决策树原理详解(无基础的同样可以看懂) |
您所在的位置:网站首页 › 树上有几个人脸怎么画的 › 决策树原理详解(无基础的同样可以看懂) |
决策树原理详解(无基础的同样可以看懂)
|
一. 决策树简介
决策树(Decision Tree),它是一种以树形数据结构来展示决策规则和分类结果的模型,作为一种归纳学习算法,其重点是将看似无序、杂乱的已知数据,通过某种技术手段将它们转化成可以预测未知数据的树状模型,每一条从根结点(对最终分类结果贡献最大的属性)到叶子结点(最终分类结果)的路径都代表一条决策的规则。决策树就是形如下图的结构(机器学习西瓜书的图): 话不多说,先看图 在介绍决策树流程的时候提到了,寻找最优划分属性是决策树过程中的重点。那么如何在众多的属性中选择最优的呢。 3.1 信息增益在介绍信息增益之前,先介绍一下信息熵的含义。我们理科生都学过化学,热力学里有一个熵的概念,熵就是来形容系统混乱程度的,系统越混乱,熵就越大。信息熵也具有同样的意义,不过它描述的是随机变量的不确定性(也就是混乱程度)。 假设某随机变量的概率分布为: 信息增益虽然在理论上可以找到最优的划分属性,但在某些情况下会存在问题。信息增益比较偏好可取值较多的属性,比如我们的样本有一个属性叫序号,每一个样本都具有一个单独的序号,因此使用序号划分后,每个子结点只有一个样本,熵为0。这样的话信息增益最大,算法就会以此属性作为最优划分属性。这显然与我们的意愿不同。因此引申出了增益比的思想。 可以这么说,增益比就是为了矫正信息增益偏好的问题。为了使算法不偏向可取值较多的属性。 基尼指数也是一个寻找最优划分属性的准则。公式如下:  这是ID3和C4.5可以生成的决策树,比如根节点根据属性(纹理)划分成了3个子结点。如果是CART决策树,它只能生成2个子结点,结果可能就是将红圈圈起的部分合并称为一个节点。你可能会问这样纹理模糊和稍糊的不就分不开了么,不用担心,如果分开效果更好的话,在该节点继续划分的时候就会将纹理的两个取值分开。因为同一个属性可以不只使用一次。
3.4 小结(1) 这是ID3和C4.5可以生成的决策树,比如根节点根据属性(纹理)划分成了3个子结点。如果是CART决策树,它只能生成2个子结点,结果可能就是将红圈圈起的部分合并称为一个节点。你可能会问这样纹理模糊和稍糊的不就分不开了么,不用担心,如果分开效果更好的话,在该节点继续划分的时候就会将纹理的两个取值分开。因为同一个属性可以不只使用一次。
3.4 小结(1)
到这里我们的划分选择的几种方法就讲完了。我们可以看出,对于每种决策树算法,他们的基本流程是一样的。不同的是,虽然决策树基本流程中的每一步骤的目的一样,但不同算法实现的方式不同。 四. 剪枝处理如果按照我们之前的方法形成决策树后,会存在一定的问题。决策树会无休止的生长,直到训练样本中所有样本都被划分到正确的分类。实际上训练样本中含有异常点,当决策树节点样本越少的时候,异常点就可能使得该结点划分错误。另外,我们的样本属性并不一定能完全代表分类的标准,可能有漏掉的特征,也可能有不准确的特征。这样就会导致决策树在训练集上准确率超高,但是在测试集上效果不好,模型过拟合,泛化能力弱。因此我们需要适当控制决策树的生长。 剪枝处理是防止决策树过拟合的有效手段。剪枝,其实就是把决策树里不该生长的枝叶剪掉,也就是不该划分的节点就不要继续划分了。剪枝分为“预剪枝”和“后剪枝”。两种操作在决策树生辰步骤的位置如下图: 我们之前使用的例子都是离散型数据,比如纹理(清晰,稍糊,模糊),色泽(青绿,乌黑,浅白),触感(硬滑,软粘),实际上我们的数据还有可能是连续值,比如西瓜的含糖率是0-1之间的连续值。