PID控制算法的C语言实现 |
您所在的位置:网站首页 › 模糊pid算法 › PID控制算法的C语言实现 |
PID控制算法的C语言实现
|
参考: PID控制器开发笔 浅谈位置式PID 专家PID控制在快速系统中的仿真及应用(这篇了论文介绍的积分分离PID、专家PID(脚本实现和simulink实现)很详细)
PID控制算法的C语言实现一 PID算法原理 在工业应用中PID及其衍生算法是应用最广泛的算法之一,是当之无愧的万能算法,如果能够熟练掌握PID算法的设计与实现过程,对于一般的研发人员来讲,应该是足够应对一般研发问题了,而难能可贵的是,在我所接触的控制算法当中,PID控制算法又是最简单,最能体现反馈思想的控制算法,可谓经典中的经典。经典的未必是复杂的,经典的东西常常是简单的,而且是最简单的,想想牛顿的力学三大定律吧,想想爱因斯坦的质能方程吧,何等的简单!简单的不是原始的,简单的也不是落后的,简单到了美的程度。先看看PID算法的一般形式:
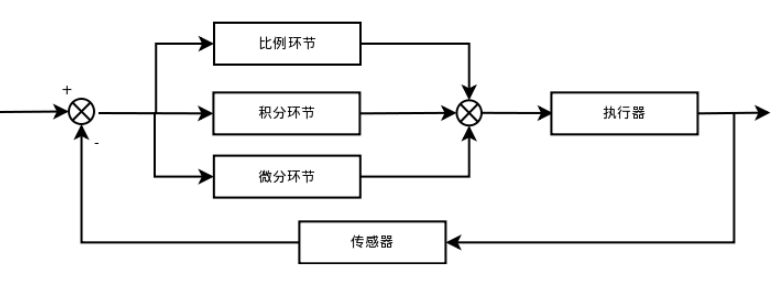
PID的流程简单到了不能再简单的程度,通过误差信号控制被控量,而控制器本身就是比例、积分、微分三个环节的加和。这里我们规定(在t时刻): 1.输入量为rin(t); 2.输出量为rout(t); 3.偏差量为err(t)=rin(t)-rout(t); pid的控制规律为
理解一下这个公式,主要从下面几个问题着手,为了便于理解,把控制环境具体一下: 1.规定这个流程是用来为直流电机调速的; 2.输入量rin(t)为电机转速预定值; 3.输出量rout(t)为电机转速实际值; 4.执行器为直流电机; 5.传感器为光电码盘,假设码盘为10线; 6.直流电机采用PWM调速 转速用单位 转/min 表示; 不难看出以下结论: 1.输入量rin(t)为电机转速预定值(转/min); 2. 输出量rout(t)为电机转速实际值(转/min); 3.偏差量为预定值和实际值之差(转/min); 那么以下几个问题需要弄清楚: 1.通过PID环节之后的U(t)是什么值呢? 2.控制执行器(直流电机)转动转速应该为电压值(也就是PWM占空比)。 3.那么U(t)与PWM之间存在怎样的联系呢? http://blog.21ic.com/user1/3407/archives/2006/33541.html(见附录1)这篇文章上给出了一种方法,即,每个电压对应一个转速,电压和转速之间呈现线性关系。但是我考虑这种方法的前提是把直流电机的特性理解为线性了,而实际情况下,直流电机的特性绝对不是线性的,或者说在局部上是趋于线性的,这就是为什么说PID调速有个范围的问题。具体看一下http://articles.e-works.net.cn/component/article90249.htm(见附录2)这篇文章就可以了解了。所以在正式进行调速设计之前,需要现有开环系统,测试电机和转速之间的特性曲线(或者查阅电机的资料说明),然后再进行闭环参数整定。这篇先写到这,下一篇说明连续系统的离散化问题。并根据离散化后的特点讲述位置型PID和增量型PID的用法和C语言实现过程。 PID控制算法的C语言实现二 PID算法的离散化 上一节中,我论述了PID算法的基本形式,并对其控制过程的实现有了一个简要的说明,通过上一节的总结,基本已经可以明白PID控制的过程。这一节中先继续上一节内容补充说明一下。 1.说明一下反馈控制的原理,通过上一节的框图不难看出,PID控制其实是对偏差的控制过程; 2.如果偏差为0,则比例环节不起作用,只有存在偏差时,比例环节才起作用。 3.积分环节主要是用来消除静差,所谓静差,就是系统稳定后输出值和设定值之间的差值,积分环节实际上就是偏差累计的过程,把累计的误差加到原有系统上以抵消系统造成的静差。 4.而微分信号则反应了偏差信号的变化规律,或者说是变化趋势,根据偏差信号的变化趋势来进行超前调节,从而增加了系统的快速性。 好了,关于PID的基本说明就补充到这里,下面将对PID连续系统离散化,从而方便在处理器上实现。下面把连续状态的公式再贴一下: 假设采样间隔为T,则在第K个 T时刻: 偏差err(K)=rin(K)-rout(K); 积分环节用加和的形式表示,即err(K)+err(K+1)+……; 微分环节用斜率的形式表示,即[err(K)-err(K-1)]/T; 从而形成如下PID离散表示形式:
其中T为采样时间,Kp为比例带,TI为积分时间,TD为微分时间。PID控制的基本原理就是如此。 则u(K)可表示成为:位置型PID 可以这么理解:比例环节将误差线性放大,积分环节将误差值的积分放大,微分环节将两次的误差值放大,所有的值相加得到最终输出值 在不断变化中,err(k)(设定值与实际输出值差值)会降低或者升高,不断降低时比例和微分环节对最终的输出贡献变少而积分环节因为误差值的不断累加贡献最大。 至于说Kp、Ki、Kd三个参数的具体表达式,我想可以轻松的推出了,这里节省时间,不再详细表示了。 其实到这里为止,PID的基本离散表示形式已经出来了。目前的这种表述形式属于位置型PID,另外一种表述方式为增量式PID,由上述表达式可以轻易得到:增量式PID 那么: 这就是离散化PID的增量式表示方式,由公式可以看出,增量式的表达结果和最近三次的偏差有关,这样就大大提高了系统的稳定性。需要注意的是最终的输出结果应该为 u(K)+增量调节值; PID的离散化过程基本思路就是这样,下面是将离散化的公式转换成为C语言,从而实现微控制器的控制作用。 当然,增量型PID必须记得一点,就是在记住U(k)=U(k-1)+∆U(k)。
