没钱买显卡也要用stable diffusion训练人物模型 |
您所在的位置:网站首页 › 模型制作基础 › 没钱买显卡也要用stable diffusion训练人物模型 |
没钱买显卡也要用stable diffusion训练人物模型
|
本文主要提供给没钱买显卡,也想通过stable diffusion训练自己人物模型的同学,怎么使用google colab,完成自己的模型训练. 代码零基础也可以,比如我就真的不会写代码 准备环境1. 需要能科学上网,如果不能的话,直接劝退了; 2. 申请一个google colab;还没有的同学可以看 温柔的玉米:Colab使用教程(超级详细版)及Colab Pro/Pro+评测 温柔的玉米 启动环境写好的colab https://colab.research.google.com/drive/1YPTUkWvvW4K2wtueOVr-4gehutPbigrq?usp=sharing 进入之后 点击 connect.  给我分配的GPU 15G, 不知道市价多少,反正免费的,还要什么自行车啊  第二步,直接执行运行,底下能看见日志,启动时间大概不到5分钟, 期间,会要google drive的权限.希望能访问google drive是要把训练的内容和日志放到drive里,colab的内容12小时后会被清空,挂在网盘里比较安全,不过看到其他文章有介绍过colab和drive访问的过程有点慢,实际操作如果不是10+G的大文件,基本还好.等看到日志,展示端口号时,服务就启动好了,  点击 public URL, 直接能在浏览器里看到 sd 的webui了. 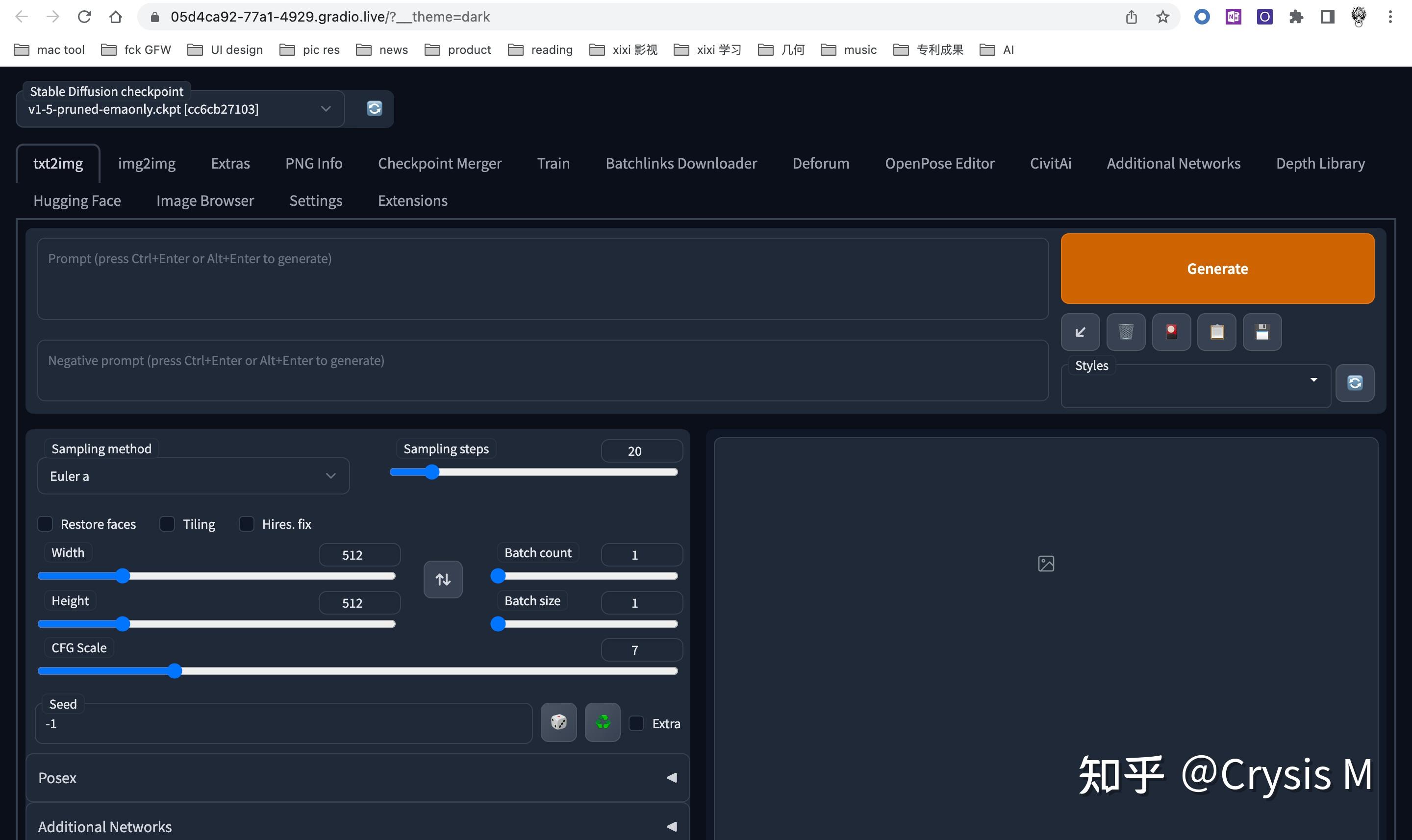 至此环境就启动好了. 准备素材把要训练的照片剪切成 512*512的大小; 想训练的照片最好有些区分 3张不同角度的全身照,5张不同角度的半身照,12张不同角度不同表情的大头照.