【建议收藏】机器学习数据预处理(四) |
您所在的位置:网站首页 › 构造函数的特征 › 【建议收藏】机器学习数据预处理(四) |
【建议收藏】机器学习数据预处理(四)
|
📌特征含义类型
非匿名特征:此部分的特征一般都带有特定的意义,我们可以根据不同的意义来挑选特征,构造特征。匿名特征:不知道特征的特定意义,只能够进行随机组合,查看不同特征的相关度来进行构造特征。
📌特征类型
类别特征:表示某特征的固定类别。
定类:只做单纯分类,不存在相对大小的特征。例如,当我们为性别编号为 男:1,女:2时,并不意味着其间存在大小的关系,而只是作为类别的区别。定序:有相对大小的特征。例如,当我们对成绩编码时 90-100:A,90-60:B时,有些时候表示其存在一定的大小顺序。 数值特征/定量特征:表示某特征的连续数值。
定类:存在某些特定类别。定序:存在一定顺序。定距:存在固定距离。定比:存在某些固定比值。 时间特征:表示某些特征的时间特性。
📌特征构造
🏷️类别特征
📄类别特征编码
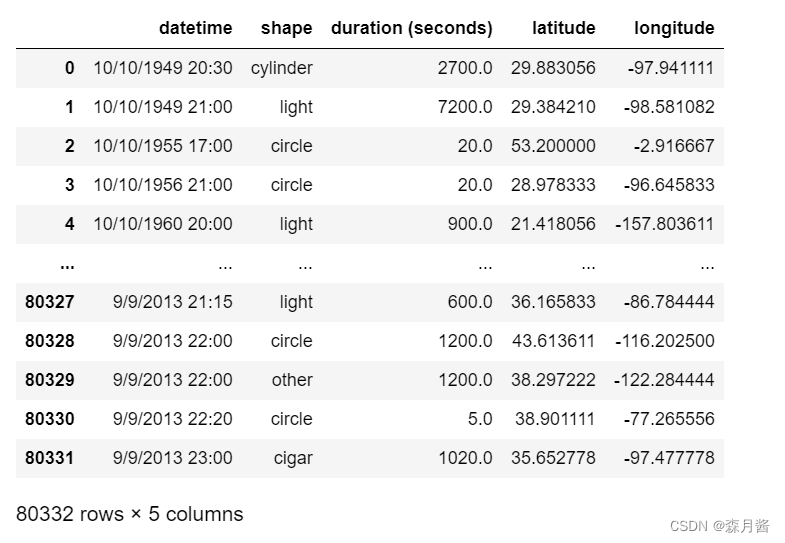
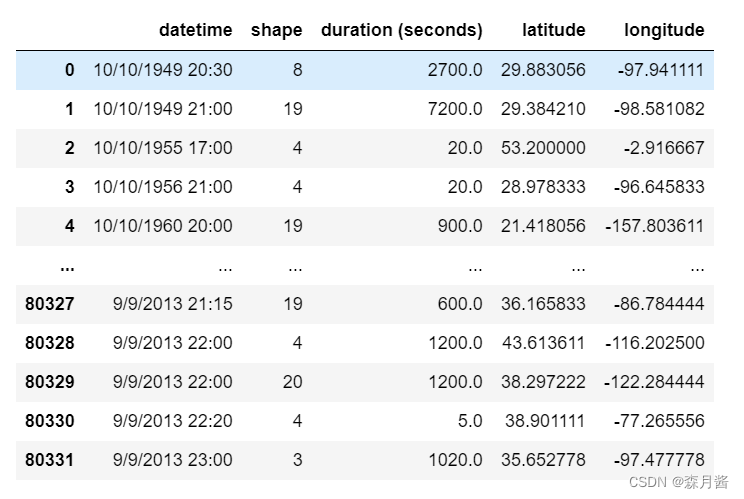
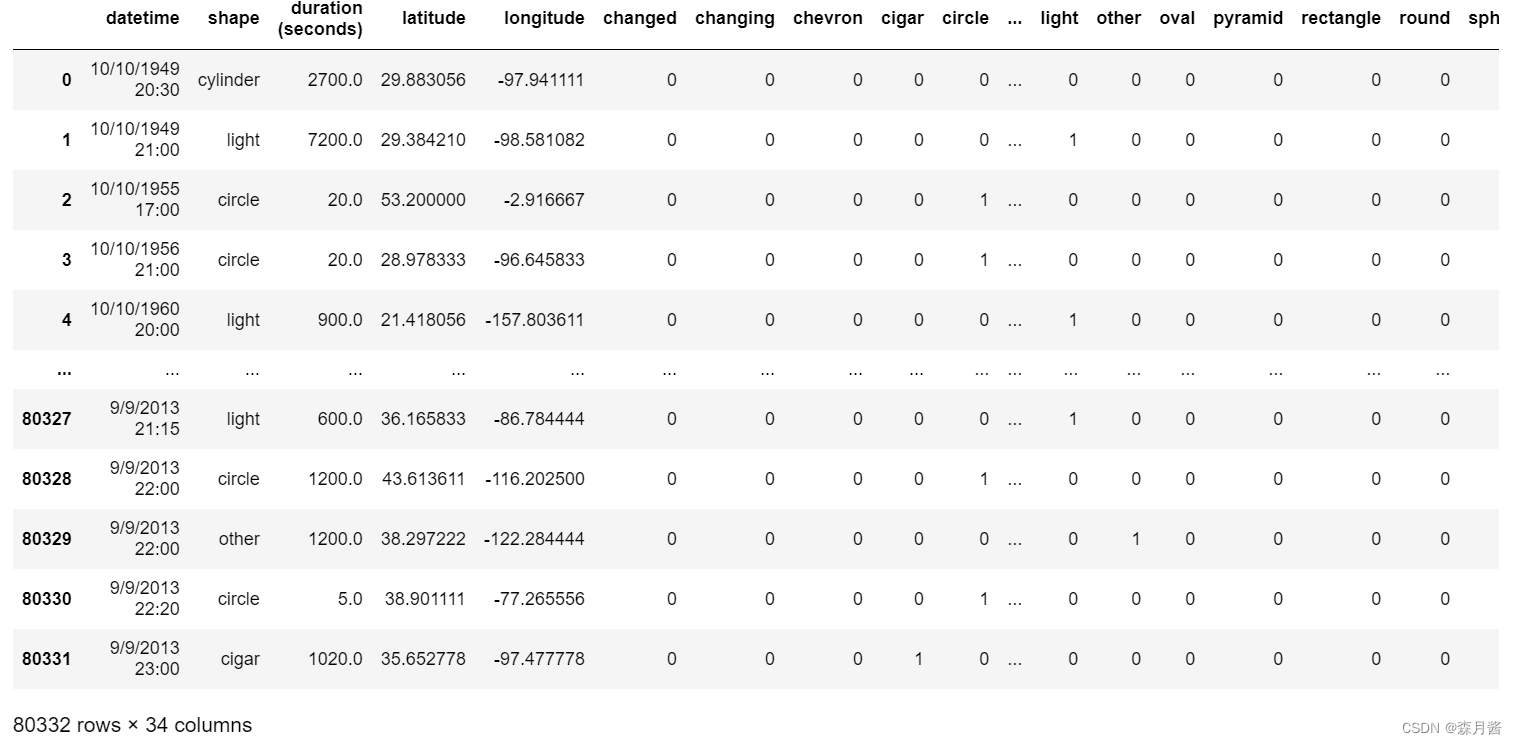
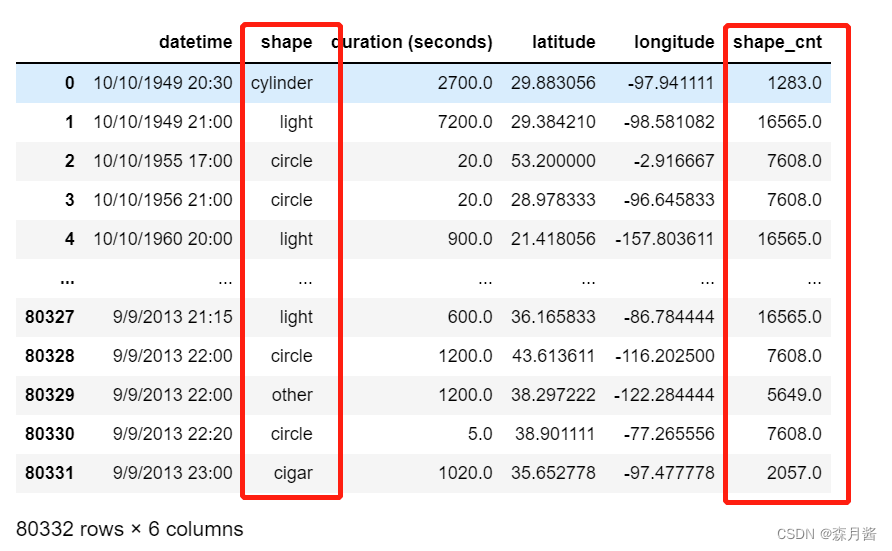
类别编码能够将object的变量准换位数值类型,例如若在数据集中性别的编码为:男:MAN,女:WOMAN,则我们首先需要将其转换为数值类型。 这里我们使用某UFO的数据集作示例,其中存在一个属性为shape表示UFO的形状,我们拟为其编码,编码前为: 类别编码结果如下: 但要注意,进行类别特征编码的后的结果通常不能够直接使用,因为这样会间接的引入顺序。 当类别特征存在一定的大小顺序时,类别特征可以进行灵活运用。例如,某些群体的年纪分为幼年,青年,老年等。 📄独立热编码对每个类别使用二进制编码,使用二进制创建新列,以表示特定行是否属于该类别。使用该方法将会对我们的数据升维,要注意我们的数据是否是稀疏的,否则维度过大且效果也不会很好。 