基于ENVI与ERDAS的Landsat 7 ETM+单窗算法地表温度(LST)反演 |
您所在的位置:网站首页 › 江津地表温度 › 基于ENVI与ERDAS的Landsat 7 ETM+单窗算法地表温度(LST)反演 |
基于ENVI与ERDAS的Landsat 7 ETM+单窗算法地表温度(LST)反演
|
基于ENVI与ERDAS的Landsat 7 ETM+单窗算法地表温度(LST)反演
1 原理部分与前期操作准备1.1 图像预处理1.2 植被指数反演1.3 单窗算法原理
2 实际操作部分2.1 数据导入与辐射定标2.2 波段合成2.3 编辑头文件2.4 转换文件数据格式2.5 FLAASH大气校正2.6 图像格式转换2.7 EDRDAS文件导入与裁剪2.8 植被指数模型建立2.9 大气校正调试2.10 地表亮度温度计算2.11 监督分类2.12 植被覆盖度与地表比辐射率计算2.13 大气参数计算2.14 地表真实温度反演
3 结果分析3.1 大气校正对植被指数的影响3.2 各类植被指数对比分析3.3 热红外波段温度反演对比分析3.4 专题地图绘制3.5 地表真实温度反演专题地图及空间分布差异
4 一些思考4.1 影响单窗温度估算误差的主要因素有哪些?4.2 ERDAS软件建模过程需注意哪些问题?
1 原理部分与前期操作准备
更新:基于GEE的Landsat地表温度反演可以看这篇博客,自动批量操作,处理更快。 首先,本文可以认为是对上一篇博客(https://blog.csdn.net/zhebushibiaoshifu/article/details/113916152)在反演算法与主要参数选取等两个方面的补充与改进。 目前主要的地表温度单波段反演算法包括大气校正法(又名辐射传输方程法,Radiative Transfer Equation,RTE)、单通道算法(Generalized Single Channel Method)和单窗算法(Mono-window Algorithm)。上面提及的那篇博客即是利用ENVI软件“Band Math”模块,基于大气校正法实现襄阳市地表温度的反演;而本次我们更进一步,借助ENVI软件和ERDAS软件,实现植被指数的反演与基于单窗算法的武汉市地表温度反演。其中,所使用的遥感影像均为Landsat 7 ETM+影像。 综上,本文的操作过程分为两个部分:首先是利用ERDAS软件“Model Maker”模块实现的植被指数反演,其次是同样利用“Model Maker”模块实现的单窗算法地表温度反演。其中,第一个部分求出的NDVI指数将用于第二部分计算。 本文内容较为丰富。因此,为了更好理解整个实验的原理及过程,将本文步骤、原理等梳理如下。 1.1 图像预处理首先,针对植被指数反演,大致操作和我的前两篇博客类似——博客1以及博客2,包括获取需要的遥感图像数据与元数据,并对其进行预处理步骤——数据导入、辐射定标(包括可见光波段、近红外波段与短波红外波段)、波段合成、编辑头文件、FLAASH大气校正等;这些预处理步骤依然是在ENVI软件中完成,具体操作方式亦与博客1类似。随后,与博客2在ENVI软件“Band Math”模块计算NDVI等植被指数不同,本次将经过预处理后的图像文件转入ERDAS软件中,裁剪并利用ERDAS软件“Model Maker”模块实现多种植被指数的反演。 其中,辐射定标需要分为两个步骤,即对可见光波段、近红外波段与短波红外波段数据(1、2、3、4、5、7六个波段)与热红外波段数据(61、62两个波段)分别进行辐射定标。针对热红外波段数据的定标在后期ERDAS软件中进行。 1.2 植被指数反演其次,需要计算NDVI(即Normalized Difference Vegetation Index,归一化植被指数,而非植被覆盖度)、RVI(即Ratio Vegetation Index,比值植被指数)与DVI(即Difference Vegetation Index,差值植被指数)等三个植被指数。 通过博客2我们已经知道,NDVI是指一幅遥感影像中,近红外波段的反射值与红光波段的反射值之差比上这二者之和;其可以用来检测植被生长状态、植被覆盖度,还可以消除部分辐射误差等,能反映出植物冠层的背景影响。NDVI的具体取值范围严格限制在-1到1之间,其取负值表示地面覆盖为云、水、雪等,即对可见光具有较高反射;0值表示地面覆盖有岩石或裸土等,从而使得NIR(Near Infrared,近红外波段)和R(Red,红光波段)数值近似相等;其取正值则表示地面有植被覆盖,且地表植被覆盖度越高,其数值越高。在植被处于中、低覆盖度时,NDVI数值随覆盖度的增加而迅速增大,而当达到一定覆盖度后增长缓慢;因此,NDVI适用于植被早、中期生长阶段的动态监测。 目前,在一些网站(如NASA官方网站)具有NDVI成品数据,可供我们直接下载、利用;而通过初始遥感影像中的近红外波段数据和红光波段数据,我们可以直接利用前述定义公式对其加以计算,即 单窗算法依据地表热辐射传输方程,不需要进行大气校正即可直接反演地表温度。这是由于NDVI是经过归一化处理的数值,大气影响对其计算误差并不是很大,一些文献直接利用热红外波段DN值计算NDVI。单窗算法公式如下: (1) 将图像压缩包文件(本文选用“LE71230392003097EDC00.tar.gz”,具体图像数据的下载等网上资源很多,大家自行查阅即可,不再赘述)解压缩;打开ENVI Classic 5.3(64-bit)软件,选择“File”→“Open Image File”,在弹出的文件选择窗口中分别选中压缩包中后缀名包含“B10”“B20”“B30”“B40”“B50”“B70”的六个“.tif”格式文件;点击“打开”。 (2) 选择“Basic Tools”→“Preprocessing”→“Calibration Utilities”→“Landsat Calibration”,在弹出的文件选择窗口中选择一个波段的图像。
(4) 执行上述操作共六次,从而对压缩包中1、2、3、4、5、7六个波段的图像均进行辐射定标操作。 (1) 选择“Basic Tools”→“Layer Stacking”,在弹出的文件选择窗口中选择经过辐射定标后的六个波段的图像。