(100张以下多多益善)  在google drive里建立一个文件夹,把照片都扔进去, 我的是MyDrive/AI/raw  予处理 予处理回到启动好的webui界面, 找到 train标签 下面的preprocess images  source 是 原始的图片, 如果用云盘就写 /content/drive/MyDrive/AI/raw. destination是 目标目录,会把源目录的图片加上标签,生成到目标去 /content/drive/MyDrive/AI/input width和height是大小; Create flipped copies 会把图片翻转后,再复制一份,用于训练, 选上; Split oversized images 会把超大的图片剪切了, Use BLIP for caption 用CLIP自动为图像打标签,选上; 开始进行处理;执行后,会在drive里收到一些描述文件.  开始训练 开始训练回到create embedding页,创建一个自己模型的名字,随便写.  Number of vectors per token :如果图片不超过100张,最好选3以下,1~2足以;创建完后,会在/content/stable-diffusion-webui/embeddings/下面生成一个pt文件,  回到 train的标签下,通过上述努力,可以祈祷一下,然后正式训练了. 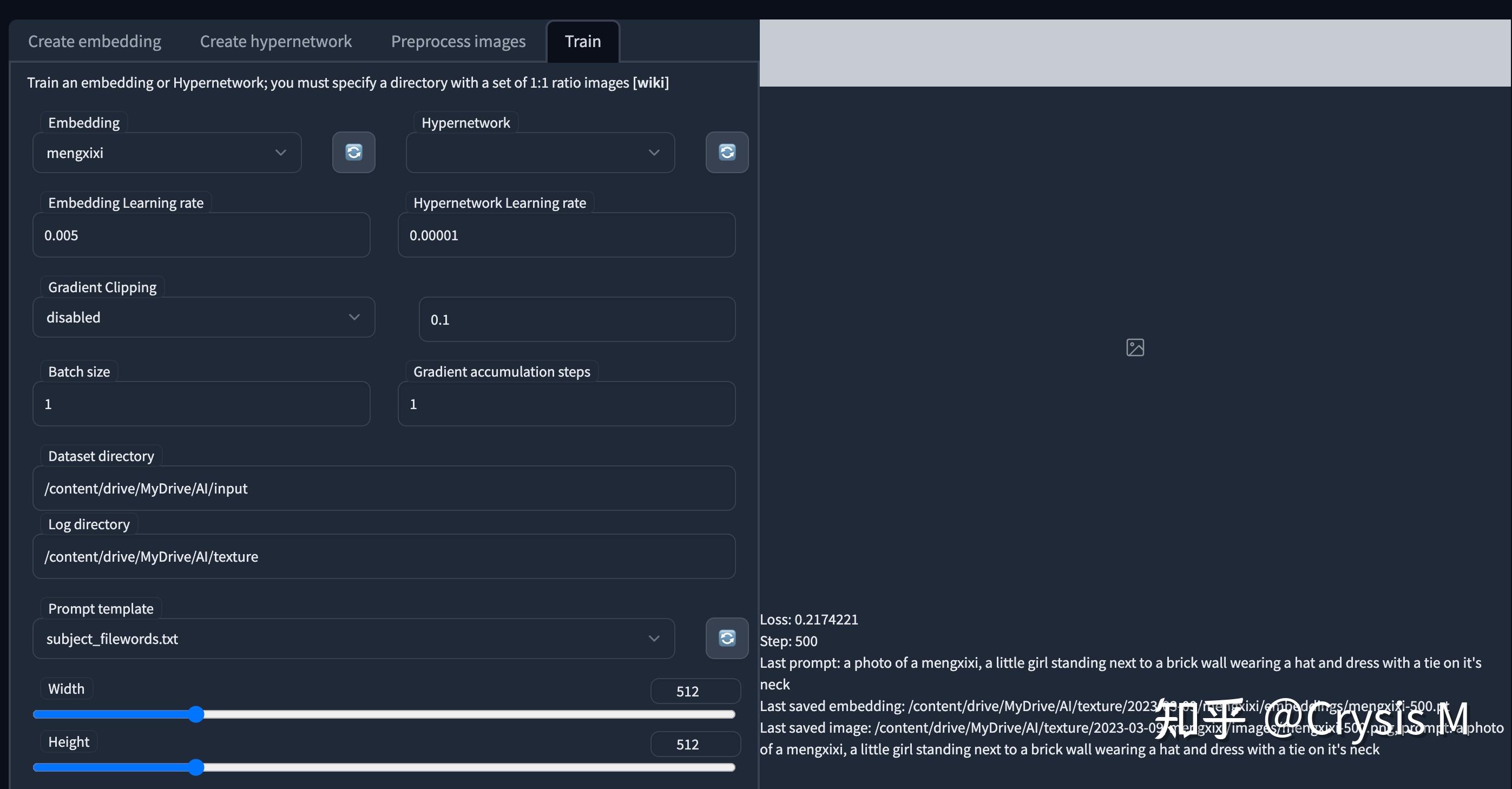 Embedding 下拉出刚才建立的pt名字, Embedding Learning rate 是学习率,这个玄学东西低的话效率会特别慢,高的会训练出来的会特别诡异.所以我掐指一算,这数可以不改; Dataset directory 是刚才目标的目录/content/drive/MyDrive/AI/input, Log directory 是日志会的目录, 我也放到了云盘上, /content/drive/MyDrive/AI/texture, 防丢; Prompt template 如果不是训练风格的话,就选subject_filewords.txt. Max steps 是最大的训练步数,默认10W,挺恐怖的,特跑10+小时, 我使的人物至少4000起步,1W以上,不过配合下面的日志可以设置稍微大一点,会生成几个模型文件. Save an image to log directory every N steps, 0 to disable 跑多少步后,会保存一个日志,默认500. 