只听几句话,百度AI就能模仿你的声音 |
您所在的位置:网站首页 › 模拟一个人的声音 › 只听几句话,百度AI就能模仿你的声音 |
只听几句话,百度AI就能模仿你的声音
|
夏乙 编译整理量子位 出品 | 公众号 QbitAI
只需要听你说几句话,AI就能“克隆”出你的声音。 这是百度Deep Voice项目最新get的能力。 Deep Voice推出于一年多以前,是一个能实时合成语音的神经网络系统。当时的第一代产品,一个系统只能学习一个人的声音,而且需要用几小时音频进行训练。 百度一直在优化Deep Voice,随后的第二、三代模型就将所需的训练数据降到了半小时,一个系统还能模仿数千人的声音。 这次的“语音克隆”研究,是这一系统的最新进步。 效果究竟如何呢?需要亲耳听一听:
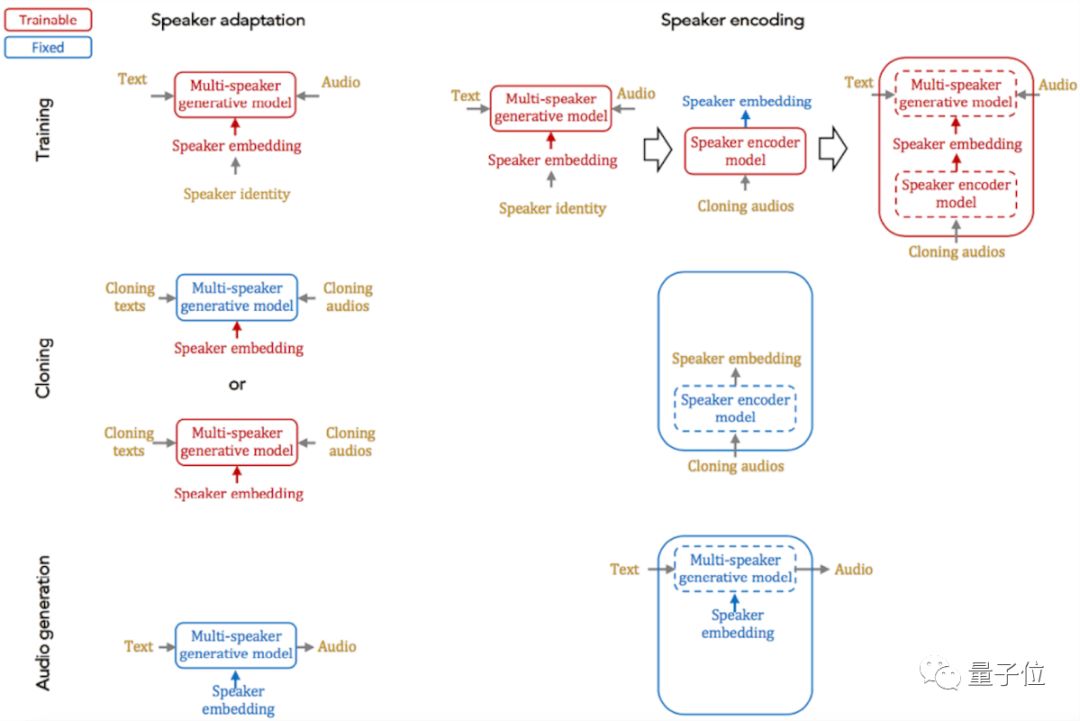
百度放出了用最新技术合成语音的几组例子,上面是量子位转录的其中一个,前一句是真人,后一句是AI克隆出来的。 更多例子在这里:https://audiodemos.github.io 这些例子中,语音克隆系统最多用了10段说话人语音样本,最少只有1个,每段样本只有3秒。量子位听了页面上的这些例子,通过10段样本合成出来的语音,就很自然、和原说话人非常相似了。1段、5段样本训练出来的语音,无论用哪种模型,依然明显不像人类。 在最新公布的论文Neural Voice Cloning with a Few Samples中,百度探讨了解决语音克隆问题的两种基本方法:说话人适应(speaker adaptation)和说话人编码(speaker encoding)。这两种方法的主要过程如下图所示:
两种方法都适用于带有说话人嵌入的多说话人语音生成模型,不会降低其质量。 说话人适应基于反向传播,用少量样本对多说话人生成模型进行微调。这种适应可以应用于整个模型,也可以只用到低维的说话人嵌入(speaker embedding)上。如果只用于说话人嵌入,会拉长克隆所需的时间、降低音频质量,但可以用更少的参数来表示每个说话人。 说话人编码会单独训练一个模型,根据要克隆的音频,结合多说话人生成模型,来推理新的说话人嵌入。说话人编码模型具有从每个音频样本中检索身份信息的时间和频率域处理模块、以最优的方式将它们结合在一起的注意力模块。这种方法的优点是克隆所需时间短,表示每个说话人的参数少,在计算资源不足的设备上也能部署。
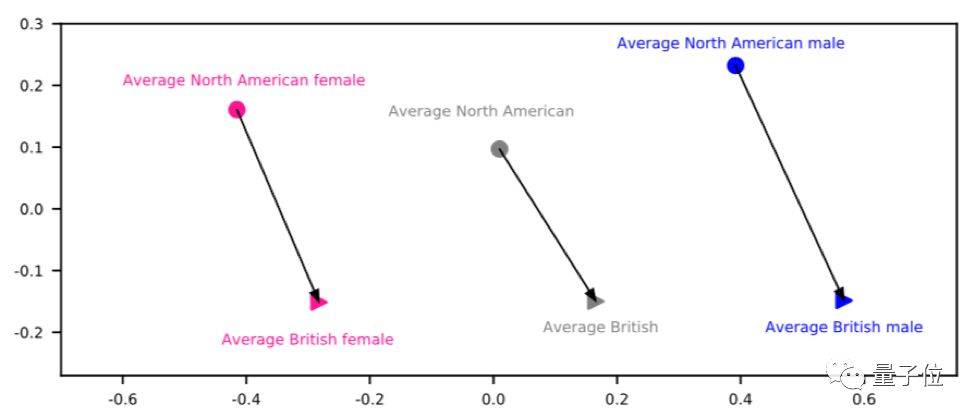
这种方法中的说话人编码器除了能计算出说话人嵌入,还能学会以有意义的方式将不同的说话人投射到嵌入空间,比如不同的性别,或者不同地方的口音会聚集到一起。因此,这个模型还能转换说话人的口音或者性别。 男声变女声、英音变美音的例子,可以在页面最下边找到:https://audiodemos.github.io 听几句话就能模仿你,百度并不是唯一一家,加拿大AI创业公司Lyrebird去年也发布了类似的产品,能通过1分钟音频模仿说话人。这款产品模仿川普、奥巴马、希拉里的音频,可以说是广为流传。 最后,想深入了解百度这次的语音克隆进展,还是要看论文:https://arxiv.org/pdf/1802.06006.pdf 百度研究院博客原文:http://research.baidu.com/neural-voice-cloning-samples/ — 完 — 加入社群 量子位AI社群13群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot5入群; 此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。 进群请加小助手微信号qbitbot5,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解) 诚挚招聘 量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。 
量子位 QbitAI · 头条号签约作者 վ'ᴗ' ի 追踪AI技术和产品新动态 |

【本文地址】
今日新闻 |
推荐新闻 |