我们接着以上述的数据为例,对shape进行独立热编码。 hot = pd.get_dummies(data['shape'].values) pd.concat([data,hot], axis=1)结果如下: 通过计算特征变量中每个值出现次数来表示该特征信息,通常情况下的问题使用此种方法提取特征都有助于帮助我们更好的构建模型。 data['shape_cnt'] = data['shape'].map(data['shape'].value_counts())
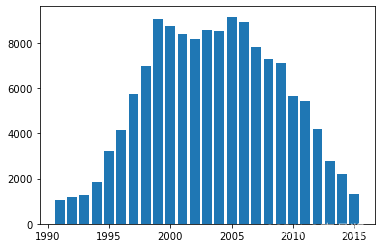
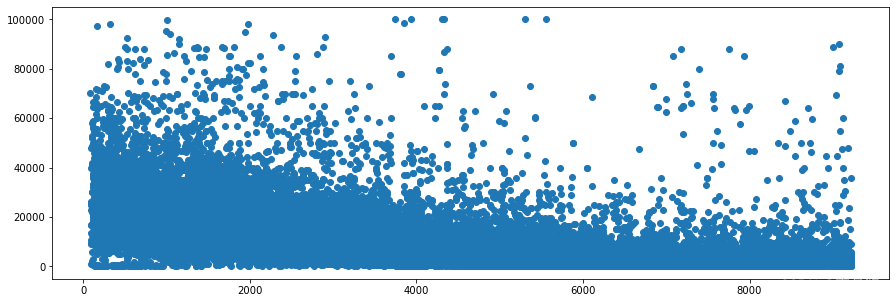
结合预测目标和存在的特征对特征进行构造。 from category_encoders import TargetEncoder encoder= TargetEncoder(cols=['power']) training_set = encoder.fit_transform(train_data['power'],train_data['price'])结果如下: 在某些情况下,我们只关注特征的有无,并不关心特征的具体大小。 train_data['power_on'] = (train_data['power'] > 0) * 1对某列的二值化结果如下: 对多个特征做组合,做差,积等,能够捕获特征间的交互作用。 例如,当我们需要评估一个人胖与瘦是不能够只关注其身高和体重,此时我们就可以根据现有的数据构造BMI指数的特征。 🏷️时间特征在特征中包含时间特征时,我们可以对其做相应的处理。 📄基础周期特征根据我们的先验知识,我们可以对年月日进行拆解,并观察其相对于我们的预测目标的关联情况。 下面我们以某二手车数据为例,统计其创建时间与最终出售价格的周期性: # 转换时间格式 train_data['regDate'] = pd.to_datetime(train_data['regDate'], format='%Y%m%d', errors='coerce') train_data['creatDate'] = pd.to_datetime(train_data