点击[train embidding]启动后然后就是漫长的等待,  我跑10W步需要17个小时,不过每500步就会存一个日志.  跑的时候colab的页面 不要关!不要关!!不要关!!! 跑的过程中会生成一个反应loss值的csv文件,loss值越小越接近目标,如果有大神的话,可以帮忙指正一下,为什么loss值会到后面反而升高了.  使用 使用把训练好的pt文件,放在/stable-diffusion-webui/embeddings/下,生成页面就有了textual的pt模型.我保留三个展示下效果.  使用的时候prompt直接写关键词就行,比如 mengxixi-12000,  RAW photo, a portrait photo of 9 y.o girl in casual clothes, mengxixi-12000,night, city street,8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3效果 RAW photo, a portrait photo of 9 y.o girl in casual clothes, mengxixi-12000,night, city street,8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3效果训练的模型是我家的小天使  训练6000步的模型 训练6000步的模型 1w步 1w步 12K步 12K步 原版 原版就loss来看,6K步是0.02, 1w步是0.44,1w2步是0.08, 个人感觉1w步之后,找个loss值小的,效果就可以. 其他-one more thingsssssscolab 超时,超量blablaweb页面长时间无交互,会被踢下来,资源占用太多,会提示没GPU了.基本等一天就可以. 我是下午出的提示,第二天上午就可以了.  而且日志文件保留的话,训练会继续之前的内容; 技术是有态度的我本人不认可“技术无罪”的口号,因为使用技术的人本身是有态度的.望同学们净化环境,那些就算打了马赛克也不适合给别人看的东西,自己开心就好,别乱转播. |
【本文地址】