这种情况下,属性的可取值无穷多,就无法直接划分节点,需要先将连续值离散化。 我们这里讲一下最简单的二分法策略对连续值进行处理,C4.5算法就是使用的这个方法,其他的算法等找到资料后我再补充到这里。 定义如下: 给定样本集D和连续属性a,假定a在D上出现了n个不同的取值,将这些值从小到大进行排序,记为{a1,a2,…,an}。基于划分点t可将D分为子集Dt-和Dt+,其中Dt-包含那些在属性a上取值不大于t的样本,而Dt+包含那些在属性a上取值大于t的样本。显然,对相邻的属性取值ai和ai+1来说,t在区间[ai,ai+1]中取任意值所产生的划分结果相同,我们就把区间[ai,ai+1]的中位点作为候选划分点好了。 **【注意】**这里我们要注意一下,对于连续值的属性来说,离散化后再进行划分选择的过程不同。 离散化后,当选择最优划分属性时,对于该属性,并不是划分为候选点数量的子节点,而是选择其中一个候选点,将样本集D二分,小于候选点的分为一类,记为D-,另一类记为D+,然后计算信息增益。循环所有候选点后,选择信息增益最大的候选点来与其他属性带来的信息增益对比,如果该候选点带来的信息增益最大,就将该候选点所在属性作为最优划分属性,并以该候选点将原节点分为2个子节点。 **【注意】**另一个值得注意的是,对于连续值离散化的属性,在进行决策树生成的过程中可能不止使用1次。以下图为例 由于各种原因,我们得到的数据经常含有缺失值。当然如果一条样本缺失值太多,我们可以直接舍弃。但对于只缺失少量数据的样本,我们丢弃就有些可惜,尤其是对于不方便收集的数据样本。我们谈一下决策树算法中对于缺失值怎么处理的。 这里还是要放上公式(显得专业一些)。千万不要被这复杂的公式吓到,实际上意义超级简单。 考虑到缺失值后,我们需要解决的有两个问题: 1. 信息增益怎么算,最优划分属性怎么着。 信息增益的计算公式如下: 至此,如何解决连续值和缺失值的方法就讲完了。 六. 决策树回归我们都知道决策树不仅可以处理分类问题,也可以处理回归问题。这里我们就简单介绍一下回归问题的解决办法。 我们先看一下决策树回归的流程,与分类问题类似。 可以看出,决策树回归的重点就在两个地方: 重点1:寻找最优切分点; 重点2:将样本切分后,子节点的输出值怎么算。 重点1: 回归决策树是通过最小二乘法来寻找最优切分点(j,s)的。定义了如下目标函数: 重点2 当找到最优切分点(j,s)后,将样本切分为左右两个子节点。子节点的输出值为该节点内的所有样本y的均值。 我们既讲了决策树的原理,中间又穿插了几个算法的名字,这里我把算法名字和原理之间的关系做一个小小的总结。 相信大家基本都是使用sklearn工具包里的决策树算法,这里简单说几句调用的方法和参数的意义,哪都能查得到,摆在这省的大家再去别的地方再搜了。 调用算法代码: from sklearn.tree import DecisionTreeClassifier #导入分类模型 from sklearn.tree import DecisionTreeRegressor #导入回归模型 model_c = DecisionTreeClassifier(max_depth=10,max_features=5) #括号内加入要人工设定的参数 model_r = DecisionTreeRegressor(max_depth=10,max_features=5) #同样的,加入参数设定值,不仅局限于这几个 model_c.fit(x_train,y_train) #训练分类模型 