基于聚类算法的城市餐饮数据分析与店铺选址 |
您所在的位置:网站首页 › 查询周边人口密度软件 › 基于聚类算法的城市餐饮数据分析与店铺选址 |
基于聚类算法的城市餐饮数据分析与店铺选址
|
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :) 1. 项目简介餐饮业生意好坏的影响因素通常有很多,包括店铺菜系、口味、服务态度、周边环境、人口密度、所在区域、人均消费等等方面。本项目以上海城市为例,对其餐饮业消费数据进行统计分析,从三个维度“口味”、“人均消费”、“性价比”对不同菜系进行横向比较。针对某一商铺类型,将上海划分成格网空间,做空间指标评价,基于聚类算法,得到较好选址的网格位置的中心坐标,以及所属区域。 B站下载与代码下载:基于聚类算法的城市餐饮数据分析与店铺选址_哔哩哔哩_bilibili 最新更新:增加Web系统,进行可视化渲染! 2. 功能组成基于聚类算法的城市餐饮数据分析与店铺选址系统的功能组成如下图所示:
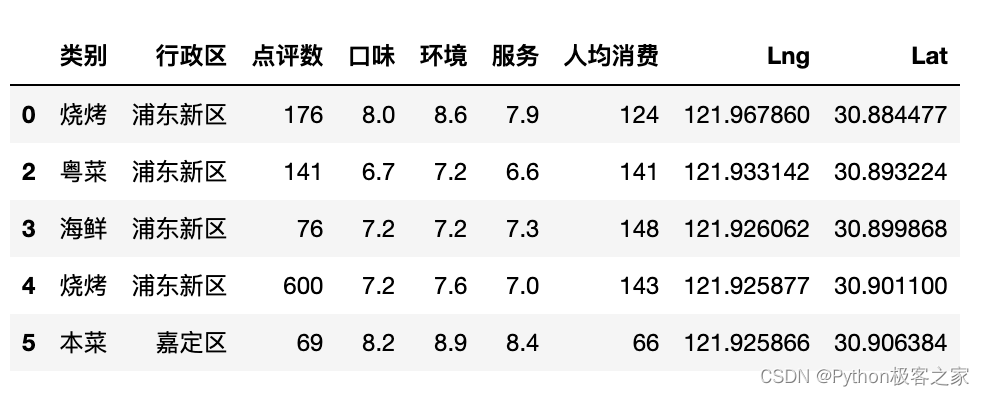
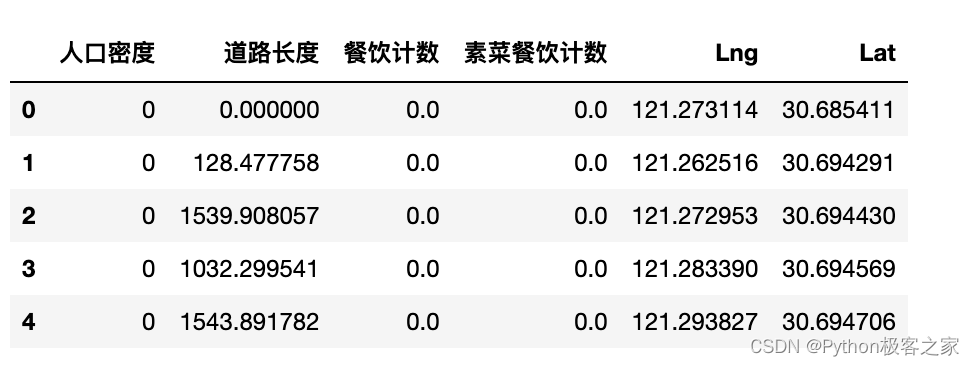
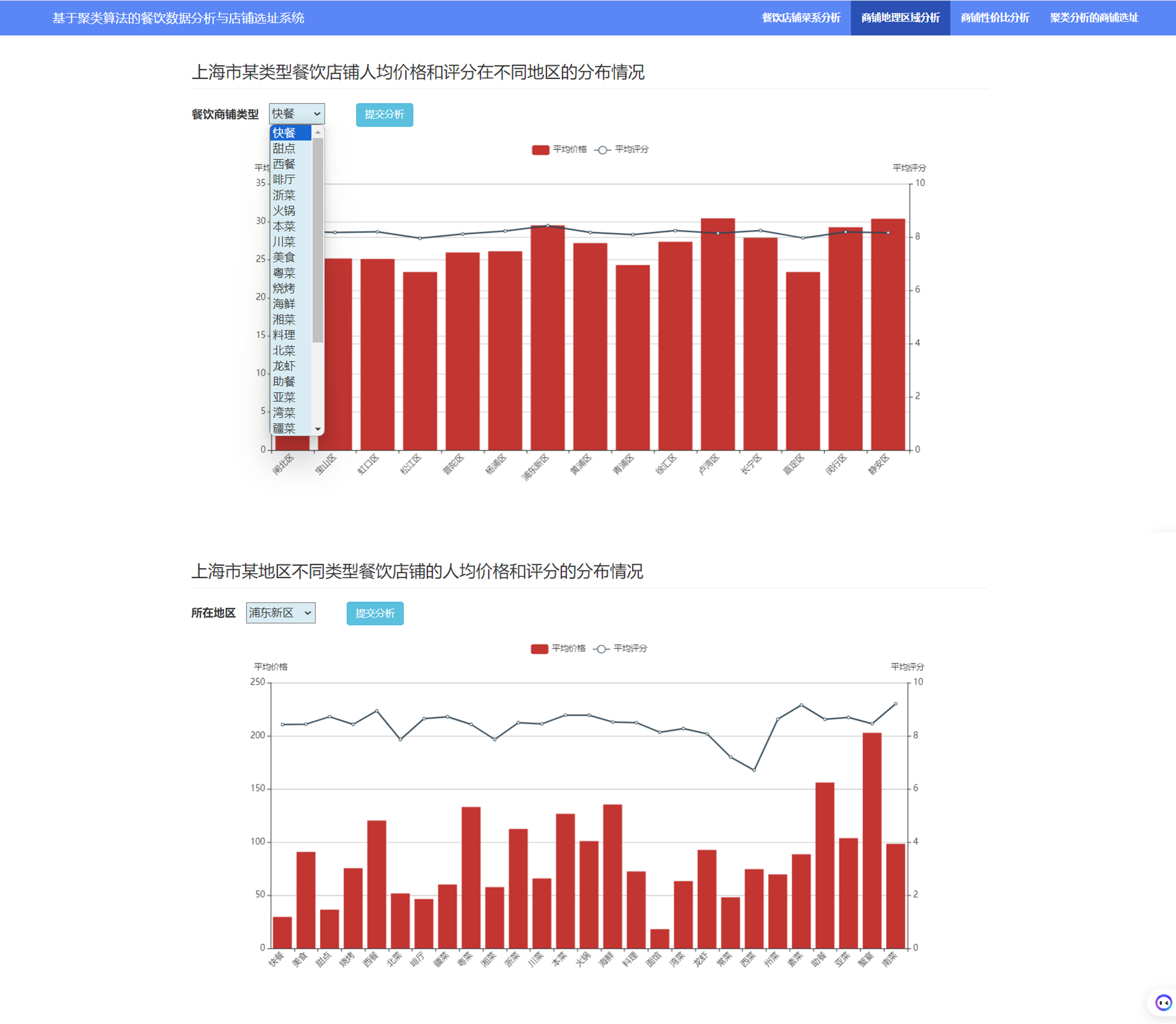
1. 从三个维度“口味”、“人均消费”、“性价比”对不同菜系进行比较,并筛选出可开店铺的 计算出三个维度的指标得分评价方法: 口味 → 得分越高越好性价比 → 得分越高越好人均消费 → 价格适中即可制作散点图,x轴为“人均消费”,y轴为“性价比得分”,点的大小为“口味得分”,绘制柱状图,分别显示“口味得分”、“性价比得分”2. 选择一个餐饮类型,将上海划分成格网空间,做空间指标评价,得到餐饮选址位置 通过空间分析,分别计算每个格网内的几个指标:人口密度指标、道路密度指标、餐饮热度指标、同类竞品指标评价方法: 人口密度指标 → 得分越高越好道路密度指标 → 得分越高越好餐饮热度指标 → 得分越高越好同类竞品指标 → 得分越低越好综合指标 = 人口密度指标0.4 + 餐饮热度指标0.3 + 道路密度指标0.2 +同类竞品指标0.1最后得到较好选址的网格位置的中心坐标,以及所属区域 4. 