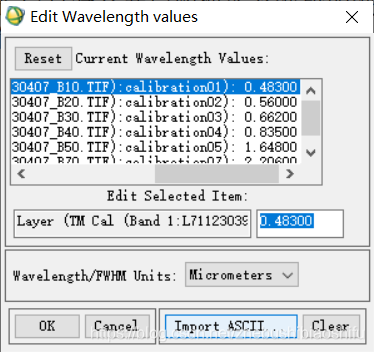
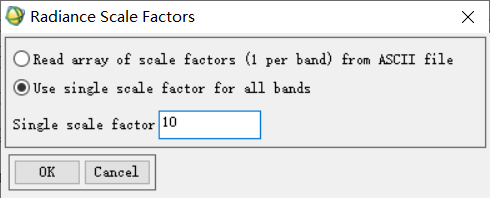
(1) 在“Available Bands List”文件列表中右键选择波段合成后的结果文件,选择“Edit Header”功能。 (2) 选择“Edit Attributes”→“Wavelengths”,按照图像各个波段原有中心波长信息对合并后图像各个波段的波长信息进行修改,并注意将数据单位修改为“Micrometers”。具体见上图。 2.4 转换文件数据格式(1) 选择“Basic Tools”→“Convert Data (BSQ,BIL,BIP)”,在弹出的文件选择窗口中选择经过波段合成、编辑头文件操作后的结果图像,点击“OK”。 (1) 选择“Basic Tools”→“Preprocessing”→“Calibration Utilities”→“FLAASH”,在弹出的转换因子窗口中选择第二项,即单一因子适用于所有波段的情况。由于我们本次所使用数据原有光谱数值为标准单位,即(W)/m2 *μm *rad,为了将这一单位换为FLAASH方法所能利用的单位,我们需要将转换因子设定为10.00。
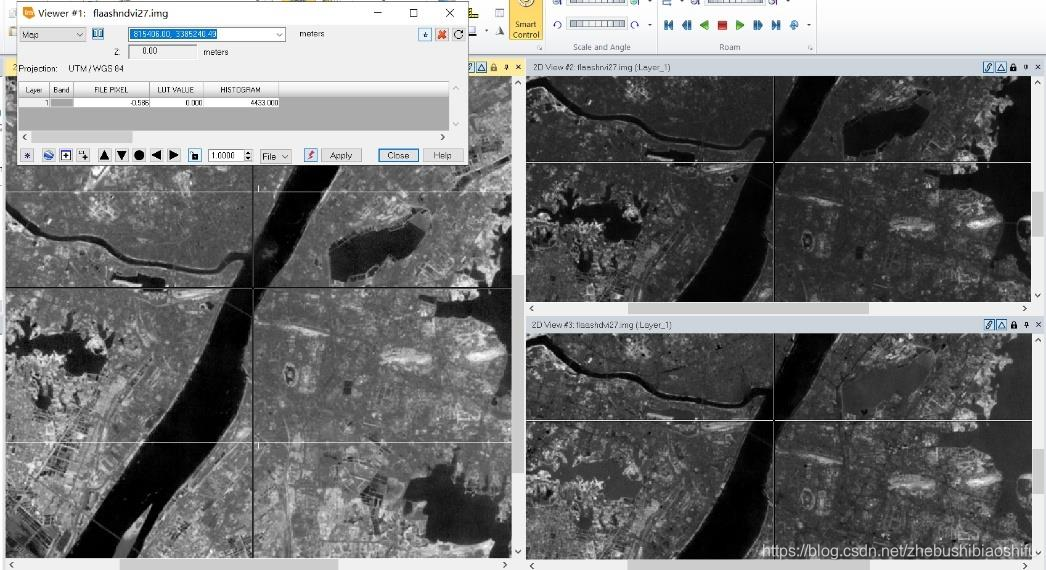
经过ENVI软件的FLAASH大气校正后,得到的结果图像并不能直接被ERDAS软件所识别,我们需要将其转换为“.img”等格式文件。需要注意的是,不要转换为“.tif”格式的文件,否则图像文件将会丢失其原有的空间信息。 (1) 选择“File”→“Save File As”→“ERDAS IMAGINE”,在弹出的文件转换选择窗口中选择经过FLAASH大气校正后的结果图像,点击左下角“OK”。
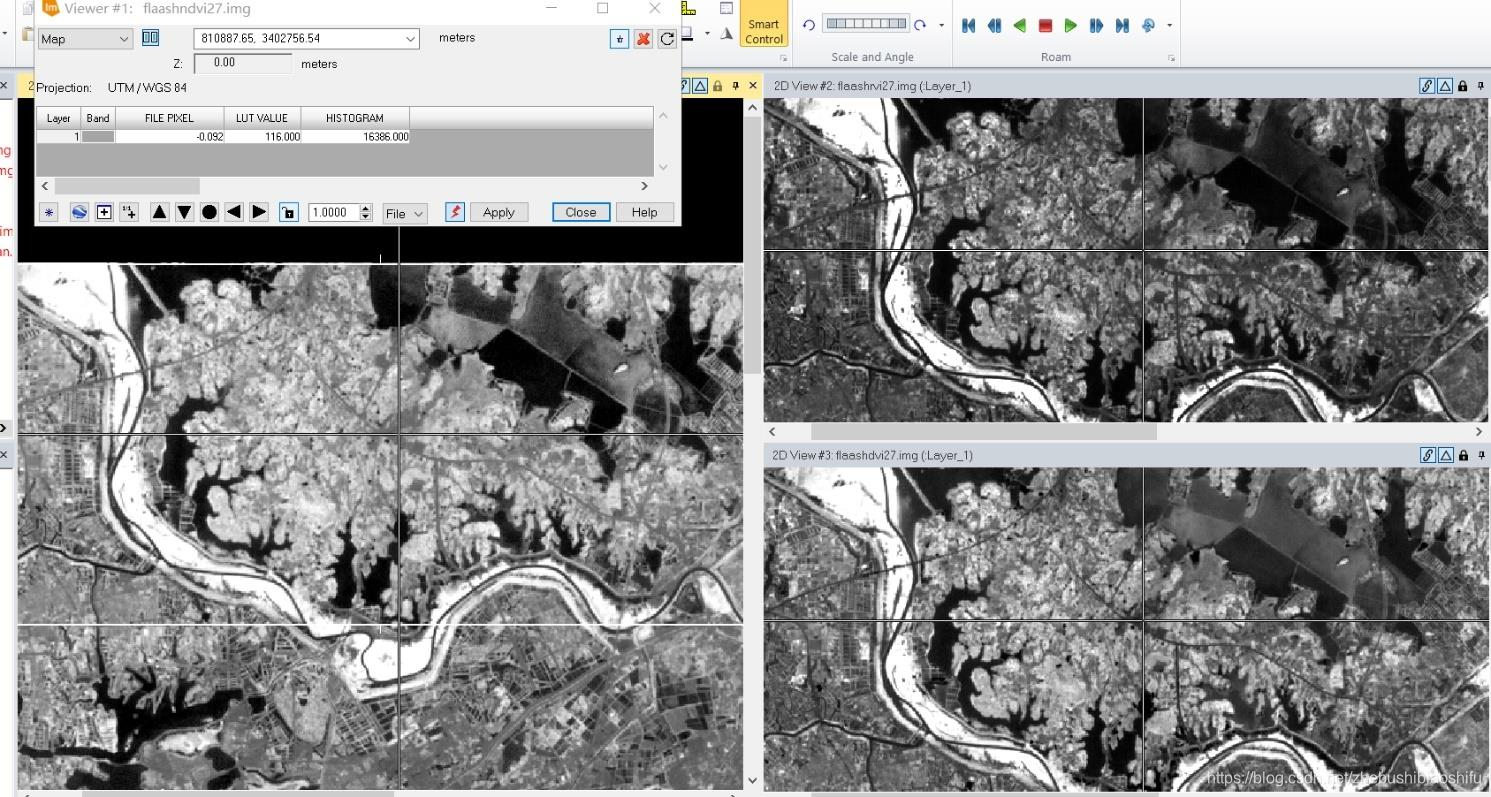
通过上述步骤得到的“.img”格式文件范围为江汉平原,整体区域面积较大,文件数据量多;而我们温度反演的目标区域仅为武汉市。因此,我们需要借助武汉市AOI(Area of Interest)文件,将原本的江汉平原地区裁剪为武汉市地区。 (1) 打开ERDAS IMAGINE 2015软件,在黑色图层窗口区域右键,并选择“Open Raster Layer”在弹出的文件打开选择窗口中选择经过FLAASH大气校正后的“.img”结果图像,点击右上角“OK”。ERDAS软件选择文件时,可以借助“Recent”和“Goto”功能,选择最近操作的文件夹路径或文件。
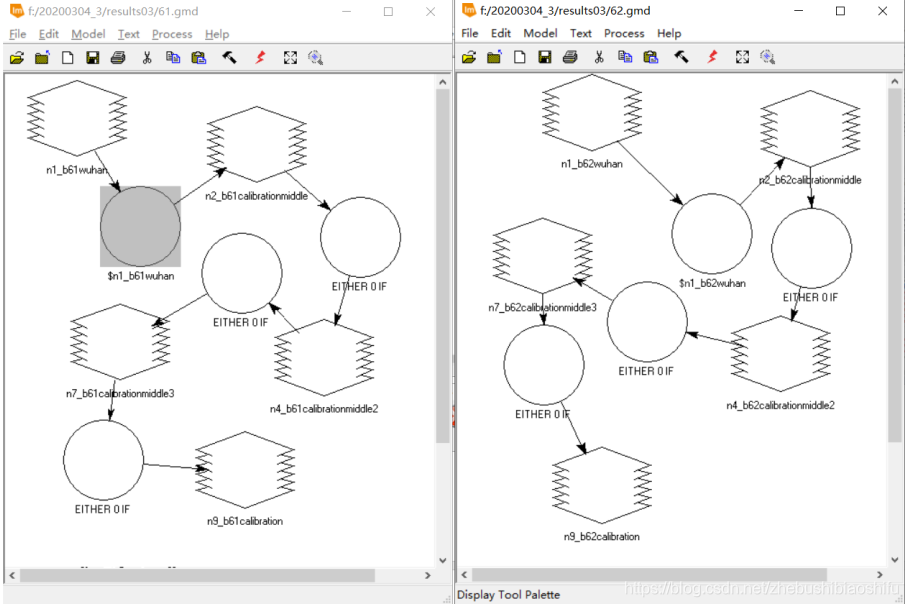
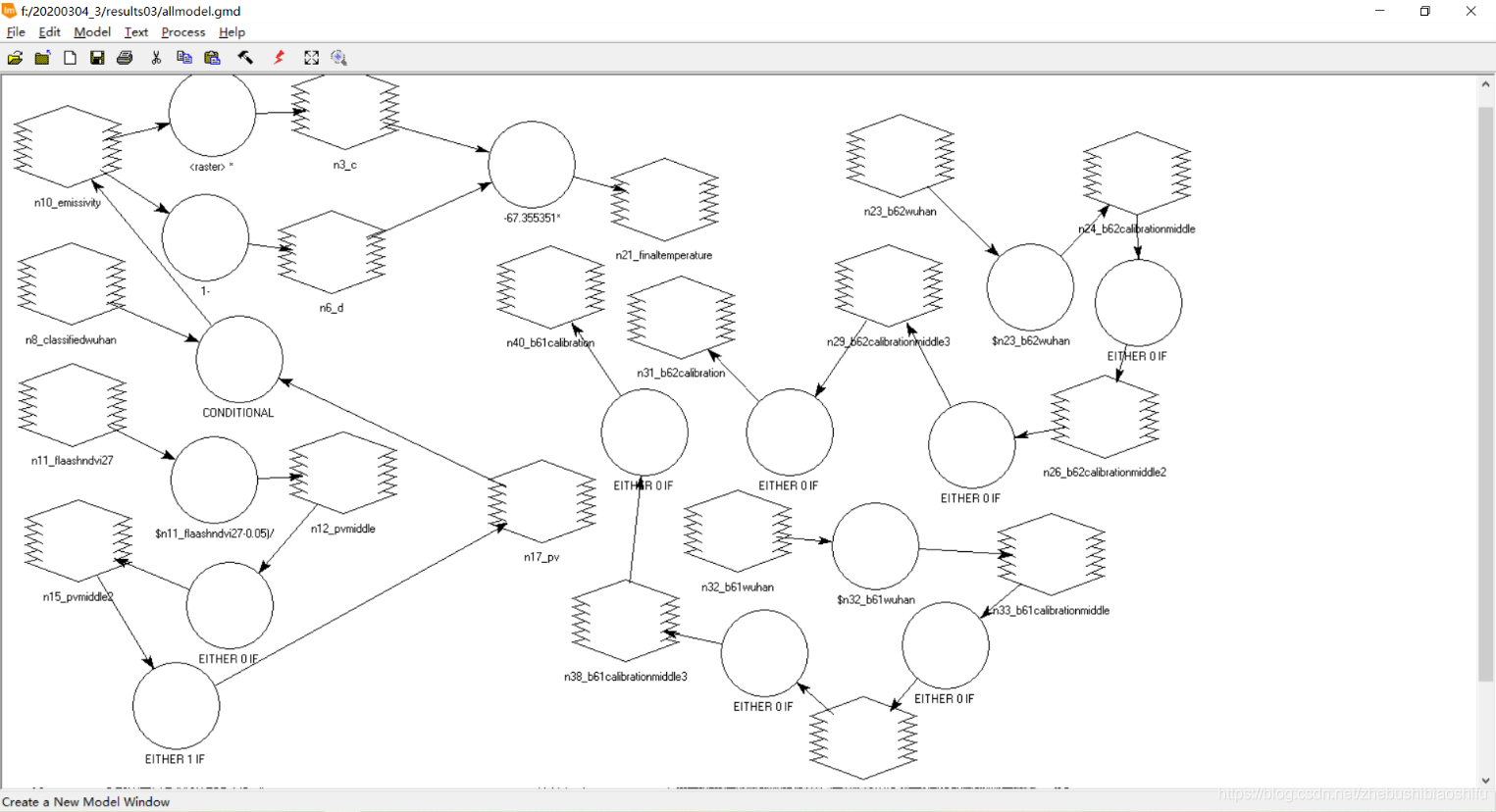
正如第一部分原理所述,本文和博客2在ENVI软件“Band Math”模块计算NDVI等植被指数不同,本次将经过预处理后的图像文件转入ERDAS软件中,裁剪并利用ERDAS软件“Model Maker”模块实现多种植被指数的反演。 一般地,ERDAS模型可以分为“输入文件”“处理函数”与“输出文件”三个部分,较为复杂的模型可以具有多个“处理函数”,并需要随之增添若干“中间文件”;各个部分之间由连接线相连,以表示模型的运行顺序与流程。模型配置结束后,调试无误即可将模型保存,利于后期继续使用同一模型。同时还可以保存模型对应的脚本代码文件。通过本次实验,可以看到保存脚本代码文件对于较为复杂(具有多个函数)的模型报错检查具有很大帮助。 (1) 选择“Toolbox”→“Model Maker”→“Model Maker”,在弹出的New_Model窗口中配置模型。
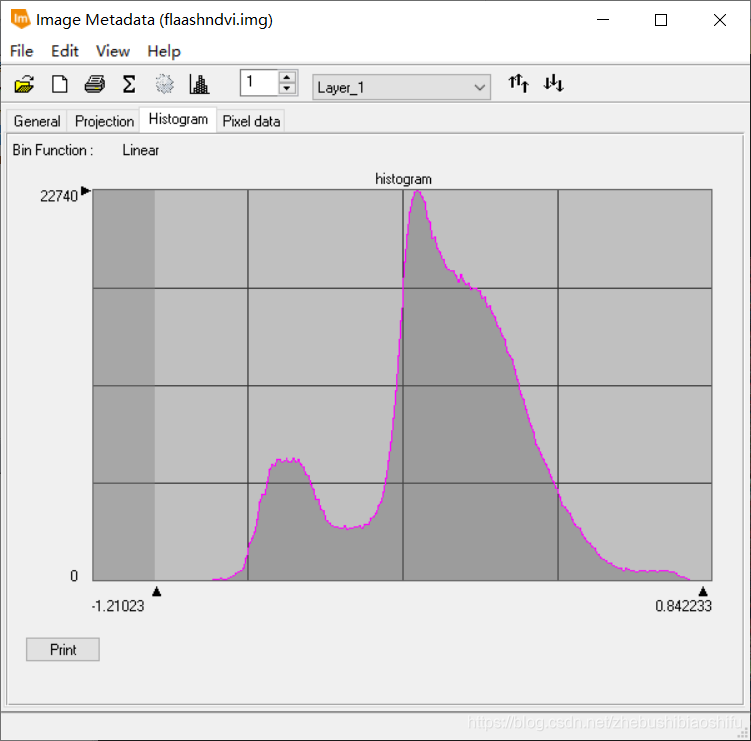
通过上述模型得到NDVI等植被指数的数据图像后,对图像的数值加以观察。此时注意到,所得到的NDVI图像中出现了较多小于-1的值。随后立即返回ENVI软件对大气校正结果图像数值加以检查,发现其中出现了较多负值。
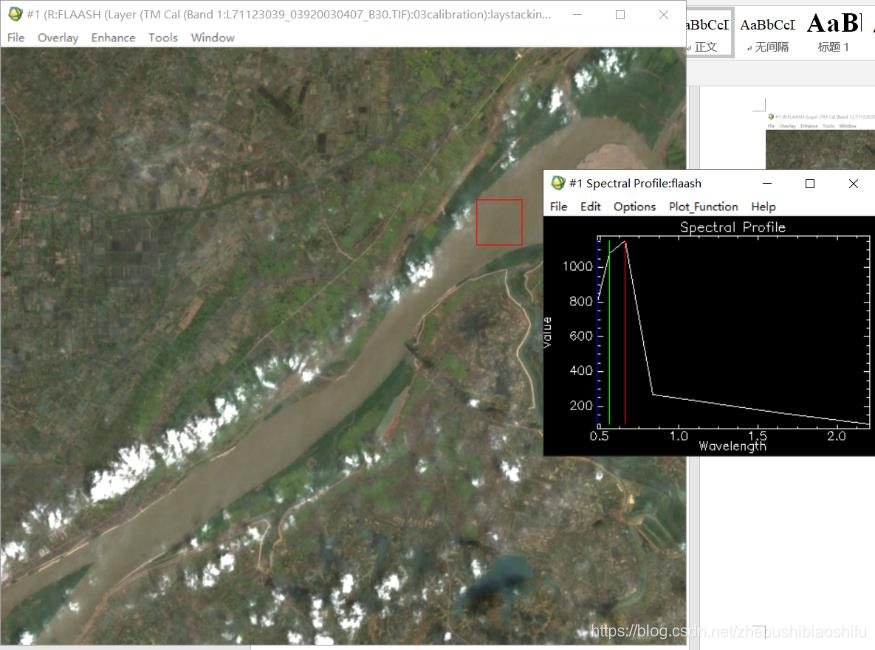
(2) 由于本次实验原始数据固定,因此推测是FLAASH大气校正参数设置出现问题。对FLAASH大气校正结果图像加以观察,发现植被、水体等整体光谱曲线并没有较大问题。
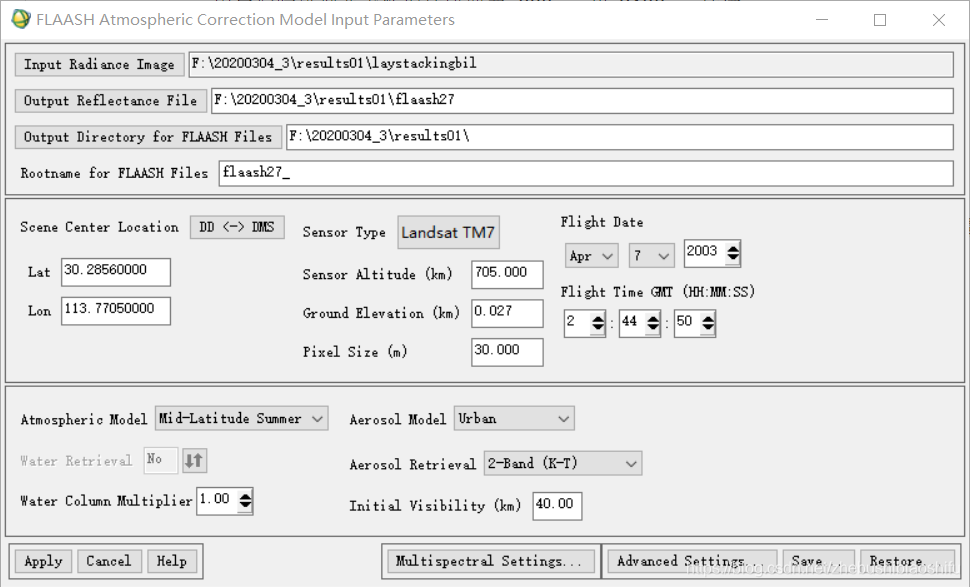
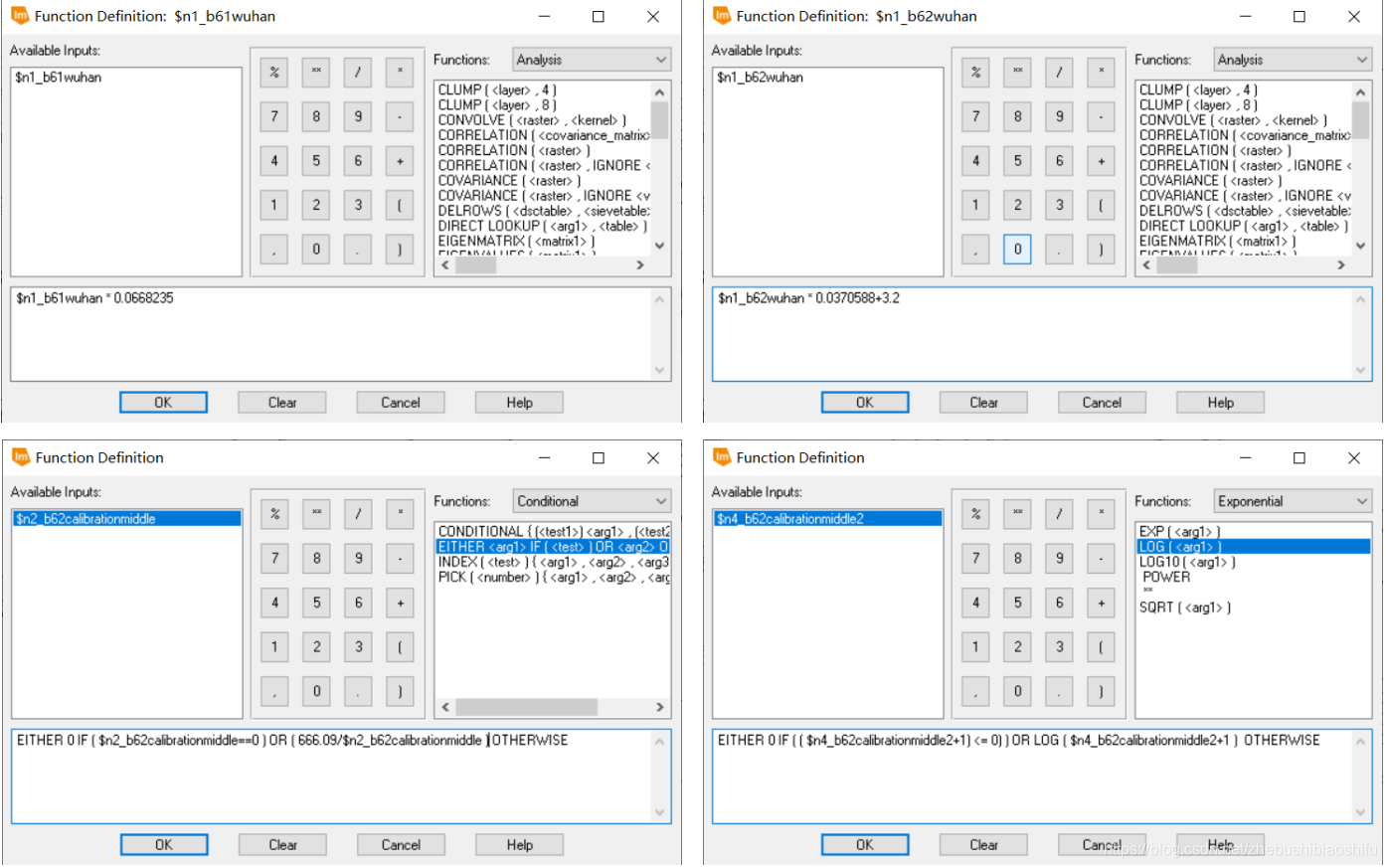
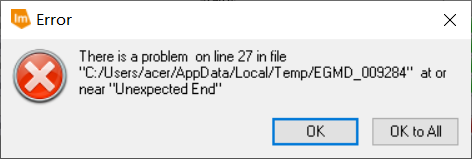
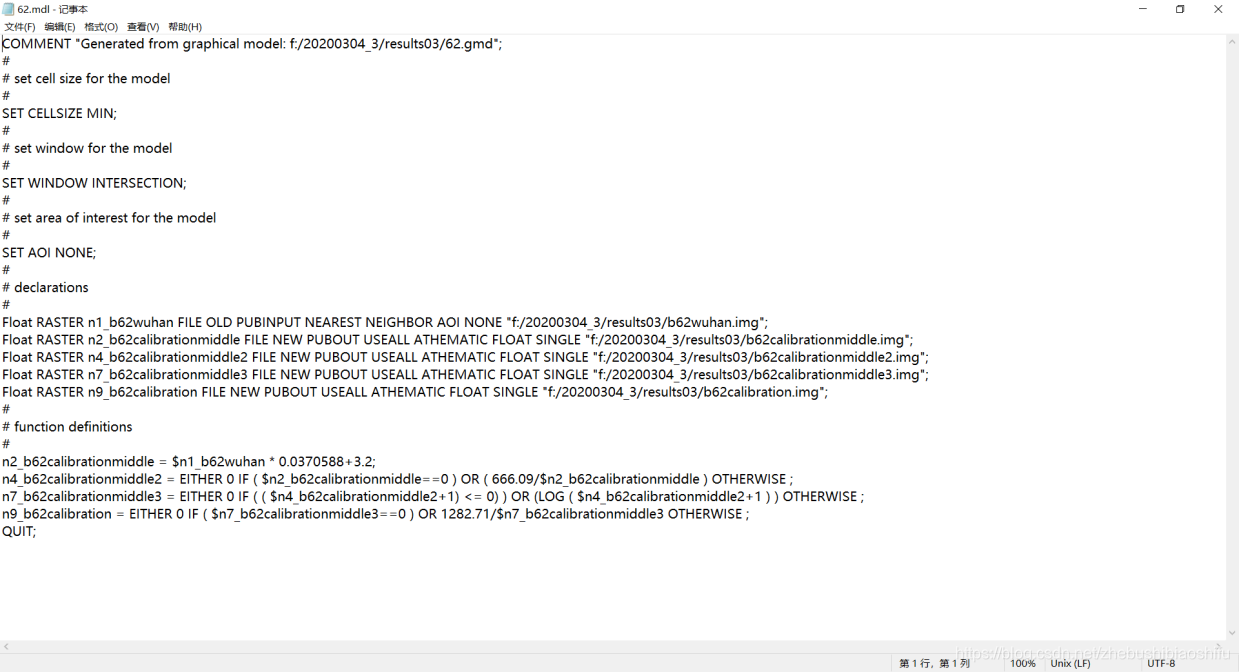
(3) 再次回到ERDAS软件,发现得到的NDVI结果图像中,出现小于-1的数值的像素并不是很多,仅仅占据全图的很小一部分。通过多次尝试,发现FLAASH大气校正参数中平均海拔似乎与之相关——若所选用的平均海拔较低,就没有出现NDVI数值小于-1的情况;而平均海拔若设置过大,往往出现了NDVI数值小于-1的情况。因此,决定尝试将FLAASH大气校正参数中的海拔加以调节,并将得到的结果与之对比。 (4) 将平均海拔调低一些后,重新进行FLAASH大气校正,发现得到的NDVI结果依然会出现一些小于-1的数值。再次返回FLAASH参数界面,考虑到本次实验最终的研究区域为武汉市,因此将气溶胶模型由Rural调整为Urban,并将平均海拔继续加以微调。重新进行FLAASH大气校正,发现得到的结果已经恢复正常,不存在小于-1的异常值。 (5) 利用验证数据无误的FLAASH大气校正结果图像重新计算各类植被指数。 (1) 选择“Toolbox”→“Model Maker”→“Model Maker”,在弹出的New_Model窗口中配置模型。 (2) 分别建立两个模型,输入文件分别为两个热红外波段(B61与B62)图像,输出文件分别为对应波段图像文件所代表的地表亮度温度数据文件,而处理函数则分别使用本文第一部分对应的热红外波段辐射定标、亮温计算公式。其中,由于公式较为复杂,可以对每一个模型均使用多个“处理函数”及中间图像文件。调试无误后分别保存模型文件。 (3) 多个单一模型调试无误并保存后,可以将其合并在一个新的模型中,从而实现多个操作一步完成。 (4) 在将全部模型合并后,运行出现报错。由于模型整体牵涉到的步骤较多,可能无法立即定位出出现错误的具体位置。此时有两个办法能够较好找到出错的位置:一是可以结合资源管理器中已经出现的中间文件,找出第一个未生成的中间文件,则出错的语句多数就集中于这一第一个未出现的中间文件函数处;二是可以直接将模型对应的脚本文件导出,并用记事本打开,根据报错信息中提示的行数确定具体出现问题的位置,并再回到ERDAS软件“Model Maker”模块中找到对应函数修改。