model_r.fit(x_train,y_train) #训练回归模型 result_c = model_c.predict(x_test) #使用模型预测分类结果 result_r = model_r.predict(x_test) #使用模型预测回归结果模型可添加的更多的参数及解释如下: criterion:字符型,可选,规定了该决策树所采用的的最佳分割属性的判决方法,有两种:“gini”,“entropy”,默认为’gini’, splitter: 字符型,可选(默认=“best”)用于在每个节点选择分割的策略,可填‘best’或’random’,前者在特征的所有划分点中找出最优的划分点。后者是随机的在部分划分点中找局部最优的划分点。默认的"best"适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐"random" max_depth: int型或None,可选(默认=None)树的最大深度,对于防止过拟合非常有用。如果不输入的话,决策树在建立子树的时候不会限制子树的深度。一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。 min_samples_split: int型float型,可选(默认值=2)分割内部节点所需的最小样本数量;如果是int型,则min_samples_split为最小样本数量。如果是float型,则min_samples_split是分数,ceil(min_samples_split * n_samples)是每个分割的最小样本数。 min_samples_leaf: int型float型,可选(默认值=1)叶节点上所需的最小样本数。如果是int类型,则将min_samples_leaf作为最小值。若是float,那么min_samples_leaf是分数,ceil(min_samples_leaf * n_samples)是每个节点的最小样本数。 min_weight_fraction_leaf:浮点型,可选(默认=0)。叶节点上(所有输入样本的)权值之和的最小加权分数。当没有提供sample_weight时,样品的重量相等。 max_features: int, float, string or None, 可选(默认=None),在寻找最佳分割时需要考虑的特性数量;如果是int类型,则考虑每个分割处的max_features特性。如果是float,那么max_features是一个分数,并且在每个分割中都考虑int(max_features * n_features)特性。如果“auto”,则max_features=sqrt(n_features)。如果“sqrt”,则max_features=sqrt(n_features)。如果“log2”,则max_features=log2(n_features)。如果没有,则max_features=n_features。 class_weight: 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多,导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,或者用“balanced”,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。当然,如果你的样本类别分布没有明显的偏倚,则可以不管这个参数,选择默认的"None" random_state: int型RandomState实例或None,可选(默认=None)如果是int, random_state是随机数生成器使用的种子;如果是RandomState实例,random_state是随机数生成器;如果没有,随机数生成器是np.random使用的RandomState实例。 |

