Python3 爬虫实战 |
您所在的位置:网站首页 › 武汉二手楼盘价格 › Python3 爬虫实战 |
Python3 爬虫实战
|
爬取时间:2019-10-09爬取难度:★★☆☆☆☆请求链接:https://wuhan.anjuke.com/sale/爬取目标:爬取武汉二手房每一条售房信息,包含地理位置、价格、面积等,保存为 CSV 文件涉及知识:请求库 requests、解析库 Beautiful Soup、CSV 文件储存、列表操作、分页判断完整代码:https://github.com/TRHX/Python3-Spider-Practice/tree/master/BasicTraining/anjuke其他爬虫实战代码合集(持续更新):https://github.com/TRHX/Python3-Spider-Practice爬虫实战专栏(持续更新):https://itrhx.blog.csdn.net/article/category/9351278
文章目录
【1x00】页面整体分析【2x00】解析模块【3x00】循环爬取模块【4x00】数据储存模块【5x00】完整代码【6x00】数据截图【7x00】程序不足的地方
【1x00】页面整体分析
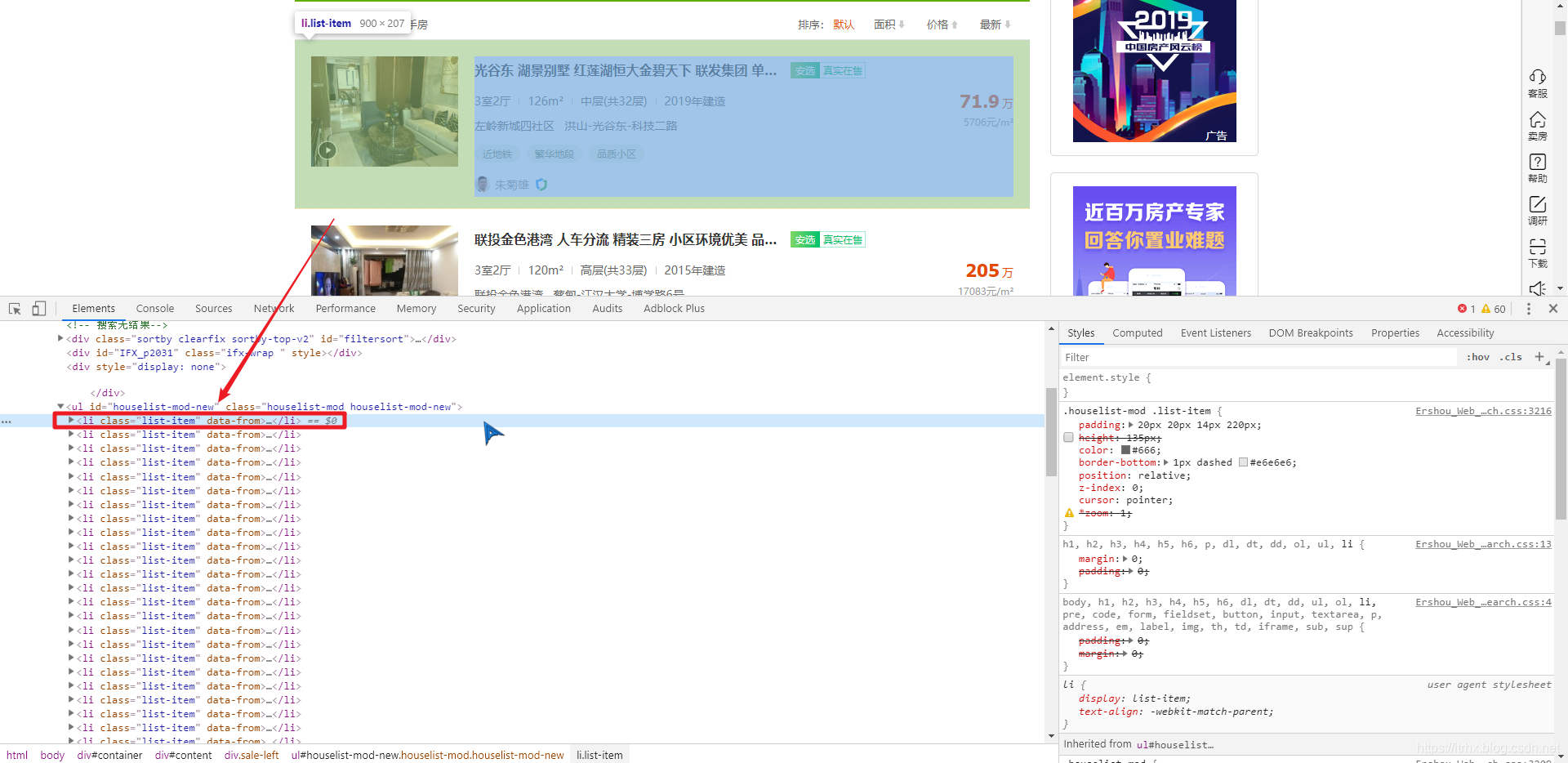
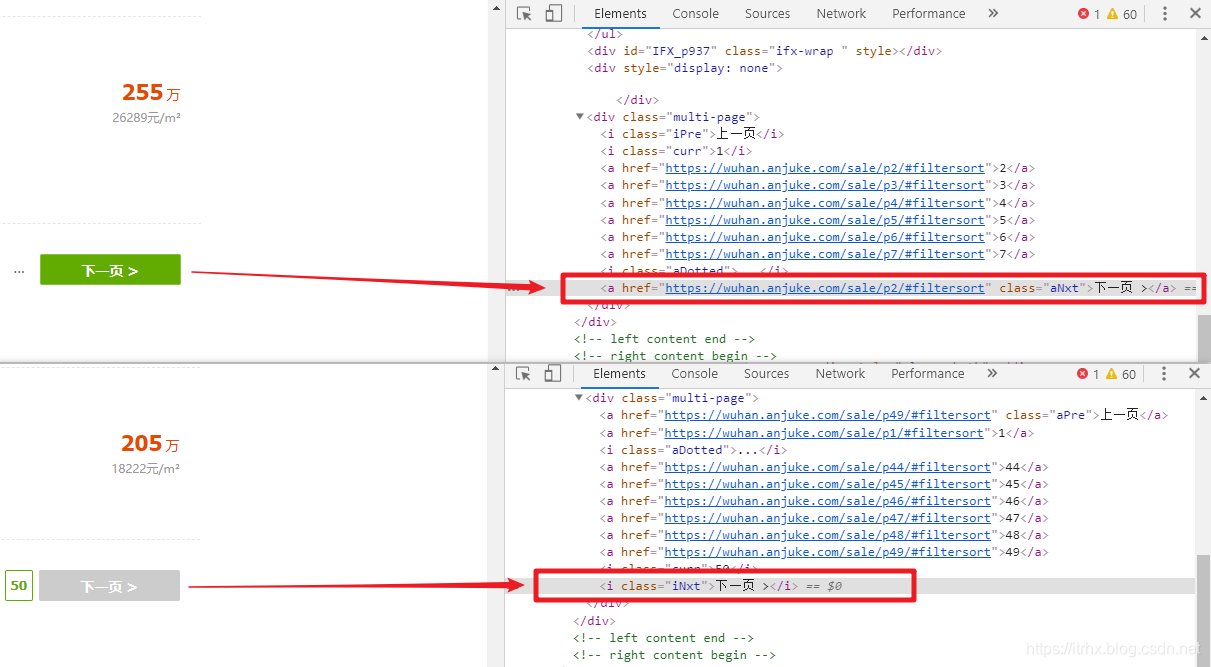
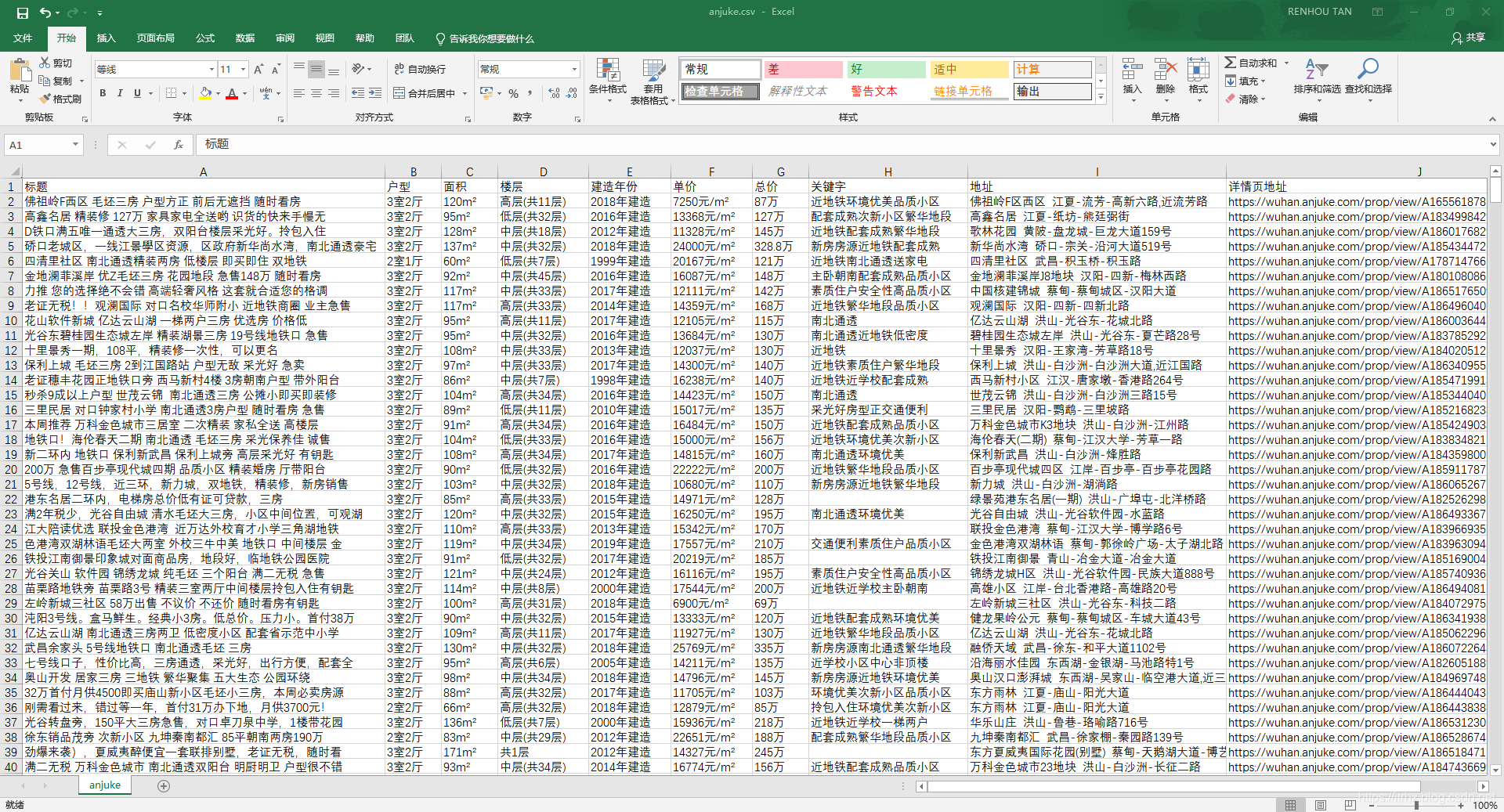
分析 安居客武汉二手房页面,这次爬取实战准备使用 BeautifulSoup 解析库,熟练 BeautifulSoup 解析库的用法,注意到该页面与其他页面不同的是,不能一次性看到到底有多少页,以前知道一共有多少页,直接一个循环爬取就行了,虽然可以通过改变 url 来尝试找到最后一页,但是这样就显得不程序员了?,因此可以通过 BeautifulSoup 解析 下一页按钮,提取到下一页的 url,直到没有 下一页按钮 这个元素为止,从而实现所有页面的爬取,剩下的信息提取和储存就比较简单了 【2x00】解析模块分析页面,可以发现每条二手房信息都是包含在 标签内的,因此可以使用 BeautifulSoup 解析页面得到所有的 标签,然后再循环访问每个 标签,依次解析得到每条二手房的各种信息 