Python实现DFA确定型有穷自动机和NFA非确定型有穷自动机相关算法 |
您所在的位置:网站首页 › 有穷自动机的最小化 › Python实现DFA确定型有穷自动机和NFA非确定型有穷自动机相关算法 |
Python实现DFA确定型有穷自动机和NFA非确定型有穷自动机相关算法
|
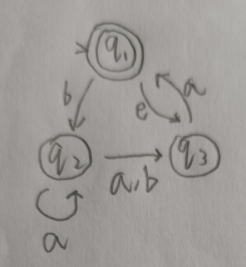
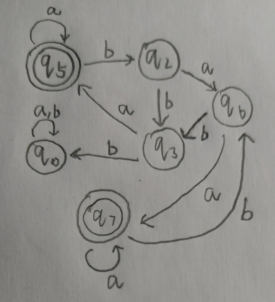
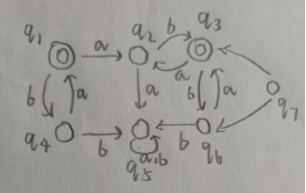
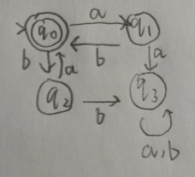
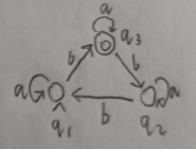
整理一下上学期写的代码,关于自动机的相关算法实现。 实现基于有穷自动机的形式化表示,可视化没什么思路就没写。 完整代码已上传至github https://github.com/huiluczP/finiteAutomata 直接想用的话test.py脚本中有示例,导入文件直接用就行。 实现功能NFA相关: 利用五元组,创建NFA模型输入字符串,判定是否被该NFA模型接受DFA相关: 利用五元组,创建DFA模型输入字符串,判断是否被该DFA模型接受NFA转DFADFA最小化RL与DFA转换包含三个文件,DFA.py,NFA.py,test.py。 数据结构形式化表示,有穷自动机都是五元组。 DFA数据结构: class DFA:states = [] # 所有状态input_symbols = [] # 字母表start_state = "q0" # 初始状态,仅有一个final_states = [] # 终结状态trans = {} # 转移函数,字典,包括启示状态,字符与终点{'q1':{'a':'q2', 'b':'q3'}} 初始状态start_state 由于FA只有一个初始状态,所以利用字符串表示。如q0。终结状态final_states 多个终结状态,利用列表list存放。如[’q1’]所有状态states 利用list存放。如[‘q0’,’q1’,’q2’]字母表input_symbols 利用list存放。如[‘a’,’b’]状态转移 trans 利用字典进行存放,即为key-value值键对存放。字典第一级key为初始状态,对应的值存放转移规则。具体的转移规则也由字典存放,该层字典的key为转移接受的字符,值为转移后的结果。由于DFA转移结果确定,所以利用字符串存放。如状态q1接受a转移到状态q2,表示为{“q1”: {“a”: “q2”}}。NFA数据结构: class NFA:states = [] # 所有状态input_symbols = [] # 字母表start_state = "q0" # 初始状态,仅有一个final_states = [] # 终结状态trans = {} # 转移函数,字典,包括启示状态,字符与终点{“q1”: {“a”: [“q2”,”q3”]}}NFA数据结构除转移规则外都相同,由于转移规则结果不确定,利用列表list存放转移后的状态集合。如{“q1”: {“a”: [“q2”,”q3”]}}。 算法具体实现 NFA判断字符串是否被接受实现在NFA.py中 代码分析计算闭包 def _cal_closure(self, state):# 计算状态state的空闭包closure_list = [state]middle_state = deque()middle_state.append(state)while len(middle_state) > 0:current_state = middle_state[0]if current_state in self.trans.keys():if "e" in self.trans[current_state].keys():for s in self.trans[current_state]["e"]:if s not in closure_list:closure_list.append(s)middle_state.append(s)middle_state.popleft()return closure_list由于NFA存在空转移,所以每个字符的输入到达的状态可能有多个,则需要计算对应的空闭包。状态的空闭包为对应状态加上空规则的终点状态集合。代码创建一个队列middle_state,队列首先入队输入状态s,之后找到以s为起点的空转移规则,将结果放入队列,同时队列第一个状态出队列。以此循环,当middle_state为空时结束计算,返回闭包。 获取下一个状态集合 def _get_next_states(self, current_states, input_char):# 由于nfa,则输入的状态和到达的状态都不唯一next_states = []for c_state in current_states:if c_state in self.trans.keys():if input_char in self.trans[c_state].keys():end_states = self.trans[c_state][input_char]for s in end_states:s_closure = self._cal_closure(s)for s_c in s_closure:if s_c not in next_states:next_states.append(s_c)print(current_states, end="")print(" -> ", end="")print(next_states)return next_states遍历转移规则集合,找到对应初始状态与输入字符的转移,并计算目标状态的空闭包集合。该状态集合即为下一个状态的集合。 判断是否存在终结状态 def _have_final_states(self, current_states):# 判断是否含有终结状态for c in current_states:if c in self.final_states:return Truereturn False判断遍历完字符后的状态集合,若其中有终结状态,则接受该字符串,否则不接受。 示例分析输入如图所示的NFA。 