 上图就是在生成决策树的过程中经历的步骤。
上图就是在生成决策树的过程中经历的步骤。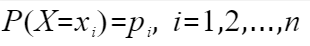 则它的信息熵计算公式为:
则它的信息熵计算公式为: 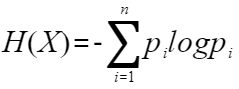 突然冒出这么一个公式你可能不适应。您可以这么理解:第一,这是大师们写出来的,肯定有道理;第二,它的值确实可以体现出随机变量的不确定性,且与我们理解的一致。 为了方便解释,我们用一个简单的便于观察的例子。下图是一个只有2个取值的随机变量,假如取值只有0和1,则P(X=0)=p,P(X=1)=1-p,其中p是x=0的概率。信息熵为H§=-plogp-(1-p)log(1-p),我们画一个p在0-1的变过过程,H§随着变化的曲线:
突然冒出这么一个公式你可能不适应。您可以这么理解:第一,这是大师们写出来的,肯定有道理;第二,它的值确实可以体现出随机变量的不确定性,且与我们理解的一致。 为了方便解释,我们用一个简单的便于观察的例子。下图是一个只有2个取值的随机变量,假如取值只有0和1,则P(X=0)=p,P(X=1)=1-p,其中p是x=0的概率。信息熵为H§=-plogp-(1-p)log(1-p),我们画一个p在0-1的变过过程,H§随着变化的曲线:  由上图可以看出,当p=0.5的时候,H§达到最大值。因为p=0或p=1的时候,X只有一种可能性,也就是X是确定的,因此熵最小,而随着p接近0.5的过程中,变量X的不确定性就越来越大,我们计算出来的熵也是越来越大,与实际相符。 好了,信息熵的概念了解了,我们再与决策树的场景联系起来。我们先对样本大概的定义一下。就借鉴机器学习课本里的例子,样本属性有纹理、触感、色泽,其中每个属性有若干个可取值,比如纹理(清晰,稍糊,模糊),色泽(青绿,乌黑,浅白),触感(硬滑,软粘)。样本分类有两种,好瓜和坏瓜。 假如决策树样本集为D,经过某属性划分后,样本集划分v个子集,D1,D2,…,Dv。 我们先计算划分前D的信息熵(有的地方用Ent(D),有的用H(D),只是一个代表信息熵的符号,如果使用不严谨,请见谅):
由上图可以看出,当p=0.5的时候,H§达到最大值。因为p=0或p=1的时候,X只有一种可能性,也就是X是确定的,因此熵最小,而随着p接近0.5的过程中,变量X的不确定性就越来越大,我们计算出来的熵也是越来越大,与实际相符。 好了,信息熵的概念了解了,我们再与决策树的场景联系起来。我们先对样本大概的定义一下。就借鉴机器学习课本里的例子,样本属性有纹理、触感、色泽,其中每个属性有若干个可取值,比如纹理(清晰,稍糊,模糊),色泽(青绿,乌黑,浅白),触感(硬滑,软粘)。样本分类有两种,好瓜和坏瓜。 假如决策树样本集为D,经过某属性划分后,样本集划分v个子集,D1,D2,…,Dv。 我们先计算划分前D的信息熵(有的地方用Ent(D),有的用H(D),只是一个代表信息熵的符号,如果使用不严谨,请见谅): 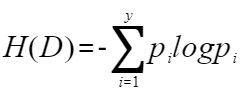 这里y=2,因为只有好瓜和坏瓜两种分类。pi表示第i类别的样本数占总样本数D的比例。 然后我们计算划分后的子样本集的信息熵
