神经网络机器翻译总结 |
您所在的位置:网站首页 › 有道神经翻译成英文 › 神经网络机器翻译总结 |
神经网络机器翻译总结
|
神经网络机器翻译(Neural Machine Translation, NMT)是最近几年提出来的一种机器翻译方法。相比于传统的统计机器翻译(SMT)而言,NMT能够训练一张能够从一个序列映射到另一个序列的神经网络,输出的可以是一个变长的序列,这在翻译、对话和文字概括方面能够获得非常好的表现。NMT其实是一个encoder-decoder系统,encoder把源语言序列进行编码,并提取源语言中信息,通过decoder再把这种信息转换到另一种语言即目标语言中来,从而完成对语言的翻译。 神经网络的seq2seq学习序列对序列的学习,顾名思义,假设有一个中文句子“我也爱你”和一个对应英文句子“I love you too”,那么序列的输入就是“我也爱你”,而序列的输出就是“I love you too”,从而对这个序列对进行训练。对于深度学习而言,如果要学习一个序列,一个重要的困难就是这个序列的长度是变化的,而深度学习的输入和输出的维度一般是固定的,不过,有了RNN结构,这个问题就可以解决了,一般在应用的时候encoder和decoder使用的是LSTM或GRU结构。
Bahdanau等人使用的encoder是一个双向RNN(bi-directional RNN),双向RNN有前向和后向RNN组成,前向RNN f → \overrightarrow{f} f 正向读取输入序列(从 x 1 x_1 x1到 x T x_T xT),并计算前向隐藏层状态 ( h 1 → , ⋯ , h T → ) (\overrightarrow{h_1},\cdots,\overrightarrow{h_T}) (h1 ,⋯,hT ),而后向RNN f ← \overleftarrow{f} f 从反向读取输入序列(从 x T x_T xT到 x 1 x_1 x1),并计算反向隐藏状态 ( h 1 ← , ⋯ , h T ← ) (\overleftarrow{h_1},\cdots,\overleftarrow{h_T}) (h1 ,⋯,hT )。对于每个单词 x j x_j xj,我们把它对应的前向隐藏状态向量 h j → \overrightarrow{h_j} hj 和后向隐藏状态向量 h j ← \overleftarrow{h_j} hj 拼接起来来表示对 x j x_j xj的注解(annotation,就还是个隐藏向量呗),例如 h j = [ h j → ; h j ← ] h_j=[\overrightarrow{h_j}; \overleftarrow{h_j}] hj=[hj ;hj ],这样,注解 h j h_j hj就包含了所有词的信息。由于RNN对最近的输入表达较好,所以注解 h j h_j hj主要反映了 x j x_j xj周围的信息。 Decoder在这个新的结构中,定义条件概率: p ( y ) = Π t = 1 T ′ p ( y t ∣ { y 1 , ⋯ , y t − 1 } , c ) p ( y t ∣ { y 1 , ⋯ , y t − 1 } , c ) = g ( y t − 1 , s t , c ) (3) p(y)=\Pi^{T^{'}}_{t=1}p(y_t|\{y_1,\cdots,y_{t-1}\},c)\tag{3}\\ p(y_t|\{y_1,\cdots,y_{t-1}\},c)=g(y_{t-1},s_t,c) p(y)=Πt=1T′p(yt∣{ y1,⋯,yt−1},c)p(yt∣{ y1,⋯,yt−1},c)=g(yt−1,st,c)(3) 其中, g g g为非线性函数, s t s_t st是decoder的隐藏状态, c c c是由encoder的隐藏序列产生的上下文向量,这个具体是什么等一会说。 把(3)式的条件概率写为: p ( y i ∣ y 1 , ⋯ , y i − 1 , x ) = g ( y i − 1 , s i , c i ) (4) p(y_i|y_1,\cdots,y_{i-1},x)=g(y_{i-1},s_i,c_i)\tag{4} p(yi∣y1,⋯,yi−1,x)=g(yi−1,si,ci)(4) 其中, s i s_i si是时间步 i i i的隐藏状态,可由下式来计算: s i = f ( s i − 1 , y i − 1 , c i ) s_i = f(s_{i-1}, y_{i-1},c_i) si=f(si−1 |