PID 控制算法可以分为位置式 PID 和增量式 PID 控制算法。两者的区别 PID 控制算法可以分为位置式 PID 和增量式 PID 控制算法。两者的区别: (1)位置式PID控制的输出与整个过去的状态有关,用到了误差的累加值;而增量式PID的输出只与当前拍和前两拍的误差有关,因此位置式PID控制的累积误差相对更大; (2)增量式PID控制输出的是控制量增量,并无积分作用,因此该方法适用于执行机构带积分部件的对象,如步进电机等,而位置式PID适用于执行机构不带积分部件的对象,如电液伺服阀。 (3)由于增量式PID输出的是控制量增量,如果计算机出现故障,误动作影响较小,而执行机构本身有记忆功能,可仍保持原位,不会严重影响系统的工作,而位置式的输出直接对应对象的输出,因此对系统影响较大。 PID控制算法的C语言实现三 位置型PID的C语言实现 上一节中已经抽象出了位置性PID和增量型PID的数学表达式,这一节,重点讲解C语言代码的实现过程,算法的C语言实现过程具有一般性,通过PID算法的C语言实现,可以以此类推,设计其它算法的C语言实现。 第一步:定义PID变量结构体,代码如下: struct _pid{ float SetSpeed; //定义设定值 float ActualSpeed; //定义实际值 float err; //定义偏差值 float err_last; //定义上一个偏差值 float Kp,Ki,Kd; //定义比例、积分、微分系数 float voltage; //定义电压值(控制执行器的变量) float integral; //定义积分值}pid; 控制算法中所需要用到的参数在一个结构体中统一定义,方便后面的使用。 第二部:初始化变量,代码如下: void PID_init(){ printf("PID_init begin \n"); pid.SetSpeed=0.0; pid.ActualSpeed=0.0; pid.err=0.0; pid.err_last=0.0; pid.voltage=0.0; pid.integral=0.0; pid.Kp=0.2; pid.Ki=0.015; pid.Kd=0.2; printf("PID_init end \n");} 统一初始化变量,尤其是Kp,Ki,Kd三个参数,调试过程当中,对于要求的控制效果,可以通过调节这三个量直接进行调节。 第三步:编写控制算法,代码如下: float PID_realize(float speed){ pid.SetSpeed=speed; pid.err=pid.SetSpeed-pid.ActualSpeed; pid.integral+=pid.err; pid.voltage=pid.Kp*pid.err+pid.Ki*pid.integral+pid.Kd*(pid.err-pid.err_last); pid.err_last=pid.err; pid.ActualSpeed=pid.voltage*1.0; return pid.ActualSpeed;} 注意:这里用了最基本的算法实现形式,没有考虑死区问题,没有设定上下限,只是对公式的一种直接的实现,后面的介绍当中还会逐渐的对此改进。 到此为止,PID的基本实现部分就初步完成了。下面是测试代码: int main(){ printf("System begin \n"); PID_init(); int count=0; while(count 200) 33 { 34 index = 0; 35 } 36 37 else 38 39 { 40 index = 1; 41 // pid.integral += pid.err; 42 } 43 pid.voltage = pid.Kp*pid.err + index * pid.Ki*pid.integral + pid.Kd*(pid.err - pid.err_last); //算法具体实现过程 44 pid.err_last = pid.err; 45 pid.ActualSpeed = pid.voltage*1.0; 46 return pid.ActualSpeed; 47 } 48 49 int main() 50 { 51 printf("System begin \n"); 52 PID_init(); 53 int count = 0; 54 while (count < 1500) 55 { 56 float speed = PID_realize(200.0); 57 printf("%f\n", speed); 58 count++; 59 } 60 return 0; 61 } 运行后的1000个数据为:(结果自行运行观看) 结论:同样采集1000个量,会发现,系统到199所有的时间是原来时间的1/2,系统的快速性得到了提高。 积分分离的PID控制算法——增量型PID的变化方法一:最后结果在两个数之间波动(没搞清为什么) 1 #include 2 #include 3 #include 4 #pragma warning(disable : 4305) 5 #pragma warning(disable : 4578) 6 7 static uint16_t BetaGeneration(float error, float epsilon) 8 { 9 int beta; 10 if (abs(error) > epsilon) 11 { 12 beta = 0; 13 } 14 else 15 { 16 beta = 1; 17 18 } 19 20 return beta; 21 22 } 23 24 25 /*定义结构体和公用体*/ 26 typedef struct 27 { 28 float setpoint; //设定值 29 float proportiongain; //比例系数 30 float integralgain; //积分系数 31 float derivativegain; //微分系数 32 float lasterror; //前一拍偏差 33 float preerror; //前两拍偏差 34 float deadband; //死区 35 float result; //输出值 