SPSS12: 12.1.1 多重线性回归分析 |
您所在的位置:网站首页 › 标准化残差散点图 › SPSS12: 12.1.1 多重线性回归分析 |
SPSS12: 12.1.1 多重线性回归分析
|
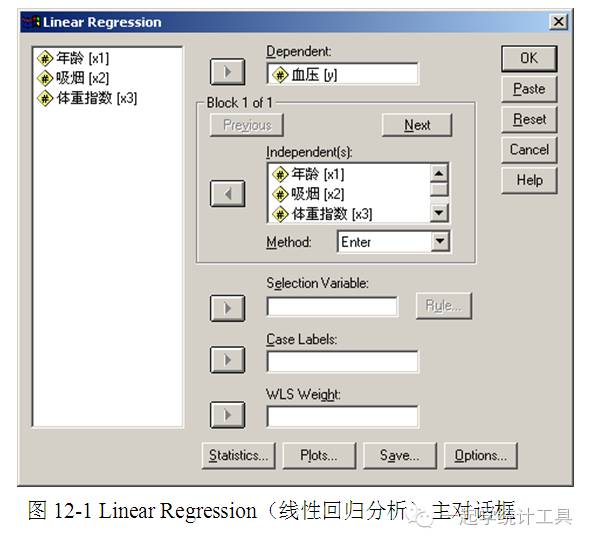
第12章 回归分析 回归分析(Regression)是研究一个或多个自变量(Independent)与一个因变量(Dependent)之间是否存在某种线性关系或非线性关系的一种统计学分析方法,包括线性回归分析(Linear Regression)、曲线参数估计法(Curve Estimation)、二值Logistic 回归分析(Binary Logistic Regression)、多项Logistic回归分析(Multinomial Logistic Regression)、有序回归分析(Ordinal Regression)、概率单位法(Probit,probabilityunit)、非线性回归分析(Nonlinear Regression)、权重估计法(Weight Estimation)、二阶段最小二乘回归分析(2-Stage Least Squares Regression)及分类回归分析(Categorical Regression)等。 12.1 线性回归分析 线性回归分析(Linear Regression)是基于最小二乘法(Least Square Method)原理产生古典统计假设下的最优线性无偏估计,是研究一个或多个自变量与一个因变量之间是否存在某种线性关系的统计学方法。如果引入回归分析的自变量只有一个,那么就是直线回归分析,所得方程就是直线回归方程。如果引入回归分析的自变量有两个以上,那么就是多重线性回归分析,所得方程就是多重线性回归方程,而直线回归分析是多重线性回归分析的特例。 产生的统计量及图形包括每个变量的有效例数、均数、标准差;每个模型的回归系数(regression coefficient)、相关系数矩阵(correlation matrix)、部分及偏相关系数(part and partial correlations)、复相关系数(multiple R)、决定系数(R2)、调整R2(adjusted R2)、R2改变量(change in R2)、估计值标准误(standard error of the estimate)、方差分析表(analysis-of-variance table)、预测值(predicted value)及残差(residual);回归系数的95%置信区间、方差—协方差矩阵(variance-covariance matrix)、方差膨胀因子(variance inflation factor)、容许度(tolerance)、Durbin-Watson检验(Durbin-Watson test)、距离测度(distance measure)、DfBeta值、DfFit值、预测区间(prediction interval)及个案诊断(casewise diagnostics);绘制散点图(scatter plot)、偏残差图(partial plot)、直方图(histogram)及正态概率图(normal probability plot)。 