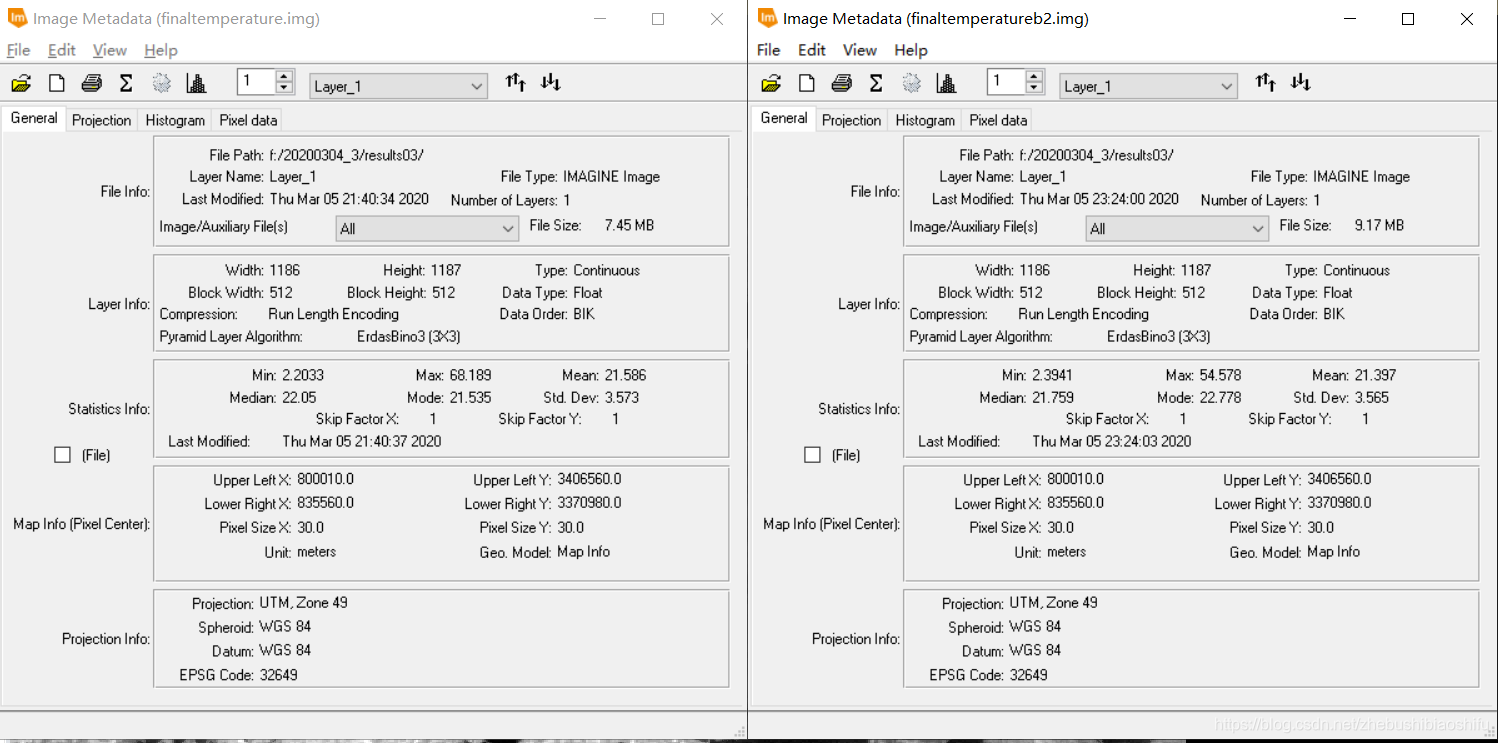
(5) 最终得到两个热红外波段对应的辐射定标、地表亮度温度计算公式模型。 如同本文第一部分原理所述,本次实验我们是用监督分了方式区分水体、植被与建筑物,从而实现更加精确的地表植被覆盖度计算。监督分类依然在ERDAS中实现。 (1) 选择“Raster”→“Supervised”→“Supervised Editor”,在弹出的AOI区域显示表中可以看到,此时还没有添加进入任何AOI,表格中处于空白状态。 (2) 分别依据水体、植被与建筑物,在图像中划定区域。每一种地表类型需要划出尽可能多的AOI,以期提高最终监督分类的效果与精确度。其中,需要将每一个水体区域都标注。 (3) 每划定一个AOI,便添加进入“Supervised Editor”中;同一地物类型的AOI添加完毕后,对这一类型的全部AOI加以合并,并赋以一个易于辨认的Value值。 (4) 其中,可以借助武汉市卫星地图影像对具体地物类别加以具体区分。但应注意,我们所使用的遥感影像为2003年的数据,而卫星影像数据成像时间相对较为接近我们现在的时间。因此,利用卫星影像亦只可以作为一种参考。 (5) AOI划分完毕后,保存。选择“Raster”→“Supervised”→“Supervised Classification”,在弹出的监督分类配置窗口中配置输入文件、输出文件与用于指定区域地表类型的AOI文件。
如本文第一部分原理所示,本次实验计算地表比辐射率的方式不再采用NDVI划分地表类型的方法,而是使用更为精确的上述监督分类结果。 (1) 选择“Toolbox”→“Model Maker”→“Model Maker”,在弹出的New_Model窗口中配置模型。
(3) 对得到的地表植被覆盖度文件数值加以检查,确定无误。
(1) 依据本文第一部分原理,计算大气等效温度与大气透射率等指标。
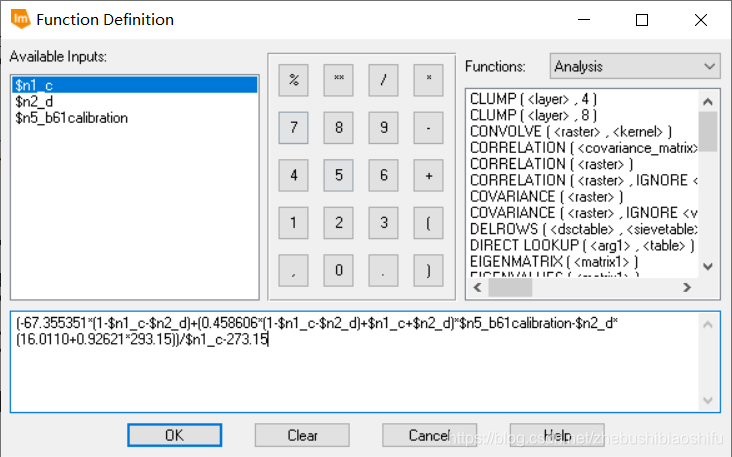
(2) 随后,求出最终地表真实温度反演公式中的中间变量C与D。 (1) 依据本文第一部分原理,以及计算求得的大气等效温度与大气透射率等指标,结合中间变量C与D,计算求出最终的地表真实温度反演结果。 (2) 利用上述建立好的模型,重复执行操作,计算出另一热红外波段对应的地表真实温度反演结果。 (3) 综观本文所使用的全部模型,可以看出模型能够极大方便原本零散的单一操作。 (1) 分别使用经过大气校正和未经过大气校正的图像计算NDVI、RVI与DVI指数,得到结果对比如下。
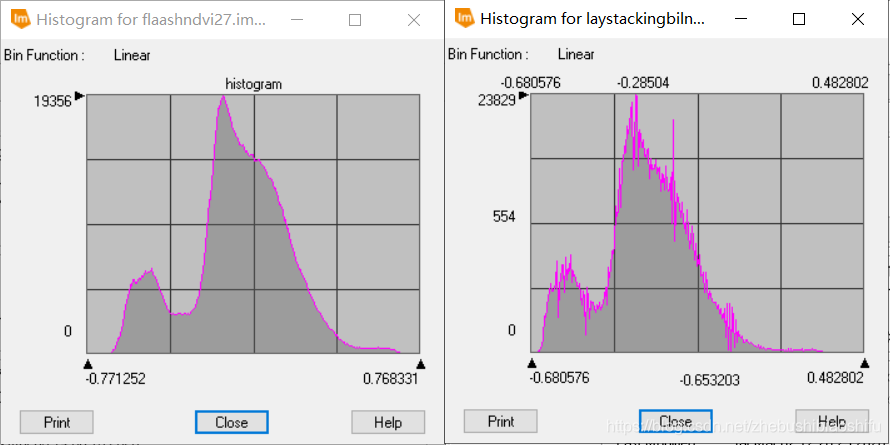
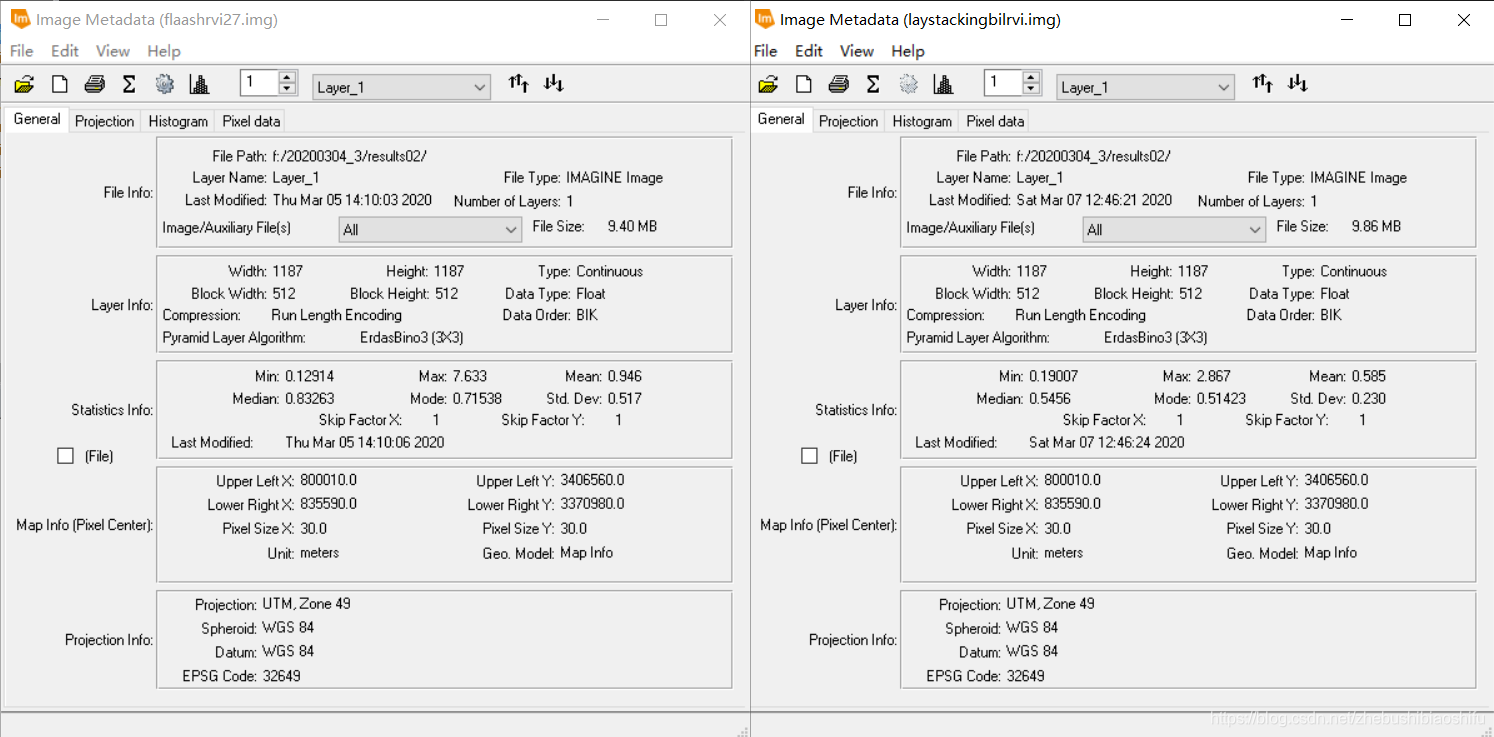
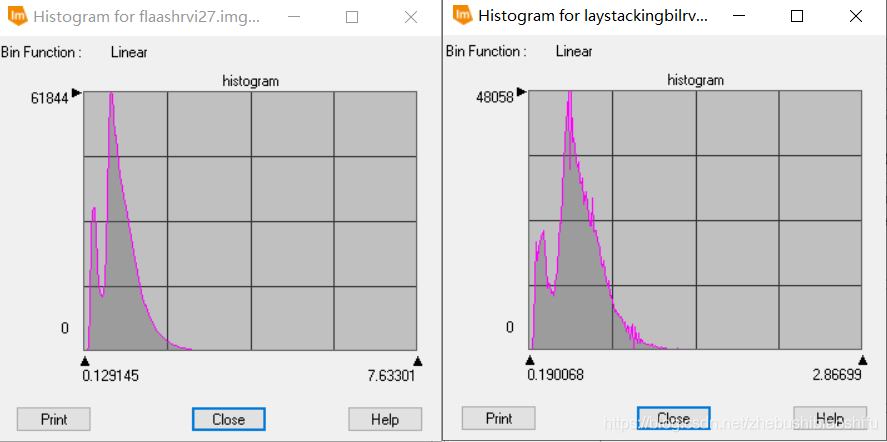
(2) 上图左侧为经过FLAASH大气校正后的图像NDVI信息,右侧为未经过FLAASH大气校正的图像NDVI信息。在数值上,可以看出经过FLAASH大气校正的NDVI数值范围较大,其最小值、最大值分别小于、大于未经过大气校正的NDVI;经过大气校正后NDVI的平均值、中位数与众数均大于未经过大气校正的数值,但二者上述三个指标均小于0;经过大气校正后得到的NDVI数据标准差较之未经过大气校正的数据大。在直方图上,经过大气校正后的NDVI数据分布明显较之未经过大气校正的数据平滑,除-0.65左右处有稍许波动外,其余部分整体较为稳定;未经过大气校正的NDVI数据波动较大,虽然整体趋势和前者一致,但其细节处的起伏十分明显,尤其是0.25左右处。除整体趋势外,经过大气校正与不经过大气校正的NDVI在峰值、谷值等方面亦较为一致。
(3) 上图左侧为经过FLAASH大气校正后的图像RVI信息,右侧为未经过FLAASH大气校正的图像RVI信息。在数值上,可以看出经过FLAASH大气校正的RVI数值范围同样较大,其最小值、最大值分别小于、大于未经过大气校正的RVI,尤其是最大值明显大于后者最大值;经过大气校正后RVI的平均值、中位数与众数同样均大于未经过大气校正的数值,尤其是平均值与中位数,前者明显大于后者,而众数相差相对较小;经过大气校正后得到的RVI数据标准差较之未经过大气校正的数据明显大。在直方图上,经过大气校正后的RVI数据分布同样明显较之未经过大气校正的数据平滑,整体部分较为稳定;未经过大气校正的RVI数据波动较大,虽然整体趋势和前者一致,但其细节处的起伏十分明显,尤其是1.00左右处具有明显波动。除整体趋势外,经过大气校正与不经过大气校正的RVI在峰值、谷值大致位置等方面亦较为一致,但其极值在具体数值上相差明显较之前述NDVI的差距要大。 (4) 上图左侧为经过FLAASH大气校正后的图像DVI信息,右侧为未经过FLAASH大气校正的图像DVI信息。在数值上,可以看出经过FLAASH大气校正的DVI数值范围十分显著大于未经过大气校正的DVI数值,其最小值、最大值分别明显小于、大于未经过大气校正的DVI,其间的差距极其明显,相差可达两个数量级;经过大气校正后DVI的平均值、中位数与众数同样均显著大于未经过大气校正的DVI数值,二者在上述三个指标之间的差距同样达到一个数量级以上;经过大气校正后得到的DVI数据标准差较之未经过大气校正的数据亦明显大。在直方图上,经过大气校正后的DVI数据分布同样明显较之未经过大气校正的数据平滑,整体部分较为稳定;未经过大气校正的DVI数据波动较大,虽然整体趋势和前者一致,但其细节处的起伏十分明显,尤其是大于0部分处具有明显波动。