工具包导入与数据读取本项目数据统计分析主要采用 numpy 和 pandas,可视化采用 Matplotlib、seaborn 和 bokeh实现: import os import gc import numpy as np import pandas as pd import seaborn as sns import matplotlib as mpl import matplotlib.pyplot as plt np.random.seed(7) plt.style.use('fivethirtyeight') import warnings warnings.filterwarnings('ignore') from bokeh.plotting import figure,show,output_file from bokeh.models import ColumnDataSource from bokeh.layouts import gridplot from bokeh.models import HoverTool from bokeh.models.annotations import BoxAnnotation from bokeh.io import output_notebook from matplotlib.font_manager import FontProperties # 读取字体路径,设置字体为思源黑体 myfont=FontProperties(fname=r'/System/Library/Fonts/Hiragino Sans GB.ttc') sns.set(font=myfont.get_name()) output_notebook()读取上海餐饮数据和上海地区的人口密度数据,并进行缺失值分析: data_df = pd.read_csv('上海餐饮数据.csv', encoding='gbk') data_df = data_df.drop(columns=['城市']) data_df = data_df[data_df['人均消费'] > 0] people_df = pd.read_csv('上海地区人口密度数据.csv', encoding='gbk') people_df.columns = ['人口密度','道路长度','餐饮计数','素菜餐饮计数','Lng','Lat'] people_df.fillna(0,inplace = True)
