SQL SERVER 生僻字查询问题和关键字COLLATE |
您所在的位置:网站首页 › 查生僻字的app推荐 › SQL SERVER 生僻字查询问题和关键字COLLATE |
SQL SERVER 生僻字查询问题和关键字COLLATE
|
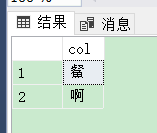
先说问题,生僻字查询的问题,有的时候我们的数据里包含一些生僻字,在查询用Like模糊匹配的时候,发现有的查询不准确,测试数据如下: --测试数据 if not object_id(N'Tempdb..#T') is null drop table #T Go Create table #T([col] nvarchar(21)) Insert #T select N'䱗'UNION SELECT N'啊' Go --测试数据结束如果这时候用Like查询,就会存在查询不准确的情况: Select * from #T WHERE col LIKE N'%䱗%'查询结果:
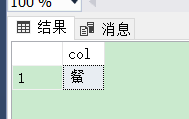
两个数据都查询出来了,这时候我们使用COLLATE关键字,加上Chinese_PRC_BIN可以解决该问题: Select * from #T WHERE col LIKE N'%䱗%' COLLATE Chinese_PRC_BIN结果:
这样就解决了这个生僻字查询的问题。
那么接下来我们说说问题原因和加的这个COLLATE Chinese_PRC_BIN 是什么意思。 生僻字由于在数据库中没有对应的编码,这样就会造成like的时候定位不到数据,所以解决这个问题也是从编码处入手,在排序的时候来做编码转换。 COLLATE简单来说就是用来定义排序规则的,具体详细介绍可以看官方文档https://docs.microsoft.com/zh-cn/sql/t-sql/statements/collations?view=sql-server-ver15 SQLSERVER的排序规则有很多,Chinese_PRC_BIN是一种排序规则,该规则分为两部分,其中Chinese_PRC_是指针对大陆简体字UNICODE的排序规则,BIN指的是二进制排序选项,这些关联选项有很多 ,例如: 选项说明区分大小写 (_CS)区分大写字母和小写字母。 如果选择此项,排序时小写字母将在其对应的大写字母之前。 如果未选择此选项,排序规则将不区分大小写。 即 SQL Server 在排序时将大写字母和小写字母视为相同。 通过指定 _CI,可以显式选择不区分大小写。区分重音 (_AS)区分重音字符和非重音字符。 例如,“a”和“ấ”视为不同字符。 如果未选择此选项,则排序规则将不区分重音。 即 SQL Server 在排序时将字母的重音形式和非重音形式视为相同。 通过指定 _AI,可以显式选择不区分重音。区分假名 (_KS)区分日语中的两种假名字符类型:平假名和片假名。 如果未选择此选项,则排序规则将不区分假名。 即 SQL Server 在排序时将平假名字符和片假名字符视为相同。 省略此选项是指定不区分假名的唯一方法。区分全半角 (_WS)区分全角字符和半角字符。 如果未选择此选项,SQL Server 会在排序时将同一字符的全角和半角形式视为相同。 省略此选项是指定不区分全半角的唯一方法上边列举了几个例子,如果想了解更多,可以到微软官网了解https://docs.microsoft.com/zh-cn/sql/relational-databases/collations/collation-and-unicode-support?view=sql-server-ver15,这里就不都贴上了。 以上就是查询生僻字和排序关键字COLLATE的介绍,欢迎指正交流。
写在最后(今天是个特殊的日子): 今天是1024程序员节日,1024不知道从什么时候开始成了我们的节日,成了这些穿着格子衬衫、头发稀疏、但正在做着一些伟大事情的人群狂欢的节日,所以在博客里,也要祝福所有正在改变世界的程序员,节日快乐,远离脱发-拒绝Bug,Happy 1024!!!
|
【本文地址】