输入可接受字符串baba,获得结果: ['q1'] -> ['q2'] ['q2'] -> ['q2', 'q3'] ['q2', 'q3'] -> ['q3'] ['q3'] -> ['q1', 'q3'] 被接受输入不可接受字符串babaab,获得结果: ['q1'] -> ['q2'] ['q2'] -> ['q2', 'q3'] ['q2', 'q3'] -> ['q3'] ['q3'] -> ['q1', 'q3'] ['q1', 'q3'] -> ['q1', 'q3'] ['q1', 'q3'] -> ['q2'] 不被接受 DFA判断字符串是否被接受实现在DFA.py中 代码分析 def read_input(self, input_str):# 遍历输入字符串字符,进行状态转移,若最终状态为终结状态,输出接收,否则输出错误current_state = self.start_state# 确认字符可靠性for c in input_str:if c not in self.input_symbols:print("输入字符串包括非法字符")return False# 遍历for c in input_str:current_state = self._get_next(current_state, c)if current_state in self.final_states:print("被接受")return Trueelse:print("不被接受")return Falsedef _get_next(self, current_state, input_char):# current_state为当前状态,input_char为读入字符current_trans = self.trans[current_state]next_state = current_trans[input_char]print("{}-{}-{}".format(current_state, input_char, next_state))return next_state最简单的功能。 首先遍历字符串,确定有没有字母表以外的字符。每次读入一个字符,找到其对应的转移规则字典,确定输入的字符key,获得转移后的状态作为当前状态,输出状态转移过程。直到读完每一个字符。 最终判断状态是否为终结状态,输出判断。 示例分析输入如图所示的DFA。 输入可接受字符串aaababb,获得结果: q0-a-q0 q0-a-q0 q0-a-q0 q0-b-q1 q1-a-q0 q0-b-q1 q1-b-q2 被接受输入不可接受字符串aba,获得结果: q0-a-q0 q0-b-q1 q1-a-q0 不被接受 NFA转DFA用的是表格法,计算所有状态组合以及组合能达到的闭包,最后生成DFA。 代码分析计算表头 def create_table_head(states):table_state_list = []# 计算表头state_num = len(states)for i in range(state_num):head_list = list(itertools.combinations(states, i + 1))table_state_list.extend(head_list)return table_state_list首先计算转换表的表头,即状态集合的所有非空真子集。代码中利用itertools库的combinations方法获取组合结果的集合。 计算空闭包 def cal_single_closure(s, trans):# 计算单一状态闭包closure = []middle_state = deque()closure.append(s)middle_state.append(s)while len(middle_state) > 0:if middle_state[0] not in trans.keys():# 非确定可能不是所有状态都有转换规则middle_state.popleft()breakif dict(trans[middle_state[0]]).keys().__contains__("e"):next_states = dict(trans[middle_state[0]])["e"]for next_state in next_states:if next_state not in closure:closure.append(next_state)middle_state.append(next_state)middle_state.popleft()return closure输入为对应状态和NFA的转移规则。状态的空闭包为对应状态加上空规则的终点状态集合。代码创建一个队列middle_state,队列首先入队输入状态s,之后找到以s为起点的空转移规则,将结果放入队列,同时队列第一个状态出队列。以此循环,当middle_state为空时结束计算,返回闭包。 计算表格 def cal_table(input_symbols, table_state_num, table_state_list, trans, state_list, closures):# table大小为表头*字母表长度,方便起见把所有项目都算上table = []for i in range(table_state_num):simple_list = [0] * len(input_symbols)# 空集合直接放入空结果if 'blank' in table_state_list[i]:for j in range(len(input_symbols)):simple_list[j] = ('blank', )table.append(simple_list)continue# 每个项目为转移规则结果的闭包的并集# 获得转移结果for j in range(len(input_symbols)):simple_trans_result = []for c in table_state_list[i]:if c in trans.keys():if input_symbols[j] in dict(trans)[c].keys():next_states = dict(trans)[c][input_symbols[j]]for next_state in next_states:if next_state not in simple_trans_result:simple_trans_result.append(next_state)# 计算闭包并集simple_closures_list = []for k in simple_trans_result:for c in closures[state_list.index(k)]:if c not in simple_closures_list:simple_closures_list.append(c)# 直接利用顺序tuple进行对应simple_closures_list = sorted(simple_closures_list)if len(simple_closures_list) > 0:simple_list[j] = tuple(simple_closures_list)else:simple_list[j] = tuple(["blank"])table.append(simple_list)return table表格中的每个值,为表头中的状态接受对应字符后的转移结果的空闭包集合。