为什么要先将损失函数求和(平均)再反向传播loss.mean().backward() |
您所在的位置:网站首页 › 求和为什么是1 › 为什么要先将损失函数求和(平均)再反向传播loss.mean().backward() |
为什么要先将损失函数求和(平均)再反向传播loss.mean().backward()
|
import torch
import torch.optim as optim
# 输入数据
x = torch.tensor([1.0, 2.0, 3.0, 4.0], requires_grad=True)
# 目标值
y_true = torch.tensor([2.0, 4.0, 6.0, 8.0])
# 定义模型参数
w = torch.tensor(0.0, requires_grad=True)
b = torch.tensor(0.0, requires_grad=True)
# 定义线性回归模型
def linear_regression(x):
print(w*x+b)
return w * x + b
# 定义均方误差损失函数
def mse_loss(y_pred, y_true):
print((y_pred - y_true) ** 2)
return ((y_pred - y_true) ** 2).mean()
# 定义优化器
optimizer = optim.SGD([w, b], lr=0.01)
# 进行训练
for epoch in range(1):
# 前向传播
y_pred = linear_regression(x)
# 计算损失
loss = mse_loss(y_pred, y_true)
# 清零梯度
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新模型参数
optimizer.step()
# 打印训练后的模型参数
print("训练后的模型参数:")
print("w:", w.item())
print("b:", b.item())
因为前向传播输入的x是一个张量,输出y_pred也是一个张量,接着传入计算损失loss得到的也是一个张量,而损失函数求梯度无法对张量进行操作,只能对标量求梯度,所以先将计算得到的损失相加得到一个标量再进行反向传播
以下是计算一次w的过程 首先,我们的线性回归模型表示为: y = w x + b y = wx + b y=wx+b,其中 x x x 是输入数据, y y y 是预测的输出, w w w 是权重(斜率), b b b 是偏置(截距)。 损失函数使用均方误差(Mean Squared Error,MSE): M S E = 1 N ∑ i = 1 N ( y i − y ^ i ) 2 MSE = \frac{1}{N}\sum_{i=1}^{N} (y_i - \hat{y}_i)^2 MSE=N1∑i=1N(yi−y^i)2,其中 N N N 是样本数量, y i y_i yi 是真实的目标值, y ^ i \hat{y}_i y^i 是预测值。 梯度下降法的更新规则为:w = w - learning_rate * ∂ MSE ∂ w \frac{\partial \text{MSE}}{\partial w} ∂w∂MSE,其中 learning_rate 是学习率,用于控制更新的步长。 现在,我们来计算第一次得到的 w 的结果。 给定初始值 w= 0.0 和 learning_rate= 0.01,我们需要计算 新的w,然后用梯度下降法更新 w w w。 首先,计算损失函数对于模型输出
y
y
y 的梯度
∂
MSE
∂
y
\frac{\partial \text{MSE}}{\partial y}
∂y∂MSE: |
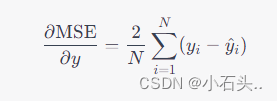 然后,计算
y
y
y 对于
w
w
w 的梯度
∂
y
∂
w
\frac{\partial y}{\partial w}
∂w∂y:
然后,计算
y
y
y 对于
w
w
w 的梯度
∂
y
∂
w
\frac{\partial y}{\partial w}
∂w∂y: 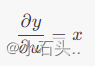 接下来,使用链式法则计算损失函数对于
w
w
w 的梯度
∂
MSE
∂
w
\frac{\partial \text{MSE}}{\partial w}
∂w∂MSE:
接下来,使用链式法则计算损失函数对于
w
w
w 的梯度
∂
MSE
∂
w
\frac{\partial \text{MSE}}{\partial w}
∂w∂MSE: 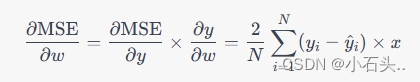 现在我们有了梯度
∂
MSE
∂
w
\frac{\partial \text{MSE}}{\partial w}
∂w∂MSE,可以使用梯度下降法的更新规则来更新
w
w
w:
现在我们有了梯度
∂
MSE
∂
w
\frac{\partial \text{MSE}}{\partial w}
∂w∂MSE,可以使用梯度下降法的更新规则来更新
w
w
w: 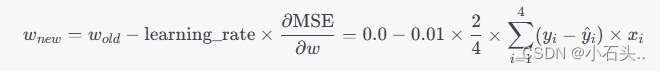 假设初始的
b
b
b 为
0.0
0.0
0.0,并将输入数据
x
=
[
1.0
,
2.0
,
3.0
,
4.0
]
x = [1.0, 2.0, 3.0, 4.0]
x=[1.0,2.0,3.0,4.0] 和目标值
y
true
=
[
2.0
,
4.0
,
6.0
,
8.0
]
y_{\text{true}} = [2.0, 4.0, 6.0, 8.0]
ytrue=[2.0,4.0,6.0,8.0] 代入计算,我们可以得到:
假设初始的
b
b
b 为
0.0
0.0
0.0,并将输入数据
x
=
[
1.0
,
2.0
,
3.0
,
4.0
]
x = [1.0, 2.0, 3.0, 4.0]
x=[1.0,2.0,3.0,4.0] 和目标值
y
true
=
[
2.0
,
4.0
,
6.0
,
8.0
]
y_{\text{true}} = [2.0, 4.0, 6.0, 8.0]
ytrue=[2.0,4.0,6.0,8.0] 代入计算,我们可以得到: 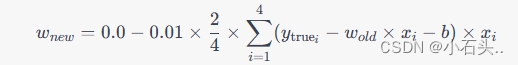 将
x
i
x_i
xi 和
y
true
i
y_{\text{true}_i}
ytruei 代入,得到:
将
x
i
x_i
xi 和
y
true
i
y_{\text{true}_i}
ytruei 代入,得到:  计算结果为:
计算结果为: 所以第一次得到的 w 的结果为 -0.3。
所以第一次得到的 w 的结果为 -0.3。【本文地址】