36 float epsilon; //偏差检测阈值 37 }PID; 38 39 //接下来实现PID控制器: 40 void PIDRegulation(PID *vPID, float processValue) 41 { 42 float thisError; 43 float increment; 44 float pError, dError, iError; 45 46 thisError = vPID->setpoint - processValue; //得到偏差值 47 pError = thisError - vPID->lasterror; 48 iError = thisError; 49 dError = thisError - 2 * (vPID->lasterror) + vPID->preerror; 50 uint16_t beta = BetaGeneration(thisError, vPID->epsilon); 51 52 if (beta > 0) 53 { 54 increment = vPID->proportiongain*pError + vPID->derivativegain*dError; //增量计算 55 } 56 else 57 { 58 increment = vPID->proportiongain*pError + vPID->integralgain*iError + vPID->derivativegain*dError; //增量计算 59 } 60 vPID->preerror = vPID->lasterror; //存放偏差用于下次运算 61 vPID->lasterror = thisError; 62 vPID->result += increment; 63 } 64 void PID_init(PID *pid) 65 { 66 printf("PID_init begin \n"); 67 pid->setpoint = 200.0; //设定值 68 pid->proportiongain = 0.2; //比例系数 69 pid->integralgain = 0.35; //积分系数 70 pid->derivativegain = 0.2; //微分系数 71 pid->lasterror = 0; //前一拍偏差 72 pid->preerror = 0; //前两拍偏差 73 pid->deadband; //死区 74 pid->result = 0; //输出值 75 pid->epsilon = 0.1; //偏差检测阈值 76 printf("PID_init end \n"); 77 } 78 79 int main() 80 { 81 printf("System begin \n"); 82 PID pid1; 83 PID_init(&pid1); 84 int cout = 1000; 85 while (cout) 86 { 87 PIDRegulation(&pid1, pid1.result); 88 printf("%f\n", pid1.result); 89 cout--; 90 } 91 return 0; 92 }方法二: 1 #include 2 #include 3 #include 4 #pragma warning(disable : 4305) 5 #pragma warning(disable : 4578) 6 struct _pid { 7 float SetSpeed; //定义设定值 8 float ActualSpeed; //定义实际值 9 float err; //定义偏差值 10 float err_next; //定义上一个偏差值 11 float err_last; //定义最上前的偏差值 12 float Kp, Ki, Kd; //定义比例、积分、微分系数 13 }pid; 14 15 void PID_init() { 16 pid.SetSpeed = 0.0; 17 pid.ActualSpeed = 0.0; 18 pid.err = 0.0; 19 pid.err_last = 0.0; 20 pid.err_next = 0.0; 21 pid.Kp = 0.2; 22 pid.Ki = 0.015; 23 pid.Kd = 0.2; 24 } 25 26 float PID_realize(float speed) 27 { 28 int index; 29 pid.SetSpeed = speed; 30 pid.err = pid.SetSpeed - pid.ActualSpeed; 31 if (abs(pid.err) > 200) 32 { 33 index = 0; 34 } 35 else 36 37 { 38 index = 1; 39 40 } 41 42 float incrementSpeed = pid.Kp*(pid.err - pid.err_next) + index*pid.Ki*pid.err + pid.Kd*(pid.err - 2 * pid.err_next + pid.err_last); 43 pid.ActualSpeed += incrementSpeed; 44 pid.err_last = pid.err_next; 45 pid.err_next = pid.err; 46 return pid.ActualSpeed; 47 } 48 49 int main() { 50 PID_init(); 51 int count = 0; 52 while (count < 1000) 53 { 54 float speed = PID_realize(200.0); 55 printf("%f\n", speed); 56 count++; 57 } 58 return 0; 59 }PID控制算法的C语言实现六 抗积分饱和的PID控制算法C语言实现 所谓的积分饱和现象是指如果系统存在一个方向的偏差,PID控制器的输出由于积分作用的不断累加而加大,从而导致执行机构达到极限位置(即转速达到最大),若控制器输出U(k)继续增大,执行器开度不可能再增大(转速不在升高),此时计算机输出控制量超出了正常运行范围而进入饱和区。 