存放结果为一个元组,包括所有闭包中的状态。空集合表头为(blank,),对应的表项也都为(blank,)。 这步理解了基本就差不多了。 转换状态形式,生成转移规则 def trans_table(table, table_head):# 为了计算方便,将状态combine转换为对应的indexindex_table = copy.deepcopy(table)for i in range(len(index_table)):for k in range(len(index_table[i])):combine = index_table[i][k]c_index = get_combine_state_index(table_head, combine)index_table[i][k] = c_indexreturn index_tabledef create_dfa_trans(table, start_index, symbols_list):# 利用table构造dfa转换结果trans = {}states = []middle_state = deque()middle_state.append(start_index)while len(middle_state) > 0: # 注意还要加上对e兜底的判断current_state = middle_state[0]states.append(current_state)simple_rule = {}for i in range(len(symbols_list)):# 状态名用q+index表示simple_rule[symbols_list[i]] = "q"+str(table[current_state][i])if table[current_state][i] not in states:middle_state.append(table[current_state][i])trans["q"+str(current_state)] = simple_rulemiddle_state.popleft()return trans, states将表格中的元组进行匹配,根据其在表头集合中的序号转换为新状态,即为q+序号的字符串。之后由开始状态创建对应的转移集合,利用队列进行所有状态的获取,直到队列为空。 获取终结状态 def get_dfa_final_state(combine_list, final_states):# 将combine_list中包含原终结状态的作为终结状态final_combines = []final_index = []for c in combine_list:for f in final_states:if f in c:final_combines.append(c)breakfor fc in final_combines:f_index = get_combine_state_index(combine_list, fc)final_index.append(f_index)return final_index终结状态为获取组合状态中有NFA中终结状态的组合状态。 最终将计算结果为参数创建DFA,返回即可。代码循环用的太多,并且表格其实不需要全部都算,算相关的即可,所以复杂度方面还是有点问题,优化啥的有空再说吧( ・_ゝ・)。 示例分析将图中所示的NFA转换为DFA。 输出中间表格结果: a b blank [('blank',), ('blank',)] q1 [('blank',), ('q2',)] q2 [('q2', 'q3'), ('q3',)] q3 [('q1', 'q3'), ('blank',)] q1,q2 [('q2', 'q3'), ('q2', 'q3')] q1,q3 [('q1', 'q3'), ('q2',)] q2,q3 [('q1', 'q2', 'q3'), ('q3',)] q1,q2,q3 [('q1', 'q2', 'q3'), ('q2', 'q3')]转换结果: start state:q5 final states:[ 'q5', 'q7'] states:['q5', 'q2', 'q6', 'q3', 'q7', 'q3', 'q0'] trans:{'q5': {'a': 'q5', 'b': 'q2'}, 'q2': {'a': 'q6', 'b': 'q3'}, 'q6': {'a': 'q7', 'b': 'q3'}, 'q3': {'a': 'q5', 'b': 'q0'}, 'q7': {'a': 'q7', 'b': 'q6'}, 'q0': {'a': 'q0', 'b': 'q0'}}转换后DFA示意图: 用的是划分法,思路就是找出等价状态。 代码分析消去不可达状态 def _delete_unreachable_node(self):# 删除不可达节点# 所以先求可达节点reachable_node = [self.start_state]middle_state = deque()middle_state.append(self.start_state)while len(middle_state) > 0:current_state = middle_state[0]for s in self.input_symbols:state = self.trans[current_state][s]if state not in reachable_node:reachable_node.append(state)middle_state.append(state)middle_state.popleft()# 删除不可达与对应转换规则unreachable_node = []for s in self.states:if s not in reachable_node:unreachable_node.append(s)for un in unreachable_node:self.states.remove(un)del self.trans[un] 利用队列,从起始状态开始,将对应的所有转移结果状态中还未被标为可达状态的状态存入队列,同时消去队列第一个状态并归为可达状态,之后,利用可达状态求出不可达状态,并消去对应的状态和规则信息。