EfficientNet实现农业病害识别(FastDeploy部署和安卓端部署) |
您所在的位置:网站首页 › 植物病害识别app的开发与应用 › EfficientNet实现农业病害识别(FastDeploy部署和安卓端部署) |
EfficientNet实现农业病害识别(FastDeploy部署和安卓端部署)
|
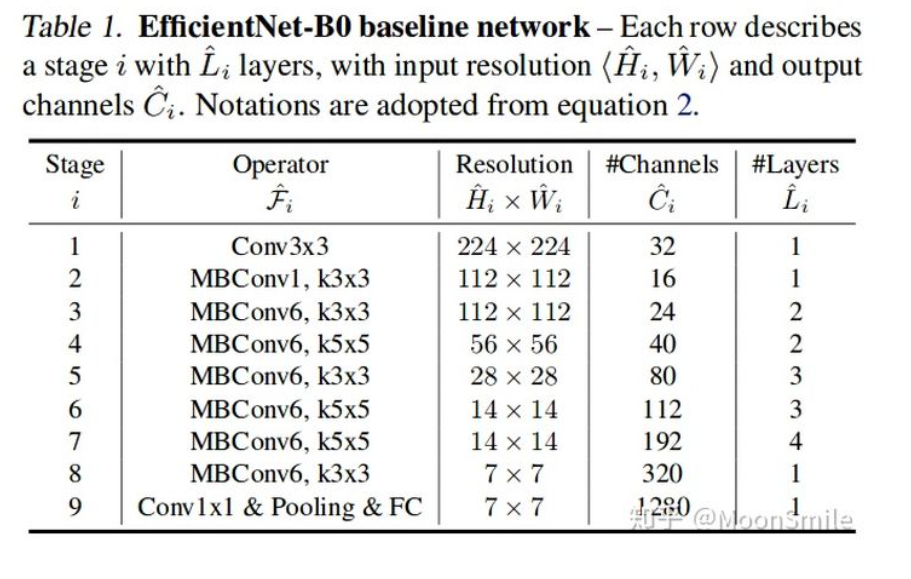
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>> 一、项目简介 1、项目背景:基于视觉深度学习的农业病害智能识别,旨在解决传统人眼识别病虫害的方法速度较慢、准确度较低等导致农药的滥用,破坏自然环境,为帮助农业病害提供一种解决思路。该项目使用2018年农作物病害数据集数据集训练,并完成了FastDeploy+pyqt5部署和Paddle Lite安卓部署。 2、项目意义: 联合国粮食及农业组织最近的一份报告表明,每年农业生产的自然损失中有三分之一以上是由农业病虫害造成的,使这些成为当前影响农业生产和农业生产的最重要因素。需要考虑的农业病虫害众多,依赖于实验室观察和实验的传统方法很容易导致错误的诊断。除此之外,缺乏专业的农业技术人员往往难以及时发现病虫害以采取适当的补救措施。为了克服这些问题,许多研究人员转向使用机器学习方法和计算机视觉技术来识别农业病虫害。这首先涉及分析和处理与植物病虫害相关的图像数据。在此之后,建立机器学习模型以获得与不同图像特征相关的不同层次。最后,使用分类器来快速准确地识别不同类型的病虫害。所有采用这种方法的研究的最终目的都是为农业病虫害的防治提供技术指导。 农业病害的图像识别比农业病虫害的识别更具挑战性。各种机器学习方法已经解决了这个问题。这些包括聚类方法、SVM分类器、贝叶斯分类器和浅层神经网络方法。许多这项工作正在进行中。然而,传统的机器学习方法在用于农业病害图像识别的实际应用中,往往存在一些不足:它们高度依赖于原始疾病图像的质量;这些方法的实现通常非常复杂;如果训练样本的数量很大,使用这些传统的机器学习方法很难有效地构建相应的模型。 随着现代智能农业的发展,使得使用更先进、更智能的机器学习方法来利用这些数据提供的机会来提高农业病害图像的有效性变得越来越重要。机器学习方法的最新进展,如深度学习和迁移学习,在许多应用领域取得了重大突破,并开始被用于农业病害图像识别。 二、数据来源与数据详情本研究基于AI Challenger农作物叶子图像数据集包含10种植物(苹果、樱桃、葡萄、柑桔、桃、草莓、番茄、辣椒、玉米、马铃薯)的27种病害(其中24个病害有分一般和严重两种程度),合计61个分类(按“物种-病害-程度”分)的特性,训练图像总数为31718张,测试图像总数为4540张。每张图包含一片农作物的叶子,叶子占据图片主要位置。 同国外相比,我国对于农作物病害识别的应用研究任重道远。深度学习在农作物病害智能识别的应用有: ①耕眼App:实现柑橘、葡萄、芒果、蔬菜病害识别及相关防治方案等 ②识农微信小程序:实现柑橘、葡萄、芒果、苹果、水稻、小麦病虫害识别及相关防治方案等。但目前的相关深度学习农作物病虫害应用是基于现有深度学习基本框架下的集成应用,主要存在以下不足: ①在识别精度上有待提升 ②在可识别的农作物种类上有待增加 ③对于病害的粒度有待细分等综上所述,本作品基于AI Challenger农作物叶子图像数据集包含10种植物的27种病害,合计61个分类(按“物种-病害-程度”分)的特性,主要从以下几个方面考虑改进: ①增加一定的农作物种类 ②优选模型,注重预测精度 ③训练调优实现精度提升 ④对农作物的病害程度实现一定细化 ⑤开发农作物病害智能识别系统 三、技术路线 1.PaddleClas简介飞桨图像分类套件PaddleClas是飞桨为工业界和学术界所准备的一个图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。 PaddleClas特性 丰富的模型库:基于ImageNet1k分类数据集,PaddleClas提供了29个系列的分类网络结构和训练配置,133个预训练模型和性能评估。SSLD知识蒸馏:基于该方案蒸馏模型的识别准确率普遍提升3%以上。