这里y=2,因为只有好瓜和坏瓜两种分类。pi表示第i类别的样本数占总样本数D的比例。 然后我们计算划分后的子样本集的信息熵 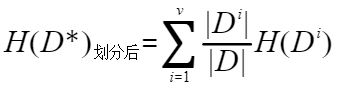 其中v是该属性的可取值的数量,比如划分属性为色泽,则v=3。Di表示该属性第i个值的样本数。相当于用色泽划分样本集D,样本集D中色泽=青绿的样本数。|Di|/|D|可以想象成一个权重。H(Di)的计算方法同计算H(D)的。 终于到了该介绍的概念:信息增益
其中v是该属性的可取值的数量,比如划分属性为色泽,则v=3。Di表示该属性第i个值的样本数。相当于用色泽划分样本集D,样本集D中色泽=青绿的样本数。|Di|/|D|可以想象成一个权重。H(Di)的计算方法同计算H(D)的。 终于到了该介绍的概念:信息增益 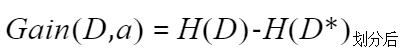 很简单,就是划分前的信息熵减去划分后的信息熵。其中a代表的此次划分中所使用的属性。 如果决策树使用信息增益准则来选择最优划分属性的话,在划分前会针对每个属性都计算信息增益,选择能使得信息增益最大的属性作为最优划分属性。ID3算法就是使用的信息增益划分方法,决策树是一个基础理论,实际落地的算法有多种,ID3是其中一种。
很简单,就是划分前的信息熵减去划分后的信息熵。其中a代表的此次划分中所使用的属性。 如果决策树使用信息增益准则来选择最优划分属性的话,在划分前会针对每个属性都计算信息增益,选择能使得信息增益最大的属性作为最优划分属性。ID3算法就是使用的信息增益划分方法,决策树是一个基础理论,实际落地的算法有多种,ID3是其中一种。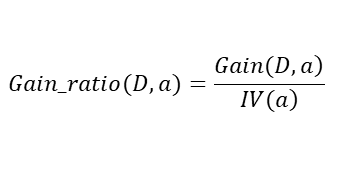 其中
其中 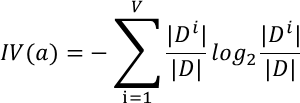 可以看出,增益比就是信息增益除以IV(a),IV(a)是属性a的固有属性,当属性a可取值增多的时候,IV(a)一般也增大,因此在一定程度上能抑制信息增益偏好取值多的属性的特点,但是增益比偏好取值较少的属性。 算法C4.5是算法ID3的改进版,它使用了信息增益和增益比两种选择算法,先选出信息增益高于平均水平的属性,然后再在这些属性中选择增益比最高的,作为最优划分属性。这样综合了信息增益和增益比的优点,可以取得较好的效果。
可以看出,增益比就是信息增益除以IV(a),IV(a)是属性a的固有属性,当属性a可取值增多的时候,IV(a)一般也增大,因此在一定程度上能抑制信息增益偏好取值多的属性的特点,但是增益比偏好取值较少的属性。 算法C4.5是算法ID3的改进版,它使用了信息增益和增益比两种选择算法,先选出信息增益高于平均水平的属性,然后再在这些属性中选择增益比最高的,作为最优划分属性。这样综合了信息增益和增益比的优点,可以取得较好的效果。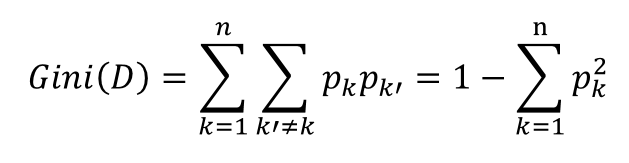 通俗的可以这么理解,基尼指数就是在样本集中随机抽出两个样本不同类别的概率。当样本集越不纯的时候,这个概率也就越大,即基尼指数也越大。这个规律与信息熵的相同,还是以刚才的只有两个取值的随机变量为例,我们这次纵坐标除了有信息熵外,再加上基尼指数。
通俗的可以这么理解,基尼指数就是在样本集中随机抽出两个样本不同类别的概率。当样本集越不纯的时候,这个概率也就越大,即基尼指数也越大。这个规律与信息熵的相同,还是以刚才的只有两个取值的随机变量为例,我们这次纵坐标除了有信息熵外,再加上基尼指数。  可以看出,基尼指数与信息熵虽然值不同,但是趋势一致。同样的,使用基尼指数来选择最优划分属性也是对比不同属性划分后基尼指数的差值,选择使样本集基尼指数减小最多的属性。
