|
zero-shot基本概念
首先通过一个例子来引入zero-shot的概念。假设我们已知驴子和马的形态特征,又已知老虎和鬣狗都是又相间条纹的动物,熊猫和企鹅是黑白相间的动物,再次的基础上,我们定义斑马是黑白条纹相间的马科动物。不看任何斑马的照片,仅仅凭借推理,在动物园一众动物中,我们也能够找到斑马。 上述例子中包含了一个推理过程,就是利用过去的知识(已知动物的描述),在脑海中推理出新对象的具体形态,从而能对新对象进行辨认。(如下图所示)ZSL就是希望能够模仿人类的这个推理过程,使得计算机具有识别新事物的能力。  如今十分火热的纯监督模型往往需要足够多的样本才能训练出足够好的模型,并且用熊猫训练出来的分类器,只能对熊猫进行分类,其他物种都无法识别,也无法进行特征的综合推理,这样的模型功能还有待完善。 ZSL就是希望我们的模型能够对其从没见过的类别进行分类,让机器具有推理能力,实现真正的智能。其中零次(Zero-shot)是指对于要分类的类别对象,一次也不学习。这样的能力听上去很具有吸引力,那么到底是怎么实现的呢? 假设我们的模型已经能够识别马,老虎和熊猫了,现在需要该模型也识别斑马,那么我们需要像爸爸一样告诉模型,怎样的对象才是斑马,但是并不能直接让模型看见斑马。所以模型需要知道的信息是马的样本、老虎的样本、熊猫的样本和样本的标签,以及关于前三种动物和斑马的描述。假设我们的模型已经能够识别马,老虎和熊猫了,现在需要该模型也识别斑马,那么我们需要像爸爸一样告诉模型,怎样的对象才是斑马,但是并不能直接让模型看见斑马。所以模型需要知道的信息是马的样本、老虎的样本、熊猫的样本和样本的标签,以及关于前三种动物和斑马的描述。,以一般的图片分类问题为例: (1)训练集数据X1及其标签Y1,包含了模型需要学习的类别(马、老虎和熊猫),这里和传统的监督学习中的定义一致; (2)测试集数据 X2及其标签 Y2,包含了模型需要辨识的类别(斑马),这里和传统的监督学习中也定义一致; (3)训练集类别的描述 A1,以及测试集类别的描述 A2;我们将每一个类别 Yi,都表示成一个语义向量ai的形式,而这个语义向量的每一个维度都表示一种高级的属性,比如“黑白色”、“有尾巴”、“有羽毛”等等,当这个类别包含这种属性时,那在其维度上被设置为非零值。对于一个数据集来说,语义向量的维度是固定的,它包含了能够较充分描述数据集中类别的属性。 在ZSL中,我们希望利用X1和Y1来训练模型,而模型能够具有识别X2的能力,因此模型需要知道所有类别的描述A1和A2。ZSL这样的设置其实就是上文中识别斑马的过程中,已知的条件。 实际上zero-shot就可以被定义为:利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集类别和测试集类别之间没有交集;期间需要借助类别的描述,来建立训练集和测试集之间的联系,从而使得模型有效。 如今十分火热的纯监督模型往往需要足够多的样本才能训练出足够好的模型,并且用熊猫训练出来的分类器,只能对熊猫进行分类,其他物种都无法识别,也无法进行特征的综合推理,这样的模型功能还有待完善。 ZSL就是希望我们的模型能够对其从没见过的类别进行分类,让机器具有推理能力,实现真正的智能。其中零次(Zero-shot)是指对于要分类的类别对象,一次也不学习。这样的能力听上去很具有吸引力,那么到底是怎么实现的呢? 假设我们的模型已经能够识别马,老虎和熊猫了,现在需要该模型也识别斑马,那么我们需要像爸爸一样告诉模型,怎样的对象才是斑马,但是并不能直接让模型看见斑马。所以模型需要知道的信息是马的样本、老虎的样本、熊猫的样本和样本的标签,以及关于前三种动物和斑马的描述。