数据增广:支持AutoAugment、Cutout、Cutmix等8种数据增广算法详细介绍、代码复现和在统一实验环境下的效果评估。10万类图像分类预训练模型:百度自研并开源了基于10万类数据集训练的 ResNet50_vd 模型,在一些实际场景中,使用该预训练模型的识别准确率最多可以提升30%。多种训练方案,包括多机训练、混合精度训练等。多种预测推理、部署方案,包括TensorRT预测、Paddle-Lite预测、模型服务化部署、模型量化、Paddle Hub等。可运行于Linux、Windows、MacOS等多种系统。 2、网络选择 红色的线是 EfficientNet 的曲线,横轴为模型大小,纵轴为准确率。从图中可以看出几乎碾压了众多之前熟悉的经典网络模型。它使用一个简单而高效的复合系数来从depth, width, resolution 三个维度放大网络,不会像传统的方法那样任意缩放网络的维度,基于神经结构搜索技术可以获得最优的一组参数(复合系数)。 红色的线是 EfficientNet 的曲线,横轴为模型大小,纵轴为准确率。从图中可以看出几乎碾压了众多之前熟悉的经典网络模型。它使用一个简单而高效的复合系数来从 depth, width, resolution 三个维度放大网络,不会像传统的方法那样任意缩放网络的维度,基于神经结构搜索技术可以获得最优的一组参数(复合系数)。

此项目选用的网络为EfficientNetB4版本,如选用更高的版本,输入图片的体积更大,会大大增加显存的使用,会造成爆显存。 3、模型库链接:Paddleclas代码GitHub链接: https://github.com/PaddlePaddle/PaddleClas Paddleclas代码Gitee链接: https://gitee.com/PaddlePaddle/PaddleClas Paddleclas文档链接: https://paddleclas.readthedocs.io/zh_CN/latest/ 四、环境配置 首先更新pip pip install --upgrade pip %cd /home/aistudio/work/ # 克隆Paddleclas仓库 # gitee 国内下载比较快 !git clone https://gitee.com/PaddlePaddle/PaddleClas.git # github # !git clone https://github.com/PaddlePaddle/PaddleClas.git %cd /home/aistudio/work/PaddleClas # 导入package !pip install -r requirements.txt 本项目使用数据集🔗此数据集已经过对标签的预处理,txt文件格式:数据地址+标签 # 解压数据集 # 注意数据集压缩包的位置 !echo "解压数据集" !unzip -oq /home/aistudio/data/data199888/bingchong_data.zip -d /home/aistudio/work/PaddleClas/dataset
 六、模型评估
评估前设置一下预测的图片路径 再次打开
~ home/aistudio/work/PaddleClas/ppcls/configs/ImageNet/EfficientNet/EfficientNetB4.yaml
Infer:
infer_imgs: xxx/xxx.jpg # 预测图片路径
batch_size: 1 # 预测图片个数
transforms:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 412
- CropImage:
size: 380 # 与训练图片大小保持一致
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- ToCHWImage:
PostProcess:
name: Topk
topk: 5
class_id_map_file: /home/aistudio/duiyingguanxi.txt # 此文件是标签对应的含义,根据开始数据集说明时的图片可知:0对应苹果健康 1对应苹果黑星病一般.....