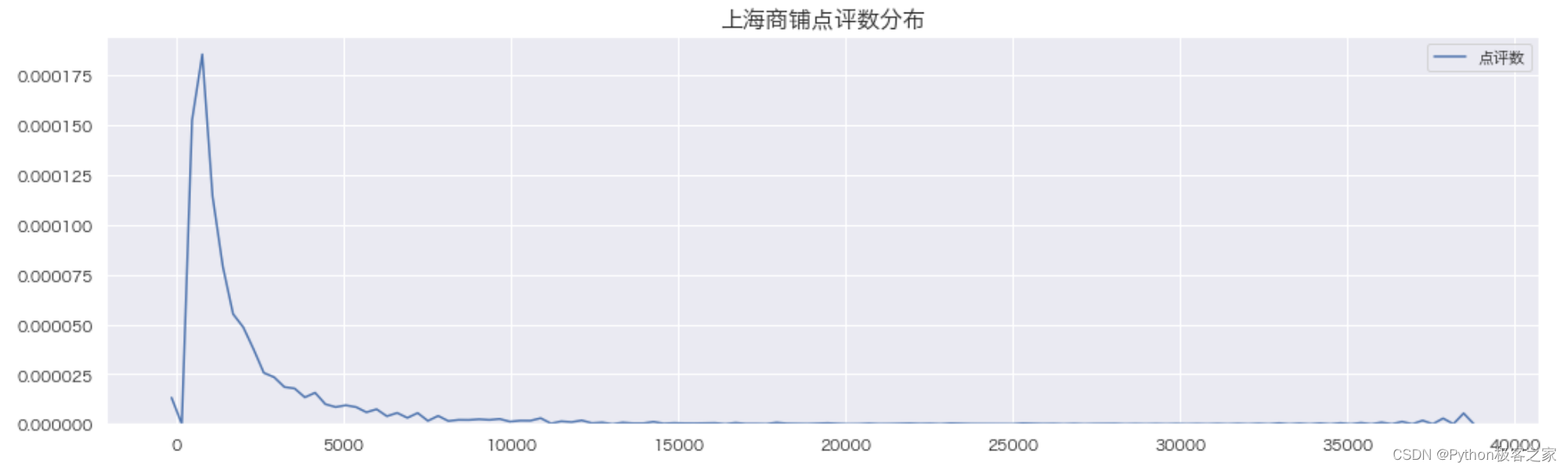
可以发现,缺失的比例非常小,考虑直接删除这些异常数据。 5. 数据探索式分析 5.1 上海商铺点评数分布 plt.figure(figsize=(16, 5)) sns.kdeplot(data_df['点评数']) plt.title('上海商铺点评数分布', fontsize=16, weight='bold') plt.show()
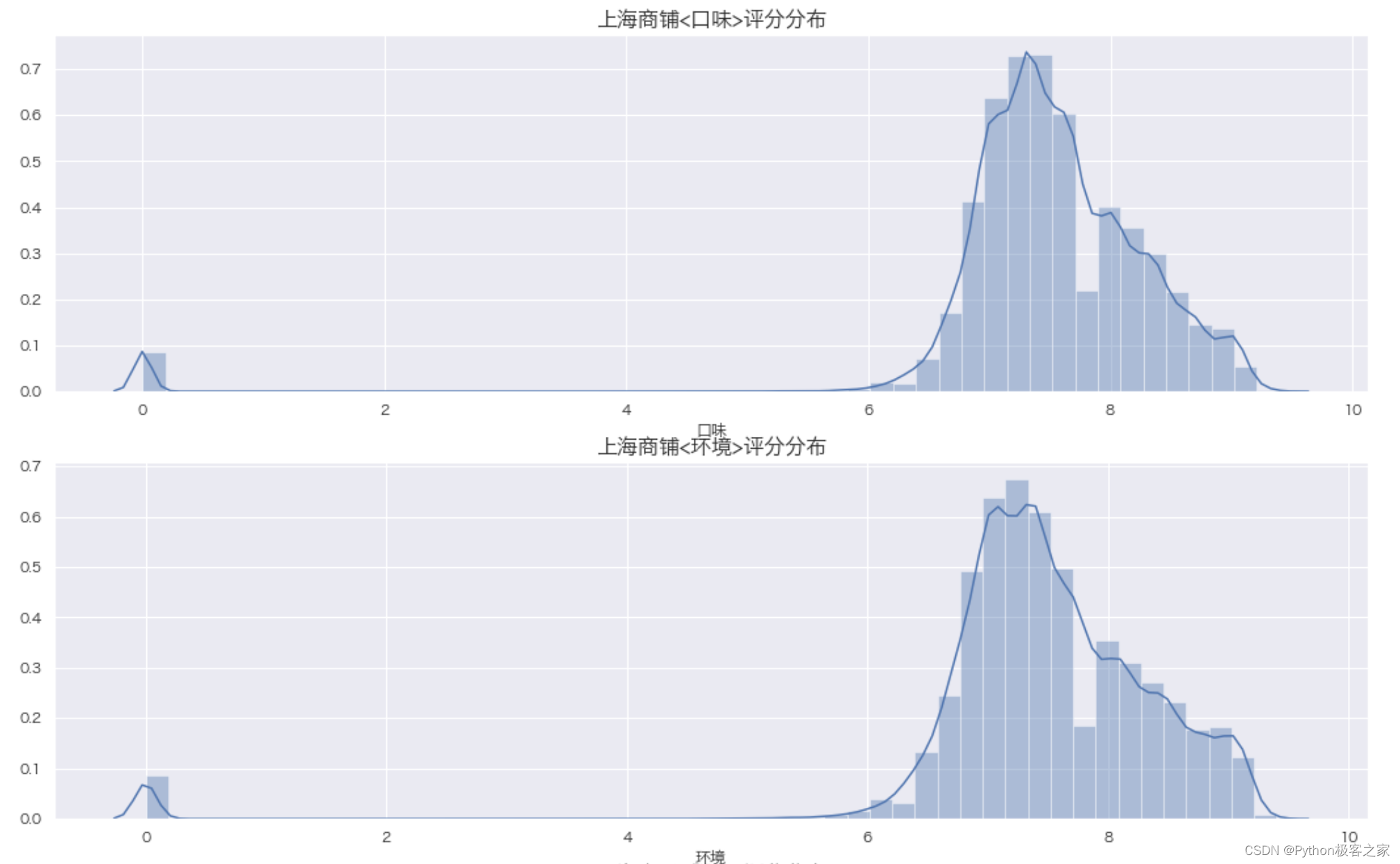
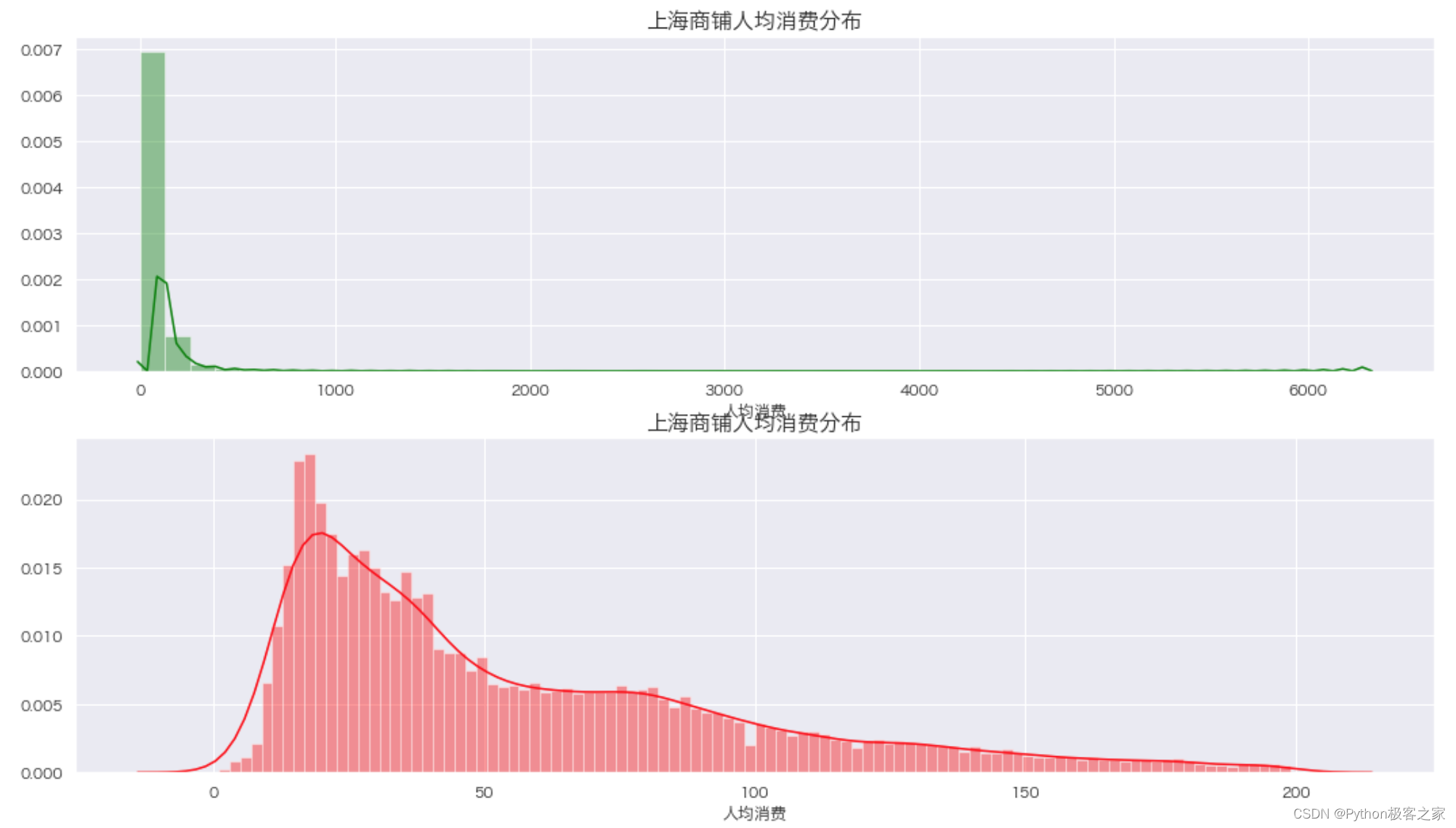
可以看出: 评分为 0 的商铺最多,可能的原因是数据存在缺失,或者用户没有对口味进行评价;大部分商铺评分集中在 6 - 10 分 5.3 上海商铺人均消费的分布 plt.figure(figsize=(16, 10)) plt.subplot(211) sns.distplot(data_df['人均消费'], bins=50, color="green") plt.title('上海商铺人均消费分布', fontsize=16, weight='bold') plt.subplot(212) tmp = data_df[(data_df['人均消费'] > 0) & (data_df['人均消费'] < 200)] sns.distplot(tmp['人均消费'], bins=100, color="red") plt.title('上海商铺人均消费分布', fontsize=16, weight='bold') plt.show()
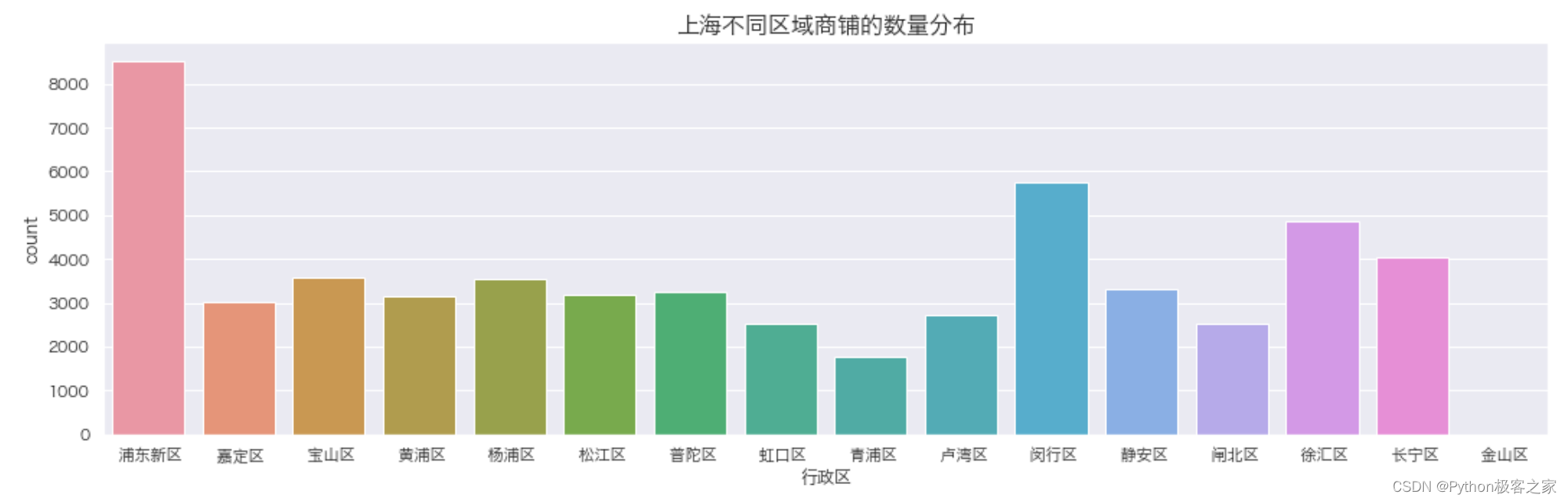
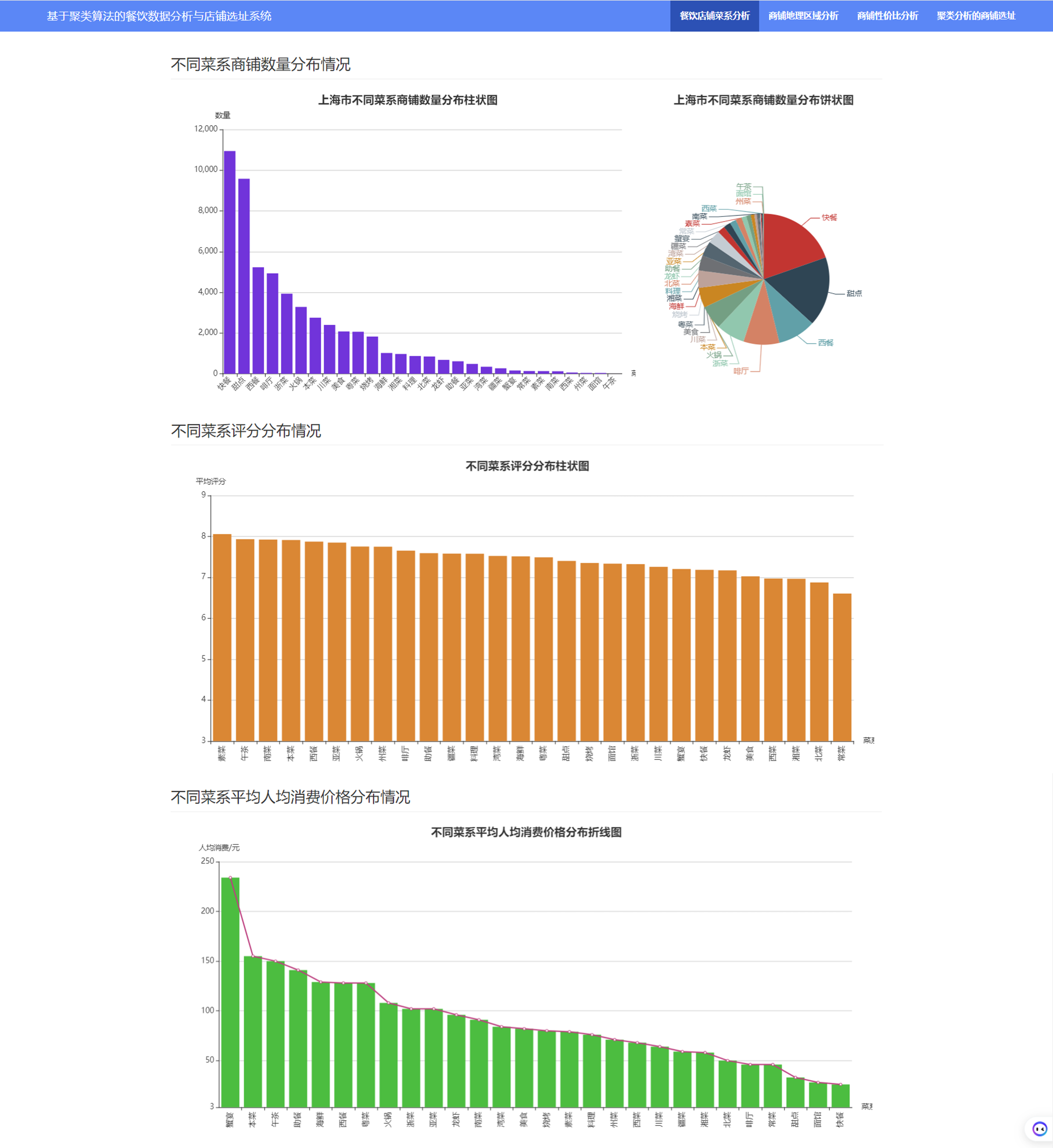
