谢爱数智慧 MagicHub 提供的开源数据集,让我们更好地结合模型与 Milvus 进行多个领域的向量检索。 在这个音频检索项目中,我们也可以使用其他的方言数据集,将数据集经过 AI 模型转成特征向量,结合 Milvus 进行相似检索,就可以把任何你听不懂的方言翻译成普通话啦! 动手玩一把? 源码链接就在下方! [1] 爱数智慧 MagicHub 开源社区: https://magichub.com/cn/category/datasets/ [2] 音频检索: https://github.com/milvus-io/bootcamp/tree/master/solutions/audio_similarity_search 作者 | 贾晶晶 Zilliz 数据工程师,毕业于西安交通大学计算机系。加入Zilliz后,主要工作内容为数据预处理、AI模型部署、Milvus 相关技术研究,以及帮助社区用户实现应用场景落地。资深动漫粉,对社区沟通超级有耐心,平时比较关注自然语言处理领域的研究。
|


【本文地址】
今日新闻 |
推荐新闻 |