假设我们的模型已经能够识别马,老虎和熊猫了,现在需要该模型也识别斑马,那么我们需要像爸爸一样告诉模型,怎样的对象才是斑马,但是并不能直接让模型看见斑马。所以模型需要知道的信息是马的样本、老虎的样本、熊猫的样本和样本的标签,以及关于前三种动物和斑马的描述。,以一般的图片分类问题为例: (1)训练集数据X1及其标签Y1,包含了模型需要学习的类别(马、老虎和熊猫),这里和传统的监督学习中的定义一致; (2)测试集数据 X2及其标签 Y2,包含了模型需要辨识的类别(斑马),这里和传统的监督学习中也定义一致; (3)训练集类别的描述 A1,以及测试集类别的描述 A2;我们将每一个类别 Yi,都表示成一个语义向量ai的形式,而这个语义向量的每一个维度都表示一种高级的属性,比如“黑白色”、“有尾巴”、“有羽毛”等等,当这个类别包含这种属性时,那在其维度上被设置为非零值。对于一个数据集来说,语义向量的维度是固定的,它包含了能够较充分描述数据集中类别的属性。 在ZSL中,我们希望利用X1和Y1来训练模型,而模型能够具有识别X2的能力,因此模型需要知道所有类别的描述A1和A2。ZSL这样的设置其实就是上文中识别斑马的过程中,已知的条件。 实际上zero-shot就可以被定义为:利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集类别和测试集类别之间没有交集;期间需要借助类别的描述,来建立训练集和测试集之间的联系,从而使得模型有效。
zero-shot存在的问题
领域漂移问题(domain shift problem) -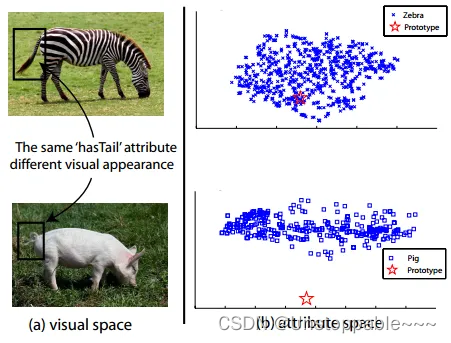 如上图所示,斑马和猪都有尾巴,因此在它的类别语义表示中,“有尾巴”这一项都是非0值,但是两者尾巴的视觉特征却相差很远。如果斑马是训练集,而猪是测试集,那么利用斑马训练出来的模型,则很难正确地对猪进行分类。枢纽点问题(Hubness problem) 将高维向量投影到低维空间时,会出现中心性问题。这样的投影减少了方差,从而导致投影点聚集成中心点。解决零样本识别问题的最常用方法之一是学习从高维视觉空间到低维语义空间的投影函数。然而,这会导致在语义空间中形成投影中心点,而这些中心点往往更接近于数量占比大的类的语义属性向量。由于在测试时,我们在语义空间中使用最近邻搜索来找到预测类别的,所以 Hubness 问题势必会降低模型的性能。语义间隔(semantic gap) 样本的特征往往是视觉特征,比如用深度网络提取到的特征,而语义表示却是非视觉的,这直接反应到数据上其实就是:样本在特征空间中所构成的流型与语义空间中类别构成的流型是不一致的。(如下图所示) 如上图所示,斑马和猪都有尾巴,因此在它的类别语义表示中,“有尾巴”这一项都是非0值,但是两者尾巴的视觉特征却相差很远。如果斑马是训练集,而猪是测试集,那么利用斑马训练出来的模型,则很难正确地对猪进行分类。枢纽点问题(Hubness problem) 将高维向量投影到低维空间时,会出现中心性问题。这样的投影减少了方差,从而导致投影点聚集成中心点。解决零样本识别问题的最常用方法之一是学习从高维视觉空间到低维语义空间的投影函数。然而,这会导致在语义空间中形成投影中心点,而这些中心点往往更接近于数量占比大的类的语义属性向量。由于在测试时,我们在语义空间中使用最近邻搜索来找到预测类别的,所以 Hubness 问题势必会降低模型的性能。语义间隔(semantic gap) 样本的特征往往是视觉特征,比如用深度网络提取到的特征,而语义表示却是非视觉的,这直接反应到数据上其实就是:样本在特征空间中所构成的流型与语义空间中类别构成的流型是不一致的。(如下图所示) 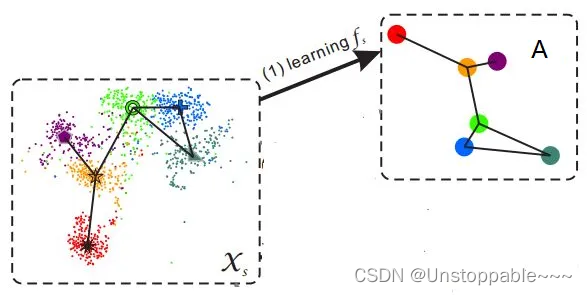
|