12.1.1 多重线性回归分析 SPSS的多重线性回归分析提供了5种建立回归方程的方法,包括强迫引入法(Enter)、逐步回归法(Stepwise)、强迫剔除法(Remove)、后向消去法(Backward Elimination)及前向逐步法(Forward Selection)。 〖例12-1〗为研究男性高血压患者血压与年龄、身高、体重等变量间的关系,随机测量了32名40岁以上男性的血压(mmHg)、年龄(岁)、身高(cm)、体重(kg)及吸烟史;其中吸烟(过去或现在吸烟)为1,而不吸烟为0。体重指数(Qutelet index)为100(体重/身高2)。见表12-1,试建立x1、x2、x3对y的多重线性回归方程并进行分析。 表12-1 32例40岁以上男性的体重指数、年龄、吸烟史与血压实测值 收缩压,y 年龄,x1 吸烟史,x2 体重指数,x3 收缩压,y 年龄,x1 吸烟史,x2 体重指数,x3 135 45 0 2.876 145 49 1 3.360 122 41 0 3.251 142 46 1 3.024 130 49 0 3.100 135 57 0 3.171 148 52 0 3.768 142 56 0 3.401 146 54 1 2.979 150 56 1 3.628 129 47 1 2.790 144 58 0 3.751 162 60 1 3.668 137 53 0 3.296 157 54 1 3.612 132 50 0 3.210 144 44 1 2.368 149 54 1 3.301 180 64 1 4.637 132 48 1 3.017 166 59 1 6.877 120 43 0 2.789 138 51 1 4.032 126 43 1 2.956 152 64 0 4.116 161 63 0 3.800 138 56 0 3.673 170 63 1 4.132 140 54 1 3.562 152 62 0 3.962 134 50 1 2.998 164 65 0 4.010 1)建立数据文件mreg2.sav,变量名为y(收缩压)、x1(年龄)、x2(吸烟史)、x3(体重指数)。 2)选择【Analyze】→【Regression】→【Linear...】,可打开Linear Regression(线性回归分析)主对话框,见到图12-1。 ☆Dependent(因变量)列表,可选择1个变量,本例为y(血压)。 ☆Independent(s)(自变量)列表,可选择1个或以上的自变量,本例为x1(年龄)、x2(吸烟史)、x3(体重指数)。 ☆Method(方法)下拉菜单,可指定自变量进入分析的方式。通过选择不同的方法,可对相同的变量建立不同的回归模型,建立多重回归的方法有5种。 Enter(强迫引入法),全部被选变量一次进入回归模型。 Stepwise(逐步回归法),在每一步中,将引入一个最小F概率(概率小于设定值)的变量引入回归方程。若已经引入回归方程的变量的F概率大于设定值,则将被剔除出回归方程。当无变量被引入或被剔除时,则终止回归过程。 Remove(强迫剔除法),将所有不进入方程模型的被选变量一次剔除。 Backward(后向消去法,Backward Elimination),一次性将所有变量引入方程,并依次进行剔除。首先剔除与因变量最小相关并符合剔除标准的变量,然后剔除第二个与因变量最小相关并符合剔除标准的变量,以此类推,当方程中的变量均不满足剔除标准时,则终止回归过程。 