['creatDate'], format='%Y%m%d', errors='coerce') plt.bar(train_data['regDate'].dt.year.value_counts().index, train_data['regDate'].dt.year.value_counts().values)年与销售量的关系如下: 除只关注年的销量之外,我们还可以关注不同时间周期的时间特征。例如,是否是节假日,是否为不同的节日等。利用我们的先验知识对数据集进行验证。 📄时间差我们可以根据数据类型的不同构造相应的相对时间差,例如二手车数据集中销售时间和车辆注册时间的时间差能够代表车辆的使用时间。 train_data['regDate'] = pd.to_datetime(train_data['regDate'], format='%Y%m%d', errors='coerce') train_data['creatDate'] = pd.to_datetime(train_data['creatDate'], format='%Y%m%d', errors='coerce') train_data['used_time'] = (train_data['creatDate'] - train_data['regDate']).dt.days构造出的特征与预测目标的结果如下所示,可以看出随着使用时间的不断增长,我们的预测目标价格也在不断减小。 本次列举了两类多种构造特征的方式,在解决问题的过程中要灵活应用。 如果对相关内容感兴趣,可以点击我的其他文章: 【建议收藏】机器学习数据预处理(一)——缺失值处理方法(内附代码)【建议收藏】机器学习数据预处理(二)——异常值处理方法(内附代码)【建议收藏】机器学习数据预处理(三)——数据分桶及数据标准化(内附代码)【建议收藏】机器学习数据预处理(四)——特征构造(内附代码)【建议收藏】机器学习数据预处理(五)——特征选择(内附代码)【建议收藏】机器学习模型构建(一)——建模调参(内附代码)【建议收藏】机器学习模型构建(二)——模型融合(内附代码) |


【本文地址】
今日新闻 |
推荐新闻 |