机器学习 |
您所在的位置:网站首页 › 树状图属于什么模型 › 机器学习 |
机器学习
|
一、决策树原理
决策树(Decision Tree)是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题。决策树算法容易理解,适用各种数据,在解决各种问题时都有良好表现,尤其是以树模型为核心的各种集成算法,在各个行业和领域都有广泛的应用。 我们来简单了解一下决策树是如何工作的。决策树算法的本质是一种图结构,我们只需要问一系列问题就可以对数据进行分类了。比如说,来看看下面这组数据集,这是一系列已知物种以及所属类别的数据:
根据已经收集到的数据,决策树算法为我们算出了下面的这棵决策树:
根据以上的决策树规则,当我们发现一个新的物种,我们就可以根据决策树判断它所属的类别。 根节点:没有进边,有出边。包含最初的,针对特征的提问。中间节点(内部节点):既有进边也有出边,进边只有一条,出边可以有很多条。都是针对特征的提问。叶子节点:有进边,没有出边,每个叶子节点都是一个类别标签。子节点和父节点:在两个相连的节点中,更接近根节点的是父节点,另一个是子节点。 二、构建决策树任意一个数据集上的所有特征都可以被拿来分枝,每个特征上的任意值都可以当成一个节点自由组合(例如身高可以分为=1.8米,也可以分为=1米,等等),所以一个数据集上可以发展出非常非常多棵决策树,其数量可达指数级。在这些树中,总有那么一棵树比其他的树分类效果都好,那样的树叫做”全局最优树“。 全局最优:经过组合形成的,整体来说分类效果最好的模型局部最优:每一次分枝的时候都向着更好的分类效果分枝,但无法确认如此生成的树在全局上是否是最优的。 决策树算法的核心是要解决两个问题: 1)如何从数据表中找出最佳节点和最佳分枝? 2)如何让决策树停止生长,防止过拟合? 一个数据集可以发展的决策树数量是指数级别的,在这么多的决策树当中挑选出一颗“全局最优树”,是非常低效的,于是我们牺牲掉小部分的准确率,用逐步的“局部最优”来达到最接近“全局最优”的结果,这类算法我们统称为“贪心算法”。 贪心算法:通过实现局部最优来达到接近全局最优结果的算法,所有的树模型都是这样的算法。 最典型的决策树算法是Hunt算法,该算法是由Hunt等人提出的最早的决策树算法。现代,Hunt算法是许多决策树算法的基础,包括ID3、C4.5和CART等。Hunt算法诞生时间较早,且基础理论并非特别完善,此处以应用较广、理论基础较为完善的ID3算法的基本原理开始,讨论如何利用局部最优化方法来创建决策模型。 ID3算法原型见于J.R Quinlan的博士论文,是基础理论较为完善,使用较为广泛的决策树模型,在此基础上J.R Quinlan进行优化后,陆续推出了C4.5和C5.0决策树算法,后二者现已称为当前最流行的决策树算法,我们先从ID3 开始讲起,再讨论如何从ID3逐渐优化至C4.5。 为了要将数据集转化为一棵树,决策树需要找出最佳节点和最佳的分枝方法,而衡量这个“最佳”的指标叫做“不纯度”。 不纯度基于叶子节点来计算的,所以树中的每个节点都会有一个不纯度,并且子节点的不纯度一定是低于父节点的, 也就是说,在同一棵决策树上,叶子节点的不纯度一定是最低的。 不纯度:决策树的每个叶子节点中都会包含一组数据,在这组数据中,如果有某一类标签占有较大的比例,我们就说叶子节点“纯”,分枝分得好。某一类标签占的比例越大,叶子就越纯,不纯度就越低,分枝就越好。 如果没有哪一类标签的比例很大,各类标签都相对平均,则说叶子节点”不纯“,分枝不好,不纯度高。
如上图右边的分类树,分类型决策树在叶子节点上的决策规则是少数服从多数,在一个叶子节点上,如果某一类标签所占的比例较大,那所有进入这个叶子节点的样本都会被认为是这一类别(5个样本当中,标签1为2个,标签0为3个,则预测该节点上所有的样本都为标签0)。 如果叶子本身不纯,那测试样本就很有可能被判断错误,相对的叶子越纯,那样本被判断错误的可能性就越小,决策树对训练集的拟合越好。 如下图,(a)的不纯度最高,(c)的不纯度最低。
不管不纯度的度量方法如何,都是由误差率衍生而来,其计算公式如下:
信息熵,又叫做香农熵,其计算公式如下:
其中
案例1:假设在二分类问题中各节点呈现如下分布,则可进一步计算上述三指数的结果
能够看出,三种方法本质上都相同,在类分布均衡时(即当p=0.5时)达到最大值,而当所有记录都属于同一个类时(p等于1或0)达到最小值。换而言之,在纯度较高时三个指数均较低,而当纯度较低时,三个指数都比较大,且可以计算得出,熵在0-1区间内分布,而Gini指数和分类误差率均在0-0.5区间内分布,三个指数随某变量占比增加而变化的曲线如下所示:
ID3采用信息熵来衡量不纯度,ID3最优条件是叶节点的总信息熵最小,因此ID3决策树在决定是否对某节点进行切分的时候,会尽可能选取使得该节点对应的子节点信息熵最小的特征进行切分。换而言之,就是要求父节点信息熵和子节点总信息熵之差要最大。对于ID3而言,二者之差就是信息增益。 一个父节点下可能有多个子节点,而每个子节点又有自己的信息熵,所以父节点信息熵和子节点信息熵之差,应该是(父节点的信息熵 )- (所有子节点信息熵的加权平均)。其中,权重=(单个叶子节点上的样本量)/(父节点上的总样本量)。 父节点和子节点的不纯度下降数可由下述公式进行计算: 其中
其中, 案例2 有如下数据集,是一个消费者个人属性和信用评分数据,标签是”是否会发生购买电脑行为“,是一个典型的二分类问题,在此数据集之上我们使用ID3构建决策树模型,并提取有效的分类规则。
(1)由原始数据集计算总的信息熵(Entropy),即根节点的信息熵,标签为二分类,(class='yes'):(class='no')=9:5。 根据公式 (2)对原始数据集按照age进行划分
(3)计算子节点的信息熵的加权平均值 对于age |




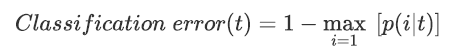
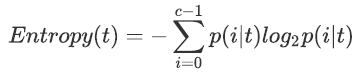
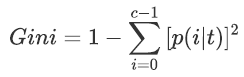


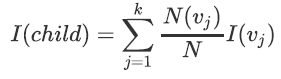


【本文地址】
今日新闻 |
推荐新闻 |