除整体趋势外,经过大气校正与不经过大气校正的RVI在峰值、谷值大致位置等方面亦较为一致,但一致性明显小于NDVI与RVI。关于上述大气校正对DVI数值如此明显的影响,我认为或许就是在FLAASH大气校正时拉伸了原有图像像元取值的整体排布,分别扩大、降低了第三、第四波段对应的最大值与最小值,从而使得两个波段数值做差之后得到的结果进一步出现较大差距。从中也可以看出,用归一化后的DVI数值,即NDVI来展示植被情况是有必要的。 (5) 综合大气校正对上述三种植被指数的数值、分布等影响,可以看出如下几点:首先,大气校正拉伸了各个不同植被指数的数值范围,或许可以认为相当于提升了研究植被的“分辨率”,将各个不同地区之间植被情况的微小差距加大,便于研究;其次,大气校正使得各植被指数分布更加稳定,减少了不必要的波动与异常值,更加方便做定量的遥感研究。 3.2 各类植被指数对比分析(1) 上述三种植被指数在数值与分布等方面的六张结果直方图已在前一部分展示。由上述实验及结果图可以看出,在数值分布上,各类植被指数在分布方面的趋势大致是一致的,例如以上六张直方图中可以明显看到,其各自波峰、波谷的走势,以及升高、降低的位置等整体均较为近似。在具体数值上,三种植被指数具有较大的差异,NDVI将取值范围严格限制在-1至1之间,整体数值小,有利于计算,尤其有利于ERDAS软件、ENVI软件等这些需要手动输入模型或波段公式的操作平台;DVI作为NDVI归一化前的数值,其数据范围较大,除了造成不必要的计算复杂度外,还可能使得不同其它运算对其数值产生较大影响——例如本次实验中FLAASH大气校正对DVI数值的影响十分之大。RVI作为三者中唯一一个不存在做差运算的植被指数,数值分布范围大于NDVI,但明显小于DVI。 (2) 上述三种植被指数在公式计算、代表意义等方面的差异已在本文第一部分原理中提现。 (3) 通过对三种不同植被指数在同一地表位置的多次比较,可以看出:NDVI图像整体相对较为明亮,DVI较暗,而RVI明度最暗。NDVI针对不同地物,如不同植被覆盖度的植被、植被与水体、植被与建筑物等的区分度最大,RVI对于上述这些不同种类的地物区分程度较低,DVI居于二者之间。对于农田等精细的植被分布,同样是NDVI具有最好的辨识效果,RVI效果不明显。在本文第一部分中提到,RVI普遍对植被覆盖度较高的地物具有较好的区别能力,这和得到的结果一致。
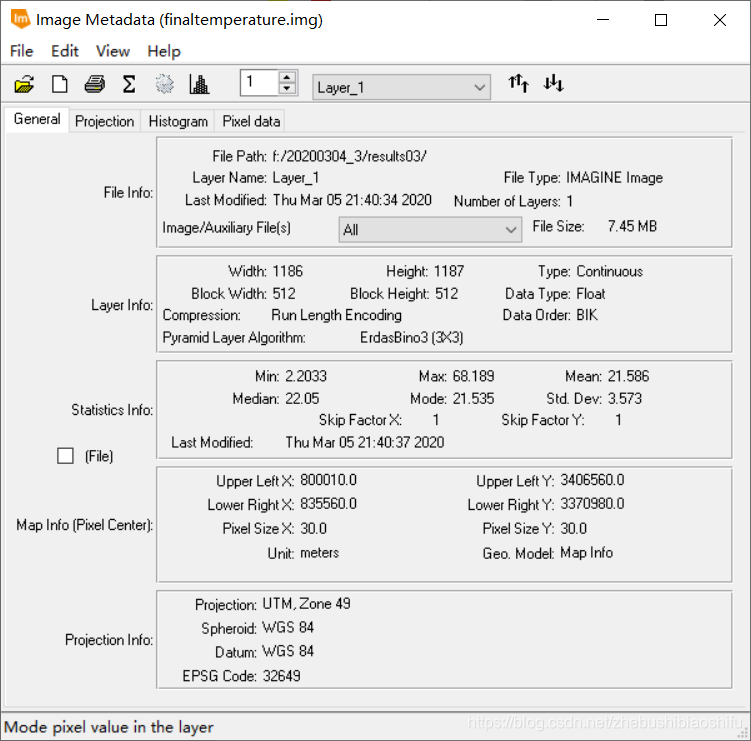
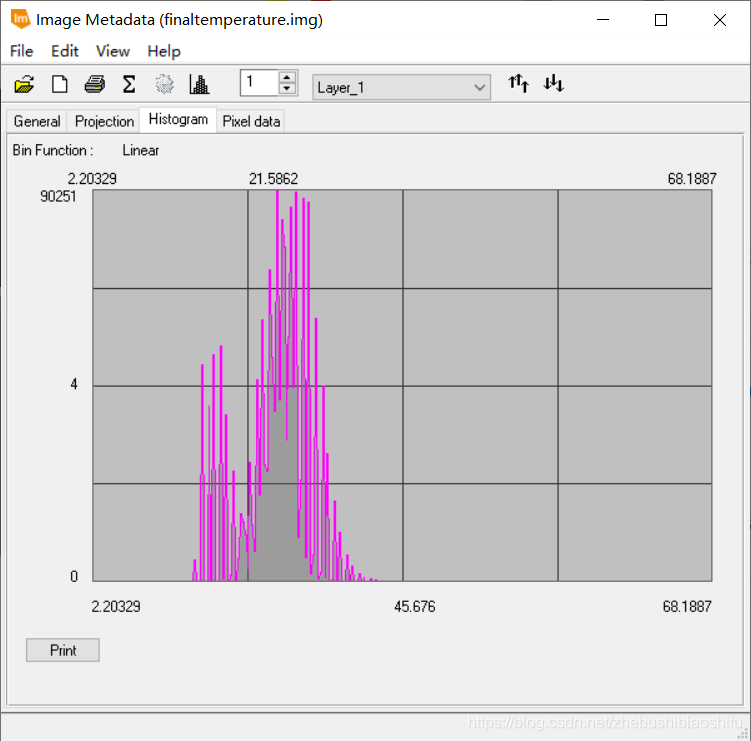
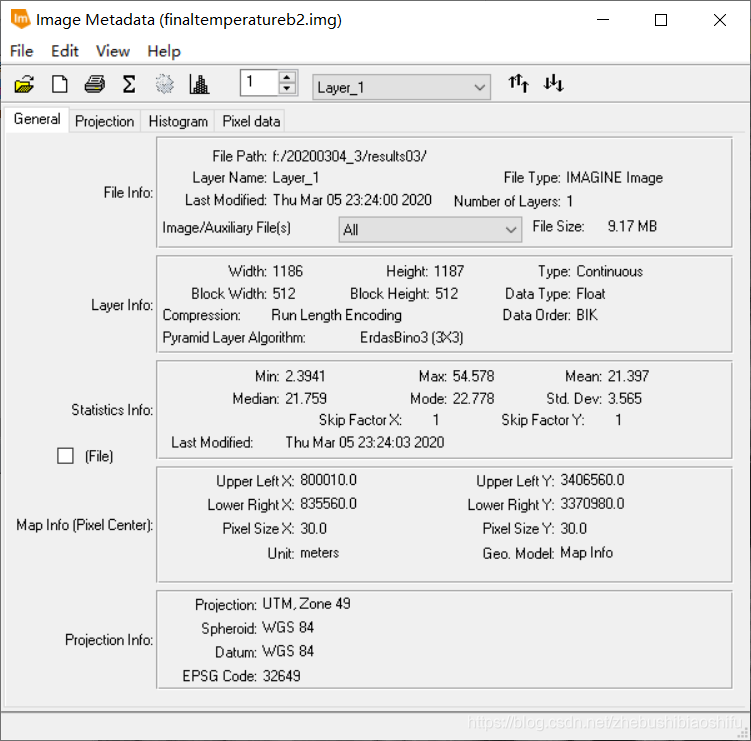
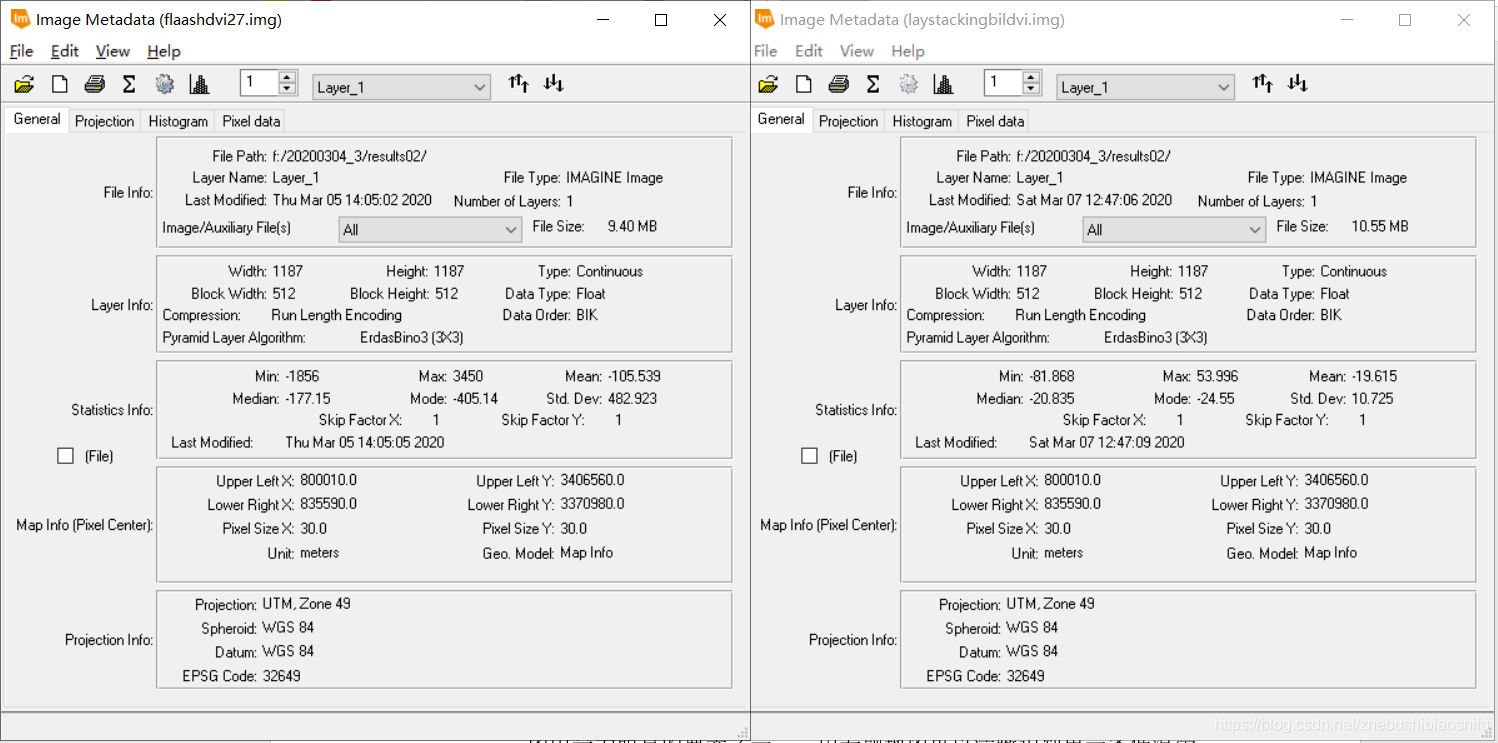
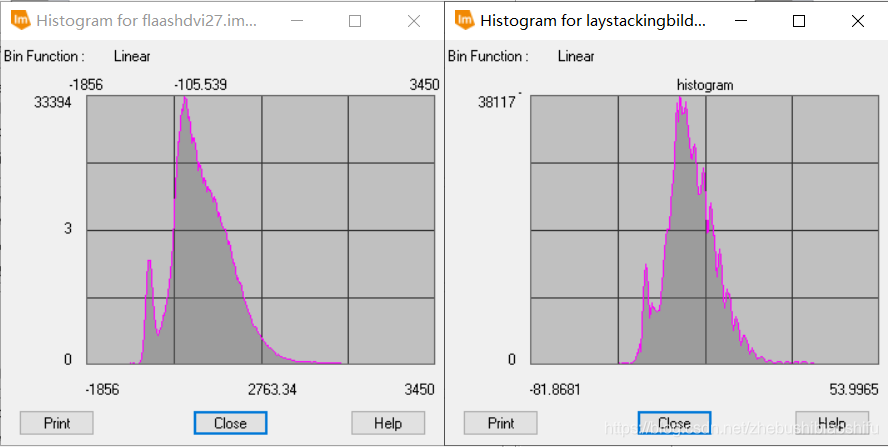
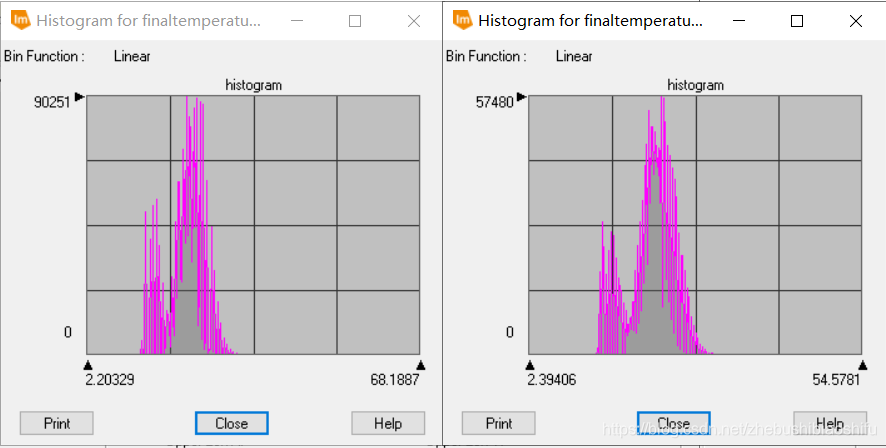
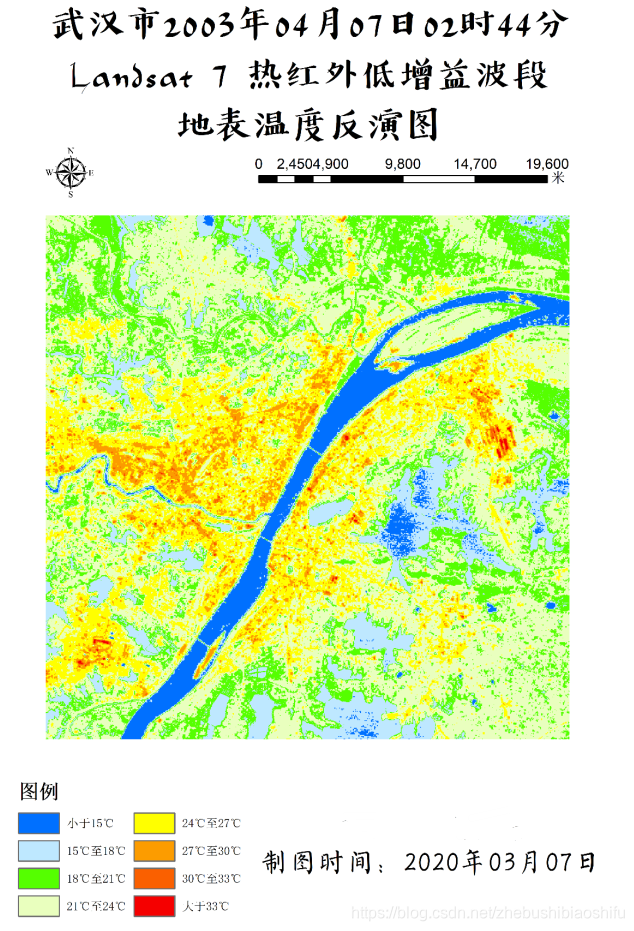
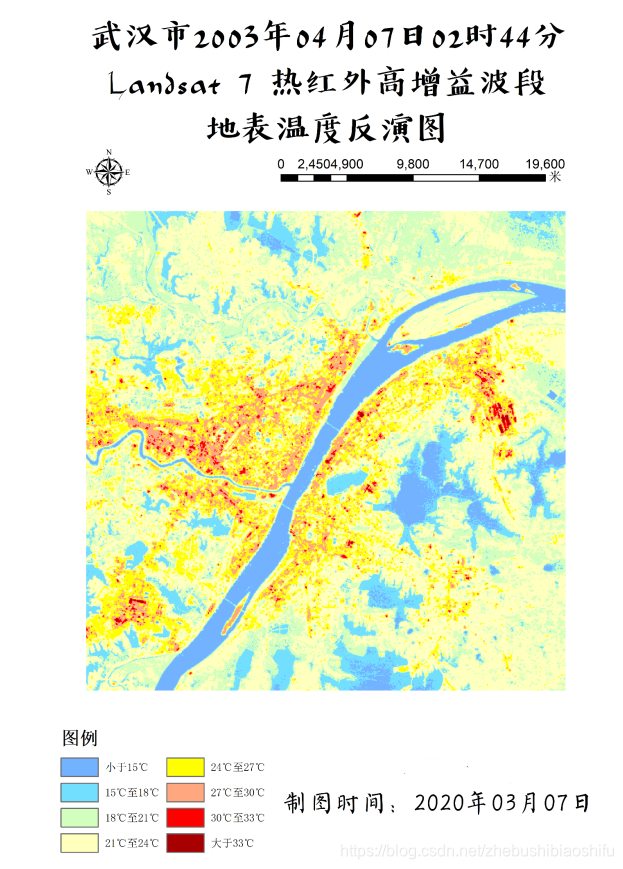
(1) 上图左侧为热红外低增益波段(即B61)反演得到的地表温度结果,右侧则为热红外高增益波段(即B62)反演得到的地表温度结果。在数值上,可以看到,低增益波段反演得到的地表温度结果明显大于高增益波段,其最小值、最大值与平均值均大于高增益波段。此外,低增益波段反演温度的中位数亦略低于高增益波段。而低增益波段反演温度的众数略小于高增益波段。在数值分布上,依据直方图可以看出二者均有部分异常值,其中,偏小的异常值在数值上较为近似,均在2.2至2.3℃左右;而二者的偏大异常值差距较大,低增益波段反演温度较大的异常值高出高增益波段14℃左右。由整体来看,高增益波段得到的温度反演结果较之低增益波段低一些。结合成像时间,为武汉市四月上旬的凌晨,结合上述结果,可知低增益波段与高增益波段得出的温度反演结果均有些偏大;其中,高增益波段得到的温度反演结果更接近实际温度一些。 3.4 专题地图绘制随后即可依据博客2中的方法绘制专题地图。 (1) 将热红外低增益波段与高增益波段得到的温度反演结果制作专题地图,如以上两图所示。 (2) 结合武汉市地表温度反演结果,可以得到如下温度空间变化结果。能够看出,武汉市成像时大部分地区气温主要处于18℃至24℃这一范围内。其中,乔木植被聚集区域温度大多为18℃至21℃之间,即图中的浅绿色区域;农田、灌木等植被聚集区温度较之乔木较高,约在21℃至24℃之间,即图中的浅黄色区域。水体温度多处于18℃以下范围,其中,长江全段大部分区域及后湖、东湖、严西湖、南湖、汤逊湖、黄家湖远岸处水体温度低于15℃,其余大部分水体分布于15℃至18℃区间内。 (3) 城镇区域温度最高,多集中于24℃至30℃区间内,部分人口密集区域温度甚至可达30℃至33℃范围。其中,江汉区大部分地区、汉阳区北部与南部、武昌区与洪山区沿长江一线、青山区东南角武汉火车站一带为城镇中温度明显较高地区,大多数处于27℃左右。而在武汉火车站附近、硚口区三环线东侧与汉阳区江汉大学及东风大道、神龙大道与车城东路汽车产业聚集区一带,出现了全图中的最高温,其温度高于33℃。大范围区域温度最高的区域出现在长江西岸、汉阳区与江岸区交界处。此外,由于划分温度类别较细,还可以看到长江、汉江上温度略高于水体的诸多桥梁。 (4) 整体来看,成像时武汉市高温地区主要集中于长江西岸、汉江北岸的江岸区、硚口区大部分地区,长江东岸沿线武昌区西侧地区,以及青山区西南地区;这些地区普遍温度较高。而对于天兴乡南侧、青山区西南、武汉火车站、汉阳区江汉大学及汽车工业园区地区,其大范围内的整体温度虽没有上述地区高,但个别地区小范围内温度达到城市最高值。此外,武汉市北部大部分地区、东南大部分地区、西南部分地区温度整体偏低。 4 一些思考 4.1 影响单窗温度估算误差的主要因素有哪些?地表辐射率。单窗算法需要用到地表比辐射率这一参数,而我们在温度反演的过程中往往是采取经验法的方式,分别为水体、植被和建筑物地表赋以不同的比辐射率数值,这一过程难免会产生对最终结果的误差。 