一旦系统出现反向偏差,u(k)逐渐从饱和区退出。进入饱和区越深(理论里比实际极限转速差值越大)则退出饱和区时间越长。在这段时间里,执行机构仍然停留在极限位置而不随偏差反向而立即做出相应的改变,这时系统就像失控一样,造成控制性能恶化,这种现象称为积分饱和现象或积分失控现象。 防止积分饱和的方法之一就是抗积分饱和法,该方法的思路是在计算u(k)时,首先判断上一时刻的控制量u(k-1)是否已经超出了极限范围: 如果u(k-1)>umax,则只累加负偏差; 如果u(k-1) pid.umax) //灰色底色表示抗积分饱和的实现 36 { 37 38 if (abs(pid.err) > 200) //蓝色标注为积分分离过程 39 { 40 index = 0; 41 } 42 else { 43 index = 1; 44 if (pid.err < 0) 45 { 46 pid.integral += pid.err; 47 } 48 } 49 } 50 else if (pid.ActualSpeed 200) //积分分离过程 52 { 53 index = 0; 54 } 55 else { 56 index = 1; 57 if (pid.err > 0) 58 { 59 pid.integral += pid.err; 60 } 61 } 62 } 63 else { 64 if (abs(pid.err) > 200) //积分分离过程 65 { 66 index = 0; 67 } 68 else { 69 index = 1; 70 pid.integral += pid.err; 71 } 72 } 73 74 pid.voltage = pid.Kp*pid.err + index * pid.Ki*pid.integral + pid.Kd*(pid.err - pid.err_last); 75 76 pid.err_last = pid.err; 77 pid.ActualSpeed = pid.voltage*1.0; 78 return pid.ActualSpeed; 79 } 80 81 int main() 82 { 83 printf("System begin \n"); 84 PID_init(); 85 int count = 0; 86 while (count < 1500) 87 { 88 float speed = PID_realize(200.0); 89 printf("%f\n", speed); 90 count++; 91 } 92 return 0; 93 } 总结:所谓抗积分饱和就是防止由于长期存在一个方向的偏差而对相反方向的偏差迟滞响应。本文的方法是在达到极值后将不再对这一方向的偏差做出反应相反只对另一方向的偏差做出反应。事实上由于偏差的存在有可能造成输出值超限的情况,所以还需要对输出值作出限制。 PID控制算法的C语言实现七 梯形积分的PID控制算法C语言实现 先看一下梯形算法的积分环节公式
作为PID控制里的积分项,其作用是消除余差,为了尽量减小余差,应提高积分项运算精度,为此可以将矩形积分改为梯形积分,具体实现的语句为: 于是如果在位置型PID算法中引入梯形积分则可以修改计算公式如下: 同样要在增量型PID算法中引入梯形积分则可以修改计算公式如下:
pid.voltage=pid.Kp*pid.err+index*pid.Ki*pid.integral/2+pid.Kd*(pid.err-pid.err_last); //梯形积分 相对于实现六的pid.voltage代码变换 1 #include 2 3 struct _pid { 4 float SetSpeed; //定义设定值 5 float ActualSpeed; //定义实际值 6 float err; //定义偏差值 7 float err_last; //定义上一个偏差值 8 float Kp, Ki, Kd; //定义比例、积分、微分系数 9 float voltage; //定义电压值(控制执行器的变量) 10 float integral; //定义积分值 11 float umax; 12 float umin; 13 }pid; 14 15 void PID_init() { 16 printf("PID_init begin \n"); 17 pid.SetSpeed = 0.0; 18 pid.ActualSpeed = 0.0; 19 pid.err = 0.0; 20 pid.err_last = 0.0; 21 pid.voltage = 0.0; 22 pid.integral = 0.0; 23 pid.Kp = 0.2; 24 pid.Ki = 0.1; //注意,和上几次相比,这里加大了积分环节的值 25 pid.Kd = 0.2; 26 pid.umax = 400; 27 pid.umin = -200; 28 printf("PID_init end \n"); 29 } 30 float PID_realize(float speed) { 31 int index; 32 pid.SetSpeed = speed; 33 pid.err = pid.SetSpeed - pid.ActualSpeed; 34 35 if (pid.ActualSpeed > pid.umax) //灰色底色表示抗积分饱和的实现 36 { 37 38 if (abs(pid.err) > 