Forward(前向逐步法),被选变量依次进入回归模型,首先引入与因变量最大相关(正相关或负相关)并符合引入标准的变量,引入第一个变量后,然后引入第二个与因变量最大偏相关并符合引入标准的变量,以此类推,当无变量符合引入标准时,则终止回归过程。 注:结果中的P值是根据简单模型拟合计算的,因此逐步模型(Stepwise、Forward及Backward)的P值是无效的。 无论选择和哪种引入方法,进入方程的变量必须符合容许偏差,默认的容许偏差是0.0001。同样一个变量若使模型中变量的容许偏差低于默认的容许偏差,则不进入方程。
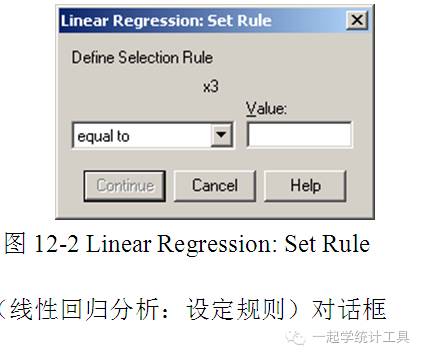
☆Selection Variable(选择变量),指定分析个案的选择规则。若要进行个案选择,可选择需进行Selection Variable(选择变量)的变量,然后单击【Rule...】,可打开Linear Regression: Set Rule(线性回归分析:设定规则)对话框,见图12-2。 Define Selection Rule(定义选择规则)的运算符的下拉菜单可选择equal to(等于)、not equal to(不等于)、less than(小于)、less than or equal to(小于或等于)、greater than(大于)、greater than or equal to(大于或等于)。
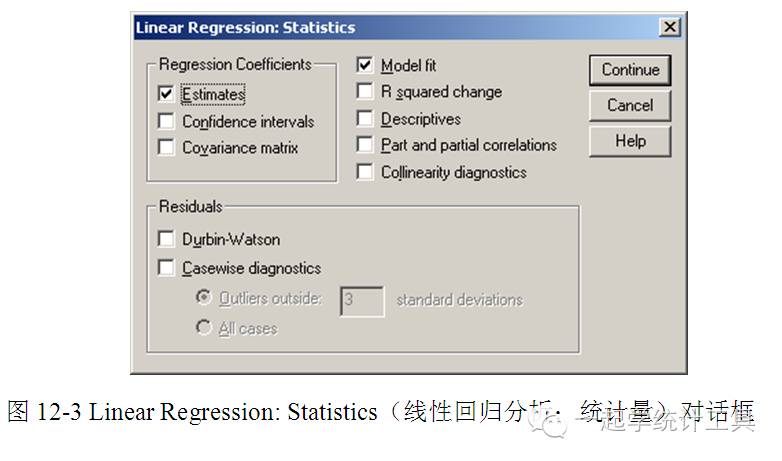
☆Case Labels(个案标识)变量,被选变量可在图形中标注点的值。 ☆WLS Weight(加权最小二乘法)变量,被选变量可用于加权最小二乘法分析。 3)单击【Statistics...】,可打开Linear Regression: Statistics(线性回归分析:统计量)对话框,见图12-3。 ☆Regression Coefficients(回归系数)。 □Estimates(估计值),显示回归系数B、回归系数的标准误(SEB)、标准化回归系数(Beta),回归系数B的t值及双侧显著性水平(Sig.)。 □Confidence intervals(置信区间),显示每个回归系数的 95% 置信区间或协方差矩阵。 □Covariance matrix(协方差矩阵),回归系数(B)的方差—协方差矩阵(Var-Covar Matrix of Regression Coefficients(B))。矩阵下三角元素(Below Diagonal)是协方差(Covariance),上三角元素(Above)是相关系数(Correlation),对角线元素是方差(Variance),同时显示相关系数矩阵。 □Model fit(模型拟合),显示被引入模型或被剔除的变量及拟合优度统计量,复相关系数R、R2、调整R2、估计值的标准误及方差分析表。 □R squared change(R2 改变量),增加或删除一个自变量所产生的R2改变量。R2改变量越大,表明该变量可能是一个较好的回归变量。 □Descriptives(描述性统计量),包括分析中每个变量的有效个案例数、平均数,含单侧显著性水平和例数的相关系数矩阵。 □Part and partial correlations(部分及偏相关系数),显示零阶、部分及偏相关系数。 □Collinearity diagnostics(共线性诊断),包括方差膨胀因子值、特征值、条件指数、单个变量的容许偏差。 ☆Residuals(残差统计量)。 □Durbin-Watson(Durbin-Watson检验统计量),同时显示标准化与非标准化残差与预测值的汇总统计量。 □Casewise diagnostics(个案诊断)。 ○Outliers outside n standard deviations(超出n倍标准差以上的个案为奇异值),默认为3。 ○All cases(所有的个案)。