可以看出,基尼指数与信息熵虽然值不同,但是趋势一致。同样的,使用基尼指数来选择最优划分属性也是对比不同属性划分后基尼指数的差值,选择使样本集基尼指数减小最多的属性。 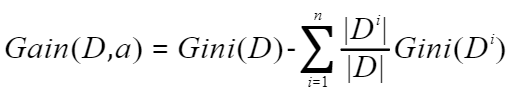 和信息增益计算方式类似,就是使用划分前样本集D的基尼指数减去划分后子样本集Di的基尼指数加权和。 著名的CART决策树就是使用基尼指数来作为划分准则。谈到这,顺便提一下CART决策树与ID3和C4.5的区别。
和信息增益计算方式类似,就是使用划分前样本集D的基尼指数减去划分后子样本集Di的基尼指数加权和。 著名的CART决策树就是使用基尼指数来作为划分准则。谈到这,顺便提一下CART决策树与ID3和C4.5的区别。 预剪枝:在决策树生成过程中,对每个结点在划分前先进性估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。它的位置在每一次生成分支节点前,先判断有没有必要生成,如没有必要,则停止划分。 后剪枝:先从训练集生成一棵完整的决策树(相当于结束位置),然后自底向上的对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点,相当于将子树剪去。值得注意的是,后剪枝时要用到一个测试数据集合,如果存在某个叶子剪去后能使得在测试集上的准确度或其他测度不降低(不变得更坏),则剪去该叶子。 理论上讲,后剪枝生成的决策树要比预剪枝生成的效果好,但是后剪枝在计算复杂度上比预剪枝高。
预剪枝:在决策树生成过程中,对每个结点在划分前先进性估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。它的位置在每一次生成分支节点前,先判断有没有必要生成,如没有必要,则停止划分。 后剪枝:先从训练集生成一棵完整的决策树(相当于结束位置),然后自底向上的对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点,相当于将子树剪去。值得注意的是,后剪枝时要用到一个测试数据集合,如果存在某个叶子剪去后能使得在测试集上的准确度或其他测度不降低(不变得更坏),则剪去该叶子。 理论上讲,后剪枝生成的决策树要比预剪枝生成的效果好,但是后剪枝在计算复杂度上比预剪枝高。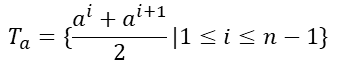 这样我们就得到了n-1个候选划分点。 定义看着如此麻烦,其实很简单,比如属性a的取值为{1.2, 2, 4,6, 7.0},我们选择两两值取中位数,就得到{(1.2+2)/2, (2+4.6)/2, (4.6+7.0)/2}三个候选点。(对于很多人来说我写的是啰嗦了点,我刚刚入门时看到定义就发蒙,可能会有和我一样的同志)
这样我们就得到了n-1个候选划分点。 定义看着如此麻烦,其实很简单,比如属性a的取值为{1.2, 2, 4,6, 7.0},我们选择两两值取中位数,就得到{(1.2+2)/2, (2+4.6)/2, (4.6+7.0)/2}三个候选点。(对于很多人来说我写的是啰嗦了点,我刚刚入门时看到定义就发蒙,可能会有和我一样的同志)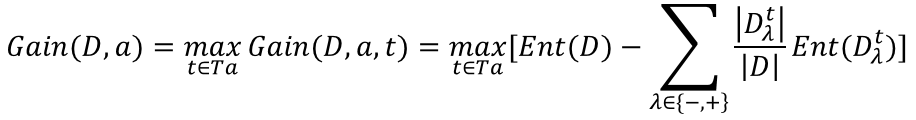 上图是对于离散化后的属性计算信息增益的公式,最右侧的求和就是使用某个候选点将样本集2分后的加权信息熵。
