内存地址、机器码与汇编指令的三角恋关系 |
您所在的位置:网站首页 › 汇编内存地址如何表示 › 内存地址、机器码与汇编指令的三角恋关系 |
内存地址、机器码与汇编指令的三角恋关系
|
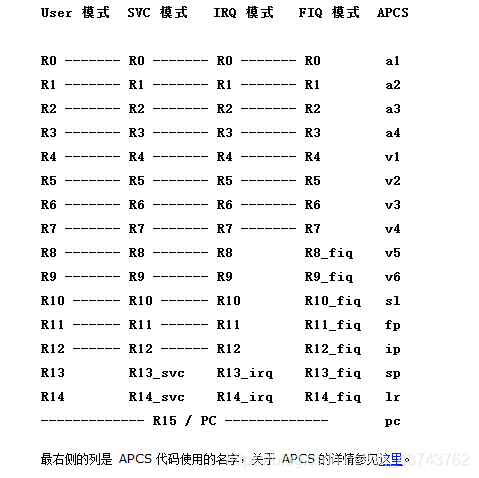
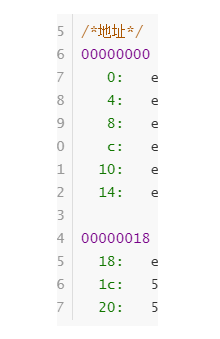
虽然机器码和内存地址领证在一起了,但是俩个人都和汇编指令有着说不清的关系,机器码的前任是汇编指令,而汇编指令又与内存地址暗地相通,这究竟是道德的沦丧还是人性的扭曲,今天就让我来领大家细细分解这三者的前世今生!!! 文章目录 一.原汇编代码二.反汇编代码三.三角恋关系1.汇编指令与内存地址的关系2.机器码与汇编指令3.内存地址与机器码之前我们使用汇编语言编写了点亮LED程序,.S文件通过FTP传到Ubuntu中,通过交叉编译工具生成.bin文件传回本机,然后通过oflash烧写进裸机的Nand FLASH,从而点亮LED。 这里分析一下汇编代码在此过程中的意义,内存地址、机器码与汇编指令三者之间的联系。 一.原汇编代码汇编代码如下: .text .global _start _start: ;程序从这里开始 ldr r1, =0X56000050 ;将地址存在r1 ldr r0, =0X100 ;将值存在r0 str r0, [r1] ;将r0的值写入[]中的地址 ldr r1, =0X56000054 ;同上 ldr r0, =0 str r0, [r1] halt: ;死循环 b halt ;一直跳转到halt简单解释一下代码: 要点亮LED,就要将GPF4引脚输出低电平,通过在GPFCON和GPFDAT寄存器中的对应位写入值来实现,即对0X56000050地址中写入0X100,对0X56000054地址中写入0 。 用到的汇编代码指令如下: ldr(load):读内存命令 str(store):写内存命令 b:跳转 mov(move):赋值 二.反汇编代码编译器会将汇编指令转换成机器码,而机器码又存放在内存地址中!!!通过反汇编指令可以得到反汇编文件,里面有内存地址、机器码与汇编指令三者的对应关系!!! 机器码就是.bin文件的十六进制形式,一组机器码有32位,ARM一次也能够处理32位的数据,这些知识都是相统一的。 通过将汇编代码,传到Linux中可以进行编译,然后生成.bin文件,当然也可以通过交叉编译工具的反汇编,生成机器码和处理后的标准的汇编码,反汇编文件为.dis文件,反汇编文件中可以查看内存地址、机器码与汇编指令三者之间的联系: led_on.elf: file format elf32-littlearm Disassembly of section .text: /*地址*/ /*机器码*/ /*汇编指令*/ 00000000 : 0: e59f1014 ldr r1, [pc, #20] ; 1c 4: e3a00c01 mov r0, #256 ; 0x100 8: e5810000 str r0, [r1] c: e59f100c ldr r1, [pc, #12] ; 20 10: e3a00000 mov r0, #0 ; 0x0 14: e5810000 str r0, [r1] 00000018 : 18: eafffffe b 18 1c: 56000050 undefined 20: 56000054 undefined在S3C2440中,CPU有各种寄存器,如图:
左边是各种寄存器,右边是寄存器的别名,下面介绍一下比较重要的几个寄存器: pc(program counter)是程序计数器,当把一个地址写入pc寄存器中,CPU就会跳转到这个地址去取指令。 lr(link register)是返回地址寄存器,当程序执行完一个调用函数时,要跳转回原来的地址,这个**lr寄存器中存放就是原来的地址,**调用函数执行完毕后,只需要转到lr中的地址就可以继续执行程序了。 sp(stack point)是栈指针 三.三角恋关系 1.汇编指令与内存地址的关系下面分析一下汇编指令与内存地址之间的关系 说明一下:为什么俩条相邻指令的内存地址差为4? 这是因为内存地址的单位都是Byte,也就是8位(bit),而且ARM是32位的,一次只能够处理32位指令,也就是4Byte的指令,所以指令的内存存放都是以4Byte为单位的。 第一条指令,要知道pc中的地址是当前指令的地址+8,因为ARM执行指令是流水线式的,比如当前执行地址a的指令,已经在对地址a+4的指令进行译码,已经在读取地址a+8的指令,也就是说,当前pc中存放的是a+8的值(第三条指令的地址)。就拿第一个指令来讲([x]代表:x地址): 此时pc中的值是第三条指令的地址,也就是8,结合[pc, #20],代表[8+20],也就是28地址,即[0X1C],这条指令代表去0X1C地址读取内存上的值,放在r1寄存器中,可以看出0X1C地址中存放的值为:
第二条指令直接将256(0X100)的值放在了r0寄存器中; 第三条指令就是将r0寄存器中的值0X100,写入地址为r1(0X56000050)的内存; 接下来三条指令,与前三条原理相同; 后面的halt死循环指令中
b 18就代表程序跳转到地址为18的地方去 取指令,执行指令 然鹅这条指令的地址就是18,所以会陷入一个死循环。 此外,可以看出汇编指令在内存中的地址都是连续的,就连汇编指令中的一些数据的内存地址都是紧跟在代码地址后面的,好奇妙哦。为什么要在最后面执行死循环呢?就是防止程序跑完之后,再跑到别的地方去。
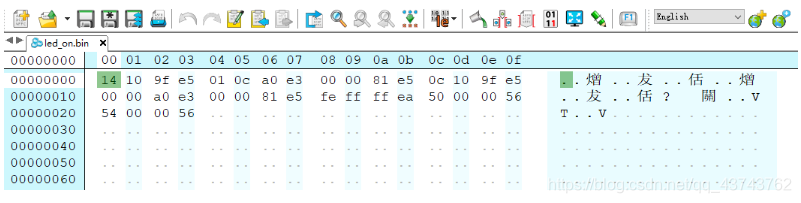
程序编译后我们得到了.bin文件,这里又有机器码,实际上机器码的内容与.bin文件完全一致,只是码制不一样,下面查看一下.bin文件的内容:
bin文件中的,这里显示的是按照地址从小到大的排布,所以第一个指令是:e59f1014,与上面的机器码完全一致。 3.内存地址与机器码了解了上面的关系后,也不难理解,机器码就是时间存放在内存地址中的数据!!! 所以,ARM一次能够处理32位的数据或指令,这指令就是指一条汇编指令,一条汇编指令的内存量就是32位,也就是4Byte,所以汇编指令与机器码之间必然有者某种关系,时其维持着这种对应关系(一条汇编指令始终对应32位机器码),也就是说,汇编指令都是有相应的机器码格式的。 可以去ARM的架构手册中查找相应汇编指令对应的机器码格式,比如mov指令: 可以看出,MOV指令确实是32位机器码的格式, 用上面的代码来说明一下:
首先搞出机器码的二进制形式,这样有对比性:
[15:12]=0,表示Rd寄存器是r0寄存器; [11:0]这12位代表了mov的参数,就是这12位的内容,这里与0X100对应,0X100叫做立即数,但我们发现这12位的内容与0X100并不一致呀,为什么呢? 实际上这12位数据,拆分为了高四位[11:8]的rotate数和低八位[7:0]的immed_8数,0X100叫做立即数,他们之间的转换关系为: 立即数 = immed_8数 循环右移 (2xroute数)位 相当于0X1循环右移24位,最终还是0X100 所以当了解了这些知识后,会加深我们对于程序运行的理解,从机器码,到汇编指令,再到C语言,再到其他语言,程序员使用的语言越来越多样化,可以实现程序的方式越来越多,但最终都是回到了机器码这一步,因为机器码才是CPU使用的!!! 可以拟人化的说: 机器码是存放在内存中的,所以机器码和内存地址是在一起的 机器码是由汇编指令编译来的,所以说汇编指令是机器码前任 汇编指令又与内存地址有着读写关系,所以说汇编指令和暗地相通 (滑稽脸) |


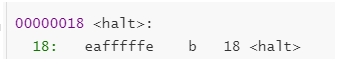



【本文地址】
今日新闻 |
推荐新闻 |