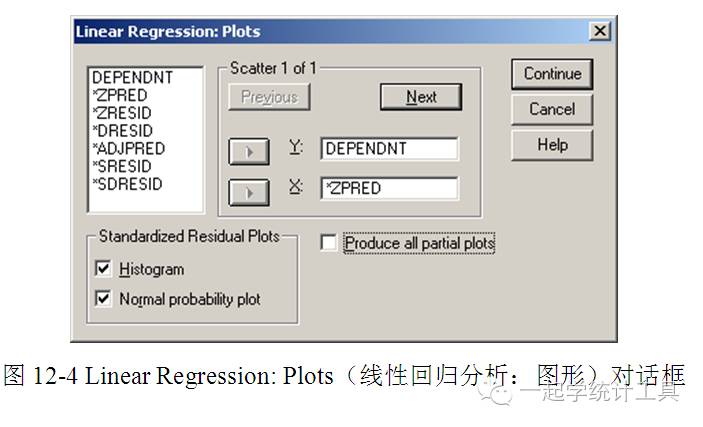
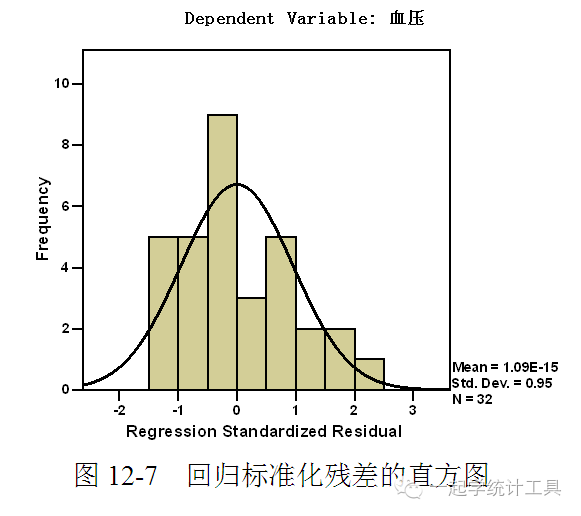
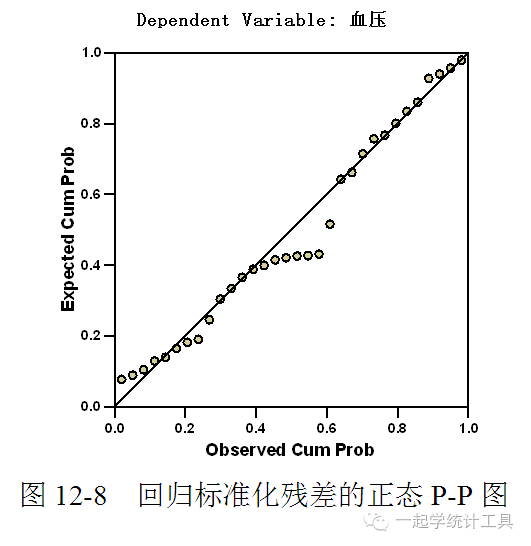
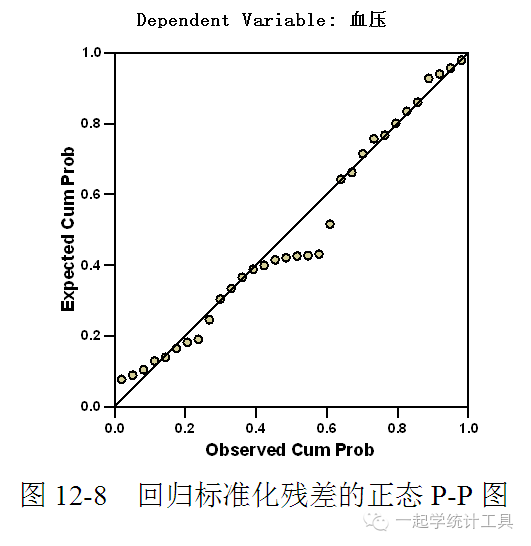
4)单击【Continue】→【Plots...】,可打开Linear Regression: Plots(线性回归分析:图形)对话框,见图12-4。 绘制图形对研究变量的正态性、线性规律及方差齐性非常有帮助,还用于发现奇异值、异常观测值。标准化残差与标准化预测值产生的散点图可研究线性规律及方差齐性。 ☆Scatter(散点图),用户从变量列表中选择变量作为Y(纵轴变量)与X(横轴变量),本例分别为DEPENDNT、*ZPRED。 ☆变量列表包括DEPENDNT(因变量)、*ZPRED(标准化预测值)、*ZRESID(标准化残差)、*DRESID(删除残差)、*ADJPRED(调整预测值)、*SRESID(Student残差)及*SDRESID(Student删除残差)。 □Produce all partial plots(产生所有的偏残差图),产生每个自变量残差与因变量残差的散点图,最少有两个自变量引入方程才能产生偏残差图。 ☆Standardized Residual Plots(标准化残差图)。 □Histogram(直方图),产生标准化残差的直方图。 □Normal probability plot(正态概率图),产生标准化残差的正态概率图(即P-P图),可对标准化残差分布与正态分布进行比较。 若选择绘制图形,在Summary statistics(综合统计量中)将显示标准化预测值(*ZPRED)及标准化残差(*ZRESID)。
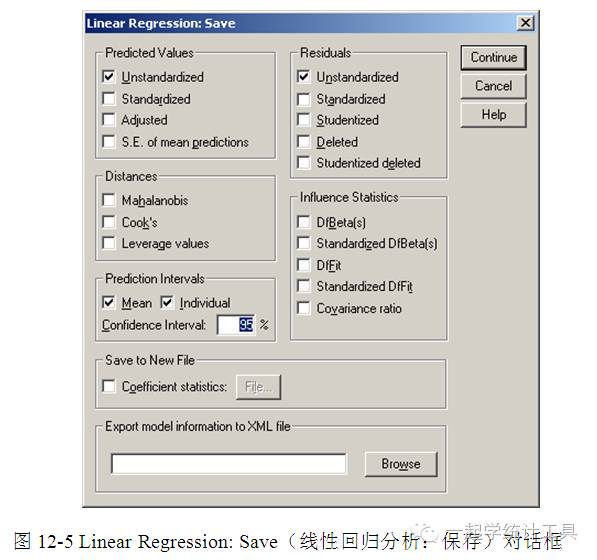
5)单击【Continue】→【Save...】,可打开Linear Regression: Save(线性回归分析:保存)对话框,见图12-5。 ☆Predicted Values(预测值),回归模型中每个个案的预测值。 □Unstandardized(非标准化预测值),模型中因变量的预测值。 □Standardized(标准化预测值),将每个预测值转换成标准化形式,即用预测值与平均预测值之差除以预测值的标准差,个案预测值的均数为0,标准差为1。 □Adjusted(调整预测值),在回归系数的计算中剔除当前个案时,当前个案的预测值。 □S.E. of mean predictions(预测值均数的标准误),与自变量相同数值的因变量平均值的标准误。 ☆Distances(距离),测量数据点与拟合模型距离的指标。 □Mahalanobis(Mahalanobis距离),自变量个案值与所有个案平均值的距离。