描述性统计分析 |
您所在的位置:网站首页 › 正态分布描述的数据案例 › 描述性统计分析 |
描述性统计分析
|
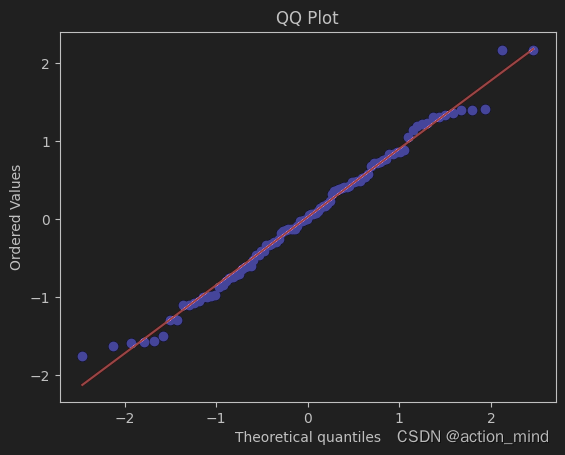
描述性统计是用于概述、显示或描述数据集特征的统计方法,不涉及数据之间的关系或推断过程。集中趋势是描述性统计中的一个核心概念,主要描述数据集中的典型值或数据的“中心”所在。 1 集中趋势的指标平均数(Mean):数据集合的总和除以数据的数量。它是数据集中最常用的集中趋势度量,但容易受极端值的影响。 中位数(Median):将数据集按大小顺序排列后位于中间的数。如果数据集的数量是偶数,则中位数是中间两个数的平均值。中位数对极端值不敏感,因此在数据分布不对称时是一个好的集中趋势度量。 众数(Mode):数据集中出现次数最多的数值。一个数据集可能有一个众数、多个众数或没有众数(如果所有数据值出现次数相同)。 用Python实现使用Python计算这些集中趋势指标很简单,因为NumPy和SciPy等库提供了现成的函数。以下是如何使用Python来计算平均数、中位数和众数的示例: import numpy as np from scipy import stats # 示例数据 data = np.random.randint(0, 100, size=100) # 平均数 mean = np.mean(data) print(f"平均数: {mean}") # 中位数 median = np.median(data) print(f"中位数: {median}") # 众数 mode = stats.mode(data) print(f"众数: {mode.mode},出现次数: {mode.count}") 平均数: 53.75 中位数: 57.5 众数: 44,出现次数: 5这段代码首先导入了必要的库,然后计算了一组示例数据的平均数、中位数和众数。注意,scipy.stats.mode()函数返回的是一个对象,其中包含了众数(mode)和众数出现的次数(count)。 注意点 当处理实际数据时,选择合适的集中趋势度量是很重要的。例如,对于偏斜分布的数据,中位数可能比平均数更能代表数据的“中心”。众数在描述类别数据时特别有用,因为它可以告诉我们哪个类别是最常见的。在使用任何统计方法之前,了解数据的分布和性质是非常重要的,这将帮助你做出更准确的分析和决策。 2 离中趋势离中趋势度量用于描述数据集中值的分散、偏斜和峰值情况。这些统计量帮助我们理解数据的波动性、分布形状及其相对于平均值的偏离程度。 实际应用场景四分位差 (Interquartile Range, IQR): 表示数据的中间50%的分布范围,常用于识别异常值。例如,在房价数据分析中,四分位差可以帮助确定大多数房价的分布范围,并识别异常高或低的价格。 标准差 (Standard Deviation) 和 方差 (Variance): 这两个度量标准用于量化数据点偏离平均值的程度。在投资领域,标准差常用于衡量投资回报的波动性或风险。 偏度 (Skewness): 描述数据分布的不对称性。正偏度表示数据右侧尾部更长,负偏度表示左侧尾部更长。在财务分析中,偏度可以帮助分析资产回报的分布特征,指导风险管理决策。 峰度 (Kurtosis): 衡量数据分布的尖锐程度。高峰度表示数据有更尖的峰和更厚的尾部,可能意味着数据中存在更多的极端值。在质量控制中,峰度分析可以揭示生产过程中的异常情况。 import numpy as np from scipy import stats # 示例数据 data = np.array([1, 2, 2, 3, 4, 6, 7, 8, 9, 10]) # 四分位差 Q1 = np.percentile(data, 25) Q3 = np.percentile(data, 75) IQR = Q3 - Q1 print(f"四分位差: {IQR}") # 标准差 std_dev = np.std(data, ddof=1) # ddof=1 为样本标准差 print(f"标准差: {std_dev}") # 方差 variance = np.var(data, ddof=1) # ddof=1 为样本方差 print(f"方差: {variance}") # 偏度 skewness = stats.skew(data) print(f"偏度: {skewness}") # 峰度 kurtosis = stats.kurtosis(data, fisher=True) # Fisher定义,正常分布的峰度为0 print(f"峰度: {kurtosis}") 四分位差: 5.5 标准差: 3.2249030993194197 方差: 10.399999999999999 偏度: 0.14582994664121351 峰度: -1.449813719044488 四分位差: 5.5 四分位差 (IQR) 表示数据分布中间50%的范围。具体来说,它是第三四分位数(Q3)与第一四分位数(Q1)之间的差异。在这个例子中,IQR为5.5,意味着数据集中间50%的数值分布在一个5.5单位的范围内。四分位差是衡量数据散布(即分布的紧密程度)的重要指标,较大的IQR表示中间数据更分散。 标准差: 3.2249030993194197 标准差 是衡量数据集中各个数据点偏离平均值的平均程度。