可以看出: 人均消费为 0 的商铺最多,可能的原因是数据存在缺失;大部分商铺评分集中在 20-200 元之间最高消费 6000+ 5.4 不同菜系的商铺数量的分布 plt.figure(figsize=(16, 5)) sns.countplot(data_df['类别'], order=data_df['类别'].value_counts().index) plt.title('上海不同区域商铺菜系类别的数量分布', fontsize=16, weight='bold') plt.show()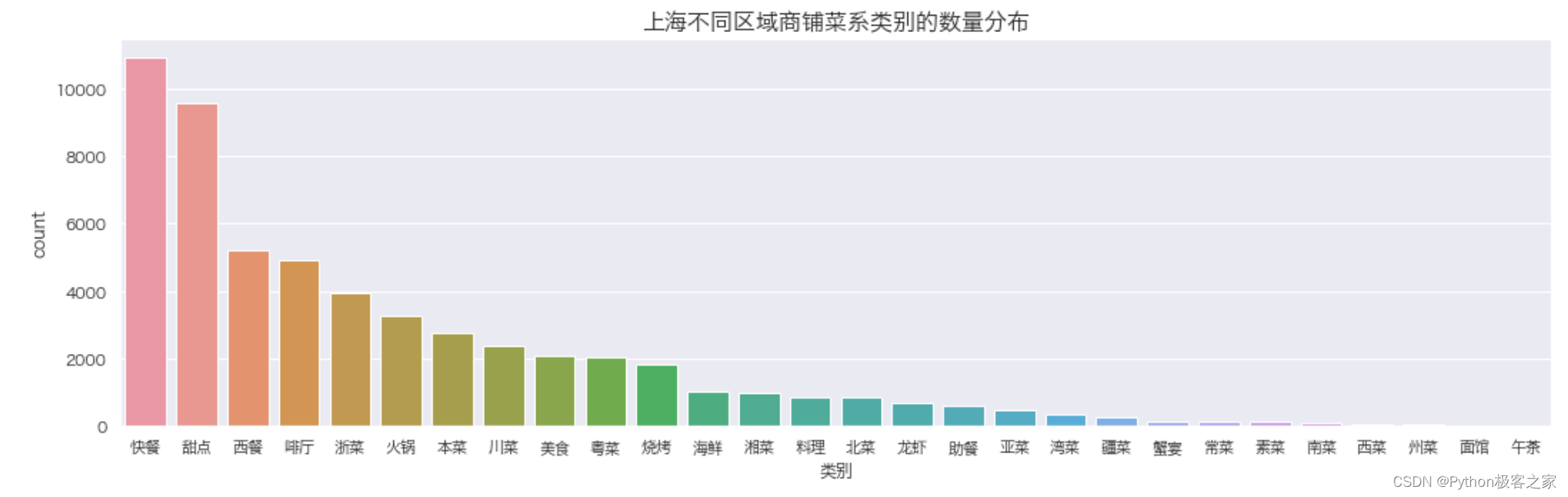 5.5 上海不同区域商铺的数量分布
plt.figure(figsize=(16, 5))
sns.countplot(data_df['行政区'])
plt.title('上海不同区域商铺的数量分布', fontsize=16, weight='bold')
plt.show() 5.5 上海不同区域商铺的数量分布
plt.figure(figsize=(16, 5))
sns.countplot(data_df['行政区'])
plt.title('上海不同区域商铺的数量分布', fontsize=16, weight='bold')
plt.show()
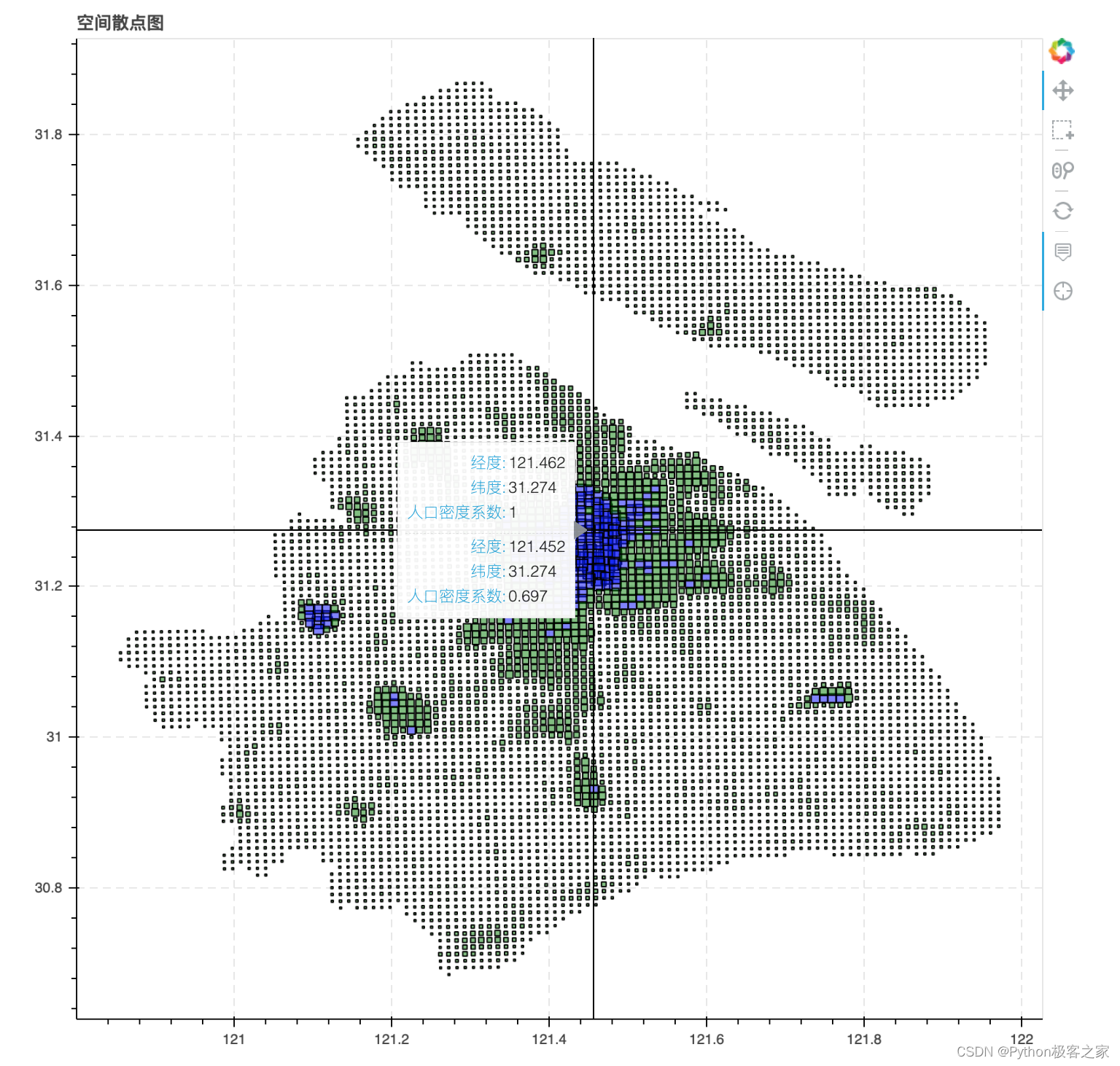
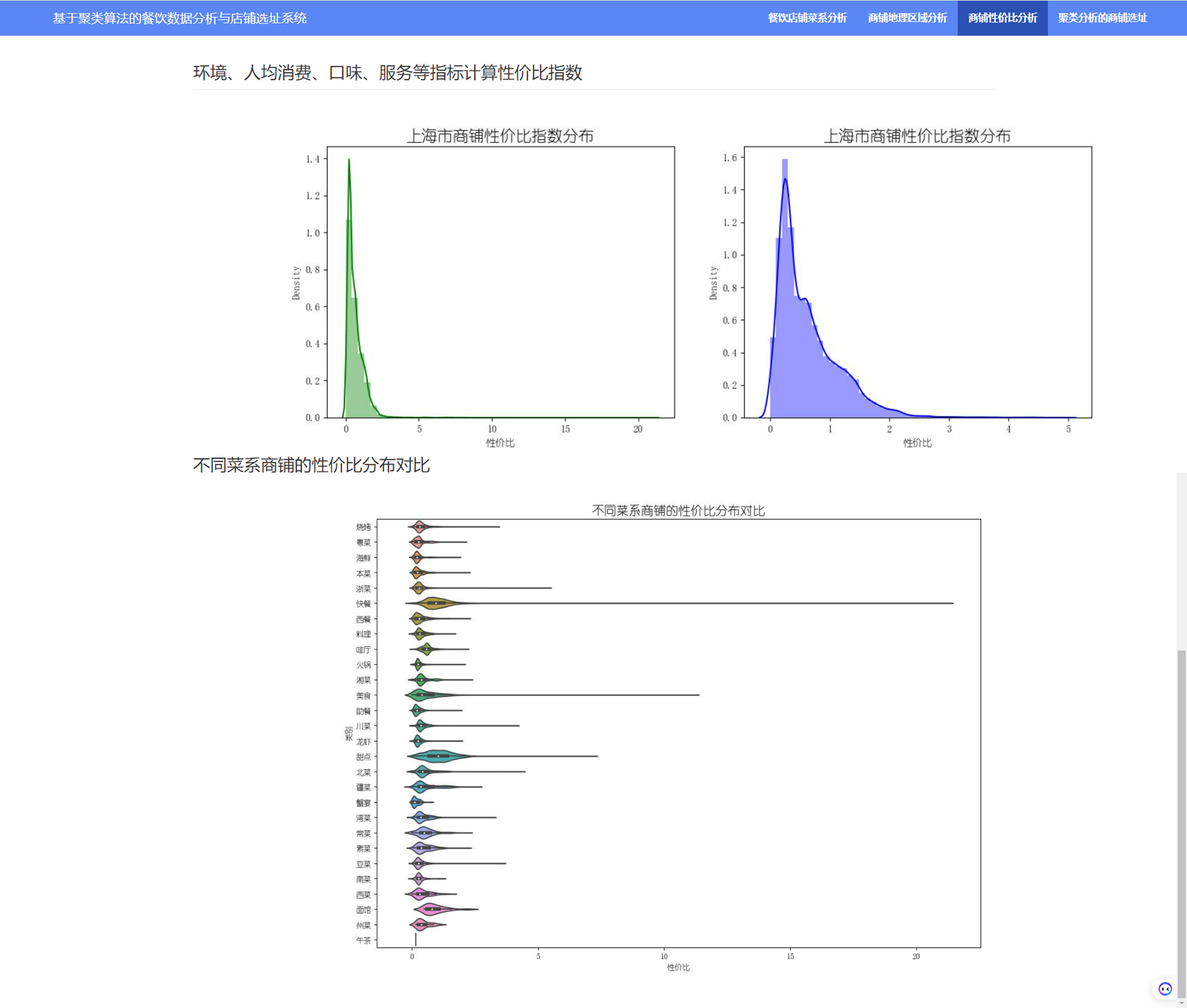
可以看出,甜点、快餐、美食、面馆的性价比相对较高! 6.3 统合人口密度分析 # 人口密度指标标准化 people_df['rkmd_norm'] = (people_df['人口密度']-people_df['人口密度'].min())/(people_df['人口密度'].max()-people_df['人口密度'].min()) # 餐饮热度指标标准化 people_df['cyrd_norm'] = (people_df['餐饮计数']-people_df['餐饮计数'].min())/(people_df['餐饮计数'].max()-people_df['餐饮计数'].min()) # 同类竞品指标标准化 people_df['tljp_norm'] = (people_df['素菜餐饮计数'].max()-people_df['素菜餐饮计数'])/(people_df['素菜餐饮计数'].max()-people_df['素菜餐饮计数'].min()) # 