ResNet(残差网络)和梯度消失/爆炸 |
您所在的位置:网站首页 › 没解决的问题它不会消失 › ResNet(残差网络)和梯度消失/爆炸 |
ResNet(残差网络)和梯度消失/爆炸
|
ResNet解决的不是梯度弥散或爆炸问题,kaiming的论文中也说了:臭名昭著的梯度弥散/爆炸问题已经很大程度上被normalized initialization and intermediate normalization layers解决了;由于直接增加网络深度的(plain)网络在训练集上会有更高的错误率,所以更深的网络并没有过拟合,也就是说更深的网络效果不好 ResNet最初的想法是在训练集上,深层网络不应该比浅层网络差,因为只需要深层网络多的那些层做恒等映射就简化为了浅层网络。所以从学习恒等映射这点出发,考虑到网络要学习一个F(x)=x的映射比学习F(x)=0的映射更难,所以可以把网络结构设计成H(x) = F(x) + x,这样就即完成了恒等映射的学习,又降低了学习难度。这里的x是残差结构的输入,F是该层网络学习的映射,H是整个残差结构的输出。 1、为什么要使用更深层次的网络? 从理论上来讲,加深深度学习网络可以提升性能。深度网络以端到端的多层方式集成了低/中/高层特征和分类器,且特征的层次可通过加深网络层次的方式来丰富。举一个例子,当深度学习网络只有一层时,要学习的特征会非常复杂,但如果有多层,就可以分层进行学习。网络的加深,理论上可以提供更好的表达能力,使每一层学习到更细化的特征。 2、梯度消失 or 爆炸 但网络加深真的只有堆叠层数这么简单么?当然不是!首先,最显著的问题就是梯度消失或梯度爆炸。我们都知道神经网络的参数更新依靠梯度反向传播(Back Propagation),那么为什么会出现梯度的消失和爆炸呢?举一个例子解释。如图2所示情况,假设每层只有一个神经元,且激活函数使用Sigmoid函数,则有
我们将问题简单化来说明梯度消失问题,假设输入只有一个特征,没有偏置单元,每层只有一个神经元:
根据链式求导和反向传播,我们可以得到:
Sigmoid函数的导数如图所示:
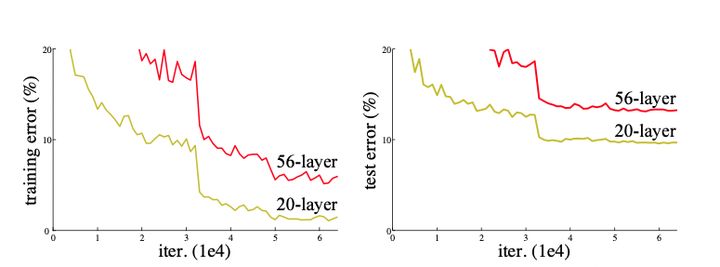
我们可以看到Sigmoid的导数最大值为0.25,那么随着网络层数的增加,小于1的小数不断相乘导致 逐渐趋近于零,从而产生梯度消失。那么梯度爆炸又是怎么引起的呢?同样的道理,当权重初始化为一个较大值时,虽然和激活函数的导数相乘会减小这个值,但是随着神经网络的加深,梯度呈指数级增长,就会引发梯度爆炸。然而,从AlexNet开始,神经网络中就使用ReLU函数替换了Sigmoid,同时BN(Batch Normalization)层的加入,也基本解决了梯度消失或爆炸问题。 3、网络退化 现在,梯度消失或爆炸的问题已经解决了。这是不是就可以通过堆叠层数来加深网络了呢?Still no! 我们来看看ResNet论文中提到的例子(见下图),很明显,56层的深层网络,在训练集和测试集上的表现都远不如20层的浅层网络。这种随着网络层数加深,准确率(accuracy)逐渐饱和,然后出现急剧下降,具体表现为深层网络的训练效果反而不如浅层网络好的现象,被称为网络退化(degradation)。
为什么会引起网络退化呢?按照理论上来说,当浅层网络效果不错的时候,网络层数的增加即使不会引起精度上的提升,也不该使模型效果变差。但事实上非线性的激活函数的存在,会造成很多不可逆的信息损失。网络加深到一定程度,过多的信息损失就会造成网络的退化。 而ResNet就是提出一种方法让网络拥有恒等映射能力,即随着网络层数的增加,深层网络至少不会差于浅层网络。 4、Residual Block 现在我们明白了,为了加深网络结构,使每一次能够学到更细化的特征从而提高网络精度,需要实现的一点是恒等映射。那么残差网络如何能够做到这一点呢? 恒等映射即为H(x)=x,已有的神经网络结构很难做到这一点。不过,如果我们将网络设计成H(x)=F(x)+x,即F(x)=H(x)-x,那么只需要使残差函数F(x)=0,就构成了恒等映射H(x)=F(x).
残差结构的目的是,随着网络的加深,使 F(x) 逼近于0,从而让深度网络的精度在最优浅层网络的基础上不会下降。看到这里你或许会有疑问,既然如此为什么不直接选取最优的浅层网络呢?这是因为最优的浅层网络结构并不易找寻,而ResNet可以通过增加深度,找到最优的浅层网络并保证深层网络不会因为层数的叠加而发生网络退化。
|



【本文地址】
今日新闻 |
推荐新闻 |