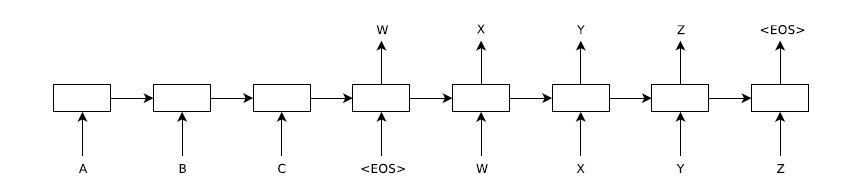 如上图,输入一个句子ABC以及句子的终结符号< EOS>,输出的结果为XYZ及终结符号< EOS>。在encoder中,每一时间步输入一个单词直到输入终结符为止,然后由encoder的最后一个隐藏层 h t h_t ht作为decoder的输入,在decoder中,最初的输入为encoder的最后一个隐藏层,输出为目标序列词X,然后把该隐藏层以及它的输出X作为下一时间步的输入来生成目标序列中第二个词Y,这样依次进行直到< EOS>。下面看它详细的模型。 给定一个输入序列 ( x 1 , ⋯ , x T ) (x_1,\cdots, x_T) (x1,⋯,xT),经过下面的方程迭代生成输出序列 ( y 1 , ⋯ , y T ′ ) (y_1,\cdots, y_{T^{'}}) (y1,⋯,yT′): h t = f ( W h x x t + W h h h t − 1 ) y t = W y h h t (1) h_t = f(W^{hx}x_t + W^{hh}h_{t-1})\tag{1}\\ y_t = W^{yh}h_t ht=f(Whxxt+Whhht−1)yt=Wyhht(1) 其中, W h x W^{hx} Whx为输入到隐藏层的权重, W h h W^{hh} Whh为隐藏层到隐藏层的权重, h t h_t ht为隐藏结点,$ W^{yh} 为隐藏层到输出的权重。在这个结构中,我们的目标是估计条件概率 为隐藏层到输出的权重。 在这个结构中,我们的目标是估计条件概率 为隐藏层到输出的权重。在这个结构中,我们的目标是估计条件概率p(y_1,\cdots,y_{T{'}}|x_1,\cdots,x_T)$,首先通过encoder的最后一个隐藏层获得$(x_1,\cdots,x_T)$的固定维度的向量表示$v$,然后通过decoder进行计算$y_1,\cdots,y_{T{'}} 的概率,这里的初始隐藏层设置为向量 的概率,这里的初始隐藏层设置为向量 的概率,这里的初始隐藏层设置为向量v$: p ( y 1 , ⋯ , y T ′ ∣ x 1 , ⋯ , x T ) = Π t = 1 T ′ p ( y t ∣ v , y 1 , ⋯ , y t − 1 ) (2) p(y_1,\cdots,y_{T^{'}}|x_1,\cdots,x_T) = \Pi^{T^{'}}_{t=1}p(y_t|v,y_1,\cdots,y_{t-1})\tag{2} p(y1,⋯,yT′∣x1,⋯,xT)=Πt=1T′p(yt∣v,y1,⋯,yt−1)(2) 在这个方程中,每个 p ( y t ∣ v , y 1 , ⋯ , y t − 1 ) p(y_t|v,y_1,\cdots,y_{t-1}) p(yt∣v,y1,⋯,yt−1)为一个softmax函数。 Sutskever等人在实际建模中有三点与上述描述不同:
如上图,输入一个句子ABC以及句子的终结符号< EOS>,输出的结果为XYZ及终结符号< EOS>。在encoder中,每一时间步输入一个单词直到输入终结符为止,然后由encoder的最后一个隐藏层 h t h_t ht作为decoder的输入,在decoder中,最初的输入为encoder的最后一个隐藏层,输出为目标序列词X,然后把该隐藏层以及它的输出X作为下一时间步的输入来生成目标序列中第二个词Y,这样依次进行直到< EOS>。下面看它详细的模型。 给定一个输入序列 ( x 1 , ⋯ , x T ) (x_1,\cdots, x_T) (x1,⋯,xT),经过下面的方程迭代生成输出序列 ( y 1 , ⋯ , y T ′ ) (y_1,\cdots, y_{T^{'}}) (y1,⋯,yT′): h t = f ( W h x x t + W h h h t − 1 ) y t = W y h h t (1) h_t = f(W^{hx}x_t + W^{hh}h_{t-1})\tag{1}\\ y_t = W^{yh}h_t ht=f(Whxxt+Whhht−1)yt=Wyhht(1) 其中, W h x W^{hx} Whx为输入到隐藏层的权重, W h h W^{hh} Whh为隐藏层到隐藏层的权重, h t h_t ht为隐藏结点,$ W^{yh} 为隐藏层到输出的权重。在这个结构中,我们的目标是估计条件概率 为隐藏层到输出的权重。 在这个结构中,我们的目标是估计条件概率 为隐藏层到输出的权重。在这个结构中,我们的目标是估计条件概率p(y_1,\cdots,y_{T{'}}|x_1,\cdots,x_T)$,首先通过encoder的最后一个隐藏层获得$(x_1,\cdots,x_T)$的固定维度的向量表示$v$,然后通过decoder进行计算$y_1,\cdots,y_{T{'}} 的概率,这里的初始隐藏层设置为向量 的概率,这里的初始隐藏层设置为向量 的概率,这里的初始隐藏层设置为向量v$: p ( y 1 , ⋯ , y T ′ ∣ x 1 , ⋯ , x T ) = Π t = 1 T ′ p ( y t ∣ v , y 1 , ⋯ , y t − 1 ) (2) p(y_1,\cdots,y_{T^{'}}|x_1,\cdots,x_T) = \Pi^{T^{'}}_{t=1}p(y_t|v,y_1,\cdots,y_{t-1})\tag{2} p(y1,⋯,yT′∣x1,⋯,xT)=Πt=1T′p(yt∣v,y1,⋯,yt−1)(2) 在这个方程中,每个 p ( y t ∣ v , y 1 , ⋯ , y t − 1 ) p(y_t|v,y_1,\cdots,y_{t-1}) p(yt∣v,y1,⋯,yt−1)为一个softmax函数。 Sutskever等人在实际建模中有三点与上述描述不同:【本文地址】
今日新闻 |
推荐新闻 |