Linux 性能监控与故障排查:主要性能指标说明及监控方法 |
您所在的位置:网站首页 › 服务器性能测试指标有哪些 › Linux 性能监控与故障排查:主要性能指标说明及监控方法 |
Linux 性能监控与故障排查:主要性能指标说明及监控方法
|
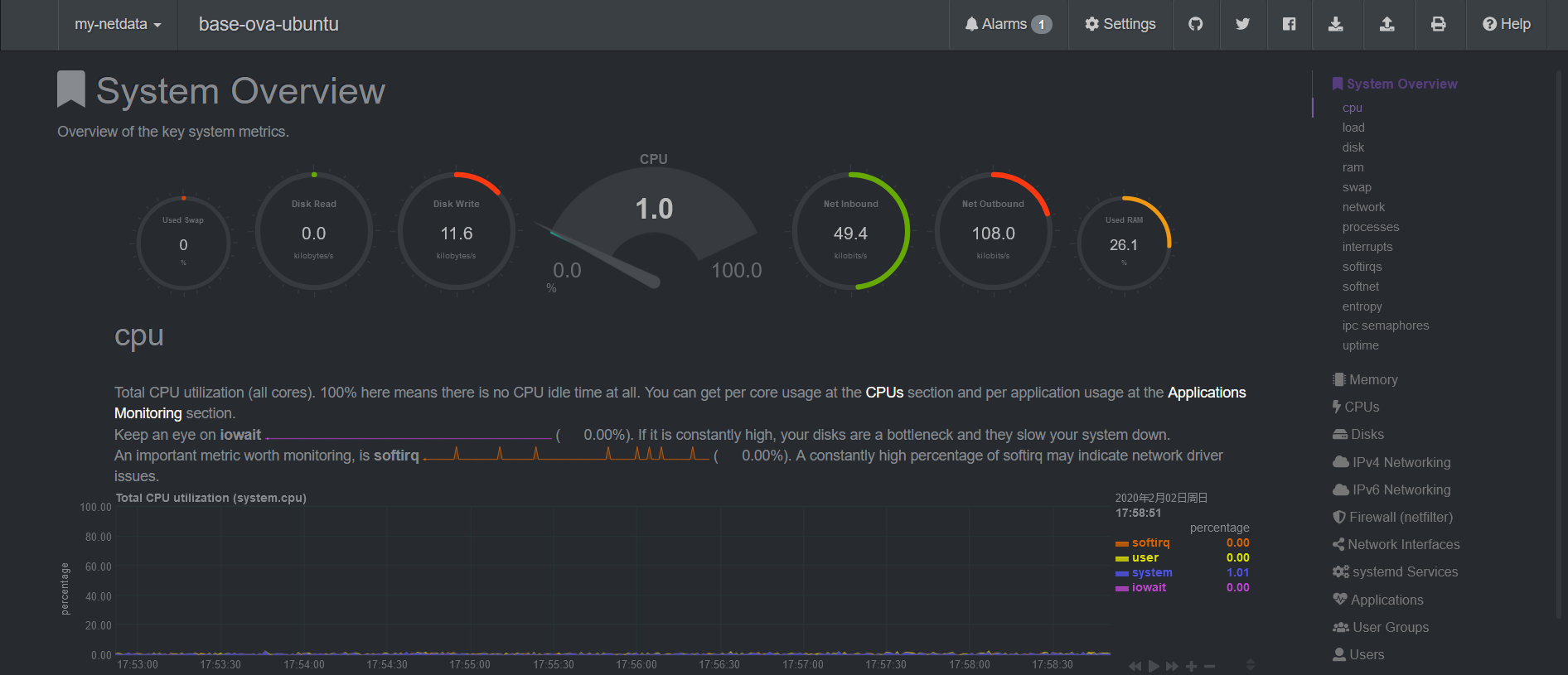
一台 Linux 服务器的四类指标如下: CPU:使用率、平均负载(load average) RAM:used | free | buffer/cache | avaliable Disk:空闲容量大小、IO 状态 Network:网速、延迟、丢包率等下面详细地说明各项系统参数的意义、它们的正常状态,以及出现异常时如何进行故障排查。 零、前置准备很多的监控工具 Ubuntu/CentOS 都不自带,需要手动安装,在开始前我们最好先把所有可能用得上的监控工具都装上。(它们都很小,基本不占空间) # ubuntu/debian sudo apt-get install \ sysstat iotop fio \ nethogs iftop # centos # 需要安装 epel 源,很多监控工具都在该源中! # 也可使用[阿里云 epel 源](https://developer.aliyun.com/mirror/epel) sudo yum install epel-release sudo yum install \ sysstat iotop fio \ nethogs iftop 大一统的监控工具下面介绍两个非常方便的大一统监控工具,它们将一台服务器的所有监控数据汇总到一个地方,方便监控。 多机监控推荐用 prometheus+grafana,不过这一套比较吃性能,个人服务器没必要上。 NetData: 极简安装、超详细超漂亮的 Web UI这里只介绍单机监控。NetData 也支持中心化的多机监控,待进一步研究。netdata 也可以被用作 prometheus 的 exporter. NetData 我要吹爆!它是 Github 上最受欢迎的系统监控工具,目前已经 44.5k star 了。 CPU 占用率低(0.1 核),界面超级漂亮超级详细,还对各种指标做了很详细的说明,安装也是一行命令搞定。相当适合萌新运维。 默认通过 19999 端口提供 Web UI 界面。
