词法分析(三):有限自动机DFA与NFA |
您所在的位置:网站首页 › 有限指什么 › 词法分析(三):有限自动机DFA与NFA |
词法分析(三):有限自动机DFA与NFA
|
词法分析概述 有限自动机(FA)有限自动机是对状态图的形式化描述 也就是说,有限自动机可以等价地表示为状态图,一个状态图也可以表示成等价的FA 有限自动机(Finite Automata)即FA 有限自动机分为: 确定有限自动机(Deterministic Finite Automata) 非确定有限自动机(Nondeterministic Finite Automata) 确定有限自动机(DFA)确定有限自动机 M 是一个五元式 M =(S,Σ,f,S0,F),其中: S:有穷状态集 Σ:输入字母表(有穷) f :状态转换函数,即状态转换图中的弧,S×Σ→S的单值部分映射, f(s,a)=s’,s是现态,输入字符a后,到达s’态 "单值"是说确定的s,a对应唯一的s’ "部分"是说,有些状态(终态)可能与任何字符均不存在映射 S0:唯一的初态 F:终态集(可空) 看下面一个例子: DFA M =({0,1,2,3},{a,b},f,0,{3}),其中f为 f(0,a)=1 f(0,b)=2 f(1,a)=3 f(1,b)=2 f(2,a)=1 f(2,b)=3 f(3,a)=3 f(3,b)=3 f 画成状态转换矩阵就是酱紫 ab012132213333有没有一点熟悉? 没错,就是表驱动法实现状态转换图时的状态表 DFA与状态转换图将 M 用状态转换图表示 画出所有状态: 注意: 由DFA的定义,DFA的状态图有且仅有一个初态, 同一个状态发出的弧上的字符不重复(单值映射,这也是DFA中D含义) 对于Σ*上的任何字α,若存在一条由初态到某一终态的道路,且这条通路上所有弧上的字符连接成的字为α,则称字α为DFA M 所接受/识别 DFA M 所识别的字的全体记为L(M) 呐,实现一个DFA即是实现与其等价的状态图 状态图的实现参见 词法分析(一):状态转换图 非确定有限自动机(NFA)NFA的理论研究诞生了一个图灵奖 非确定有限自动机 M 是一个五元式 M = (S,Σ,f,S0,F),其中: S:有穷状态集 Σ:输入字母表(有穷) f :状态转换函数,即状态转换图中的弧,S×Σ*→2S的部分映射, (2S即S的幂集,是由S的所有子集组成的集合,2S = { A|A⊆S }) f(s,a)=S’,s是现态,输入字符a后,可到达状态集S’里的任何一个状态,S’ ⊆ 2S 不保证是单值映射,因此是NFA(NFA的N) 另外需要注意的是,弧接受的可以是字,甚至是甚至 S0:非空的初态集 F:终态集(可空) 对于Σ*上的任何字α,若存在一条由初态到某一终态的道路,且这条通路上所有弧上的字符/字连接成的字为α,则称字α为NFA M 所接受/识别 NFA M 所识别的字的全体记为L(M) NFA与DFANFA相对于DFA的不同 NFA可以有多个初态弧上的标记可以是Σ*上的字,甚至可以是正规式,而不一定是单个字符同一状态上射出的弧上的字可以重复,也就是说接受同一个字,可以到达多个状态从定义上可以看出,DFA是NFA的特例 将NFA表示为状态转换图与DFA相似
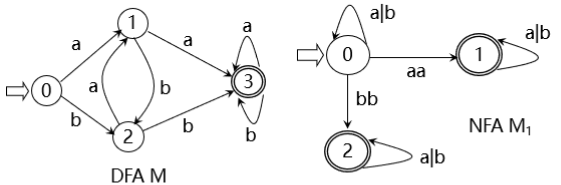