200) //蓝色标注为积分分离过程 39 { 40 index = 0; 41 } 42 else { 43 index = 1; 44 if (pid.err < 0) 45 { 46 pid.integral += pid.err; 47 } 48 } 49 } 50 else if (pid.ActualSpeed 200) //积分分离过程 52 { 53 index = 0; 54 } 55 else { 56 index = 1; 57 if (pid.err > 0) 58 { 59 pid.integral += pid.err; 60 } 61 } 62 } 63 else { 64 if (abs(pid.err) > 200) //积分分离过程 65 { 66 index = 0; 67 } 68 else { 69 index = 1; 70 pid.integral += pid.err; 71 } 72 } 73 74 pid.voltage = pid.Kp*pid.err + index * pid.Ki*pid.integral / 2 + pid.Kd*(pid.err - pid.err_last); //梯形积分 75 76 pid.err_last = pid.err; 77 pid.ActualSpeed = pid.voltage*1.0; 78 return pid.ActualSpeed; 79 } 80 81 int main() 82 { 83 printf("System begin \n"); 84 PID_init(); 85 int count = 0; 86 while (count < 1500) 87 { 88 float speed = PID_realize(200.0); 89 printf("%f\n", speed); 90 count++; 91 } 92 return 0; 93 }结论最后运算的稳定数据为:199.999878,较教程六中的199.9999390而言,精度进一步提高。 总结:积分项的引入目的就是为了消除系统的余差,那么积分项的计算精度越高,对消除系统的余差就越有利。梯形积分相较于矩形积分其精度有比较大的提高,所以对消除余差也就越有效。 PID控制算法的C语言实现八 变积分的PID控制算法C语言实现 变积分PID可以看成是积分分离的PID算法的更一般的形式。在普通的PID控制算法中,由于积分系数ki是常数,所以在整个控制过程中,积分增量是不变的。但是,系统对于积分项的要求是,系统偏差大时,积分作用应该减弱甚至是全无,而在偏差小时,则应该加强。积分系数取大了会产生超调,甚至积分饱和,取小了又不能短时间内消除静差。因此,根据系统的偏差大小改变积分速度是有必要的。 变积分PID的基本思想是设法改变积分项的累加速度,使其与偏差大小相对应:偏差越大,积分越慢; 偏差越小,积分越快。 设置系数f(e(k)),它是e(k)的函数。当∣e(k)∣增大时,f减小,反之增大。变速积分的PID积分项表达式为:
系数f与偏差当前值∣e(k)∣的关系可以是线性的或是非线性的,例如,可设为:
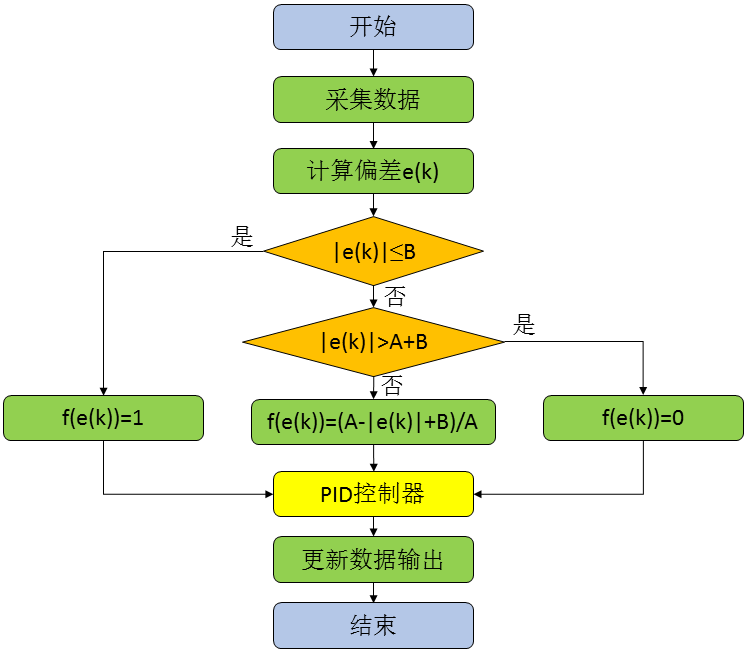
由以上公式可知,f(err(k))的值在[0,1]区间变化,当偏差值|err(k)|大于分离区间A+B时,不对当前偏差err(k)进行累加;当偏差值|err(k)|小于B时,加入当前偏差err(k)进行累加;介于B和A+B的区间时,按一定函数关系随err(k)变化。于是变积分PID算法可以表示为: 上述的f(err(k))函数只是我们列举的一种,事实上可以采取任何可行的方式,甚至是非线性函数,只要更符合控制对象的特性。 对于用增量型PID算法的变积分表示如下: 看到这个公式,很多人可能会发觉与前面的积分分离算法的公式很象。特别是在增量型算法中,它们的形式确实是一样的,但表达的意思确是有一定区别,那么我们来看看有什么不同呢?在后面我们再作总结。 变积分实际上是通过对偏差的判断,让积分以不同的速度累计。这一系数介于0-1之间,可以通过多种方式实现,在这里我们按线性方式实现。变积分的控制流程图如下:
这里给积分系数前加上一个比例值index: 当abs(err) 200) //变积分过程 33 { 34 index = 0.0; 35 } 36 else if (abs(pid.err) < 180) { 37 index = 1.0; 38 pid.integral += pid.err; 39 } 40 else { 41 index = (200 - abs(pid.err)) / 20; 42 pid.integral += pid.err; 43 } 44 pid.voltage = pid.Kp*pid.err + index * pid.Ki*pid.integral + pid.Kd*(pid.err - pid.err_last); 45 46 pid.err_last = pid.err; 47 pid.ActualSpeed = pid.voltage*1.0; 48 return pid.ActualSpeed; 49 } 50 51 int main() 52 { 53 printf("System begin \n"); 54 PID_init(); 55 int count = 0; 56 while (count < 1500) 57 { 58 float speed = PID_realize(200.0); 59 printf("%f\n", speed); 60 count++; 61 } 62 return 0; 63 } 代码结果自行运行 最终结果可以看出,系统的稳定速度非常快(测试程序参见本系列教程3)
总结:
变积分实际上有一定的专家经验在里面,因为限值的选取以及采用什么样的函数计算系数,有很大的灵活性。