植被覆盖度。计算地表比辐射率时需要一致植被覆盖度。我们将现实中植被覆盖度这一原本受到多种因素影响、并无精确规律可言的指标模型化,通过公式计算,自然会带来一定误差。 对不同地物类别的划分。不同地物类别(即水体、植被与建筑物)影响到将采取哪一个公式计算该像元上对应的地表比辐射率;本文由将NDVI作为划分依据转变为将监督分类作为划分依据,精度有很大提升,但依然存在一定误差。 大气等效温度。我们通过公式将地面附近气温转换为大气等效温度,无形中同样引入一些误差。 大气透射率、大气含水量。大气含水量决定大气透射率,而大气透射率影响最终地表真实温度反演公式;因此二者均会对温度反演结果产生精度影响。 NDVI与大气校正结果。由本文的结果可以看到,使用不同大气校正参数及不同的大气校正结果影响NDVI数值,而NDVI数值影响植被覆盖度。当然,单窗算法可以不对波段数据加以大气校正处理,若不进行大气校正,所得到的NDVI结果将会只有一个确定的值,从而避免这两个因素带来的误差。 4.2 ERDAS软件建模过程需注意哪些问题?首先,对于建模输入与输出文件的图像数据精度格式需要注意,要选用浮点(即“Float”)类型。因为一般的波段运算操作往往会牵涉到很多精密的小数计算,若将图层保存为整形的数据格式,自然会带来巨大的模型计算误差。 其次,对于模型中的处理函数,若所涉及的公式较为复杂,最好将公式拆开,多设置一些中间图层。这样可以有效减少公式输入错误带来的报错排查难度。 再次,对于一个连贯的操作(如本文中计算地表植被指数、反演地表真实温度等),可以在多个小公式确定无误后,将其连接起来,组成一个完整的计算模型。完整的模型将十分有利于后期重复工作,可将原本需要点击多次的操作简化。 随后,需要更好利用模型中的脚本语言文件,可借助其更加清晰的表达来检查模型的报错。如本文报告中提到的,导出的脚本文件代码语言更加整齐、清晰,较之模型模块中函数编辑窗口更加简洁,可以有效地找出代码错误。 最后,或许是由于软件盗版等原因,部分模型在第一次运行之后,若直接对其修改,可能会出现得到全白色结果图的情况。此时需要将原有模型删除,重新建立。 欢迎关注公众号:疯狂学习GIS
|
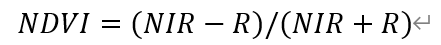 而在计算NDVI时需要注意,所选用的原始遥感影像不能具有过多的云干扰。 RVI又称“绿度”,是指一幅遥感影像中,近红外波段与红光波段的数值或反射率的比值。RVI与植物中LAI(Leaf Area Index,叶面积指数)、叶干生物量、叶绿素含量等指标密切相关,可作为一种绿色植物的灵敏指示参数,同时可用于检测和估算植物体生物量;其能较好反映植被覆盖度和生长状况的差异,特别适用于植被生长旺盛、具有较高覆盖度的植被监测。一般而言,绿色健康植被覆盖地区的RVI远大于1,而对于水体、裸土、不透水面等无植被覆盖地面,RVI值处在1附近。其中,包含植被的地面的RVI值往往大于2。 另一方面,RVI受到大气的影响较为剧烈,因此在计算精确的RVI数值时,需要预先进行大气校正,或使用两个波段的反射率加以计算。本文中,我们将直接利用其定义公式计算RVI,即
而在计算NDVI时需要注意,所选用的原始遥感影像不能具有过多的云干扰。 RVI又称“绿度”,是指一幅遥感影像中,近红外波段与红光波段的数值或反射率的比值。RVI与植物中LAI(Leaf Area Index,叶面积指数)、叶干生物量、叶绿素含量等指标密切相关,可作为一种绿色植物的灵敏指示参数,同时可用于检测和估算植物体生物量;其能较好反映植被覆盖度和生长状况的差异,特别适用于植被生长旺盛、具有较高覆盖度的植被监测。一般而言,绿色健康植被覆盖地区的RVI远大于1,而对于水体、裸土、不透水面等无植被覆盖地面,RVI值处在1附近。其中,包含植被的地面的RVI值往往大于2。 另一方面,RVI受到大气的影响较为剧烈,因此在计算精确的RVI数值时,需要预先进行大气校正,或使用两个波段的反射率加以计算。本文中,我们将直接利用其定义公式计算RVI,即 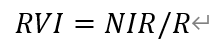 DVI又称“农业植被指数”,是指一幅遥感影像中,近红外波段与红光波段的数值或反射率的差值。DVI对土壤背景的变化较为敏感,能够较好识别植被和水体;其数值随生物量的增加而迅速增大。本文中,我们将直接利用其定义公式计算DVI,即
DVI又称“农业植被指数”,是指一幅遥感影像中,近红外波段与红光波段的数值或反射率的差值。DVI对土壤背景的变化较为敏感,能够较好识别植被和水体;其数值随生物量的增加而迅速增大。本文中,我们将直接利用其定义公式计算DVI,即 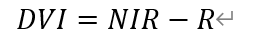 随后,我们利用单窗算法实现武汉地区的地表温度反演。在博客2中,我们利用大气校正法实现地表真实温度的反演;而这一方法由于需要将大气对地表热辐射的影响由卫星传感器所接收到的热辐射总量中减去,因此需要获取图像成像实时的研究区大气剖面数据(如大气水分含量、大气压力等),以求出大气向上辐射亮度L↑、大气向下辐射亮度L↓等参数。而实时获取上述大气剖面数据是较为不易的,因此往往使用标准大气剖面数据代替实时大气剖面数据,对结果加以估计。因而,这样将使得得到的地表反演温度偏离正常值,产生一定误差。
随后,我们利用单窗算法实现武汉地区的地表温度反演。在博客2中,我们利用大气校正法实现地表真实温度的反演;而这一方法由于需要将大气对地表热辐射的影响由卫星传感器所接收到的热辐射总量中减去,因此需要获取图像成像实时的研究区大气剖面数据(如大气水分含量、大气压力等),以求出大气向上辐射亮度L↑、大气向下辐射亮度L↓等参数。而实时获取上述大气剖面数据是较为不易的,因此往往使用标准大气剖面数据代替实时大气剖面数据,对结果加以估计。因而,这样将使得得到的地表反演温度偏离正常值,产生一定误差。 其中,T_s为所求地表真实反演温度,T_b为热红外波段接收到的地表亮度温度,T_a为大气等效温度,其主要取决于大气剖面的气温分布及大气状态;在标准大气状态下,T_a与地面附近气温(一般取地面2米处气温)T_0存在一定线性关系。目前,国内多位学者对这一具体的线性关系已有研究,主要包括以下公式。