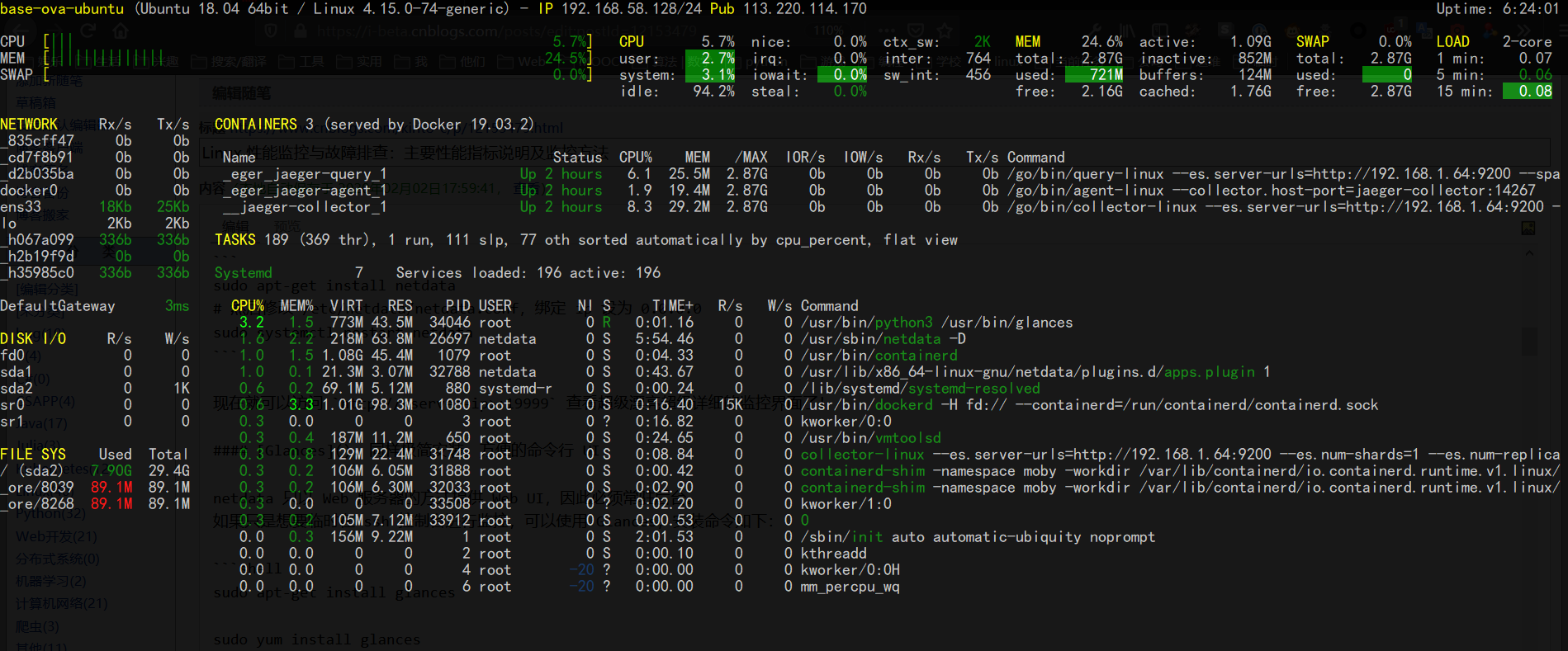
现在就可以访问 http://:19999 查看超级漂亮超级详细的监控界面了! Glances: 同样极简安装、方便的命令行 UInetdata 只以 Web 服务器的方式提供 Web UI,因此必须常驻后台。 如果只是想要临时在 ssh 控制台进行监控,可以使用 Glances,安装命令如下: sudo apt-get install glances sudo yum install glances启动命令:glances,可提供 CPU、RAM、NetWork、Disk 和系统状态等非常全面的信息。(只是不够详细)
glances 同样提供中心化的多机监控,还有 Web 界面,但是和 netdata 相比就有些简陋了。不作介绍。 一、CPU 指标 1. CPU 使用率CPU 使用率即 CPU 运行在非空闲状态的时间占比,它反应了 CPU 的繁忙程度。使用 top 命令我们可以得到如下信息: %Cpu(s): 0.0 us, 2.3 sy, 0.0 ni, 97.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st us(user):表示 CPU 在用户态运行的时间百分比,通常用户态 CPU 高表示有应用程序比较繁忙。典型的用户态程序包括:数据库、Web 服务器等。 sy(sys):表示 CPU 在内核态运行的时间百分比(不包括中断),通常内核态 CPU 越低越好,否则表示系统存在某些瓶颈。 ni(nice):表示用 nice 修正进程优先级的用户态进程执行的 CPU 时间。nice 是一个进程优先级的修正值,如果进程通过它修改了优先级,则会单独统计 CPU 开销。 id(idle):表示 CPU 处于空闲态的时间占比,此时,CPU 会执行一个特定的虚拟进程,名为 System Idle Process。 wa(iowait):表示 CPU 在等待 I/O 操作完成的时间占比,通常该指标越低越好,否则表示 I/O 可能存在瓶颈,需要用 iostat 等命令做进一步分析。 