【笔记】概统论与数理统计第四章知识点总结 |
您所在的位置:网站首页 › 概率论与数理统计第一章笔记 › 【笔记】概统论与数理统计第四章知识点总结 |
【笔记】概统论与数理统计第四章知识点总结
|
4.1 数学期望
1. 离散型随机变量的数学期望 E(X):随机变量X取值的加权平均值,权重为概率,级数𝑖=1∞𝑥𝑖𝑝𝑖收敛,则0-1分布X~B(1, p):E(x) = p二项分布X~(n, p):E(X) =np指数分布X~e(𝛌):E(X) =2. 连续型随机变量的数学期望: 3. 随机变量函数的数学期望 一维随机变量: 离散型:X 为离散型随机变量,其分布律为
公式的意义:求E(Y)时,不必算出的分布律或概率密度,而只要利用X的分布律或概率密度就可以了 连续型:若X为连续型的,其密度函数为f(x),且反常积分
离散型:若 (X, Y) 是离散型,二维概率分布律为
连续型:若(X, Y)为连续型,其二维密度函数为f(x, y),且反常积分
4. 数学期望的性质 E(C) = CE(CX) = CE(X)E(aX + bY) = aE(X) + bE(Y)4.2 方差和矩 1. 方差的定义及计算 方差:随机变量 X 取值在期望 E(X) 周围的集中程度定义: X为离散型: 2. 方差的性质 D(C) = 0D(aX+b) =
随机变量
3. 变异系数、原点矩及中心距 变异系数:在比较两个随机变量的取值集中程度时消除方差和标准差的量纲,衡量了 X 取值在 E(X) 周围的相对集中程度(越小越集中)定义:若随机变量 X 的期望、方差均存在, 且 E(X) ≠ 0, 则
随机变量的原点矩和中心距: 是非负整数 X 的 k 阶原点矩: X 的 k 阶中心矩: 1. 协方差 定义:Cov(X, Y) = E(X − E(X))(Y − E(Y)) = E(XY) − E(X)E(Y)特别情况:Cov(X, X) = D(X)计算 离散型
协方差的性质 Cov(X, Y) = Cov(Y, X) Cov(aX, Y) = a Cov(X, Y)Cov(X + Y, Z) = Cov(X, Z) + Cov(Y, Z)Cov(X, a) = 0Cov(X, Y) = E(XY) − E(X)E(Y)若 X, Y 独立, 那么, Cov(X, Y) = 0D(X ± Y) = D(X) + D(Y) ± 2 Cov(X, Y)协方差阵:
2. 相关系数 协方差反映随机变量 X 与 Y 的线性相关关系, 但它受量纲的影响:Cov(aX, bY) = ab Cov(X, Y)。我们将根据协方差定义出一个不受量纲影响的相关系数定义:
注意:独立性蕴含不相关性, 反之未必 性质 R(X,Y)=R(Y,X)|R(X,Y)|≤1|R(X, Y)| = 1 的充要条件为:存在常数 a, b, 且 a = 0,使得 P(Y = aX + b) = 1 (X与Y线性相关) |
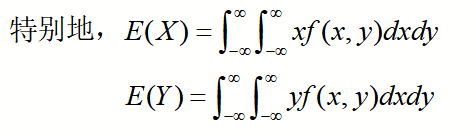
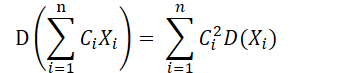
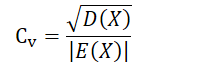
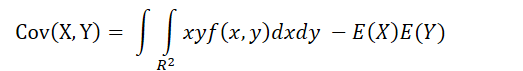
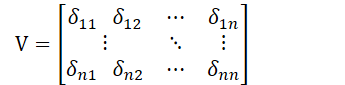
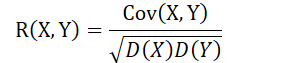
【本文地址】
今日新闻 |
推荐新闻 |