道路密度指标标准化 people_df['dlmi_norm'] = (people_df['道路长度']-people_df['道路长度'].min())/(people_df['道路长度'].max()-people_df['道路长度'].min()) people_df['人口密度系数'] = people_df['rkmd_norm']*0.4 + people_df['cyrd_norm']*0.3 + \ people_df['tljp_norm']*0.1 + people_df['dlmi_norm']*0.2 # 人口密度按照从大到小排序 people_df = people_df.sort_values(by = '人口密度系数',ascending=False).reset_index() # 商铺数据按照性价比排序 data_df = data_df.sort_values(by = '性价比',ascending=False).reset_index(drop=True)按照人口密度绘制空间散点图: people_df['size'] = people_df['人口密度系数'] * 15 people_df['color'] = 'green' people_df['color'].iloc[:200] = 'blue' # 人口密度最大的前10个位置 # 添加size字段 source = ColumnDataSource(people_df) # 创建ColumnDataSource数据 hover = HoverTool(tooltips=[("经度", "@Lng"), ("纬度", "@Lat"), ("人口密度系数", "@rkmd_norm"), ]) # 设置标签显示内容 p = figure(plot_width=800, plot_height=800, title="空间散点图" , tools=[hover,'box_select, reset, wheel_zoom, pan,crosshair']) # 构建绘图空间 p.square(x = 'Lng',y = 'Lat',source = source, line_color = 'black',fill_alpha = 0.5, size = 'size',color = 'color') p.ygrid.grid_line_dash = [6, 4] p.xgrid.grid_line_dash = [6, 4] show(p)
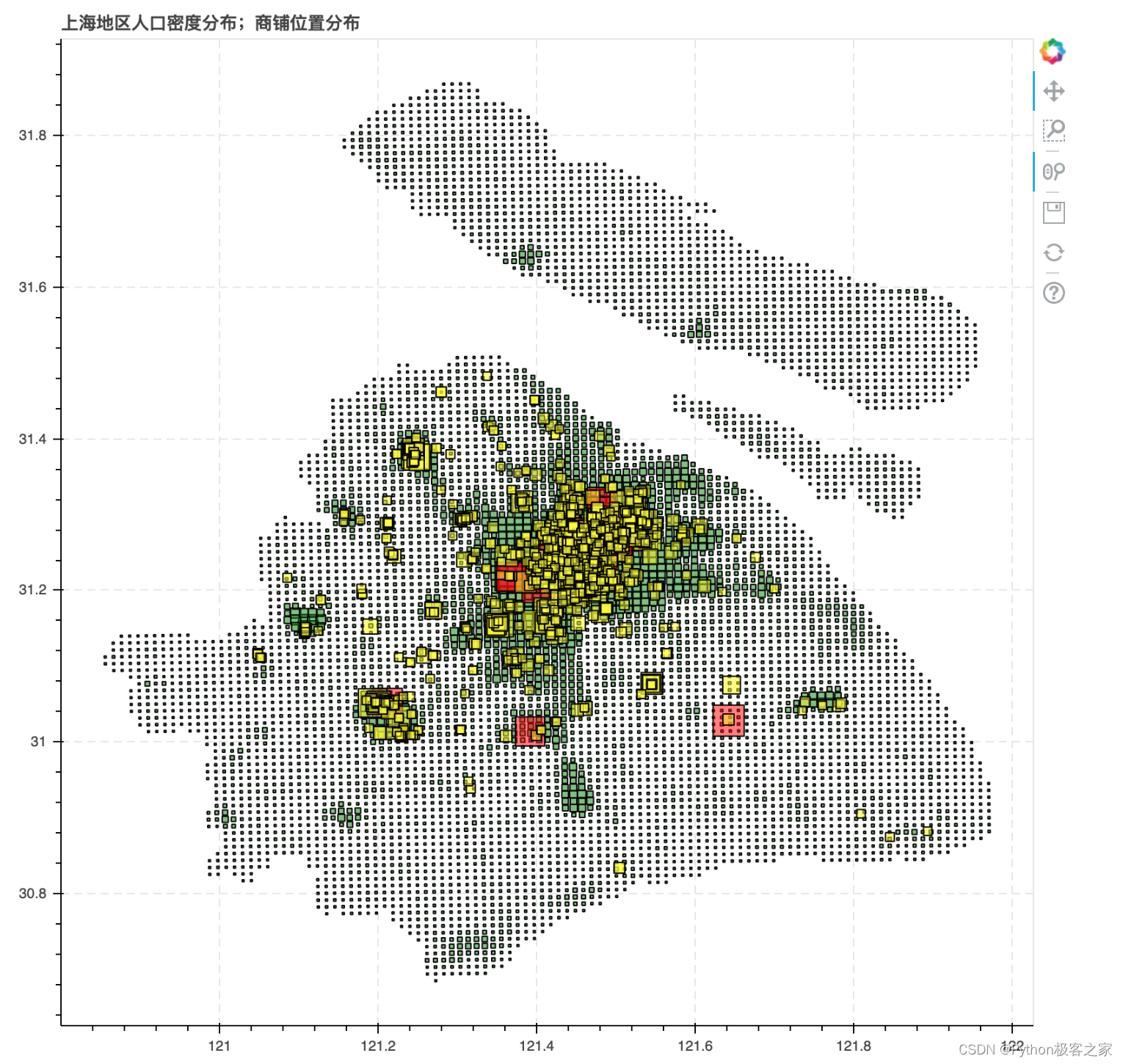
绘制综合性价比的 TOP1000商铺的空间分布: # 添加显示的size字段 people_df['size'] = people_df['人口密度系数'] * 15 people_df['color'] = 'green' people_df['color'].iloc[:20] = 'blue' # 人口密度最大的前20个位置 cater_df = data_df[:1000] # 选择性价比排名前 1000 名的商铺进行可视化 cater_df['size'] = data_df['性价比'] * 3 cater_df['color'] = 'yellow' cater_df['color'].iloc[:20] = 'red' # 选择性价比排名前 1000 名的商铺设置为红色 # 创建 ColumnDataSource 数据 people_source = ColumnDataSource(people_df) cater_source = ColumnDataSource(cater_df) p = figure(plot_width=800, plot_height=800, title="上海地区人口密度分布;商铺位置分布" ) # 构建绘图空间 p.square(x = 'Lng',y = 'Lat',source = people_source, line_color = 'black',fill_alpha = 0.5, size = 'size',color = 'color') p.square(x = 'Lng',y = 'Lat',source = cater_source, line_color = 'black',fill_alpha = 0.5, size = 'size',color = 'color') p.ygrid.grid_line_dash = [6, 4] p.xgrid.grid_line_dash = [6, 4] show(p)