我们在前面做了积分分离的算法,这次又说了变积分的算法。他们有相通的地方,也有不同的地方,下面对他们进行一些说明。
首先这两种算法的设计思想是有区别的。积分分离的思想是偏差较大时,取消积分;而偏差较小时引入积分。变积分的实现是想是设法改变积分项的累加速度,偏差大时减弱积分;而偏差小时强化积分。有些所谓改进型的积分分离算法实际已经脱离了积分分离的基本思想,而是动态改变积分系数。就这一点而言,特别是在增量型算法中,已经属于变积分的思想了。
其次,对于积分分离来说,该操作是针对整个积分项操作,这一点在位置型PID算法中,表现的尤为明显。而对于变积分来说,是针对当前偏差的积分累计,就是说只影响当前这次的积分部分。再者,具体的实现方式也存在区别,特别是在位置型PID方式下尤为明显。
我们在这里讨论它们的区别原因,佷显然就是我们没办法同时采用这两种优化方式,只能分别实现,在后面我们将实现基于积分项的优化。
PID控制算法的C语言实现九 (1)微分先行PID控制算法 微分先行PID控制的特点是只对输出量yout(k)进行微分,而对给定值rin(k)不进行微分。这样,在改变给定值时,输出不会改变,而被控量的变化通常是比较缓和的。这种输出量先行微分控制适用于给定值rin(k)频繁升降的场合,可以避免给定值升降时引起系统振荡,从而明显地改善了系统的动态特性
(2)不完全微分PID控制算法 在PID控制中,微分信号的引入可改善系统的动态特性,但也易引进高频干扰,在误差扰动突变时尤其显出微分项的不足。若在控制算法中加入低通滤波器,则可使系统性能得到改善 不完全微分PID的结构如下图。左图将低通滤波器直接加在微分环节上,右图是将低通滤波器加在整个PID控制器之后
(3)带死区的PID控制算法 在计算机控制系统中,某些系统为了避免控制作用过于频繁,消除由于频繁动作所引起的振荡,可采用带死区的PID控制算法,控制算式为: 式中,e(k)为位置跟踪偏差,e0是一个可调参数,其具体数值可根据实际控制对象由实验确定。若e0值太小,会使控制动作过于频繁,达不到稳定被控对象的目的;若e0太大,则系统将产生较大的滞后 控制算法流程:
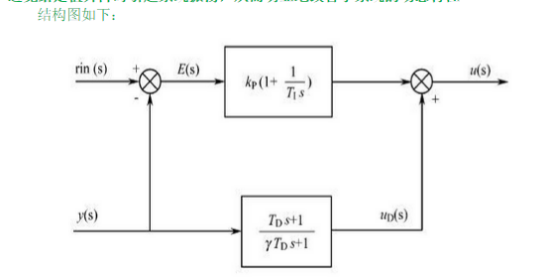
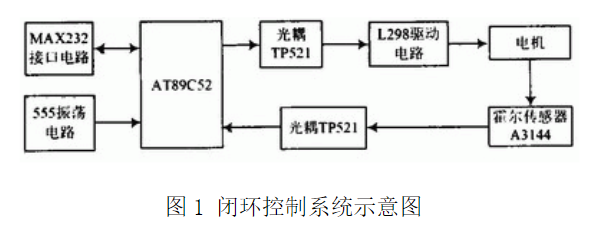
注: PID控制算法的C语言实现十 专家PID与模糊PID的C语言实现本节是PID控制算法的C语言实现系列的最后一节,前面8节中,已经分别从PID的实现到深入的过程进行了一个简要的讲解,从前面的讲解中不难看出,PID的控制思想非常简单,其主要问题点和难点在于比例、积分、微分环节上的参数整定过程,对于执行器控制模型确定或者控制模型简单的系统而言,参数的整定可以通过计算获得,对于一般精度要求不是很高的执行器系统,可以采用拼凑的方法进行实验型的整定。 然而,在实际的控制系统中,线性系统毕竟是少数,大部分的系统属于非线性系统,或者说是系统模型不确定的系统,如果控制精度要求较高的话,那么对于参数的整定过程是有难度的。专家PID和模糊PID就是为满足这方面的需求而设计的。专家算法和模糊算法都归属于智能算法的范畴,智能算法最大的优点就是在控制模型未知的情况下,可以对模型进行控制。这里需要注意的是,专家PID也好,模糊PID也罢,绝对不是专家系统或模糊算法与PID控制算法的简单加和,他是专家系统或者模糊算法在PID控制器参数整定上的应用。也就是说,智能算法是辅助PID进行参数整定的手段。 其实在前面几节的讲述中,已经用到了专家PID的一些特例行为了,从第五节到第八节都是专家系统一些特列化的算法,对某些条件进行了局部的判定,比如如果偏差太大的话,就去除积分项,这本身就是含有经验的专家系统。 专家系统、模糊算法,需要参数整定就一定要有整定的依据,也就是说什么情况下整定什么值是要有依据的,这个依据是一些逻辑的组合,只要找出其中的逻辑组合关系来,这些依据就再明显不过了。下面先说一下专家PID的C语言实现。正如前面所说,需要找到一些依据,还得从PID系数本身说起。 1.比例系数Kp的作用是加快系统的响应速度,提高系统的调节精度。Kp越大,系统的响应速度越快,系统的调节精度越高,但是容易产生超调,甚至会使系统不稳定。Kp取值过小,则会降低调节精度,使响应速度缓慢,从而延长调节时间,是系统静态、动态特性变差; 2.积分作用系数Ki的作用是消除系统的稳态误差。Ki越大,系统的静态误差消除的越快,但是Ki过大,在响应过程的初期会产生积分饱和的现象,从而引起响应过程的较大超调。若Ki过小,将使系统静态误差难以消除,影响系统的调节精度; 3.微分系数Kd的作用是改善系统的动态特性,其作用主要是在响应过程中抑制偏差向任何方向的变化,对偏差变化进行提前预报。但是kd过大,会使响应过程提前制动,从而延长调节时间,而且会降低系统的抗干扰性。 反应系统性能的两个参数是系统误差e和误差变化律ec,这点还是好理解的: 首先我们规定一个误差的极限值,假设为Mmax;规定一个误差的比较大的值,假设为Mmid;规定一个误差的较小值,假设为Mmin; 当abs(e)>Mmax时,说明误差的绝对值已经很大了,不论误差变化趋势如何,都应该考虑控制器的输入应按最大(或最小)输出,以达到迅速调整误差的效果,使误差绝对值以最大的速度减小。此时,相当于实施开环控制。 当e*ec>0时,说明误差在朝向误差绝对值增大的方向变化,此时,如果abs(e)>Mmid,说明误差也较大,可考虑由控制器实施较强的控制作用,以达到扭转误差绝对值向减小的方向变化,并迅速减小误差的绝对值。