数据库索引原理及优化 |
您所在的位置:网站首页 › 检索算法有哪些 › 数据库索引原理及优化 |
数据库索引原理及优化
|
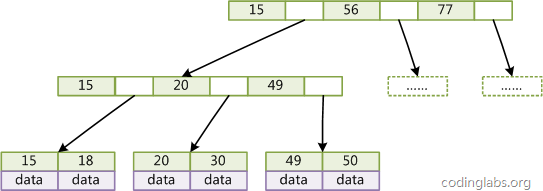
我们知道,数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。那么有哪些查询算法可以使查询速度变得更快呢? 顺序查找(linear search )最基本的查询算法当然是顺序查找(linear search),也就是对比每个元素的方法,不过这种算法在数据量很大时效率是极低的。 数据结构:有序或无序队列 复杂度:O(n) 实例代码: //顺序查找 int SequenceSearch(int a[], int value, int n) { int i; for(i=0; ivalue) return BinarySearch2(a, value, low, mid-1); if(a[mid] key) return BTree_Search(point[i]->node); } return BTree_Search(point[i+1]->node); } data = BTree_Search(root, my_key);关于B-Tree有一系列有趣的性质,例如一个度为d的B-Tree,设其索引N个key,则其树高h的上限为logd((N+1)/2),检索一个key,其查找节点个数的渐进复杂度为O(logdN)。从这点可以看出,B-Tree是一个非常有效率的索引数据结构。 另外,由于插入删除新的数据记录会破坏B-Tree的性质,因此在插入删除时,需要对树进行一个分裂、合并、转移等操作以保持B-Tree性质,本文不打算完整讨论B-Tree这些内容,因为已经有许多资料详细说明了B-Tree的数学性质及插入删除算法,有兴趣的朋友可以查阅其它文献进行详细研究。 2.3.2 B+Tree其实B-Tree有许多变种,其中最常见的是B+Tree,比如MySQL就普遍使用B+Tree实现其索引结构。B-Tree相比,B+Tree有以下不同点: 每个节点的指针上限为2d而不是2d+1; 内节点不存储data,只存储key; 叶子节点不存储指针;下面是一个简单的B+Tree示意。
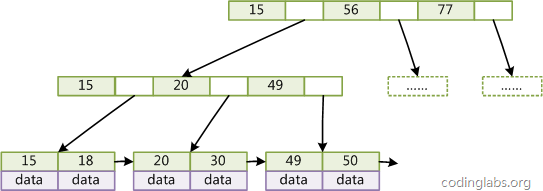
由于并不是所有节点都具有相同的域,因此B+Tree中叶节点和内节点一般大小不同。这点与B-Tree不同,虽然B-Tree中不同节点存放的key和指针可能数量不一致,但是每个节点的域和上限是一致的,所以在实现中B-Tree往往对每个节点申请同等大小的空间。一般来说,B+Tree比B-Tree更适合实现外存储索引结构,具体原因与外存储器原理及计算机存取原理有关,将在下面讨论。 2.3.3 带有顺序访问指针的B+Tree一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上进行了优化,增加了顺序访问指针。
如图所示,在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能,例如图4中如果要查询key为从18到49的所有数据记录,当找到18后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率。 这一节对B-Tree和B+Tree进行了一个简单的介绍,下一节结合存储器存取原理介绍为什么目前B+Tree是数据库系统实现索引的首选数据结构。
原文链接:https://www.cnblogs.com/wuchanming/p/6886020.html
相关文章: 常见的查询算法及数据结构 索引数据结构设相关的计算机原理 数据库索引所采用的数据结构B-/+Tree及其性能分析 MySQL索引实现 索引使用策略及优化 |
【本文地址】
今日新闻 |
推荐新闻 |