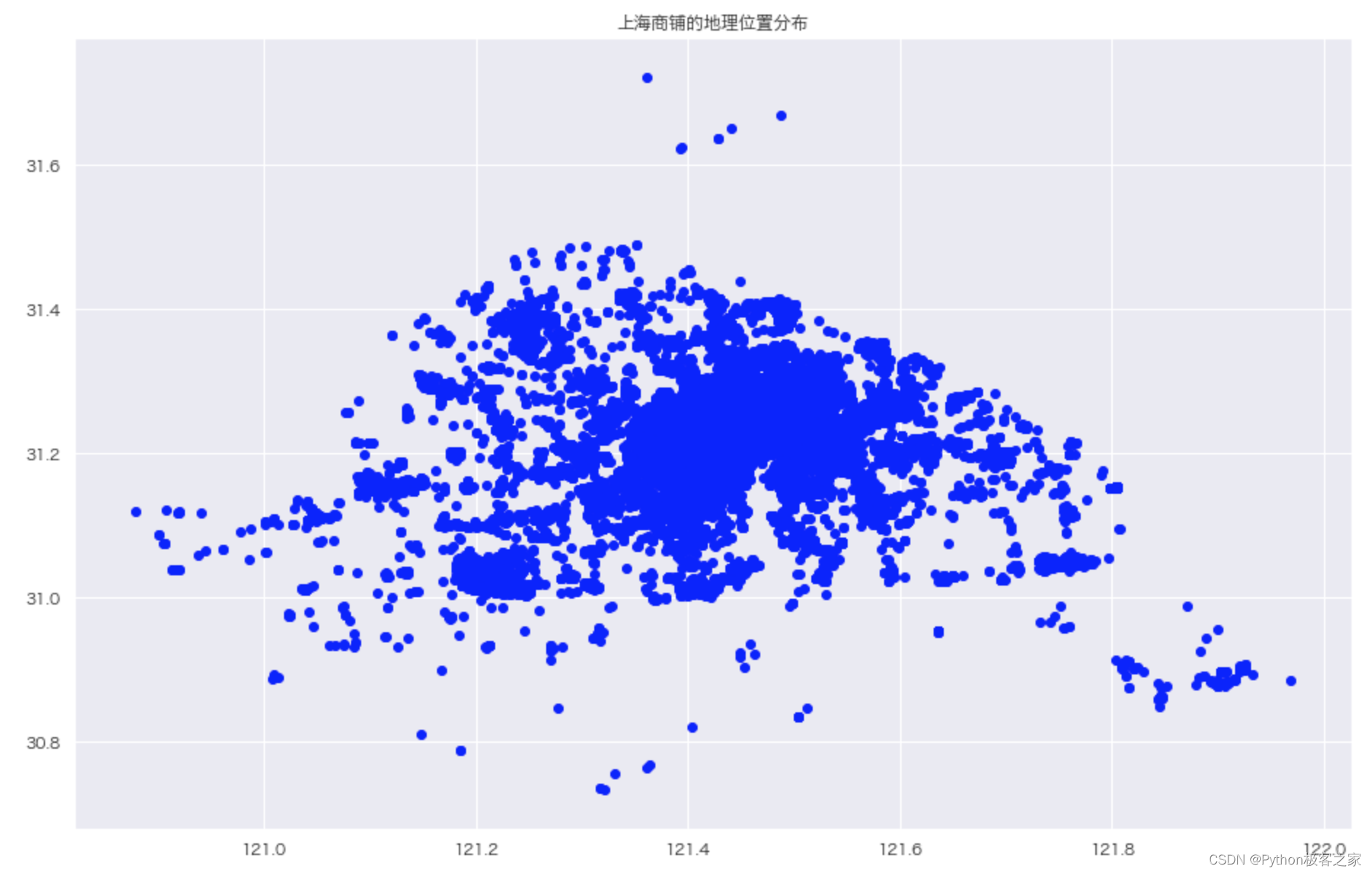
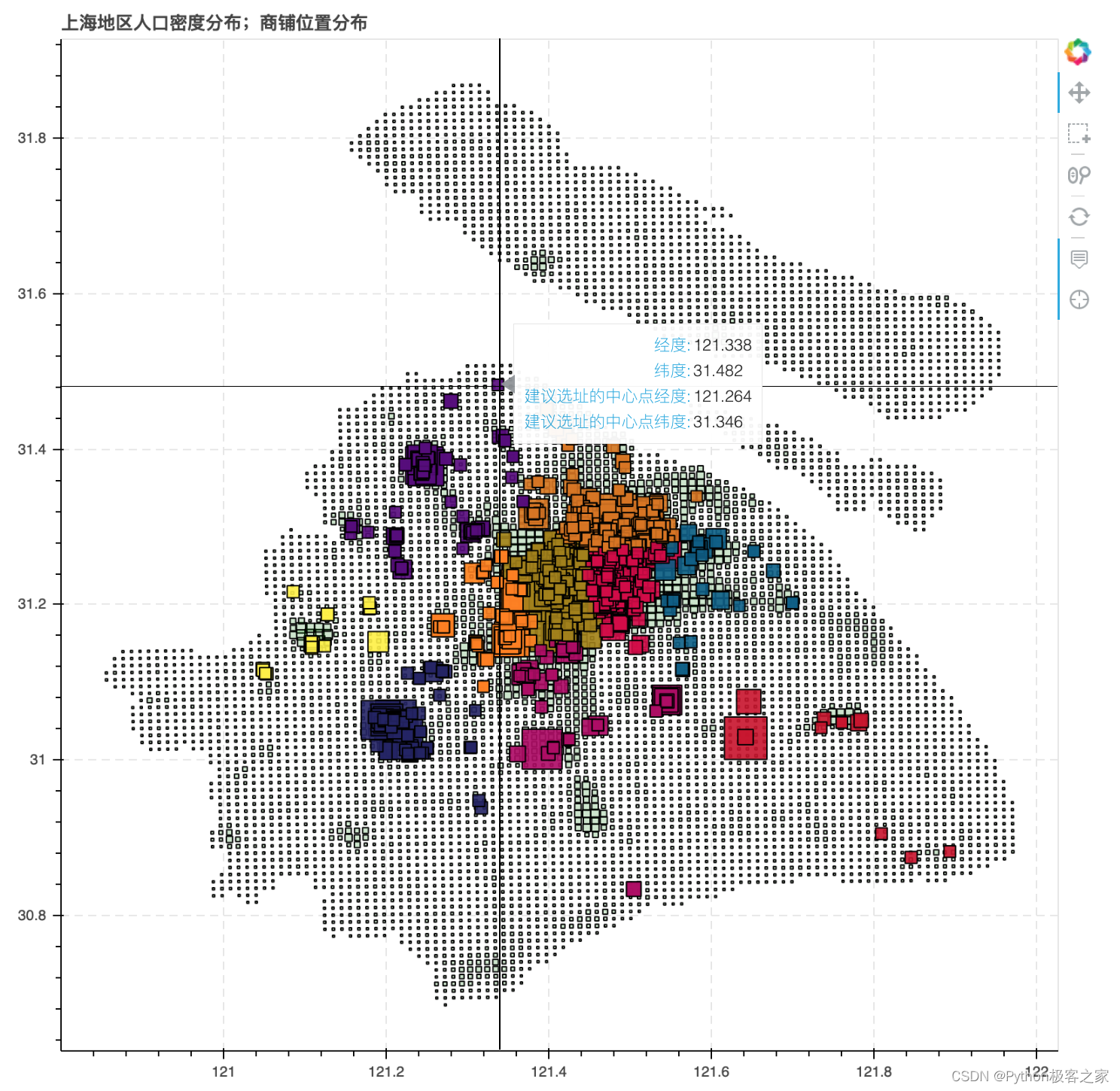
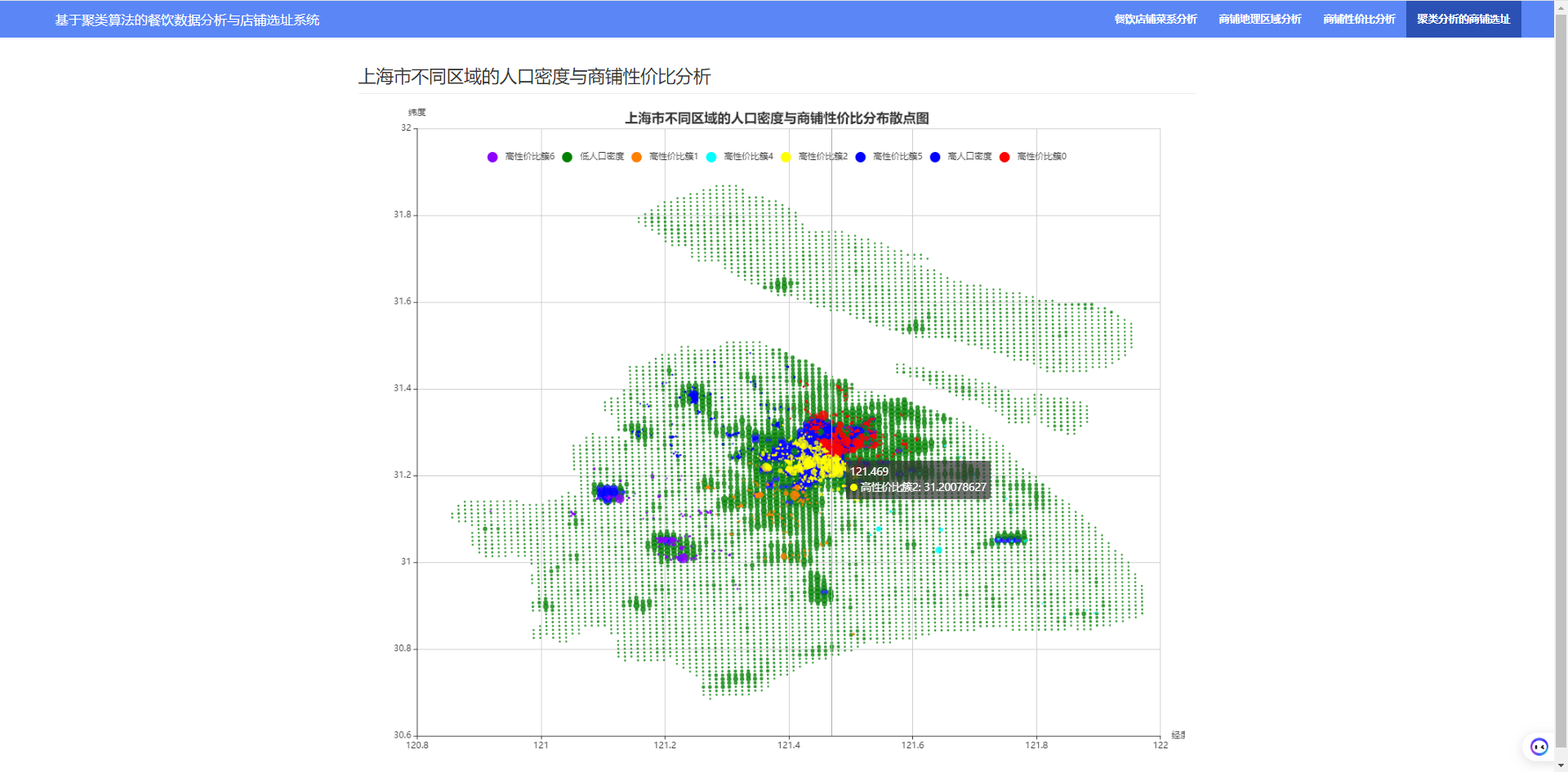
可以看出,市中心人口密度最大,大部分的商铺也集中在市中心,说明人口密度是商铺选址考虑的重要因素! 6.5 KMeans聚类算法对上海餐饮商铺选址的分析利用 kmeans 对商铺的经纬度、行政区、点评数、口味、环境、服务和人均消费等特征进行聚类,对聚类结果可视化: colors = ['#d40045','#ff7f00','#055D87','#56007d','#af0065','#fff231','#ca1028','#d9760f','#a38204', '#232166'] # 添加显示的size字段 people_df['size'] = people_df['人口密度系数'] * 15 people_df['color'] = 'green' cater_df = cater_df[:1000] # 选择性价比排名前 1000 名的商铺进行可视化 cater_df['size'] = data_df['性价比'] * 4 cater_df['color'] = 'yellow' for i in range(N_CLUSTER): cater_df['color'].loc[cater_df['cluster_label'] == i] = colors[i] # 创建 ColumnDataSource 数据 people_source = ColumnDataSource(people_df) cater_source = ColumnDataSource(cater_df) hover = HoverTool(tooltips=[("经度", "@Lng"), ("纬度", "@Lat"), ("建议选址的中心点经度", "@cluster_Lng"), ("建议选址的中心点纬度", "@cluster_Lat") ]) # 