此时如果abs(e) temp ) 65 { 67 Pwm.DutyCycle_Uint8 = Pwm.DutyCycle_Uint8 - temp; 69 } 71 else 73 { 75 Pwm.DutyCycle_Uint8 = 0; 77 } 79 } 81 else 83 { 85 return; 87 } 89 } 91 else //如果当前电压小于输出电压 93 { 94 95 if( ( UKTemp - ADPool.Value_Uint16[UPWMADCH] ) > UDELTA ) 96 97 { 98 99 temp = UKTemp - ADPool.Value_Uint16[UPWMADCH]; 100 101 temp = temp / 4; //上升处理不要超调,所以每次只+一半 102 103 if( (255-Pwm.DutyCycle_Uint8) > temp ) 104 105 { 106 107 Pwm.DutyCycle_Uint8 += (temp/2); 108 109 } 110 111 else 112 113 { 114 115 Pwm.DutyCycle_Uint8 = 255; 116 117 } 118 119 } 120 121 else 122 123 { 124 125 return; 126 127 } 128 129 } 130 131 DisPlayVoltage(); 132 133 PWMChangeDuty(Pwm.DutyCycle_Uint8); //改变占空比 134 135 Delay(10,10); 136 137 138 139 } 140 141 } 142 143 } 144 145 /*****************************************************/ 附录2 直流电机PWM调速系统中控制电压非线性研究 引言 由于线性放大驱动方式效率和散热问题严重,目前绝大多数直流电动机采用开关驱动方式。开关驱动方式是半导体功率器件工作在开关状态,通过脉宽调制PWM控制电动机电枢电压,实现调速。目前已有许多文献介绍直流电机调速,宋卫国等用89C51单片机实现了直流电机闭环调速;张立勋等用AVR单片机实现了直流电机PWM调速;郭崇军等用C8051实现了无刷直流电机控制;张红娟等用PIC单片机实现了直流电机PWM调速;王晨阳等用DSP实现了无刷直流电机控制。上述文献对实现调速的硬件电路和软件流程的设计有较详细的描述,但没有说明具体的调压调速方法,也没有提及占空比与电机端电压平均值之间的关系。在李维军等基于单片机用软件实现直流电机PWM调速系统中提到平均速度与占空比并不是严格的线性关系,在一般的应用中,可以将其近似地看作线性关系。但没有做深入的研究。本文通过实验验证,在不带电机情况下,PWM波占空比与控制输出端电压平均值之间呈线性关系;在带电机情况下,占空比与电机端电压平均值满足抛物线方程,能取得精确的控制。本文的电机闭环调速是运用Matlab拟合的关系式通过PID控制算法实现。 1 系统硬件设计 本系统是基于TX-1C实验板上的AT89C52单片机,调速系统的硬件原理图如图1所示,主要由AT89C52单片机、555振荡电路、L298驱动电路、光电隔离、霍尔元件测速电路、MAX 232电平转换电路等组成。
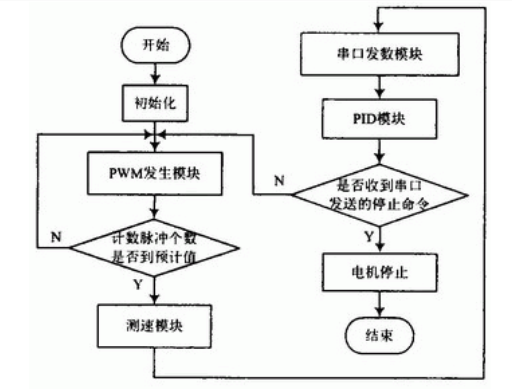
2 系统软件设计 系统采用模块化设计,软件由1个主程序,3个中断子程序,即外部中断0、外部中断1,定时器0子程序,PID算法子程序,测速子程序及发送数据到串口显示子程序组成,主程序流程图如图2所示。外部中断0通过比较直流电平与锯齿波信号产生PWM波,外部中断1用于对传感器的脉冲计数。定时器0用于对计数脉冲定时。测得的转速通过串口发送到上位机显示,通过PID模块调整转速到设定值。本实验采用M/T法测速,它是同时测量检测时间和在此检测时间内霍尔传感器所产生的转速脉冲信号的个数来确定转速。由外部中断1对霍尔传感器脉冲计数,同时起动定时器0,当计数个数到预定值2 000后,关定时器0,可得到计2 000个脉冲的计数时间,由式计算出转速: n=60f/K=60N/(KT) (1) 式中:n为直流电机的转速;K为霍尔传感器转盘上磁钢数;f为脉冲频率;N为脉冲个数;T为采样周期。
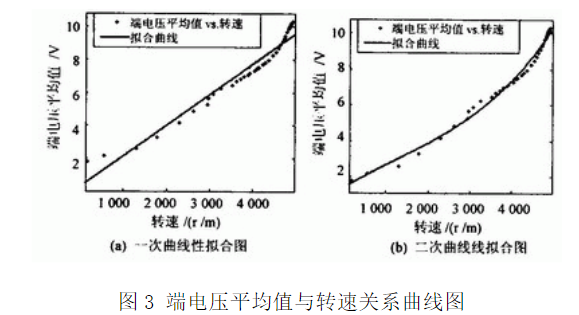
3 实验结果及原因分析 3.1 端电压平均值与转速关系 3.1.1 实验结果 实验用的是永磁稳速直流电机,型号是EG-530YD-2BH,额定转速2 000~4 000 r/min,额定电压12 V。电机在空载的情况下,测得的数据用Matlab做一次线性拟合,拟合的端电压平均值与转速关系曲线如图3(a)所示。相关系数R-square:0.952 1。拟合曲线方程为: y=0.001 852x+0.296 3 (2) 由式(2)可知,端电压平均值与转速可近似为线性关系,根椐此关系式,在已测得的转速的情况下可以计算出当前电压。为了比较分析,同样用Matlab做二次线性拟合,拟合的端电压平均值与转速关系曲线如图3(b)所示。相关系数R-square:0.986 7。
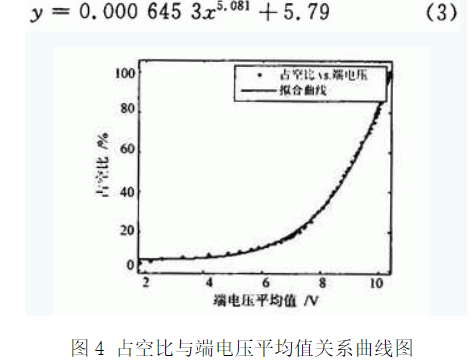
3.1.2 原因分析 比较图3(a)可知,当转速在0~1 500 r/min和4 000~5 000 r/min,端电压平均值与转速间存在的非线性,用二次曲拟合如图3(b)所示,拟合相关系数较高。由图3(a)可见,当电机转速为0时电机两端电压平均值约为1.3 V。这是因为电机处于静止状态时,摩擦力为静摩擦力,静摩擦力是非线性的。随着外力的增加而增加,最大值发生在运动前的瞬间。电磁转矩为负载制动转矩和空载制动转矩之和,由于本系统不带负载,因此电磁转矩为空载制动转矩。空载制动转矩与转速之间此时是非线性的。电磁转矩与电流成正比,电流又与电压成正比,因此此时电压与转速之间是非线性的。 当转速在2 000~4 000 r/min线性关系较好,占空比的微小改变带来的转速改变较大,因此具有较好的调速性能。这是因为随着运动速度的增加,摩擦力成线性的增加,此时的摩擦力为粘性摩擦力。粘性摩擦是线性的,与速度成正比,空载制动转矩与速度成正比,也即电磁转矩与电流成正比,电流又与电压成正比,因此此时电压与转速之间是线性的。当转速大于4 000 r/min。由于超出了额定转速所以线性度较差且调速性能较差。此时用二次曲线拟合结果较好,因为当电机高速旋转时,摩擦阻力小到可以忽略,此时主要受电机风阻型负荷的影响,当运动部件在气体或液体中运动时,其受到的摩擦阻力或摩擦阻力矩被称为风机型负荷。对同一物体,风阻系数一般为固定值。阻力大小与速度的平方成正比。即空载制动转矩与速度的平方成正比,也即电磁转矩与速度的平方成正比,电磁转矩与电流成正比,电流又与电压成正比,因此此时电压与转速之间是非线性的。 3.2 占空比与端电压平均值关系 3.2.1 实验结果 拟合占空比与端电压平均值关系曲线如图4所示。相关系数R-square:0.998 4。拟合曲线方程为:
如图4所示,占空比与端电压平均值满足抛物线方程。运用积分分离的PID算法改变电机端电压平均值,可以运用此关系式改变占空比,从而实现了PWM调速。 用示波器分别测出电压的顶端值Utop与底端值Ubase,端电压平均值Uarg满足关系式:
其中:α为占空比。 正是由于所测得的电机端电压底端值Ubase不为0,所以得出的占空比与端电压平均值之间关系曲线为抛物线。若将电机取下,直接测L298的out1与out2输出电压。所测得的电机端电压底端值Ubase约为0,所得的占空比与端电压平均值满足线性关系,即令式(4)中Ubase为0,式(4)变为:
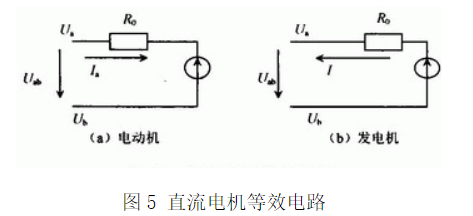
3.2.2 原因分析 将电机取下后,直接测L298的输出端之间的电压,占空比与端电压平均值满足关系式(5),说明整个硬件电路的设计以及软件编程的正确性。从电机反电势角度分析,当直流电机旋转时,电枢导体切割气隙磁场,在电枢绕组中产生感应电动势。由于感应电动势方向与电流的方向相反,感应电动势也即反电势。直流电机的等效模型如图5所示。图5(a)表示电机工作在电动机状态。图5(b)表示电机工作在发电机状态。
如图5(a)所示,电压平衡方程为:
式中:U为外加电压;Ia为电枢电流;Ra为电枢绕组电阻;2△Ub为一对电刷接触压降,一般取2△Ub为0.5~2 V;Ea为电枢绕组内的感应电动势。电机空载时,电枢电流可忽略不计,即电流Ia为0。空载时的磁场由主磁极的励磁磁动势单独作用产生。给电机外加12 V的额定电压,由(6)可得反电势:
以40%的占空比为例,电机端电压Uab是测量中的电压平均值Uarg,其值为8.34 V,测量中的电压底端值Ubase约为7 V。由式(7)可得Ea的值范围应在6.34~7.84 V。由图5(b)可见,此时Uab的值是测得的底端值Ubase即电机的电动势Ea为7 V。 当PWM工作在低电平状态,直流电机不会立刻停止,会继续旋转,电枢绕组切割气隙磁场,电机此时工作在发电机状态,产生感应电动势E。
式中:Ce为电机电动势常数;φ为每级磁通量。由于电机空载,所以图5(b)中无法形成回路。用单片机仿真软件Proteus可直观的看出在PWM为低电平状态,电机处于减速状态。低电平持续时间越长,电机减速量越大。正是由于在低电平期间,电机处于减速状态,由式(8)可知,Ce,φ均为不变量,转速n的变化引起E的改变。此时Uab的值等于E的值。电机在低电平期间不断的减速,由于PWM周期较短,本文中取20 ms,电机在低电平期间转速还未减至0,PWM又变为高电平了。这样,就使测得的Ubase值不为0。以40%的占空比为例,当PWM工作在低电平状态,测得Ubase的值约为7 V。由式(8)可知,当正占空比越大,转速也就越大,同时减速时间越短,感应电势E的值越大。所以Ubase的值也就越大。 4 结语 重点分析了直流电机PWM调速过程中控制电压的非线性,对非线性的影响因素做了详细的分析。由于PWM在低电平期间电压的底端值不为0,导致了占空比与电机端电压平均值之间呈抛物线关系。因此,可用得出的抛物线关系式实现精确调速。本系统的非线性研究可为电机控制中非线性的进一步研究提供依据,在实际运用中,可用于移动机器人、飞行模拟机的精确控制。 附录3隶属函数(membership function),用于表征模糊集合的数学工具。对于普通集合A,它可以理解为某个论域U上的一个子集。为了描述论域U中任一元素u是否属于集合A,通常可以用0或1标志。用0表示u不属于A,而用1表示属于A ,从而得到了U上的一个二值函数χA(u),它表征了U的元素u对普通集合的从属关系,通常称为A的特征函数,为了描述元素u对U上的一个模糊集合的隶属关系,由于这种关系的不分明性,它将用从区间[0,1]中所取的数值代替0,1这两值来描述,记为(u),数值(u)表示元素隶属于模糊集的程度,论域U上的函数μ即为模糊集的隶属函数,而(u)即为u对A的隶属度。
|
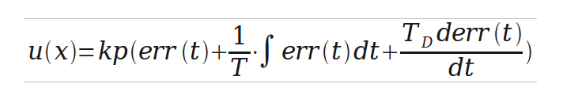
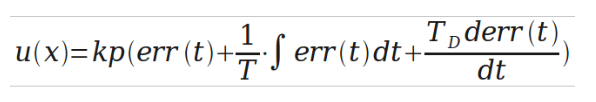
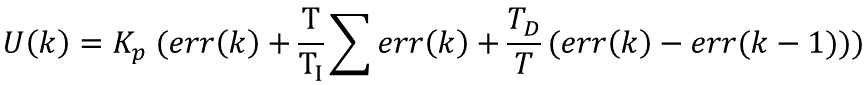

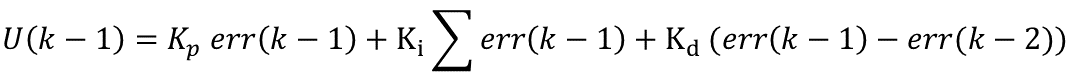
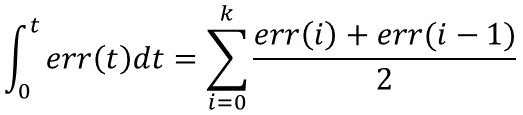
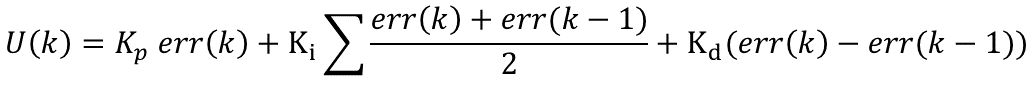
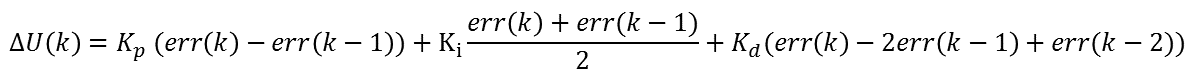
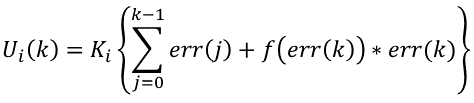
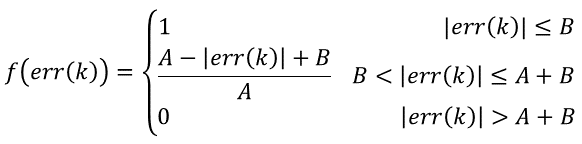
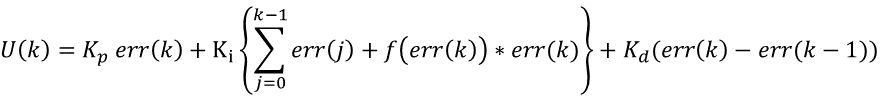



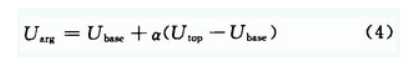

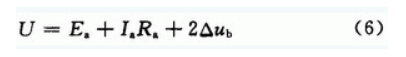



【本文地址】
今日新闻 |
推荐新闻 |