%cd /home/aistudio/work/PaddleClas/
!echo "模型预测"
!python tools/infer.py \
-c ppcls/configs/ImageNet/EfficientNet/EfficientNetB4.yaml\
-o Global.pretrained_model=output/EfficientNetB4/best_model
六、模型评估
评估前设置一下预测的图片路径 再次打开
~ home/aistudio/work/PaddleClas/ppcls/configs/ImageNet/EfficientNet/EfficientNetB4.yaml
Infer:
infer_imgs: xxx/xxx.jpg # 预测图片路径
batch_size: 1 # 预测图片个数
transforms:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 412
- CropImage:
size: 380 # 与训练图片大小保持一致
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- ToCHWImage:
PostProcess:
name: Topk
topk: 5
class_id_map_file: /home/aistudio/duiyingguanxi.txt # 此文件是标签对应的含义,根据开始数据集说明时的图片可知:0对应苹果健康 1对应苹果黑星病一般.....
%cd /home/aistudio/work/PaddleClas/
!echo "模型预测"
!python tools/infer.py \
-c ppcls/configs/ImageNet/EfficientNet/EfficientNetB4.yaml\
-o Global.pretrained_model=output/EfficientNetB4/best_model
结果: [{‘class_ids’: [24, 19, 9, 47, 49], ‘scores’: [0.94794, 0.05146, 0.04491, 0.02791, 0.02734], ‘file_name’: ‘./dataset/putao.png’, ‘label_names’: [‘柑桔健康’, ‘葡萄黑腐病严重’, ‘玉米健康’, ‘番茄早疫病严重’, ‘番茄晚疫病菌严重’]}] '24’代表置信度最高的标签,‘0.94794’代表置信度,‘柑桔健康’代表标签含义 七、模型导出 # 导出模型 !echo "模型导出" !python tools/export_model.py -c ./ppcls/configs/ImageNet/EfficientNet/EfficientNetB4.yaml\ -o Global.pretrained_model=./output/EfficientNetB4/best_model\ -o Global.save_inference_dir=./inference模型结构:
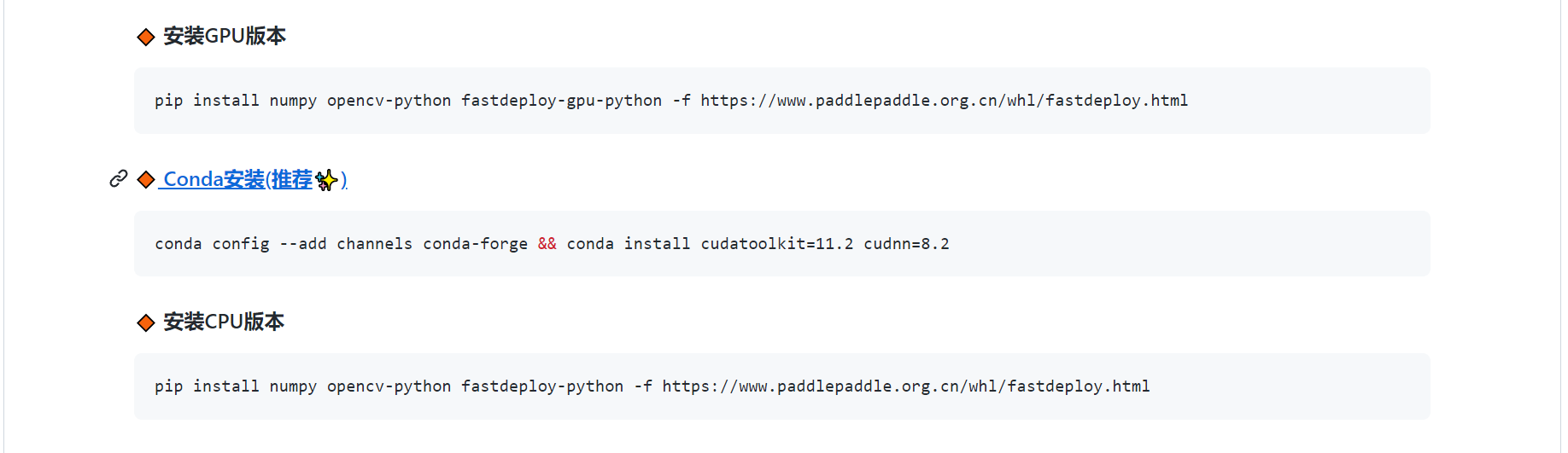
FastDeploy官方文档地址:🔗 安装 安装GPU版本 pip install numpy opencv-python fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.htmlConda安装(推荐✨) conda config --add channels conda-forge && conda install cudatoolkit=11.2 cudnn=8.2安装CPU版本 pip install numpy opencv-python fastdeploy-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