有限自动机的等价:对于任意两个有限自动机 M 和 M1,若L(M)=L(M1),则称M与M1等价 上图中的 L(M)=L(M1) = { 含有aa或bb的字 } DFA M 与 NFA M1等价 自动机理论中的一个重要结论:判定两个自动机的等价性的算法是存在的 (这里空白太小,写不下,略 ) 既然DFA是NFA的特例,凡是DFA可以识别的字集,都可以通过NFA识别, 那么NFA的描述能力是不是比DFA强呢? 即 是否存在某些字的集合,只能用NFA描述,而无法通过DFA描述? 答案是否定的 自动机理论指出:DFA与NFA在识别能力上是相同的 对于每一个NFA M,存在一个DFA M’,使得L(M)=L(M’) 由于NFA与DFA的不同,DFA易于程序实现,NFA易于词法规则的人工设计 那么在设计编程语言时,就需要将NFA转化为等价的DFA 而对于每一个NFA M,存在一个DFA M’,使得L(M)=L(M’) 也就是说 任何一个NFA都可以转换为等价的DFA 下面给出NFA转化为等价的DFA的方法,同时也是对于上面这条定理的构造性证明 首先看NFA与DFA的区别 FA\区别初态映射弧接受的内容DFA唯一单值映射字符NFA初态集(可以不唯一)映射结果也是状态集字(字符)、正规式只要等价地消除这三个差别,NFA就转化为了DFA 接下来以下面这个识别含有aa或bb的字的NFA为例,给出构造等价的DFA的过程 有NFA M = (S,Σ,f,S0,F),其状态转换图如下 由于增加的所有弧都是ε弧,所以改造后的状态图识别的字集没有改变,这种变换是等价变换 那为什么也要增加唯一的终态呢? (词法分析中,FA用于判断单词符号是否属于某个正规集(比如某个语言的所有单词集合),以正规式的角度来看,终态应该只有一个,到达终态说明被正规式识别,属于该正规集,未达到终态说明不被正规式所接受 ) 接下来将弧上的字/正规式替换为字符 若状态 i 到状态 j 弧上的字α由字符α1α2组成,在两状态间引入新的状态 k, 将α分为α1与α2两段弧如下图所示 使用按照将字拆解为字符的变换方法,可以得到下面的结果 该方法称为子集法: 按字符将起始状态集与到达状态集抽象为状态,从而等价地化为单值映射, ε弧按照语义被吸收,由 ε-closure 运算去除 首先定义 ε-closure 运算: 设 I 是状态集的一个子集,则 I 的 ε-闭包 ε-closure(I) 为 若状态s∈I,则s∈ε-closure(I) 若状态s∈I,则从s出发经过任意条 ε弧可以到达的任何状态s’,都属于ε-closure(I) 再定义Ia运算: 设a为Σ中的一个字符,定义Ia=ε-closure(J),其中, J为I中的某个状态出发经过一条a弧而到达的状态集合,Ia即是为这样的集合作ε-闭包 以下图的NFA为例,说明ε-闭包及Ia运算 在下图NFA中使用子集法进行确定化 这张表实际上就是状态集 I 接收字符 i 后到达状态集 Ii,描述了状态集间的单值映射 将每个状态集视为新的状态,该表即为一个状态转换矩阵 这个状态转换矩阵就是一个新的FA,而且是一个DFA 其中含有原先初态X的状态集为新的初态,含有原来任何一个终态的状态集都是新的终态 ab012132214335464564635这个表是不是也很熟悉? 斯巴拉西!DFA有辽! 画成状态图! 那么,现在的词法分析的理论已经是下面酱紫了 其实有一个问题 左边是子集法由NFA确定化得到的DFA,右边是我们之前见过的DFA 大家都是识别含有aa或bb的串的DFA,为啥子集法构造出来的就复杂些呢? 这里又有了新的姿势,DFA的化简,或者说最小化 这篇的内容有点多了,下一篇 词法分析(四):DFA的化简 2019/7/23 |