Mahalanobis距离大时,则表明该个案的一个或多个自变量有奇异值。 □Cook's(Cook 距离),当一个个案参与计算回归系数时,所有个案残差变化的大小,Cook 距离大时,表明该个案直接地影响回归系数。 □Leverage values(杠杆值),测量回归拟合点的影响,中心点杠杆值的范围是0(对拟合无影响)到(N-1)/N之间。 ☆Prediction Intervals(预测区间),包括均数与个体预测区间的上下限。 □Mean(平均预测区间),平均预测反应区间的上下限(两个变量)。 □Individual(个体预测区间),对于单个自变量中,因变量平均预测区间的上下限(两个变量)。 Confidence Interval(置信区间),输入1-99.99的间的任意数值用作指定上述两个预测区间的置信度。只有选择Mean(平均预测区间)或Individual(个体预测区间)后,才能输入数值。典型的置信区间值为90、95、99。 ☆Residuals(残差),为因变量的实际值减去回归方程的预测值。 □Unstandardized(非标准化残差),观察值与模型预测值之差。 □Standardized(标准化残差),残差除以估计量的标准差,其均数为0,标准差为1。 □Studentized(Student残差),残差除以不同个案估计值的标准差,取决于每个个案自变量的值与自变量均数间的距离。 □Deleted(删除残差),当个案参与计算回归系数时的残差,为因变量值与调整预测值之差。 □Studentized deleted(Student删除残差),删除残差除以标准误。 ☆Influence Statistics(影响统计量)。 □DfBeta(s)(DfBeta值),β值的差值,为剔除一个个案后回归系数改变的大小。该值在模型中的每一项均进行计算(包括常数)。 □Standardized DfBeta(s)(标准化DfBeta值),β值的标准化差值,为剔除一个个案后回归系数改变的大小,当它大于2/Sqrt(N)时,该点可能为强影响点。该值在模型中的每一项均进行计算(包括常数)。 □DfFit(DfFit值),拟合值之差,为剔除一个个案后预测值改变的大小。 □Standardized DfFit(标准化DfFit值),拟合值的标准化差值,为剔除一个个案后预测值改变的大小,当它大于2/Sqrt(p/N)时,该点可能为强影响点 □Covariance ratio(协方差矩阵的比率),为一个个案不参加回归系数计算时的协方差矩阵与所有个案均参与回归系数计算的协方差矩阵的比值,该值若接近1,表明该个案对协方差矩阵的影响不大。 ☆Save to New File(保存到新文件),将回归系数保存到一个新的文件中。 □Coefficient statistics(系数统计量),单击【Files...】指定保存的路径与文件名。 ☆Export model information to XML file(将模型信息输出到XML格式文件),单击【Browse】指定文件名及路径。
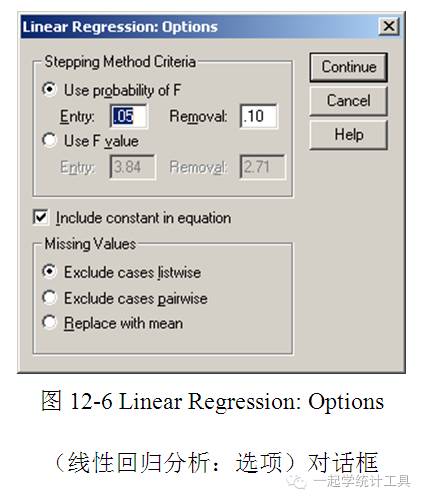