上图是对于离散化后的属性计算信息增益的公式,最右侧的求和就是使用某个候选点将样本集2分后的加权信息熵。 密度和含糖率都是连续属性,他们都被使用了两次。
密度和含糖率都是连续属性,他们都被使用了两次。 有些符号在这里打不出来,我就把文字也截图了。 对属性a,ρ表示无缺失值的样本所占的比例,𝑝k表示无缺失值样本中第k类所占的比例,𝑟𝑣表示无缺失值样本中在属性a上取值为av的样本所占的比例。
有些符号在这里打不出来,我就把文字也截图了。 对属性a,ρ表示无缺失值的样本所占的比例,𝑝k表示无缺失值样本中第k类所占的比例,𝑟𝑣表示无缺失值样本中在属性a上取值为av的样本所占的比例。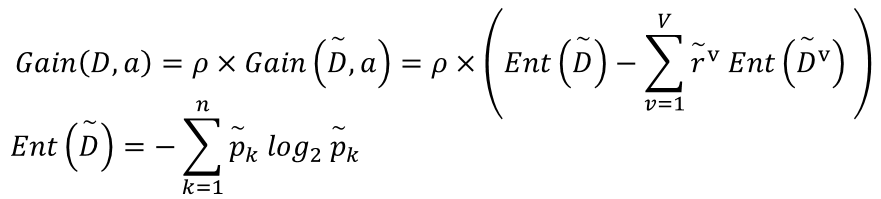 相当于将没有缺失值样本单独拿出来,对这些无缺失值的样本集进行划分,求出信息增益,再乘以无缺失值的样本数占总样本的比例ρ。当样本中无缺失值的时候,ρ=1,这个公式就等价于我们之前讲的信息增益的计算公式。 2. 对于含有缺失值的样本,怎么划分到子节点 (1)样本在该属性上取值已知,则正常分入其取值对应的节点 (2)样本在该属性上取值未知,样本同时划分到所有节点,调整样本在每个节点的权重为𝑟𝑣∗𝑤𝑥。相当于对于不同节点,样本乘上了不同的权重rv(详见上公式)
相当于将没有缺失值样本单独拿出来,对这些无缺失值的样本集进行划分,求出信息增益,再乘以无缺失值的样本数占总样本的比例ρ。当样本中无缺失值的时候,ρ=1,这个公式就等价于我们之前讲的信息增益的计算公式。 2. 对于含有缺失值的样本,怎么划分到子节点 (1)样本在该属性上取值已知,则正常分入其取值对应的节点 (2)样本在该属性上取值未知,样本同时划分到所有节点,调整样本在每个节点的权重为𝑟𝑣∗𝑤𝑥。相当于对于不同节点,样本乘上了不同的权重rv(详见上公式) 在讲流程之前,先说一个前提:决策树回归就是指CART决策树回归,因此形成的数同样是严格的二叉树形式。
在讲流程之前,先说一个前提:决策树回归就是指CART决策树回归,因此形成的数同样是严格的二叉树形式。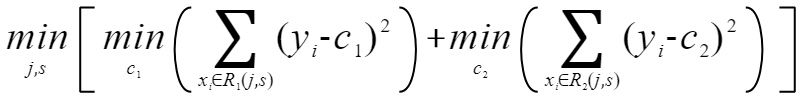 算法会遍历每个属性的每个值(j,s),就假如到属性j和值s的时候,会将样本集划分为2个子集(x=s),我们这里称这两个子集为R1和R2。 首先,我们要先寻找最优的C1使得R1的误差平方和最小,C2使得R2的误差平方和最小。这个数学上很容易证明,当C1和C2分别为子集R1和R2的y的均值的时候成立。上式也可以写成:
算法会遍历每个属性的每个值(j,s),就假如到属性j和值s的时候,会将样本集划分为2个子集(x=s),我们这里称这两个子集为R1和R2。 首先,我们要先寻找最优的C1使得R1的误差平方和最小,C2使得R2的误差平方和最小。这个数学上很容易证明,当C1和C2分别为子集R1和R2的y的均值的时候成立。上式也可以写成: 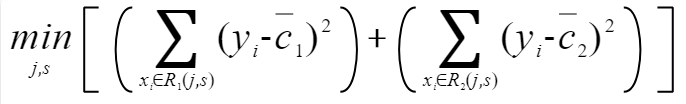 这样对于每一个(j,s),我们都会根据上式得到一个数值。然后我们取能使得上式取值最小的(j,s),作为最优切分点。
这样对于每一个(j,s),我们都会根据上式得到一个数值。然后我们取能使得上式取值最小的(j,s),作为最优切分点。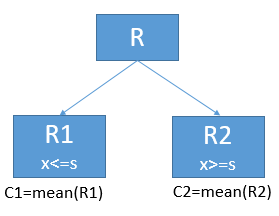 到这里决策树回归的原理就讲完了。
到这里决策树回归的原理就讲完了。 我们将的算法有ID3,C4.5和CART决策树三种。
我们将的算法有ID3,C4.5和CART决策树三种。【本文地址】
今日新闻 |
推荐新闻 |