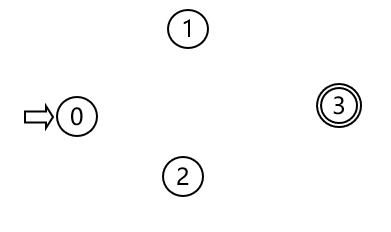 将 f 表示为弧
将 f 表示为弧 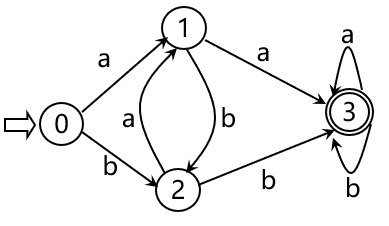 okk,DFA M 就这样等价地表示为状态图了
okk,DFA M 就这样等价地表示为状态图了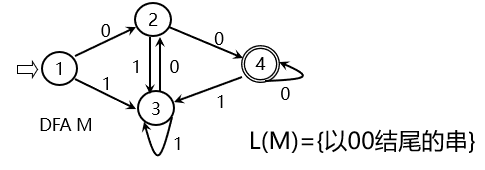
 DFA与NFA的关系
DFA与NFA的关系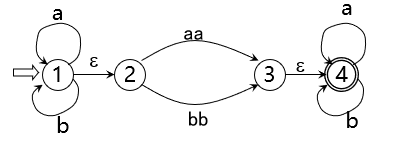 将此状态转换图做如下改造:
将此状态转换图做如下改造: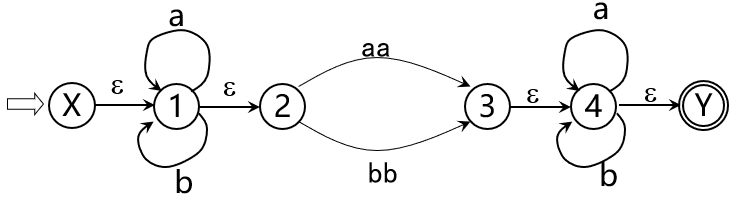 此时的M具有了唯一的初态
此时的M具有了唯一的初态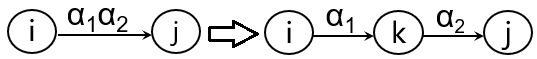
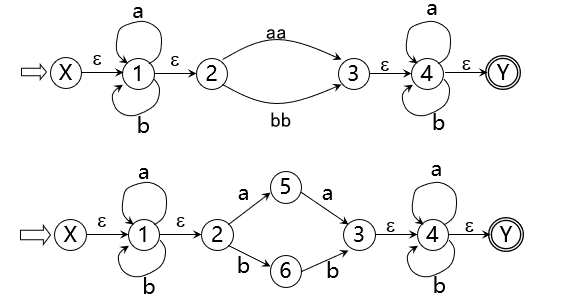 最后只需将NFA确定化,即将NFA中的 f 转化为DFA中的 S×Σ→S的单值映射, 包括化为单值映射、去除ε弧(Σ) 好了,正餐终于到了,下个小节来讲NFA的确定化
最后只需将NFA确定化,即将NFA中的 f 转化为DFA中的 S×Σ→S的单值映射, 包括化为单值映射、去除ε弧(Σ) 好了,正餐终于到了,下个小节来讲NFA的确定化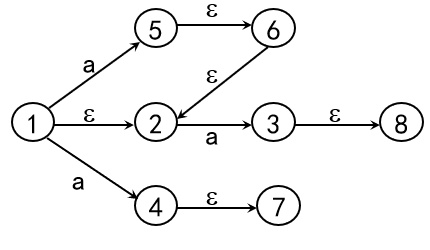 ε-closure({1}) = {1,2} 记 I = {1,2},则 Ia= ε-closure({5,4,3}) = {5,4,3,6,2,7,8}
ε-closure({1}) = {1,2} 记 I = {1,2},则 Ia= ε-closure({5,4,3}) = {5,4,3,6,2,7,8}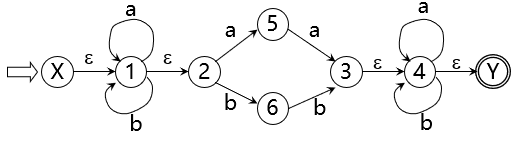 如下表,表头为参与计算的状态集 I,各字符的运算结果 Ii,其中i∈Σ 每个计算出的状态集再进行 Ii 的运算、 因为Σ为有限集,所以这张表也是有限的
如下表,表头为参与计算的状态集 I,各字符的运算结果 Ii,其中i∈Σ 每个计算出的状态集再进行 Ii 的运算、 因为Σ为有限集,所以这张表也是有限的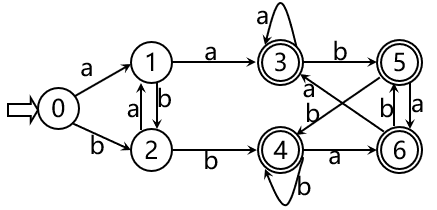 不难看出,这就是识别含有aa或bb的字的DFA
不难看出,这就是识别含有aa或bb的字的DFA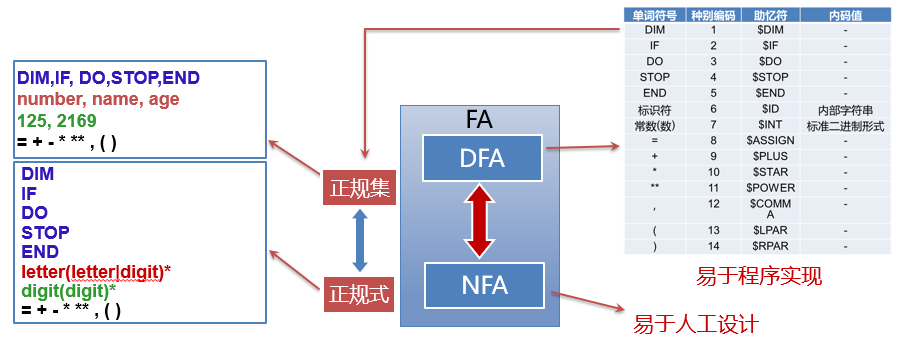 小结:程序设计语言的单词集合是一个正规集,可以由正规式描述,正规式与正规集是一组对应的概念;FA分为DFA和NFA,NFA易于人工设计,DFA易于词法分析的程序实现,从定义上来看,DFA是NFA的特例,而NFA与DFA的描述是相同的,并且NFA可以等价地转换为DFA
小结:程序设计语言的单词集合是一个正规集,可以由正规式描述,正规式与正规集是一组对应的概念;FA分为DFA和NFA,NFA易于人工设计,DFA易于词法分析的程序实现,从定义上来看,DFA是NFA的特例,而NFA与DFA的描述是相同的,并且NFA可以等价地转换为DFA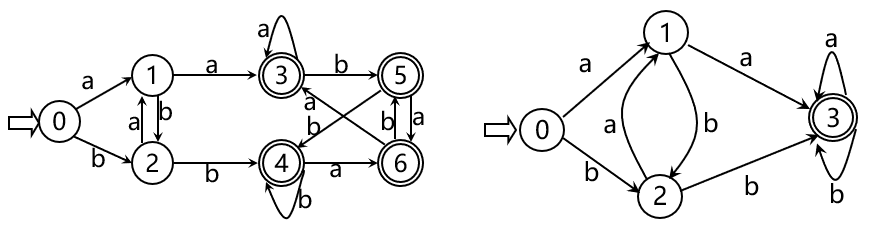
【本文地址】
今日新闻 |
推荐新闻 |