前面已经分析过,该网页是无法一下就能看到一共有多少页的,尝试找到最后一页,发现一共有50页,那么此时就可以搞个循环,一直到第50页就行了,但是如果有一天页面数增加了呢,那么代码的可维护性就不好了,我们可以观察 下一页按钮 ,当存在下一页的时候,是 标签,并且带有下一页的 URL,不存在下一页的时候是 标签,因此可以写个 if 语句,判断是否存在此 标签,若存在,表示有下一页,然后提取其 href 属性并传给解析模块,实现后面所有页面的信息提取,此外,由于安居客有反爬系统,我们还可以利用 Python中的 random.randint() 方法,在两个数值之间随机取一个数,传入 time.sleep() 方法,实现随机暂停爬取 数据储存比较简单,将每个二手房信息组成一个列表,依次写入到 anjuke.csv 文件中即可 results = [title, layout, cover, floor, year, unit_price, total_price, keyword, address, details_url] with open('anjuke.csv', 'a', newline='', encoding='utf-8-sig') as f: w = csv.writer(f) w.writerow(results) 【5x00】完整代码 # ============================================= # --*-- coding: utf-8 --*-- # @Time : 2019-10-09 # @Author : TRHX # @Blog : www.itrhx.com # @CSDN : https://blog.csdn.net/qq_36759224 # @FileName: anjuke.py # @Software: PyCharm # ============================================= import requests import time import csv import random from bs4 import BeautifulSoup headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36' } def parse_pages(url, num): response = requests.get(url=url, headers=headers) soup = BeautifulSoup(response.text, 'lxml') result_list = soup.find_all('li', class_='list-item') # print(len(result_list)) for result in result_list: # 标题 title = result.find('a', class_='houseListTitle').text.strip() # print(title) # 户型 layout = result.select('.details-item > span')[0].text # print(layout) # 面积 cover = result.select('.details-item > span')[1].text # print(cover) # 楼层 floor = result.select('.details-item > span')[2].text # print(floor) # 建造年份 year = result.select('.details-item > span')[3].text # print(year) # 单价 unit_price = result.find('span', class_='unit-price').text.strip() # print(unit_price) # 总价 total_price = result.find('span', class_='price-det').text.strip() # print(total_price) # 关键字 keyword = result.find('div', class_='tags-bottom').text.strip() # print(keyword) # 地址 address = result.find('span', class_='comm-address').text.replace(' ', '').replace('\n', '') # print(address) # 详情页url details_url = result.find('a', class_='houseListTitle')['href'] # print(details_url) results = [title, layout, cover, floor, year, unit_price, total_price, keyword, address, details_url] with open('anjuke.csv', 'a', newline='', encoding='utf-8-sig') as f: w = csv.writer(f) w.writerow(results) # 判断是否还有下一页 next_url = soup.find_all('a', class_='aNxt') if len(next_url) != 0: num += 1 print('第' + str(num) + '页数据爬取完毕!') # 3-60秒之间随机暂停 time.sleep(random.randint(3, 60)) parse_pages(next_url[0].attrs['href'], num) else: print('所有数据爬取完毕!') if __name__ == '__main__': with open('anjuke.csv', 'a', newline='', encoding='utf-8-sig') as fp: writer = csv.writer(fp) writer.writerow(['标题', '户型', '面积', '楼层', '建造年份', '单价', '总价', '关键字', '地址', '详情页地址']) start_num = 0 start_url = 'https://wuhan.anjuke.com/sale/' parse_pages(start_url, start_num) 【6x00】数据截图
虽然使用了随机暂停爬取的方法,但是在爬取了大约 20 页的数据后依然会出现验证页面,导致程序终止 原来设想的是可以由用户手动输入城市的拼音来查询不同城市的信息,方法是把用户输入的城市拼音和其他参数一起构造成一个 URL,然后对该 URL 发送请求,判断请求返回的代码,如果是 200 就代表可以访问,也就是用户输入的城市是正确的,然而发现即便是输入错误,该 URL 依然可以访问,只不过会跳转到一个正确的页面,没有搞清楚是什么原理,也就无法实现由用户输入城市来查询这个功能 |
【本文地址】
今日新闻 |
推荐新闻 |