6)单击【Continue】→【Options...】,可打开Linear Regression: Options(线性回归分析:选项)对话框,见图12-6。 ☆Stepping Method Criteria(逐步回归方法准测),可应用于Stepwise(逐步回归法)、Backward(后向消去法)、Forward(前向逐步法),变量可根据指定的F值或F值的显著性水平(概率)被引入或剔除出模型。 ○Use probability of F(使用F的概率),当F值的显著性水平小于Entry(引入)值时,该变量将进入回归方程,若大于Removal(剔除)值时,则被剔除。Entry(引入)值必须小于Removal(剔除)值,且均为正数。若想更多的变量进入模型,可增加Entry(引入)值。若想在模型中剔除更多的变量,可降低的Removal(剔除)值。 ○Use F value(使用F值),当F值大于Entry(引入)值时,该变量将进入回归方程,若小于Removal(剔除)值时,则被剔除。Entry(引入)值必须大于Removal(剔除)值,且均为正数。若想更多的变量进入模型,可降低Entry(引入)值。若想在模型中剔除更多的变量,可增加的Removal(剔除)值。 □Include constant in equation(方程包含常数项),默认状态下,回归模型包含常数项,若不选此项,则回归模型经过原点。回归方程是否包含常数项,某些回归的结果的解释将不一样,如R2值不能用常规的方式来解释。 ☆Missing Values(缺失值)。 ○Exclude cases listwise(剔除含有缺失值的全部个案),所有变量均为有效值的个案才参与分析。 ○Exclude cases pairwise(成对剔除含有缺失值的个案),在回归分析中,进行相关分析的变量对均为有效值时,才进行相关系数的计算,自由度取决于最小的对数。 ○Replace with mean(用平均数替换缺失值),用变量均数代替缺失值,所有个案均参与计算。
7)单击【Continue】→【OK】,得到主要结果。 Regression(回归分析),强迫引入法 结果12-1 Variables Entered/Removedb(变量引入/剔除) Model Variables Entered Variables Removed Method 1 x3 体重指数, x2 吸烟, x1 年龄a . Enter a. All requested variables entered. b. Dependent Variable: y 血压 结果12-2 Model Summaryb(模型摘要) Model R R Square Adjusted R Square Std. Error of the Estimate 1 0.895a 0.801 0.780 6.70636 a. Predictors: (Constant), x3 体重指数, x2 吸烟, x1 年龄 b. Dependent Variable: y 血压 结果12-3 ANOVAb(方差分析表) Model Sum of Squares df Mean Square F Sig. 1 Regression 5,082.566 3 1,694.189 37.669 0.000a Residual 1,259.309 28 44.975 Total 6,341.875 31 a. Predictors: (Constant), x3 体重指数, x2 吸烟, x1 年龄 b. Dependent Variable: y 血压 结果12-4 Coefficientsa(回归系数) Model Unstandardized