标准差越大,表示数据点相对于平均值的波动越大;标准差越小,表示数据点较为集中。这个例子中,标准差约为3.22,表明数据点在平均值周围平均偏离约3.22单位。 方差: 10.399999999999999 方差 是标准差的平方,也用于衡量数据的波动性。方差越大,数据的分散程度越高。这个例子中,方差约为10.4,与标准差相对应,提供了波动性的另一种度量方式。 偏度: 0.14582994664121351 偏度 描述了数据分布的不对称性。偏度值为正表示数据分布的右尾(较大值)更长,为负表示左尾(较小值)更长。接近0的偏度值意味着数据分布比较对称。这里的偏度值约为0.146,表明数据分布相对较为对称,但略微右偏。 峰度: -1.449813719044488 峰度 描述了数据分布顶部的尖锐程度以及尾部的厚度。峰度大于0表示一个比正态分布更尖锐的峰值和更厚的尾部;小于0表示一个比正态分布更平缓的顶部和较薄的尾部。这个例子中,峰度约为-1.45,意味着数据分布的顶部比正态分布更平缓,尾部较薄。 总结这组数据显示了一个相对波动性中等、略微右偏但接近对称分布、顶部较为平缓的数据分布。这些统计量为我们提供了关于数据集分布特性的全面视图,有助于进一步分析和决策。 3正态分布正态分布是许多统计分析和假设检验的基础。在实际数据分析中,检验数据是否遵循正态分布是一个常见步骤,因为许多统计方法要求数据接近正态分布。下面我将简要介绍几种检验数据正态性的方法,并提供Python实现示例。 1. KS检验 (Kolmogorov-Smirnov Test)KS检验是一种非参数检验,用于比较两个样本是否来自同一分布,或者比较一个样本与参考分布(如正态分布)是否相同。 from scipy import stats import numpy as np # 生成正态分布样本数据 data = np.random.normal(loc=0, scale=1, size=100) # KS检验,比较数据与标准正态分布 ks_statistic, p_value = stats.kstest(data, 'norm') print(f"KS统计量: {ks_statistic}, P值: {p_value}") KS统计量: 0.04007914255552314, P值: 0.9951867096784285 2. P-P图 (Probability-Probability Plot) 和 QQ图 (Quantile-Quantile Plot)P-P图和QQ图是用于图形化检验数据分布的方法。P-P图比较累积分布函数(CDF),而QQ图比较分位数。这两种图都可以用于评估数据是否近似正态分布。 import numpy as np import matplotlib.pyplot as plt import scipy.stats as stats # 生成正态分布样本数据 data = np.random.normal(loc=0, scale=1, size=100) # 绘制QQ图 stats.probplot(data, dist="norm", plot=plt) plt.title("QQ Plot") plt.show()
Shapiro-Wilk检验是一种用于检验数据正态性的方法,它检验一个样本是否来自正态分布。 from scipy import stats # 生成正态分布样本数据 data = np.random.normal(loc=0, scale=1, size=100) # 进行Shapiro-Wilk检验 w_statistic, p_value = stats.shapiro(data) print(f"W统计量: {w_statistic}, P值: {p_value}") W统计量: 0.9947768396389826, P值: 0.9689670597988114 4. 动差法 (Method of Moments)动差法是一种基于样本矩(如均值、方差)来估计分布参数的方法。虽然它不是一个正态性检验,但可以用于计算样本的偏度和峰度,进而提供数据是否接近正态分布的线索。 Python计算偏度和峰度: # 使用之前生成的data # 计算偏度 skewness = stats.skew(data) print(f"偏度: {skewness}") # 计算峰度 kurtosis = stats.kurtosis(data) print(f"峰度: {kurtosis}") 偏度: 0.13125063245973762 峰度: -0.14368564194099953以上方法提供了不同的视角来评估数据的正态性。图形化方法(如P-P图和QQ图)提供直观的视觉证据,而统计检验(如KS检验和Shapiro-Wilk检验)提供了定量的证据。在实际应用中,通常建议结合多种方法来评估数据的正态性。 ata) print(f"峰度: {kurtosis}") 偏度: 0.13125063245973762 峰度: -0.14368564194099953 以上方法提供了不同的视角来评估数据的正态性。图形化方法(如P-P图和QQ图)提供直观的视觉证据,而统计检验(如KS检验和Shapiro-Wilk检验)提供了定量的证据。在实际应用中,通常建议结合多种方法来评估数据的正态性。 |
【本文地址】
今日新闻 |
推荐新闻 |