|
基于皮尔逊相关系数的用户相似推荐算法python实现
随着电子商务规模的不断扩大,商品个数和种类快速增长,顾客需要花费大量的时间才能找到自己想买的商品。这种浏览大量无关的信息和产品过程无疑会使淹没在信息过载问题中的消费者不断流失。 为了解决这些问题,个性化推荐系统应运而生。个性化推荐系统是建立在海量数据挖掘基础上的一种高级商务智能平台,以帮助电子商务网站为其顾客购物提供完全个性化的决策支持和信息服务。 推荐系统是利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程。个性化推荐是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品。 协同过滤(Collaborative Filtering)算法是推荐系统中最早诞生的算法之一,并且在推荐系统领域也是使用最多最普遍的推荐算法,协同过滤的原理是首先给目标用户找出其相似用户,通过相似用户的喜好进而挖掘出目标用户的喜好。这里面其实就涉及到协同过滤算法的两个主要的功能,其一是目标用户找出相似用户的过程,这个过程可以称为预测过程,其二是相似用户的喜好挖掘目标用户的喜好,这个过程可以称为推荐过程,在预测过程我们通过会使用目标用户的行为及日志等用户信息去挖掘目标用户的偏好模型,然后通过这个偏好模型再去找出相似带有该偏好模型的用户,而在推荐过程我们会采用这些带有相似偏好模型的用户喜好的物品推荐给目标用户。其实这个过程可以用日常生活中的例子来阐述,我们去看电影的时候,会经常遇到看什么电影的问题,当看到电影传单上所有的电影时,我们又很难确定看哪个电影,而这个时候我们通常会问朋友或同学,通过去询问或者打听看哪部电影,而通常问的这个朋友或者同学是兴趣爱好相似比较信任的。这个过程可以很生动的描述推荐系统的核心思想。
同过皮尔逊相关系数仍然可以得到用户关于物品的推荐得分,可通过如下公式,另外代码如下 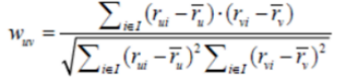
import math
def UserSimilarity(records):
# record=[{user:ul,item:a,value:4},.... .... ,]
item_user = dict()
ave_vote = dict()
activity = dict()
for r in records:
addToMat(item_user, r['item'], r['user'], r['value'])
addToVec(ave_vote, r['user'], r['value']) # 用户每一件物品评分求和 ave_vote{u1:17,u2:10,u3:6}
addToVec(activity, r['user'], 1) # 求物品数量和 activity{u1:4,u2:3,u3:2}
print(ave_vote)
ave_vote = {u: sum_value / activity[u] for u, sum_value in ave_vote.items()} # 用户物品评分平均值
nu = dict() # nu同一用户每一物品-其评分均值后平方求和
W = dict()
for i, ri in item_user.items():
# item_users{a:{u1:4,u2:3},b:{u1:3,u2:4,u3:4},c:{u1:5,u3:2},d:{u1:5,u2:3}}
RI = set()
for u, rui in ri.items():
addToVec(nu, u, (rui - ave_vote[u]) * (rui - ave_vote[u])) # 同一用户每一物品评分-其平均值后平方再求和(公式分母)
RI.add(u)
for v, rvi in ri.items():
if u == v:
continue
addToMat(W, u, v, (rui - ave_vote[u]) * (rvi - ave_vote[v]))#相似计算公式分子
print("----------------------------------------------------")
# 相似计算的分子diffSqu_ave_value
for u in W:
W[u] = {v: diffSqu_ave_value / math.sqrt(nu[v] * nu[u]) for v, diffSqu_ave_value in W[u].items()}#通过公式计算出用户对于物品的相似系数,并存于W
return W
# item_users{a:{u1:4,u2:3},b:{u1:3,u2:4,u3:4},c:{u1:5,u3:2},d:{u1:5,u2:3}}
def addToMat(dicts, index, k, v): # 列表记录中,行(字典)中某一列(index)为第一层键,对应k:v构成其值,值为字典类型
if index not in dicts:
dicts[index] = dict()
dicts[index][k] = v
else:
if k not in dicts[index]:
dicts[index][k] = v
else:
dicts[index][k] = dicts[index][k] + v
def addToVec(dicts, user, v): # 列表记录中,行(字典)中某一列的分类数量数量统计,每次加入V
if user not in dicts:
dicts[user] = v
else:
dicts[user] = dicts[user] + v
record = [{'user': 'u1', 'item': 'a', 'value': 4},
{'user': 'u1', 'item': 'b', 'value': 3},
{'user': 'u1', 'item': 'd', 'value': 5},
{'user': 'u1', 'item': 'c', 'value': 5},
{'user': 'u2', 'item': 'a', 'value': 3},
{'user': 'u2', 'item': 'b', 'value': 4},
{'user': 'u2', 'item': 'd', 'value': 3},
{'user': 'u3', 'item': 'b', 'value': 4},
{'user': 'u3', 'item': 'c', 'value': 2}
]
w = UserSimilarity(record)
# print('最终结果:')
# print(w)
import operator
def RecUser(u, record, W, K):
user_items = dict()
for r in record:
addToMat(user_items, r['user'], r['item'], r['value'])
print('****************************')
print(user_items)
RecU = {}
norm = 0
keys = operator.itemgetter(1)
for v, wuv in sorted(W[u].items(), key=operator.itemgetter(1), reverse=True)[0:K]: # 根据计算出的相似度进行排序
# print(v)
for item, rvi in user_items[v].items():
if item in user_items[u]: # 找到该用户(u1)还未购买的商品
continue
RecU[item] = 0
print("Recu", RecU)
AverV = {}
for v, wuv in sorted(W[u].items(), key=operator.itemgetter(1), reverse=True)[0:K]:
n = 0
for rvi in user_items[v].values(): # 获取近似用户的商品评分
if v not in AverV.keys():
AverV[v] = 0
AverV[v] += rvi
n += 1
AverV[v] = AverV[v] / n # 计算平均分
n = 0
for item, rvi in user_items[u].items(): # 获取目标用户购买的商品及评分
if u not in AverV.keys():
AverV[u] = 0
AverV[u] += rvi
n += 1
AverV[u] = AverV[u] / n # 计算平均分
print("AverV", AverV)
for i, rui in RecU.items():
dr = 0
allW = 0
for v, wuv in sorted(W[u].items(), key=operator.itemgetter(1), reverse=True)[0:K]:
if i in user_items[v].keys():
# print(W[u][v], user_items[v][i], AverV[v], wuv)
dr += W[u][v] * (user_items[v][i] - AverV[v]) # 相似度物品均分差
allW += abs(wuv) # 取绝对值
RecU[i] = AverV[u] + dr / allW # 得出一个相对的目标用户是否会购买的字典
# print("dwd", RecU)
print("给用户", u, "推荐", RecU)
return RecU
record = [{'user': 'u1', 'item': 'a', 'value': 4},
{'user': 'u1', 'item': 'b', 'value': 3},
{'user': 'u1', 'item': 'd', 'value': 5},
{'user': 'u1', 'item': 'c', 'value': 5},
{'user': 'u2', 'item': 'a', 'value': 3},
{'user': 'u2', 'item': 'b', 'value': 4},
{'user': 'u2', 'item': 'd', 'value': 3},
{'user': 'u3', 'item': 'b', 'value': 4},
{'user': 'u3', 'item': 'e', 'value': 2}
]
w = UserSimilarity(record)
print("此程序結果为:")
print(w)
RecUser("u1", record, w, 1)
|