史上最全航班号,航班信息爬虫,飞常准 |
您所在的位置:网站首页 › 查询历史航班 › 史上最全航班号,航班信息爬虫,飞常准 |
史上最全航班号,航班信息爬虫,飞常准
|
有一个爬航班信息的需求,在飞常准网站上可以得到一个航班列表,里面有6000个航班号,但经过测试后发现这个列表不全,导致爬取的数据缺失严重,经过长时间的收集,最终得到了一份更全面的航班号,虽然还是没有达到全部覆盖,但已经是能找到最全的了,共10931个航班号,且基本有效,最终爬取到了9747个航班信息。点击获取最全航班号
附代码: import requests import re from bs4 import BeautifulSoup as bs import time import random from fake_useragent import UserAgent requests.adapters.DEFAULT_RETRIES = 5 class Variflight(object): def __init__(self): self.url_base = 'http://www.variflight.com' self.ua = UserAgent() self.headers = {} def get_ip(self): with open('f:\\data\\ip.txt','r') as f: ip_list = f.read().split('\n') return ip_list def get_fnums(self): #航班列表 ip_list = self.get_ip() url_fnum_list = 'http://www.variflight.com/sitemap.html?AE71649A58c77=' while(1): try: self.headers['User-Agent'] = self.ua.random ip = random.choice(ip_list) r = requests.get(url_fnum_list,headers=self.headers,proxies={'http':ip,'https':ip},timeout=1) break except: ip_list = self.get_ip() soup = bs(r.text,'lxml') list_a = soup.find(class_='list').find_all('a') list_url_fnum = [self.url_base + a.attrs['href'] for a in list_a] # print('get_fums') return list_url_fnum def get_fnums_from_txt(self,fname='所有航班号'): url = 'http://www.variflight.com/flight/fnum/{}.html?AE71649A58c77=' with open('f:\\data\\{}.txt'.format(fname),'r') as f: fnums = f.read().split(' ') url_fnums = [url.format(fnum) for fnum in fnums] return url_fnums def get_url_details(self,url_fnum,fdate): try:#fdate=20200101 url = url_fnum + '&fdate={}'.format(fdate) # print(url) ip_list = self.get_ip() while(1): try: ip = random.choice(ip_list) self.headers['User-Agent'] = self.ua.random r = requests.get(url,headers=self.headers,proxies={'http':ip,'https':ip},timeout=1) # print(r.text) break except: ip_list = self.get_ip() soup = bs(r.text,'lxml') list_a = soup.find_all(class_="searchlist_innerli") list_url = [self.url_base + a.attrs['href'] for a in list_a] return list_url except: # print(e) return [] def timeformat(self,timestamp): timestr = time.strftime('%Y/%m/%d %H:%M:%S',time.localtime(timestamp)) if timestamp else '--' return timestr def get_url_data(self,url_detail): while(1): ip_list = self.get_ip() try: self.headers['User-Agent'] = self.ua.random ip = random.choice(ip_list) r = requests.get(url_detail,headers=self.headers,proxies={'http':ip,'https':ip},timeout=1) url_str = re.findall('https://flightadsb.variflight.com/flight-playback/(.