核心代码 在下方代码中可以发现.pdiparams和.pdmodel在模型导出步骤中已经生成,但事实.yml文件并没有生成,此时我们可能会猜测此yml文件可能为训练时的模型文件(ppcls/configs/ImageNet/EfficientNet/EfficientNetB4.yaml),但是事实并不是这样。官方说明🔗 这里我为大家提供了修改好的yml文件 网盘 import cv2 import fastdeploy.vision as vision im = cv2.imread("img_3.png") # 读取图片 # 加载模型 model = vision.classification.EfficientNet(model_file="modd/inference.pdmodel", params_file="modd/inference.pdiparams", config_file="modd/inference.yml") # 预测 result = model.predict(im) print(result)结果:
部分代码 完整代码需要自取 class admi_window(QtWidgets.QMainWindow, Ui_MainWindow): def __init__(self): super(admi_window, self).__init__() self.setupUi(self) # 创建窗体对象 self.tulu = None def openImage(self): # 选择本地图片上传 imgName, imgType = QFileDialog.getOpenFileName() print('图片路径:', imgName) pix = QPixmap(str(imgName)) self.label.setPixmap(pix) self.label.setScaledContents(True) self.tulu = imgName def pri(self): if self.tulu == None: msg_box = QMessageBox(QMessageBox.Critical, '请先选择图片', '请先选择图片') msg_box.exec_() else: im = cv2.imread(self.tulu) result = model.predict(im) lab = str(result).split('(')[1].split(')')[0].split(', \n')[0].split(': ')[1] sco = str(result).split('(')[1].split(')')[0].split(', \n')[1].split(': ')[1] self.textEdit.setText(f"症状:{labil[int(lab)]}\n可信率:{sco}") print(result) if __name__ == '__main__': # 加载模型 model = vision.classification.EfficientNet(model_file="modd/inference.pdmodel", params_file="modd/inference.pdiparams", config_file="modd/inference.yml") app = QApplication(sys.argv) window = admi_window() window.show() sys.exit(app.exec_())效果: 参考 基于PP-PicoDet行车检测(完成安卓端部署) 九、项目总结 通过这次项目,仔细研究了EfficientNet的网络结构总结如下: 1、网络深度的增加,典型的如resnet,就是通过残差网络的堆叠,增加网络层数,以此来提升精度。 2、网络宽度的增加,通过增加每层网络的特征层数,提取更多的特征,以此来提升精度。 3、图像分辨率的增加,分辨率越高的图像,所能获取的信息越多,网络能够学习到更多的特征,从而提升精度。 4、EfficientNet特点:历史的实验经验表明,对于卷积神经网络的提升,着重点在于网络深度,网络宽度,分辨率这三个维度。因此,efficientnet应运而生,efficientnet结合了这三个优点,很好的平衡深度、宽度和分辨率这三个维度,通过一组固定的缩放系数统一缩放这三个维度。 参考基于飞桨的农作物病害智能识别系统 此文章为转载 原项目链接 |









【本文地址】
今日新闻 |
推荐新闻 |