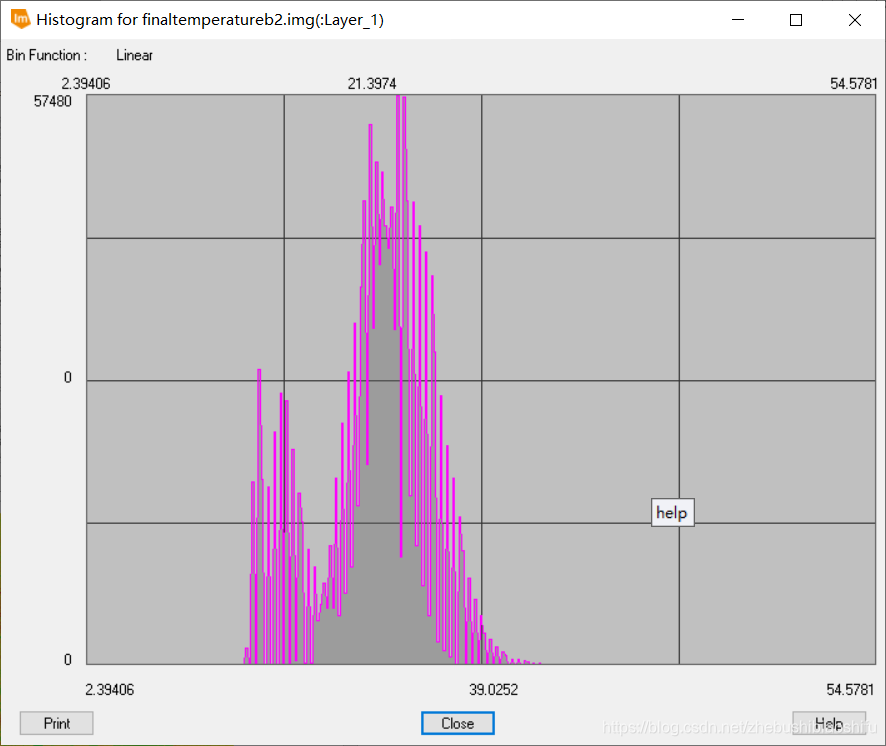
其中,T_s为所求地表真实反演温度,T_b为热红外波段接收到的地表亮度温度,T_a为大气等效温度,其主要取决于大气剖面的气温分布及大气状态;在标准大气状态下,T_a与地面附近气温(一般取地面2米处气温)T_0存在一定线性关系。目前,国内多位学者对这一具体的线性关系已有研究,主要包括以下公式。 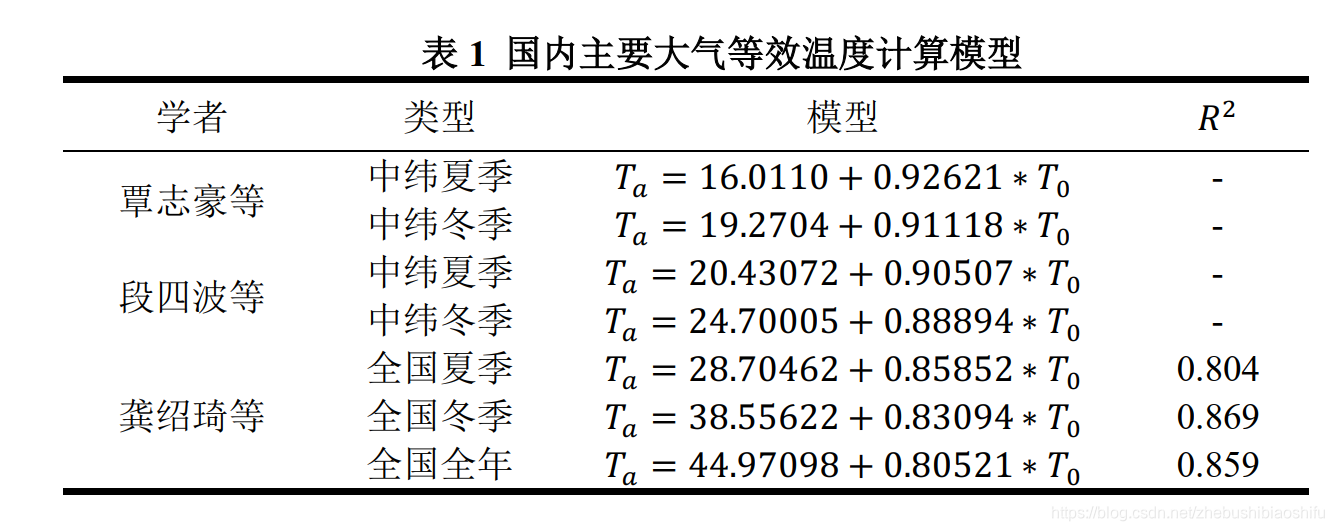 本次实验研究对象为4月上旬的武汉市,因此可以直接使用表中“中纬夏季”或“全国夏季”对应公式;在此我们选择第一个公式。其中,T_0取经验值20℃。 T_s计算式中-67.355351与0.458606为两个经验常量,C与D为中间变量,其计算公式分别为:
本次实验研究对象为4月上旬的武汉市,因此可以直接使用表中“中纬夏季”或“全国夏季”对应公式;在此我们选择第一个公式。其中,T_0取经验值20℃。 T_s计算式中-67.355351与0.458606为两个经验常量,C与D为中间变量,其计算公式分别为:  其中,ε为地表比辐射率,τ为大气透射率。 物体的比辐射率是物体向外辐射电磁波的能力表征,是指在同一温度下地表发射的辐射量与一黑体发射的辐射量的比值。其不仅依赖于地表物体的具体组成,而且与物体的表面状态(如表面粗糙度)及物理性质(如介电常数、含水量等)有关,并随着所测定的波长和观测角度等因素变化。对地表比辐射率的精确定量测量难度较大,因此同博客2一致,本文我们仍然依据经验法对地表比辐射率加以估计:
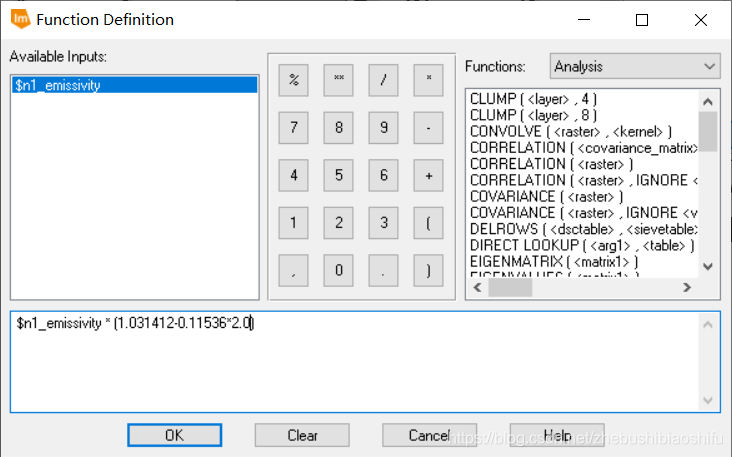
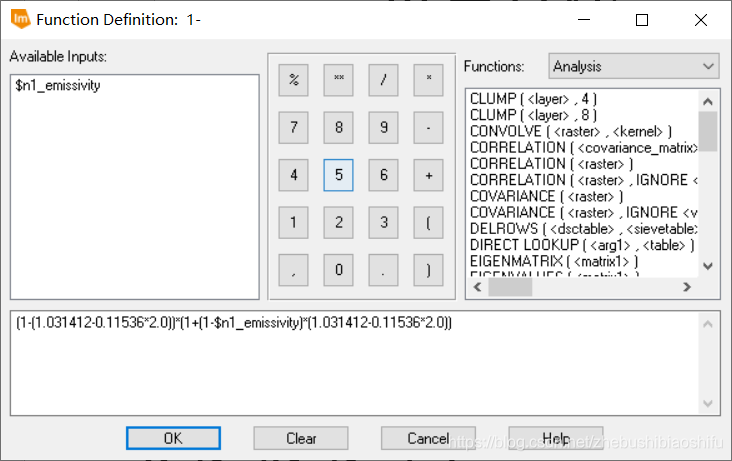
其中,ε为地表比辐射率,τ为大气透射率。 物体的比辐射率是物体向外辐射电磁波的能力表征,是指在同一温度下地表发射的辐射量与一黑体发射的辐射量的比值。其不仅依赖于地表物体的具体组成,而且与物体的表面状态(如表面粗糙度)及物理性质(如介电常数、含水量等)有关,并随着所测定的波长和观测角度等因素变化。对地表比辐射率的精确定量测量难度较大,因此同博客2一致,本文我们仍然依据经验法对地表比辐射率加以估计: 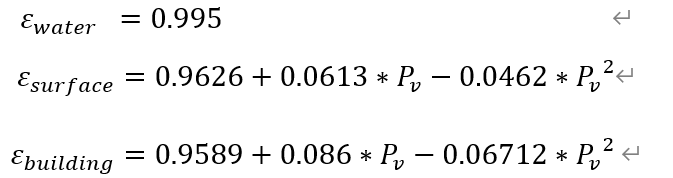 由公式可知,不同的地物对应不同的地表比辐射率计算方法。在博客2中,我们直接利用研究区各个像元NDVI的取值估计其所对应的地表状态;这样的计算方法虽然简便,但会带来一定误差。因此,本次我们选择利用ERDAS软件中的“Supervised Classification”模块对水体、植被与建筑等不同地物加以区分,从而提高分类精度。 其中,P_v为对应区域的植被覆盖度。植被覆盖度有如下两个不同的计算公式:
由公式可知,不同的地物对应不同的地表比辐射率计算方法。在博客2中,我们直接利用研究区各个像元NDVI的取值估计其所对应的地表状态;这样的计算方法虽然简便,但会带来一定误差。因此,本次我们选择利用ERDAS软件中的“Supervised Classification”模块对水体、植被与建筑等不同地物加以区分,从而提高分类精度。 其中,P_v为对应区域的植被覆盖度。植被覆盖度有如下两个不同的计算公式: 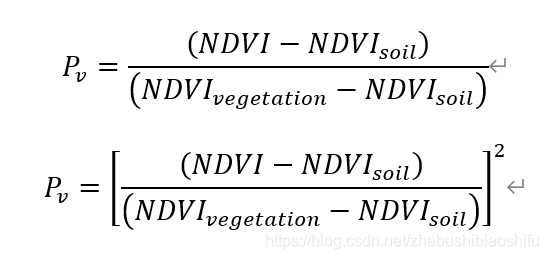 其中,〖NDVI〗_soil为裸土的NDVI数值,〖NDVI〗_vegetation为植被的NDVI数值。如果图像范围内有明显的茂密植被区,则取这一区域的平均NDVI作为〖NDVI〗_vegetation的值;同理,若图像范围内有明显的裸露土地,则可取这一区域的平均NDVI作为〖NDVI〗_soil的值。一般地,我们亦可以令〖NDVI〗_vegetation为经验值0.7,〖NDVI〗_soil为经验值0.05;NDVI超出〖NDVI〗_vegetation时,我们可以认为其为植被覆盖地区,P_v为1;NDVI低于〖NDVI〗_soil时,我们可以认为其为裸土、水体等,P_v为0。 针对上述P_v的两个不同计算公式,有文献指出第一个公式得到的地表真实温度反演结果偏高,建议使用第二个公式;而亦有文献并未对两种不同公式加以优劣评价。 大气透射率τ主要取决于大气水分含量。大气含水量ω为卫星过境时地面附近(一般取地面2米处)的大气含水量。对于夏季而言,不同的大气含水量对应不同的τ计算公式:
其中,〖NDVI〗_soil为裸土的NDVI数值,〖NDVI〗_vegetation为植被的NDVI数值。如果图像范围内有明显的茂密植被区,则取这一区域的平均NDVI作为〖NDVI〗_vegetation的值;同理,若图像范围内有明显的裸露土地,则可取这一区域的平均NDVI作为〖NDVI〗_soil的值。一般地,我们亦可以令〖NDVI〗_vegetation为经验值0.7,〖NDVI〗_soil为经验值0.05;NDVI超出〖NDVI〗_vegetation时,我们可以认为其为植被覆盖地区,P_v为1;NDVI低于〖NDVI〗_soil时,我们可以认为其为裸土、水体等,P_v为0。 针对上述P_v的两个不同计算公式,有文献指出第一个公式得到的地表真实温度反演结果偏高,建议使用第二个公式;而亦有文献并未对两种不同公式加以优劣评价。 大气透射率τ主要取决于大气水分含量。大气含水量ω为卫星过境时地面附近(一般取地面2米处)的大气含水量。对于夏季而言,不同的大气含水量对应不同的τ计算公式:  本次实验中,大气含水量ω取经验值2.0。 热红外波段接收到的地表亮度温度T_b即相当于对热红外波段进行辐射定标后,再进一步处理的结果。本次实验所用Landsat 7 ETM+影像的热红外低增益波段(即B61)、高增益波段(即B62)分别对应如下不同的两个定标公式:
本次实验中,大气含水量ω取经验值2.0。 热红外波段接收到的地表亮度温度T_b即相当于对热红外波段进行辐射定标后,再进一步处理的结果。本次实验所用Landsat 7 ETM+影像的热红外低增益波段(即B61)、高增益波段(即B62)分别对应如下不同的两个定标公式:  通过上述公式计算得出的是对应波段的热辐射强度L_ℷ,还需要进行下一步计算才可以转换为地表亮度温度T_b。其中,两个热红外波段对应的地表亮度温度计算公式一致:
通过上述公式计算得出的是对应波段的热辐射强度L_ℷ,还需要进行下一步计算才可以转换为地表亮度温度T_b。其中,两个热红外波段对应的地表亮度温度计算公式一致: 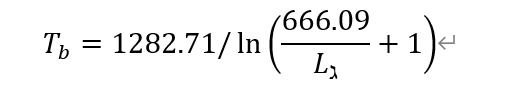
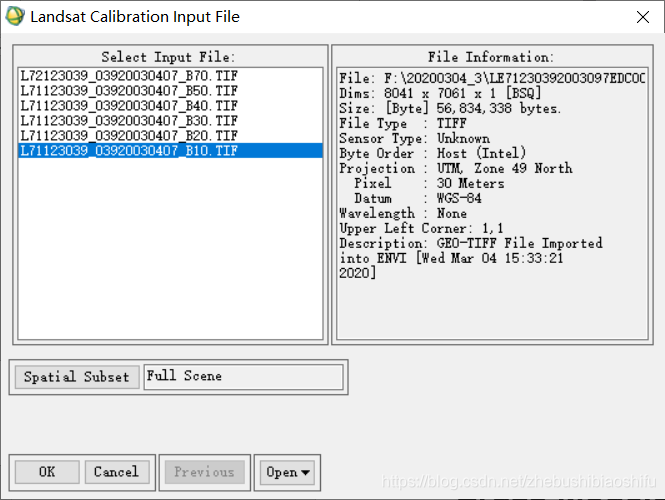 (3) 在弹出的属性配置窗口中调整待定标卫星图像对应的传感器、数据获取日期、太阳高度角、对应波段数、电磁波类型(辐射或反射)、文件存储方式及地址等信息。其中,与卫星有关的信息可以由卫星图像的元数据信息中获取。
(3) 在弹出的属性配置窗口中调整待定标卫星图像对应的传感器、数据获取日期、太阳高度角、对应波段数、电磁波类型(辐射或反射)、文件存储方式及地址等信息。其中,与卫星有关的信息可以由卫星图像的元数据信息中获取。 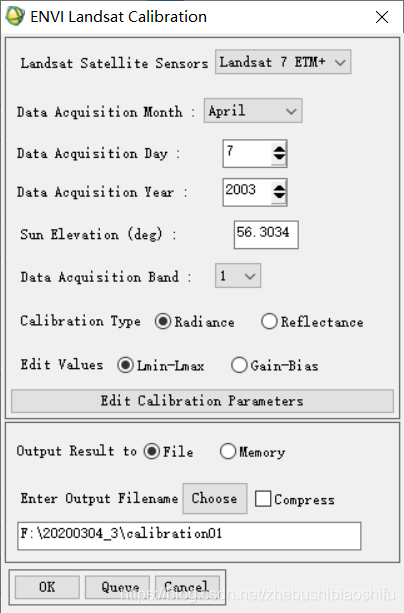
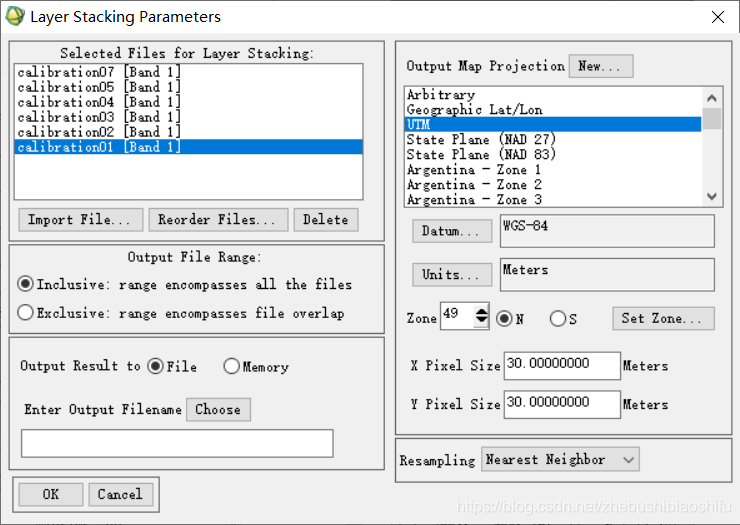 (2) 选择后,需要观察六幅图像在待合成文件列表中的排列顺序。由于后期我们需要对合成后的图像各个波段的信息进行折线图形式的分析操作,因此需要将待合成文件按照“中心波长值”由小至大的顺序排列。点击“Reorder Files”即可实现这一功能。 (3) 顺序排列完毕后,检查投影信息等无误后,点击“OK”即可开始合成操作。
(2) 选择后,需要观察六幅图像在待合成文件列表中的排列顺序。由于后期我们需要对合成后的图像各个波段的信息进行折线图形式的分析操作,因此需要将待合成文件按照“中心波长值”由小至大的顺序排列。点击“Reorder Files”即可实现这一功能。 (3) 顺序排列完毕后,检查投影信息等无误后,点击“OK”即可开始合成操作。 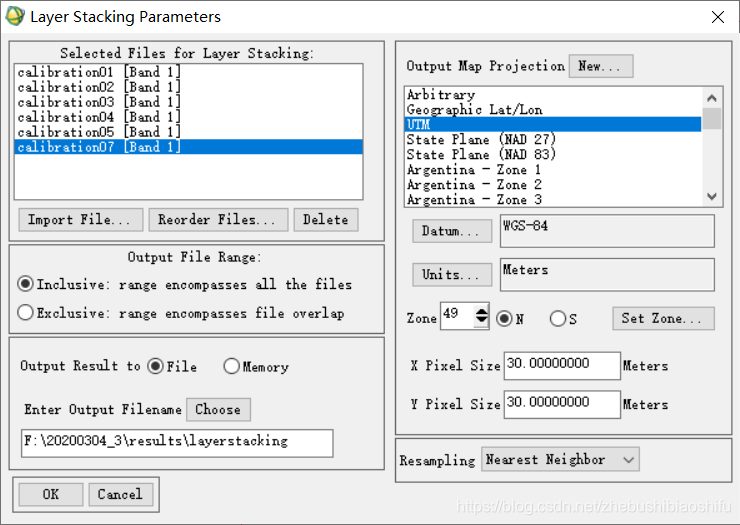

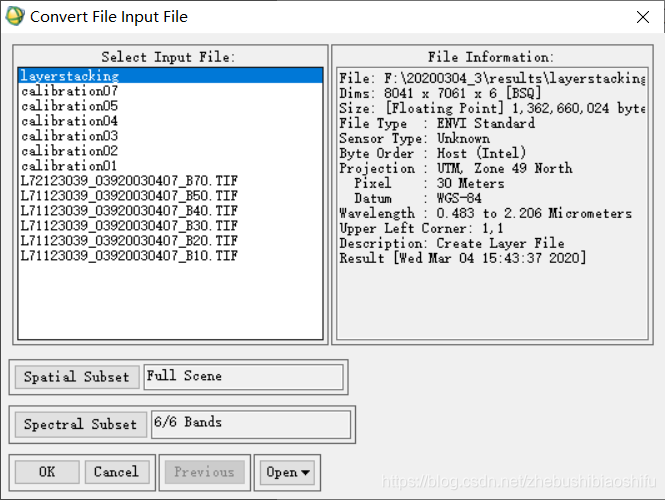
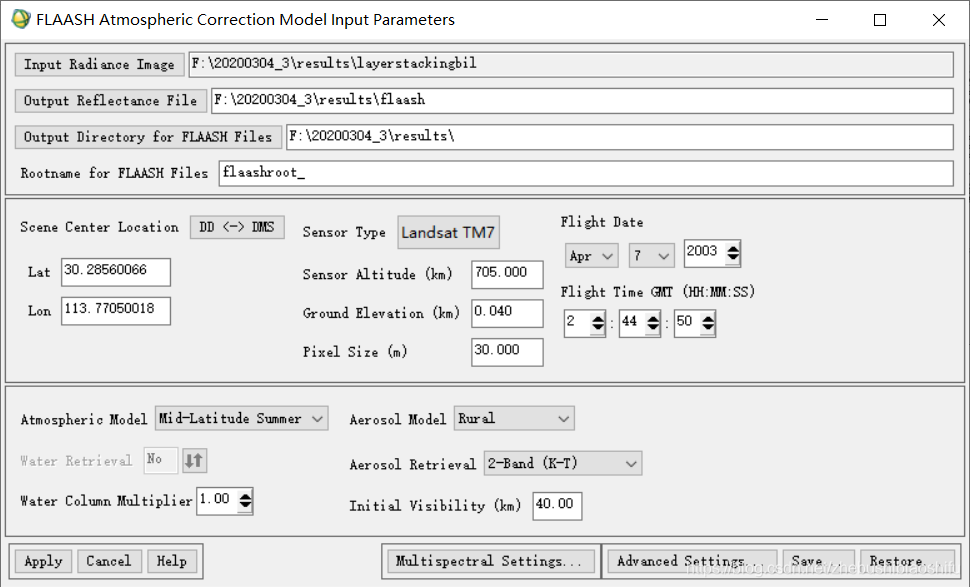
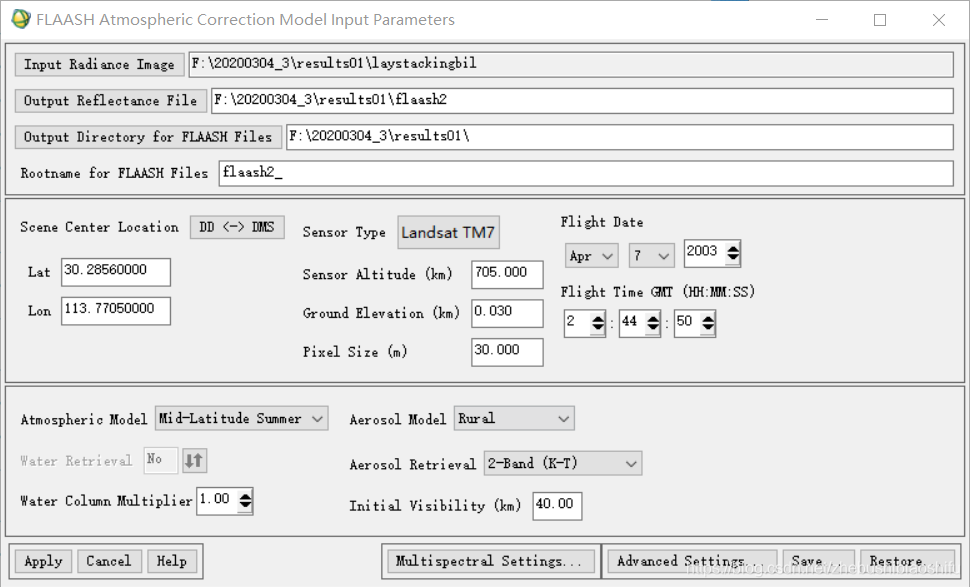
 (2) 在随后弹出的配置对话框中,首先选择输入图像文件、输出图像文件目录及名称,同时依据遥感影像的元数据,配置其中心点经纬度、传感器类型(传感器类型一旦选定,系统将会自动匹配传感器高度与像元大小这两个参数)、航行时间;同时依据实际研究区的情况,配置平均海拔高度这一选项;其次,选择合适的地球大气模型和气溶胶模型。其中,地球大气模型需要根据一张标准查找表确定,气溶胶模型则依据研究区域实际情况加以确定。前期操作时,设置FLAASH大气校正参数如下;但后期发现这样的设置有问题。具体更改附在本文2.9部分,大家有需要可以直接暂时跳过本部分进入2.9部分查看问题所在。
(2) 在随后弹出的配置对话框中,首先选择输入图像文件、输出图像文件目录及名称,同时依据遥感影像的元数据,配置其中心点经纬度、传感器类型(传感器类型一旦选定,系统将会自动匹配传感器高度与像元大小这两个参数)、航行时间;同时依据实际研究区的情况,配置平均海拔高度这一选项;其次,选择合适的地球大气模型和气溶胶模型。其中,地球大气模型需要根据一张标准查找表确定,气溶胶模型则依据研究区域实际情况加以确定。前期操作时,设置FLAASH大气校正参数如下;但后期发现这样的设置有问题。具体更改附在本文2.9部分,大家有需要可以直接暂时跳过本部分进入2.9部分查看问题所在。
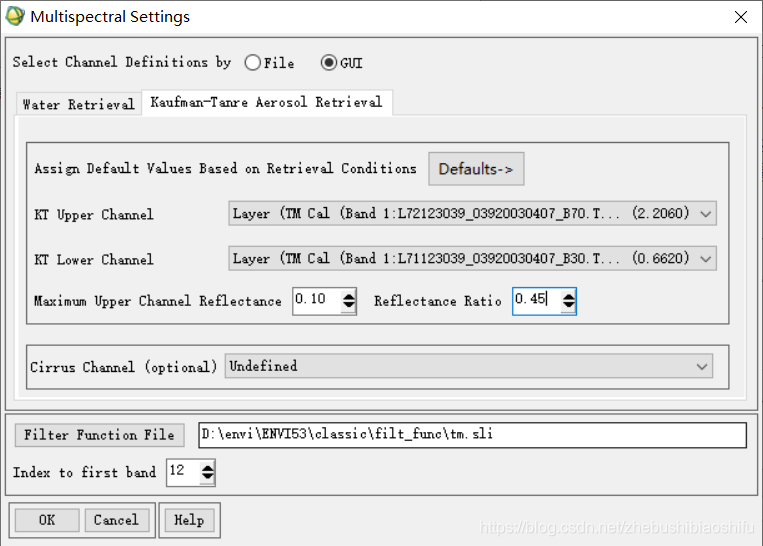 (3) 接下来,选择“Multispectral Settings”。当基本设置中设置了水汽反演模型和气溶胶模型时,我们需要相应地将多光谱相关属性加以配置,配置完毕后点击“OK”。 (4) 全部设置完毕后,可以点击右下角的“Save”按钮,从而将本次对于FLAASH方法的全部属性配置保存;在后期若对同样的遥感数据进行同样的操作时,保存属性配置可以免去多次重复调整相关参数的工作,从而提高效率。 (5) 点击“Apply”,将会开始执行FLAASH大气校正。得到结果后,同样得到一份结果日志。
(3) 接下来,选择“Multispectral Settings”。当基本设置中设置了水汽反演模型和气溶胶模型时,我们需要相应地将多光谱相关属性加以配置,配置完毕后点击“OK”。 (4) 全部设置完毕后,可以点击右下角的“Save”按钮,从而将本次对于FLAASH方法的全部属性配置保存;在后期若对同样的遥感数据进行同样的操作时,保存属性配置可以免去多次重复调整相关参数的工作,从而提高效率。 (5) 点击“Apply”,将会开始执行FLAASH大气校正。得到结果后,同样得到一份结果日志。 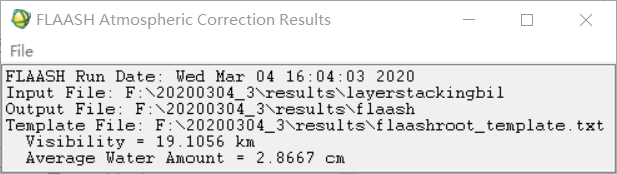

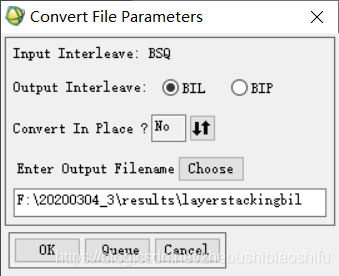
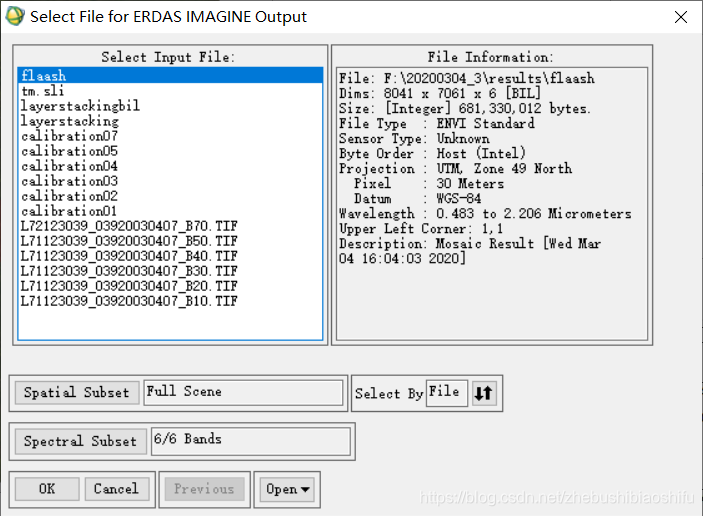 (2) 在弹出的转换文件属性配置窗口中设置,配置好结果图像文件保存路径、保存文件名等。
(2) 在弹出的转换文件属性配置窗口中设置,配置好结果图像文件保存路径、保存文件名等。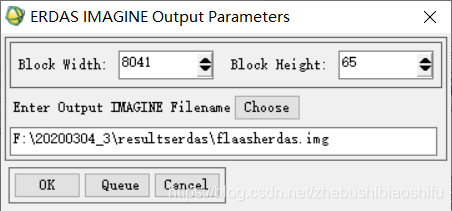
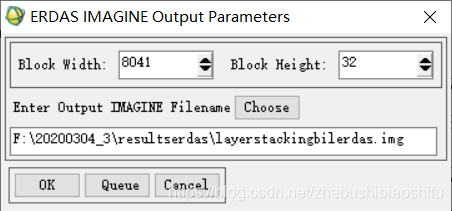 (3) 如本文第一部分原理部分所示,单窗算法亦可以使用未经过辐射定标与大气校正的数据计算NDVI数值。本次实验需要比较经过与不经过大气校正得到的植被指数的差异,因此在将FLAASH大气校正后的结果图像转换完毕后,还需要将未经过大气校正、转换过数据存储格式的“BIL”格式文件同样转换为“ERDAS IMAGINE”格式文件。
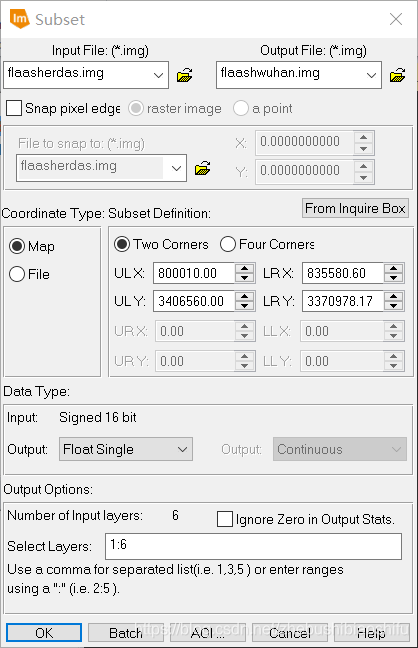