*?)"',r.text)[0] values = url_str.split('/') fnum = values[0] forg = values[1] fdst = values[2] ftime = values[3] url_data = 'https://adsbapi.variflight.com/adsb/index/flight?lang=zh_CN&fnum={fnum}&time={time}&forg={forg}&fdst={fdst}'.format(fnum=fnum,time=ftime,forg=forg,fdst=fdst) break except: # print(e) ip_list = self.get_ip() # print('get_url_data') return url_data def parse_data(self,url_data,fdata): ip_list = self.get_ip() while(1): try: self.headers['User-Agent'] = self.ua.random ip = random.choice(ip_list) r = requests.get(url_data,headers=self.headers,proxies={'http':ip,'https':ip},timeout=1) json= r.json() data = json.get('data',{}) break except: ip_list = self.get_ip() fnum = data.get('fnum','--') #航班号 airCName = data.get('airCName','--') # 航空公司 scheduledDeptime = self.timeformat(data.get('scheduledDeptime',0)) # 计划出发 actualDeptime = self.timeformat(data.get('actualDeptime',0)) # 实际出发 forgAptCname = data.get('forgAptCname','--') # 出发地 scheduledArrtime = self.timeformat(data.get('scheduledArrtime',0)) # 计划到达 actualArrtime = self.timeformat(data.get('actualArrtime',0)) # 实际到达 fdstAptCname = data.get('fdstAptCname','--') # 到达地 status = '取消' if actualArrtime == '--' else '到达' # 状态 value = ','.join([fnum,airCName,scheduledDeptime,actualDeptime,forgAptCname,scheduledArrtime,actualArrtime,fdstAptCname,status]) # print(value) with open('f:\\data\\{0}.csv'.format(fdata),'a') as f: f.write(value + '\n') def main(self,fdata,k=0): # fnums = self.get_fnums() fnums = self.get_fnums_from_txt('所有航班号') n = len(fnums) print(fdata) for i in range(k,n): print('\r{}/{}'.format(i+1,n),end='') fnum = fnums[i] url_details = self.get_url_details(fnum,fdata) for url_detail in url_details: url_data = self.get_url_data(url_detail) self.parse_data(url_data,fdata) if __name__ == "__main__": flight = Variflight() fdata = 20200229 #日期 flight.main(fdata) |
 分享一些经验: 飞常准网站上航班信息中实际起飞和到达时间是一张图片,通用的思路是将图片下载下来调用pytesseract或其他ORC工具去识别。
分享一些经验: 飞常准网站上航班信息中实际起飞和到达时间是一张图片,通用的思路是将图片下载下来调用pytesseract或其他ORC工具去识别。 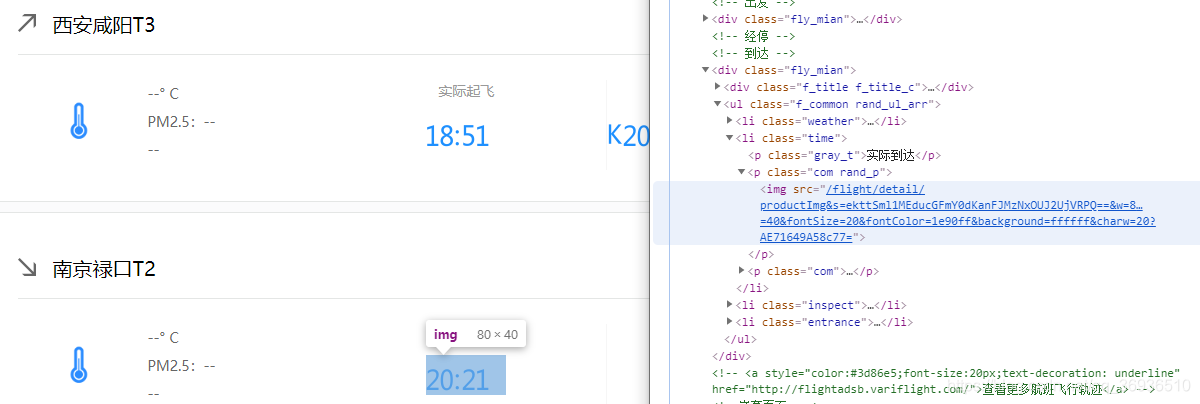 但其实可以找到数据源是如下的json,只需要将时间戳转换为本地时间就可以了。
但其实可以找到数据源是如下的json,只需要将时间戳转换为本地时间就可以了。 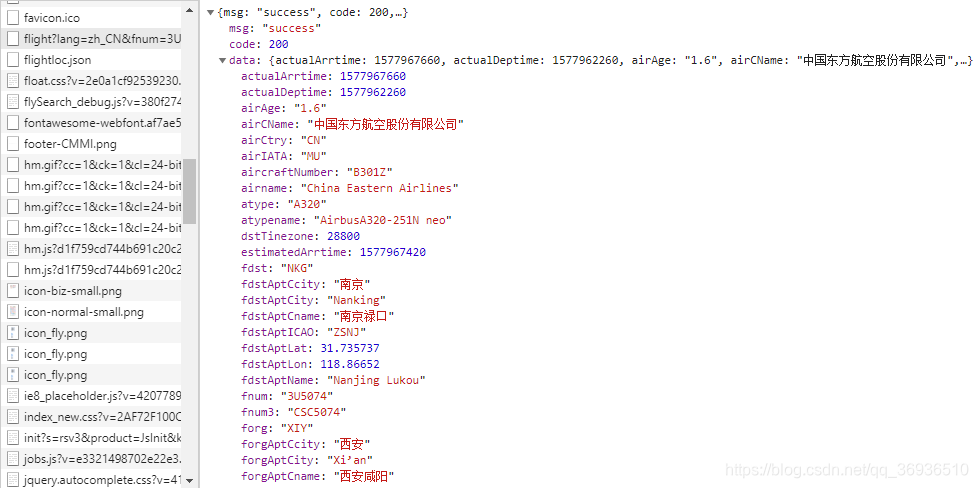 URL为:https://adsbapi.variflight.com/adsb/index/flight?lang=zh_CN&fnum=3U5074&time=1577960700&forg=XIY&fdst=NKG 观察URL可以发现需要四个参数,航班号,时间,出发地和目的地。正好,网页源代码中iframe的URL中就有这些参数,那后面的操作就很简单了。还需要注意网站有反爬机制,需要代理IP。
URL为:https://adsbapi.variflight.com/adsb/index/flight?lang=zh_CN&fnum=3U5074&time=1577960700&forg=XIY&fdst=NKG 观察URL可以发现需要四个参数,航班号,时间,出发地和目的地。正好,网页源代码中iframe的URL中就有这些参数,那后面的操作就很简单了。还需要注意网站有反爬机制,需要代理IP。
【本文地址】
今日新闻 |
推荐新闻 |