Coefficients Standardized Coefficients t Sig. B Std. Error Beta 1 (Constant) 45.724 9.746 4.692 0.000 x1 年龄 1.547 0.228 0.745 6.798 0.000 x2 吸烟 8.922 2.431 0.316 3.670 0.001 x3 体重指数 3.195 1.995 0.175 1.601 0.120 a. Dependent Variable: y 血压 结果12-5 Residuals Statisticsa(残差统计量) Minimum Maximum Mean Std. Deviation N Predicted Value 119.5472 168.4835 144.4375 12.80444 32 Std. Predicted Value -1.944 1.878 0.000 1.000 32 Standard Error of Predicted Value 1.648 5.992 2.245 0.775 32 Adjusted Predicted Value 118.7923 175.4356 144.5559 13.31790 32 Residual -9.57664 13.71040 0.00000 6.37361 32 Std. Residual -1.428 2.044 0.000 0.950 32 Stud. Residual -1.474 2.206 -0.003 1.012 32 Deleted Residual -10.2007 15.9699 -0.1184 7.34545 32 Stud. Deleted Residual -1.507 2.384 0.007 1.038 32 Mahal. Distance 0.903 23.777 2.906 3.982 32 Cook's Distance 0.000 0.395 0.043 0.078 32 Centered Leverage Value 0.029 0.767 0.094 0.128 32 a. Dependent Variable: y 血压
上述操作还可通过如下命令执行: REGRESSION /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA /CRITERIA=PIN(.05) POUT(.10) CIN(95) /NOORIGIN /DEPENDENT y /METHOD=ENTER x1 x2 x3 /SCATTERPLOT=(y ,*ZPRED ) /RESIDUALS HIST(ZRESID) NORM(ZRESID) /SAVEPRED MCIN ICIN RESID . 8)主要结果分析 ⑴方差分析表(ANOVA),见结果12-3。 模型(Model) 平方和 自由度 均方 F值 P值 回归(Regression) 5082.566 3 1694.189 37.669 0.000 剩余(Residual) 1259.309 28 44.975 总计(Total) 6341.875 31 ⑵多重回归方程(强迫引入法,Enter),见结果12-4。 y=45.724+1.547(x1)+8.922(x2)+3.195(x3),(P(Sig.=0.000) |
【本文地址】
今日新闻 |
推荐新闻 |