iowait 只考虑 Synchronous File IO,It does NOT count time spent waiting for IPC objects such as sockets, pipes, ttys, select(), poll(), sleep(), pause() etc. hi(hardirq):表示 CPU 处理硬中断所花费的时间。硬中断是由外设硬件(如键盘控制器、硬件传感器等)发出的,需要有中断控制器参与,特点是快速执行。 si(softirq):表示 CPU 处理软中断所花费的时间。软中断是由软件程序(如网络收发、定时调度等)发出的中断信号,特点是延迟执行。 st(steal):表示 CPU 被其他虚拟机占用的时间,仅出现在多虚拟机场景。如果该指标过高,可以检查下宿主机或其他虚拟机是否异常。 2. 平均负载(Load Average)top 命令的第一行输出如下: top - 21:11:00 up 8 min, 0 users, load average: 0.52, 0.58, 0.59其中带有三个平均负载的值,它们的意思分别是** 1 分钟(load1)、5 分钟(load5)、15 分钟(load15)内系统的平均负载**。 平均负载(Load Average)是指单位时间内,系统处于 可运行状态(Running / Runnable) 和 不可中断态 的平均进程数,也就是 平均活跃进程数。 我们知道实际上一个 CPU 核只能跑一个进程,操作系统通过分时调度提供了多进程并行的假象。所以当平均负载(平均活跃进程数)不大于 CPU 逻辑核数时,系统可以正常运转。 如果平均负载超过了核数,那就说明有一部分进程正在活跃中,但是它却没有使用到 CPU(同一时间只能有 1 个进程在使用 CPU),这只可能有两个原因: 这部分进程在排队等待 CPU 空闲。 这部分 CPU 在进行 IO 操作。不论是何种状况,都说明系统的负载过高了,需要考虑降负或者升级硬件。 理想状态下,系统满负荷工作,此时平均负载 = CPU 逻辑核数(4核8线程 CPU 有8个逻辑核)。但是,在实际生产系统中,不建议系统满负荷运行。通用的经验法则是:平均负载 |
【本文地址】
今日新闻 |
推荐新闻 |