|
预处理理论
目录
预处理理论1、特征工程2、数据清洗(1)数据样本采集(抽样)(2)异常值(空值)处理
3、特征预处理(1)特征选择特征选择有三个切入思路①过滤思想②包裹思想③嵌入思想
(2)特征变换①对值化②离散化③归一化(Min-Max)④标准化⑤数值化⑥正规化(规范化)
(3)特征降维(4)特征衍生
4、HR表的特征预处理
1、特征工程
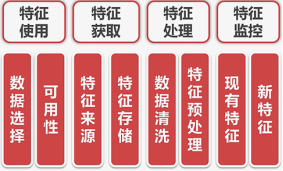 数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。特征工程一般包括特征使用、特征获取、特征处理、特征监控四大方面。 特征使用包括:数据的选择和数据的可用性判断。这两方面主要关注点放在特征的元数据上。数据选择是分析和我们目标最相关的数据都有哪些,这些数据如何获取。数据的可用性,这里说的可用性是指数据特征是否能持续输出,比如我们需要建立模型,用到的数据是实时更新的,那么只能获取到历史数据是远远不够的。 特征获取,数据源已经确定了,下一步就是确定与存储数据的过程,这个过程也分两个。一个是特征来源的确认即我们可能需要的特征来自哪张表或者哪个文件,是不是有的特征来自于两张表等。另一个是特征的规整与存储,比如说这些特征来自于不同的文件,那么就要把不同地方的特征进行规整,存储在方便以后使用的媒介中。 特征处理(特征的预处理过程),目的是指数据属性和特征能尽可能大的发挥作用体现差别。其中又分为数据清洗和特征预处理。 特征监控:如果我们建立了模型,要长期使用,随着时间的流逝,可能的数据集会越来越多,同时在更多未知的情况下,模型的效果可能会有变化。参数也可能需要重新校正,这需要我们对模型,对特征的契合程度进行不断的监控。这其中分为两个方向,一个是针对现有特征看是不是依然对我们的数据任务有积极的作用,另一个方向就是探寻新的特征,是不是有助于提高效果,或者更能代表我们的数据任务目标。所以数据模型不是一成不变的,它也是有进化的。 数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。特征工程一般包括特征使用、特征获取、特征处理、特征监控四大方面。 特征使用包括:数据的选择和数据的可用性判断。这两方面主要关注点放在特征的元数据上。数据选择是分析和我们目标最相关的数据都有哪些,这些数据如何获取。数据的可用性,这里说的可用性是指数据特征是否能持续输出,比如我们需要建立模型,用到的数据是实时更新的,那么只能获取到历史数据是远远不够的。 特征获取,数据源已经确定了,下一步就是确定与存储数据的过程,这个过程也分两个。一个是特征来源的确认即我们可能需要的特征来自哪张表或者哪个文件,是不是有的特征来自于两张表等。另一个是特征的规整与存储,比如说这些特征来自于不同的文件,那么就要把不同地方的特征进行规整,存储在方便以后使用的媒介中。 特征处理(特征的预处理过程),目的是指数据属性和特征能尽可能大的发挥作用体现差别。其中又分为数据清洗和特征预处理。 特征监控:如果我们建立了模型,要长期使用,随着时间的流逝,可能的数据集会越来越多,同时在更多未知的情况下,模型的效果可能会有变化。参数也可能需要重新校正,这需要我们对模型,对特征的契合程度进行不断的监控。这其中分为两个方向,一个是针对现有特征看是不是依然对我们的数据任务有积极的作用,另一个方向就是探寻新的特征,是不是有助于提高效果,或者更能代表我们的数据任务目标。所以数据模型不是一成不变的,它也是有进化的。
2、数据清洗
(1)数据样本采集(抽样)
数据抽样注意事项:样本要具备代表性;样本比例要平衡以及样本不平衡时如何处理;考虑全量数据。
(2)异常值(空值)处理
识别异常值和重复值:Pandas: isnull()/duplicated() 直接丢弃(包括重复数据): Pandas: drop()/dropna()/drop_duplicated() 如果异常值比较多,可以将是否有异常当作一个新的属性,替代原值,也可以通过集中值(除了异常值之外的均值,众数等)指代,还可以用边界值指代:Pandas: fillna() 连续型数据还可以通过插值的方法来填充异常值: Pandas: interpolate()—Series
#数据清洗
#异常值(空值)处理
import pandas as pd
import numpy as np
df=pd.DataFrame({"A":["a0","a1","a1","a2","a3","a4"],
"B":["b0","b1","b2","b2","b3",None],
"C":[1,2,None,3,4,5],
"D":[0.1,10.2,11.4,8.9,9.1,12],
"E":[10,19,32,25,8,None],
"F":["f0","f1","g2","f3","f4","f5"]})
print(df)
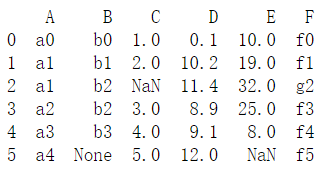
#识别空值
df.isnull()
#True的都是空值
#有空值的行都被去掉了
df.dropna()
#识别A的重复值,重复值为true
df.duplicated(["A"])
#duplicated(["A","B"])表示只有A、B在相同的行数间都重合时才是重合的
df.duplicated(["A","B"])
#去掉重复值
df.drop_duplicates(["A"])
#keep表示重复时保留哪一个
#keep=first,last,false(全去掉)
#inplace默认False,表示不会更改原表,反之
df.drop_duplicates(["A"],keep="last")
#标注异常值
df.fillna("b*")
#集中值进行指代
df.fillna(df["E"].mean())
#插值interpolate()必须是对series进行操作
df["E"].interpolate()
#(1+4)/2=2.5,返回相邻两个值的均值
pd.Series([1,None,4,5,20]).interpolate()
#D属性除去第一个值外其他值都是在8~12之间,所以第一个值可能是异常值
#利用四分位数上下界的方法来去掉异常值
#剔除异常值的方法,上下界之间的为正常值,其余为异常值
q_low = df["D"].quantile(q=0.25)
q_high = df["D"].quantile(q=0.75)
q_interval = q_high - q_high
k = 1.5
df[df["D"] > q_low - k * q_interval][df["D"] |