(3) 如本文第一部分原理部分所示,单窗算法亦可以使用未经过辐射定标与大气校正的数据计算NDVI数值。本次实验需要比较经过与不经过大气校正得到的植被指数的差异,因此在将FLAASH大气校正后的结果图像转换完毕后,还需要将未经过大气校正、转换过数据存储格式的“BIL”格式文件同样转换为“ERDAS IMAGINE”格式文件。 (2) 选择“Raster”→“Subset & Chip”→“Create Subset Image”,在弹出的文件裁剪配置窗口中选择经过FLAASH大气校正后的“.img”结果图像,配置输出文件路径和文件名,并选择输出图像文件格式为“Float Single”,在下方“AOI”选项中选择武汉市AOI文件,点击左下角“OK”选项。
(2) 选择“Raster”→“Subset & Chip”→“Create Subset Image”,在弹出的文件裁剪配置窗口中选择经过FLAASH大气校正后的“.img”结果图像,配置输出文件路径和文件名,并选择输出图像文件格式为“Float Single”,在下方“AOI”选项中选择武汉市AOI文件,点击左下角“OK”选项。 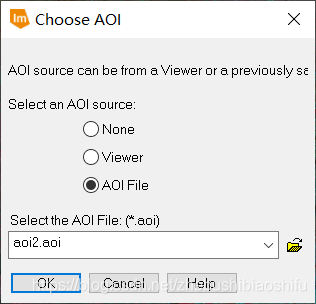
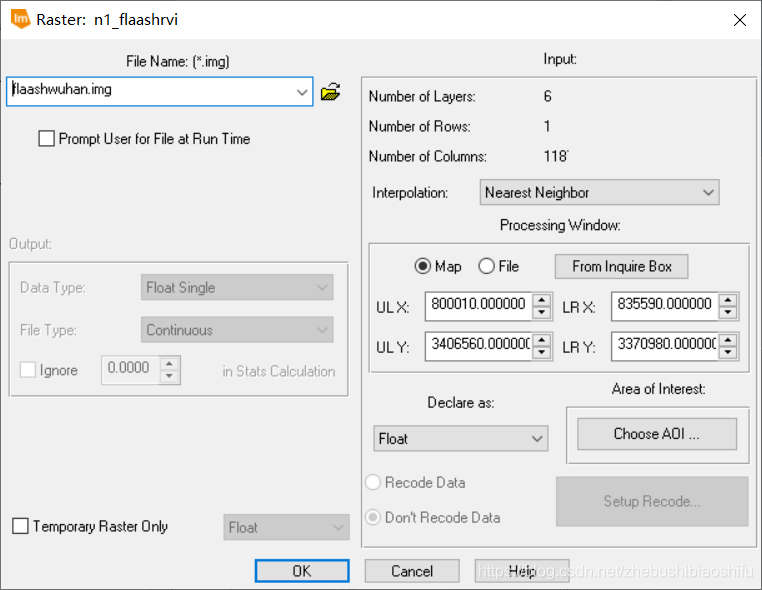 (2) 分别建立三个模型,输入文件均为经过剪裁的武汉市大气校正图像,输出文件分别对应NDVI、RVI与DVI图像文件,而处理函数则分别使用本文第一部分对应的不同植被指数计算公式。调试无误后分别保存模型文件。
(2) 分别建立三个模型,输入文件均为经过剪裁的武汉市大气校正图像,输出文件分别对应NDVI、RVI与DVI图像文件,而处理函数则分别使用本文第一部分对应的不同植被指数计算公式。调试无误后分别保存模型文件。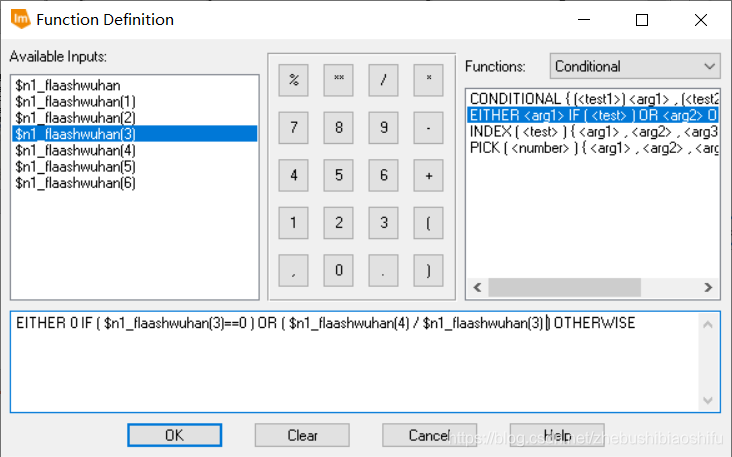
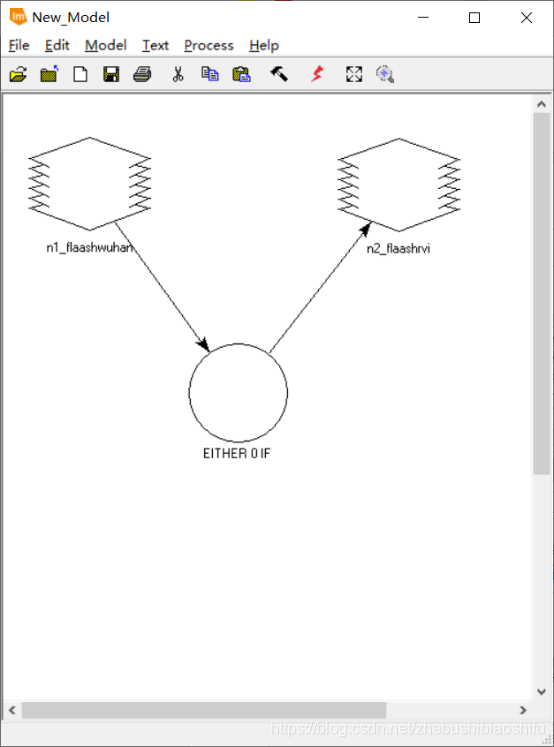 (3) 需要注意的是,本次实验涉及到小数计算较多,需要在配置模型输入文件与输出文件时注意选择“Float”格式,从而避免计算结果被四舍五入的情况。
(3) 需要注意的是,本次实验涉及到小数计算较多,需要在配置模型输入文件与输出文件时注意选择“Float”格式,从而避免计算结果被四舍五入的情况。 (4) 多个单一模型调试无误并保存后,可以将其合并在一个新的模型中,从而实现多个操作一步完成。
(4) 多个单一模型调试无误并保存后,可以将其合并在一个新的模型中,从而实现多个操作一步完成。 

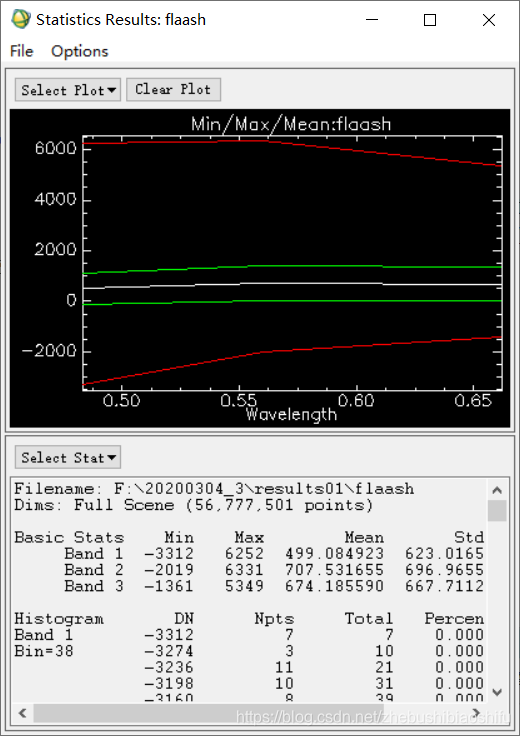 一般地,FLAASH大气校正结果中多存在部分负值情况,尤其是高分辨率图像数据。这些负值像元经常分布在校正后图像中的阴影、水体及边缘等区域,蓝色波段也常常会出现负值像元较多的情况。 而如果负值较多,如负值像元个数占图像总像元数量的5%以上,有为不正常状态,往往可能是数据本身、参数设置等方面因素造成错误的校正结果。 (1) 通过ENVI软件中“Quick Stats”模块,可以看到我的大气校正结果第一波段数据中,数值小于等于-6的像元个数已经占据了全图的近32%部分,即出现的负值较多。
一般地,FLAASH大气校正结果中多存在部分负值情况,尤其是高分辨率图像数据。这些负值像元经常分布在校正后图像中的阴影、水体及边缘等区域,蓝色波段也常常会出现负值像元较多的情况。 而如果负值较多,如负值像元个数占图像总像元数量的5%以上,有为不正常状态,往往可能是数据本身、参数设置等方面因素造成错误的校正结果。 (1) 通过ENVI软件中“Quick Stats”模块,可以看到我的大气校正结果第一波段数据中,数值小于等于-6的像元个数已经占据了全图的近32%部分,即出现的负值较多。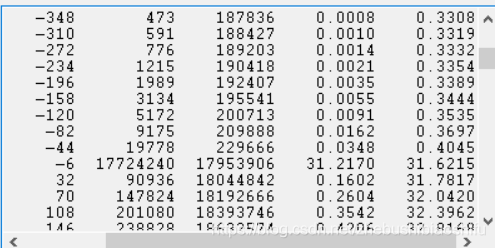
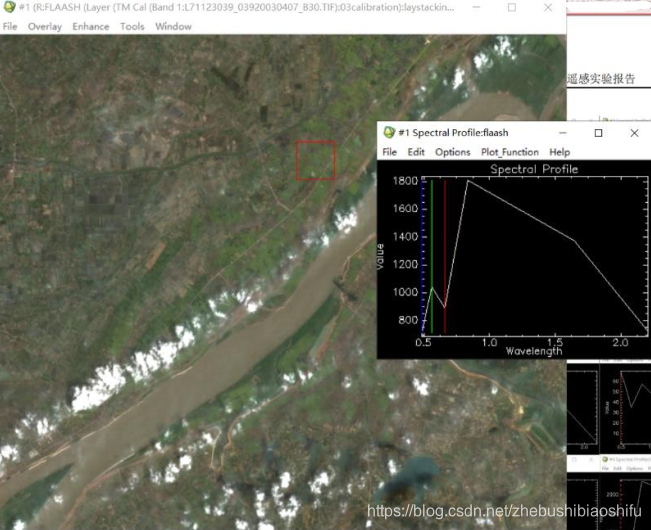



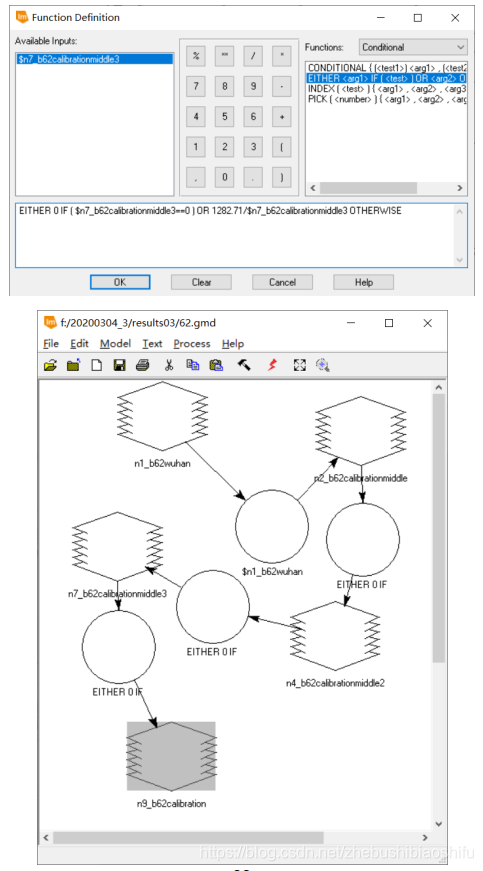
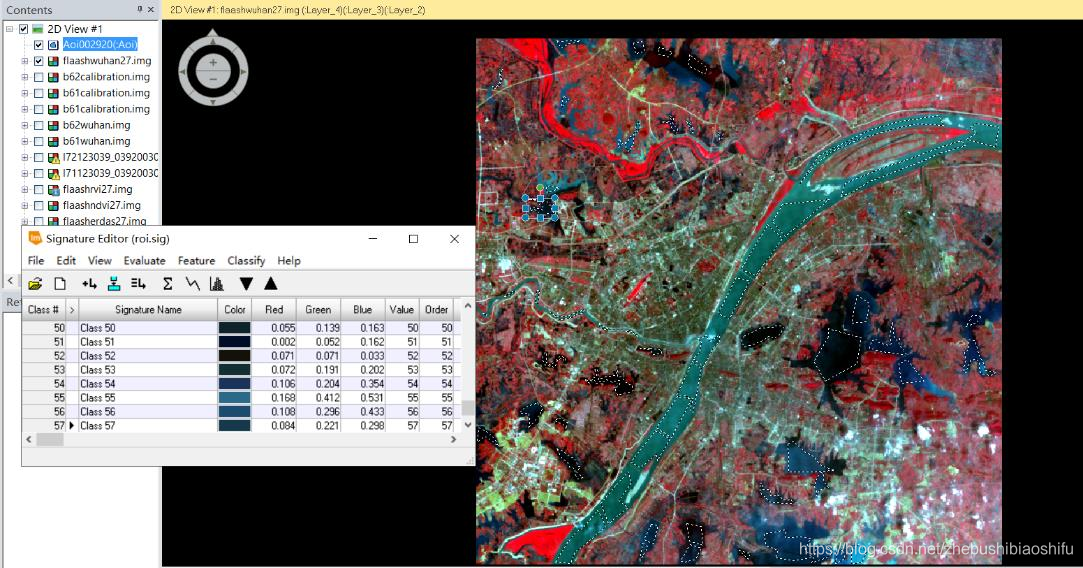
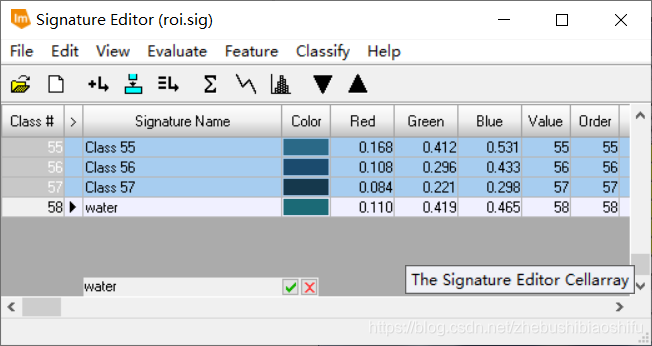
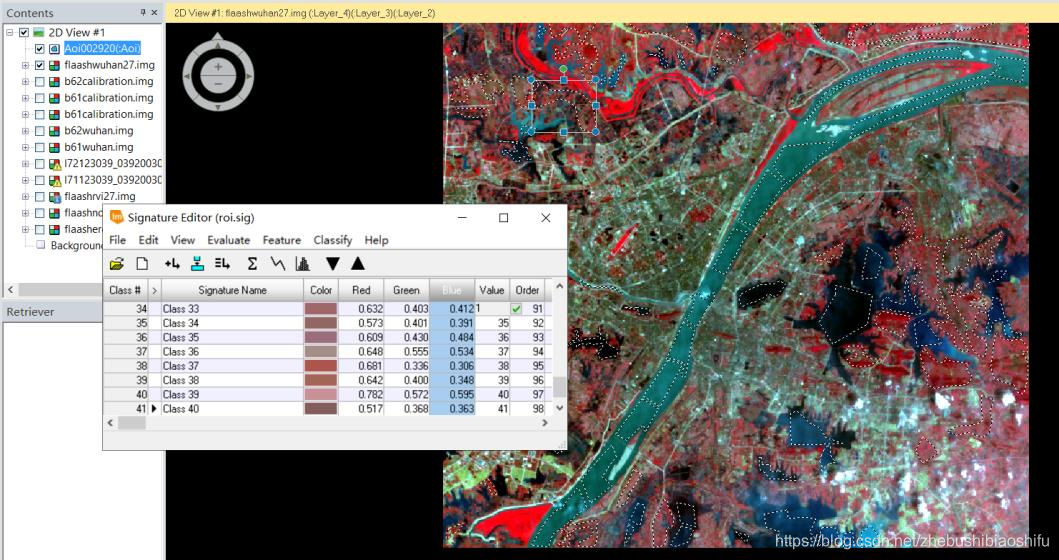
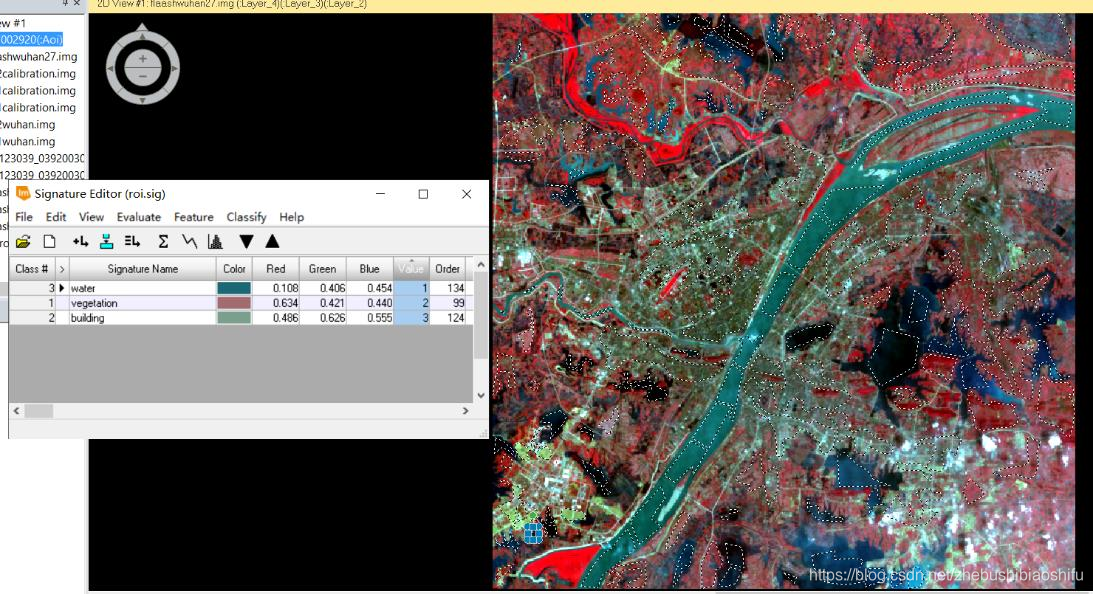
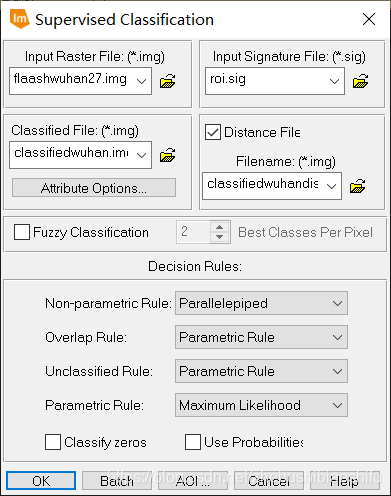

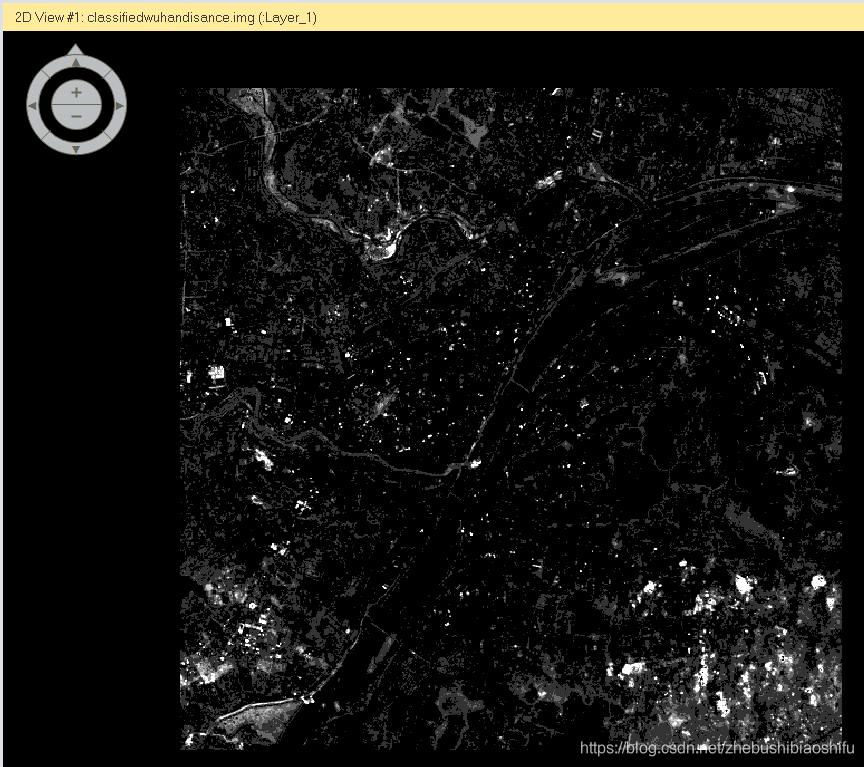 (6) 上图为验证监督分类结果精度的DISTANCE文件,其中距离数值即为该像素数值与具体分类对应类别的差距。这一文件可以衡量最终监督分类的效果。
(6) 上图为验证监督分类结果精度的DISTANCE文件,其中距离数值即为该像素数值与具体分类对应类别的差距。这一文件可以衡量最终监督分类的效果。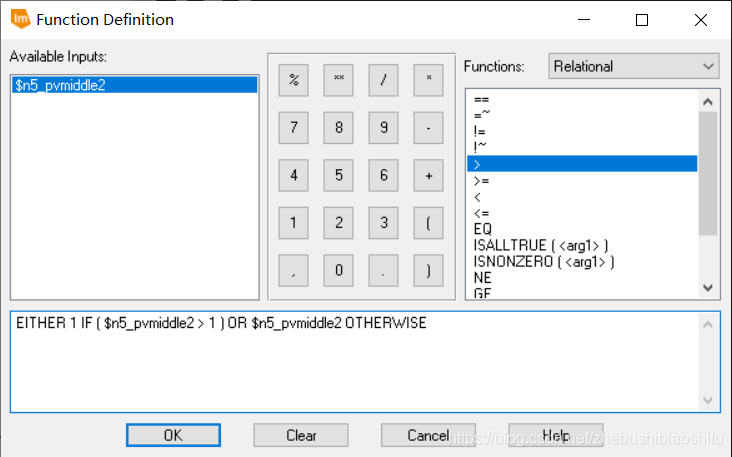 (2) 需要注意,当NDVI大于0.7或小于0.05时,对应的地表植被覆盖度分别取1和0。若不注意这一过程,会使得得到的植被覆盖度图像数值超出0-1这一界限。
(2) 需要注意,当NDVI大于0.7或小于0.05时,对应的地表植被覆盖度分别取1和0。若不注意这一过程,会使得得到的植被覆盖度图像数值超出0-1这一界限。 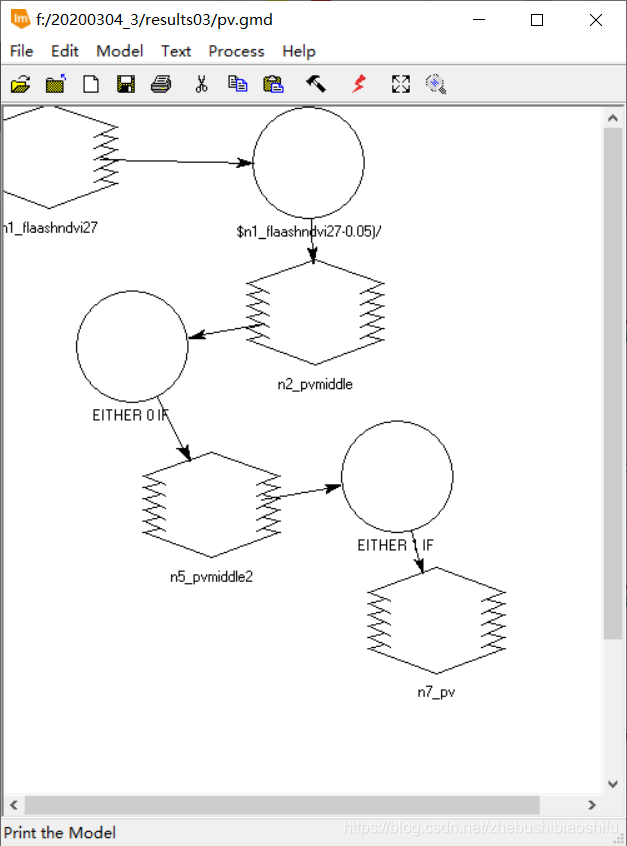
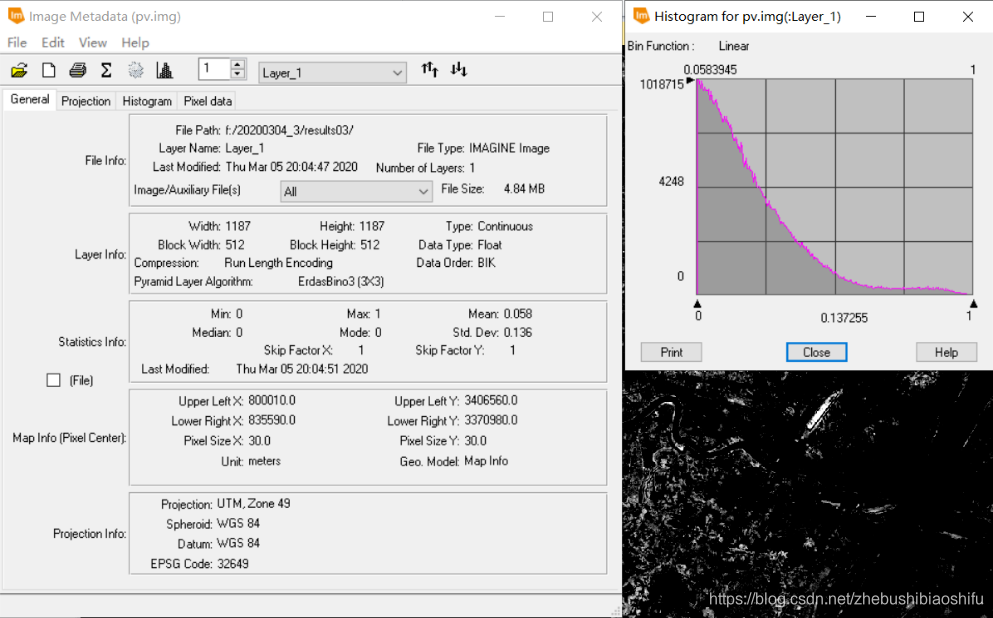 (4) 利用求得的地表植被覆盖度文件进一步求出地表比辐射率,此实需要用到上述监督分类结果。
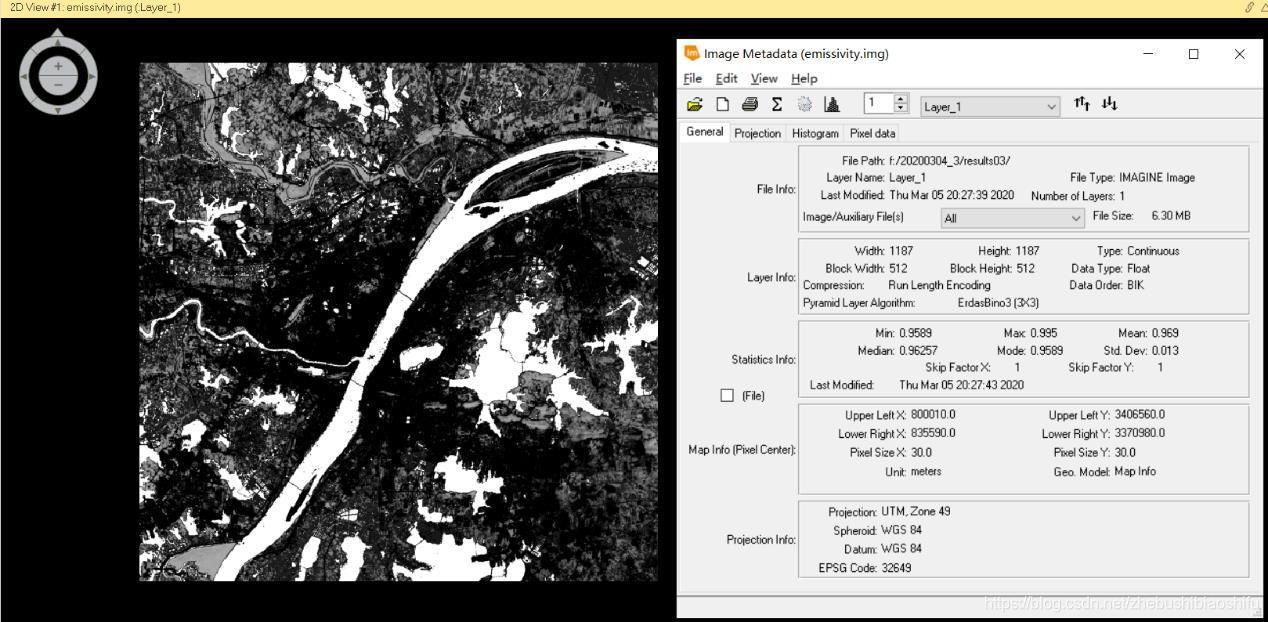
(4) 利用求得的地表植被覆盖度文件进一步求出地表比辐射率,此实需要用到上述监督分类结果。 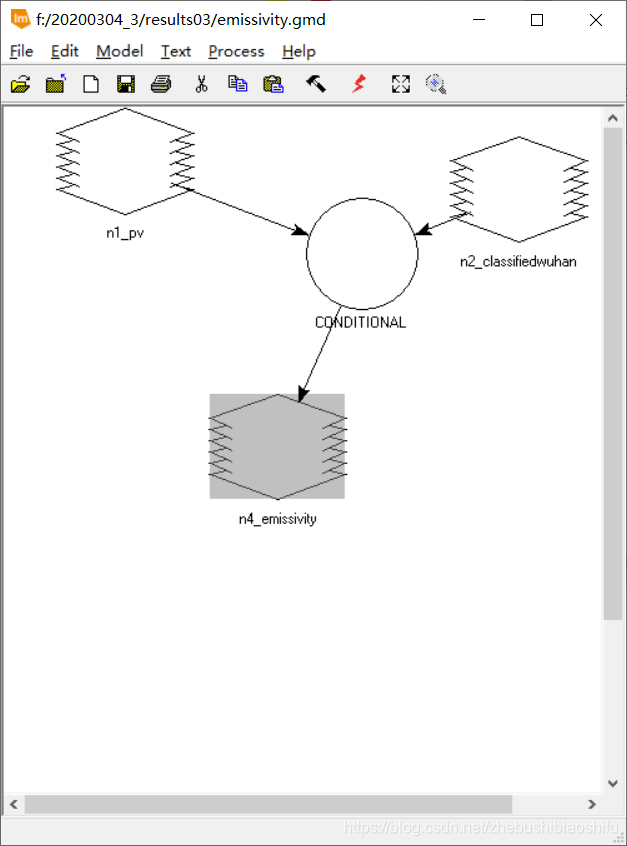


【本文地址】