设置标签显示内容 p = figure(plot_width=800, plot_height=800, title="上海地区人口密度分布;商铺位置分布", tools=[hover,'box_select, reset, wheel_zoom, pan,crosshair']) # 构建绘图空间 p.square(x = 'Lng',y = 'Lat',source = people_source, line_color = 'black',fill_alpha = 0.2, size = 'size',color = 'color') p.square(x = 'Lng',y = 'Lat',source = cater_source, line_color = 'black',fill_alpha = 0.9, size = 'size',color = 'color') p.ygrid.grid_line_dash = [6, 4] p.xgrid.grid_line_dash = [6, 4] show(p)
本项目以上海城市为例,对其餐饮业消费数据进行统计分析,从三个维度“口味”、“人均消费”、“性价比”对不同菜系进行横向比较。针对某一商铺类型,将上海划分成格网空间,做空间指标评价,基于聚类算法,得到较好选址的网格位置的中心坐标,以及所属区域。 欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 精彩专栏推荐订阅: 1. Python 毕设精品实战案例2. 自然语言处理 NLP 精品实战案例3. 计算机视觉 CV 精品实战案例
|

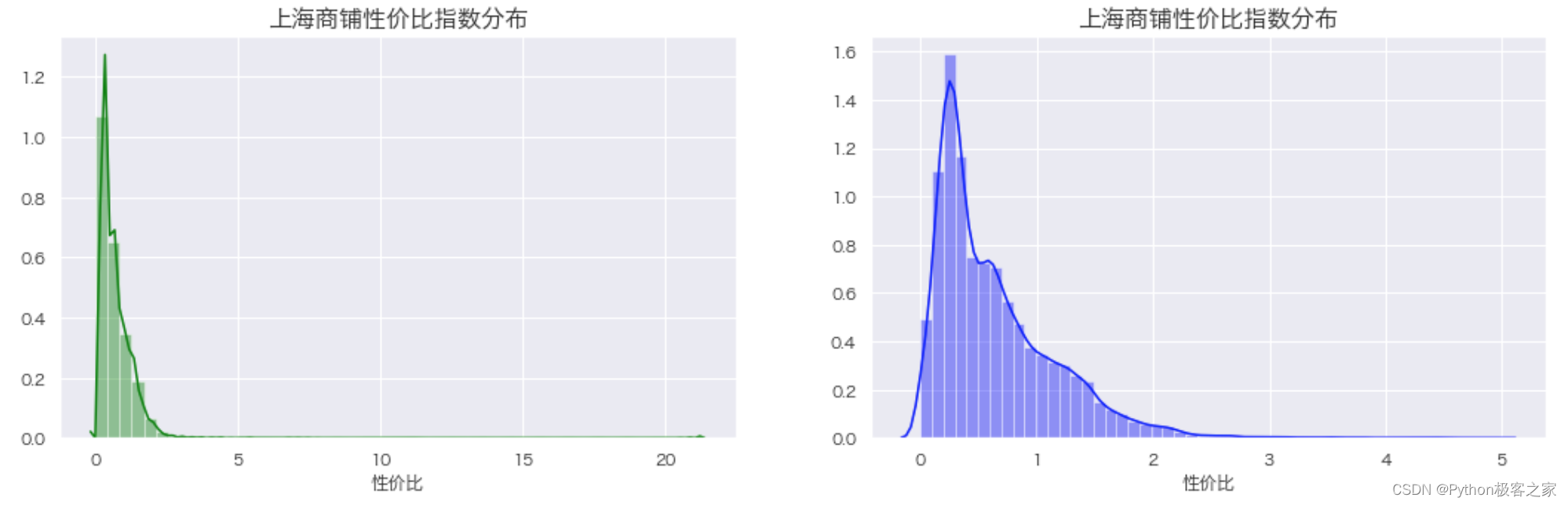 可以看出,大部分商铺的性价比评分集中在 3 以内,性价比超高10的只有16个商铺,占比非常小,可能是数据采集的时候存在问题,考虑删除该异常数据。
可以看出,大部分商铺的性价比评分集中在 3 以内,性价比超高10的只有16个商铺,占比非常小,可能是数据采集的时候存在问题,考虑删除该异常数据。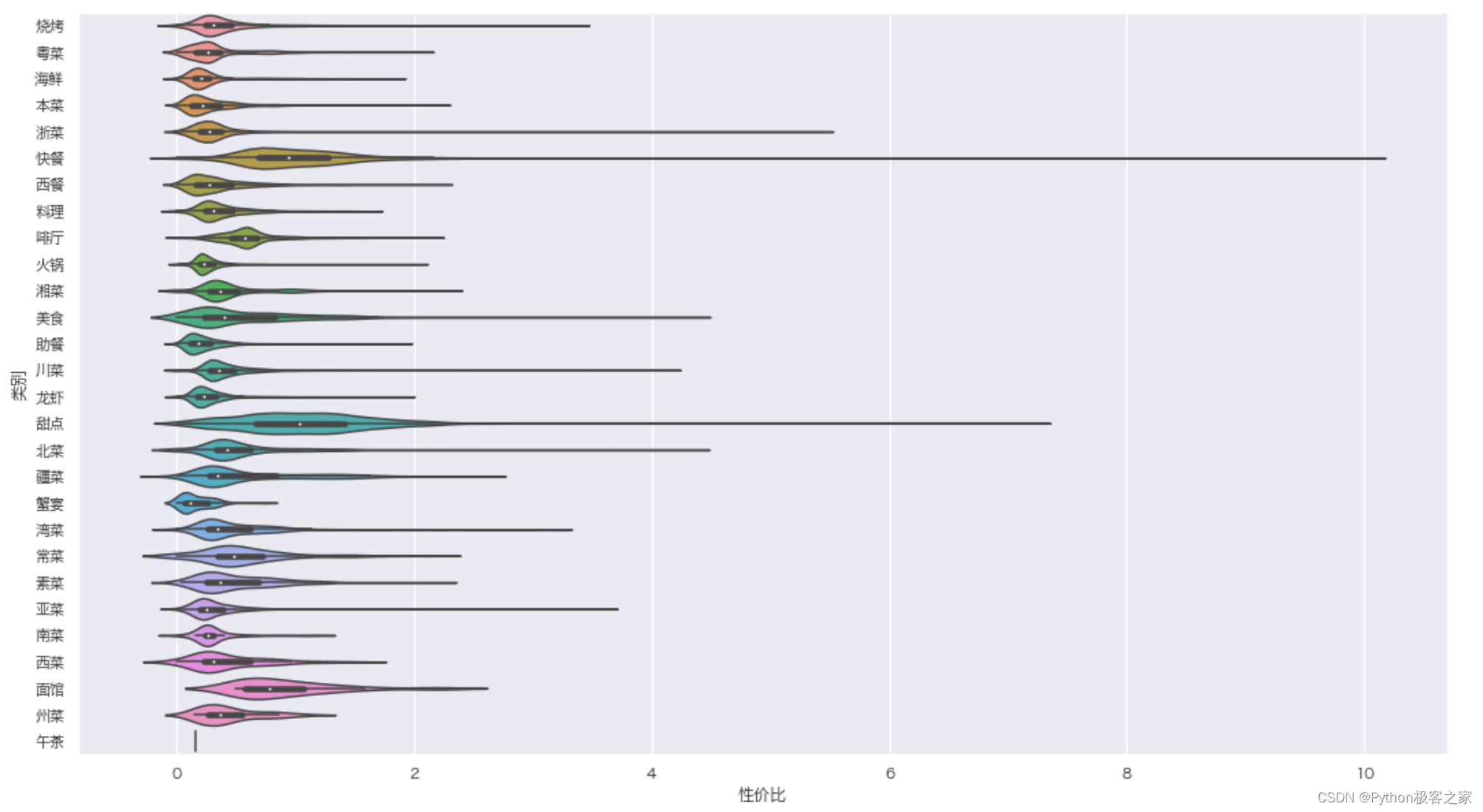


【本文地址】
今日新闻 |
推荐新闻 |