初始化划分信息 first = self.final_states.copy() second = [] for s in self.states:if s not in first:second.append(s) divide = [first, second]初始划分为终结状态与其他状态。 计算新的划分信息 def _cal_divide(self, divide):# 计算分离相关矩阵whole_new_divide = []for d in divide:# 把归属都放在矩阵里d_end = []for char in self.input_symbols:simple_d_end = []for s in d:end = self.trans[s][char]# 找到end归哪组for i in range(len(divide)):if end in divide[i]:simple_d_end.append(i)breakd_end.append(simple_d_end)# 展开新dividenew_divide = []symbol_num = len(self.input_symbols)for i in range(len(d_end[0])):# 先把第一个放进去,先放序号if len(new_divide) == 0:new_divide.append([i])else:# 遍历已有新分组,放进去,不然就整个新的is_in_old = Falsefor n_d in new_divide:is_this = Truefor j in range(symbol_num):if d_end[j][n_d[0]] != d_end[j][i]:is_this = Falsebreak# 为true,分为该类if is_this:n_d.append(i)is_in_old = Truebreak# 整个新的if not is_in_old:new_divide.append([i])# 此时新divide中全是index,变为对应状态for n_d in new_divide:for n_d_d_index in range(len(n_d)):n_d[n_d_d_index] = d[n_d[n_d_d_index]]for n_d in new_divide:whole_new_divide.append(n_d)return whole_new_divide对每个划分进行判断。对d集合中的每个状态进行计算,生成矩阵。矩阵中信息为每个状态经过符号转移后状态所属的划分序号。只有所有符号的转移划分结果序号都分别相同时,两个状态才被分入同一个新的划分。 计算新转移 def _build_trans(self, divide):# 利用新状态建成新转换trans = {}for i in range(len(divide)):# 因为等价,所以用第一个状态即可simple_rule = {}state = divide[i][0]for s in self.input_symbols:end_state = self.trans[state][s]after_end_state = ""for j in range(len(divide)):if end_state in divide[j]:after_end_state = "q" + str(j)breaksimple_rule[s] = after_end_stateafter_state = "q" + str(i)trans[after_state] = simple_rulereturn trans每个划分给予一个状态,即为q+划分序号。同时依照每个划分中原有的转移信息生成新的转移规则。 示例分析将图中所示DFA最小化。 划分结果: [['q1', 'q3'], ['q2'], ['q4', 'q6'], ['q5']]新DFA结果五元组: q0 ['q0'] ['q0', 'q1', 'q2', 'q3'] {'q0': {'a': 'q1', 'b': 'q2'}, 'q1': {'a': 'q3', 'b': 'q0'}, 'q2': {'a': 'q0', 'b': 'q3'}, 'q3': {'a': 'q3', 'b': 'q3'}}
RE就是正则表达式,正则语言和FA之间关系紧密。 不过我转换只写了DFA转RE,RE转DFA要先逆波兰转换然后各个成分转规则,过于复杂,有兴趣自己实现下吧。 代码分析增加伪开始状态与伪结束状态 trans = copy.deepcopy(self.trans) # 增加假头和假尾 start_state = self.start_state trans["qs"] = {"e": start_state} for f_s in self.final_states:trans[f_s]["e"] = "qe"对开始状态增加到达它的一条空转移,对所有的终结状态增加从它出发的空转移。 获取状态上目标状态为自己的转移,转为∪连接的字符串 这步比较关键,主要是找到最终RE中被星号循环包裹的一部分。 def _make_self_rule_into_one(state, state_trans):self_str = ""self_rule_list = []for t in dict(state_trans).keys():# 自交为并if state_trans[t] == state:self_rule_list.append(t)del state_trans[t]# 数量大于1,则增加并符if len(self_rule_list) == 1:# state_trans[self_rule_list[0]] = stateself_str = self_rule_list[0]elif len(self_rule_list) > 1:self_to_self = "∪".join(self_rule_list)# state_trans[self_to_self] = stateself_str = self_to_self# 返回对应要放到星号中的符号串return self_str遍历对应状态上所有转移规则,若转移规则的终状态为本身,则将该转移规则的接受字符保存在list中,完成后将list中的字符串利用∪符号连接。 消去状态,产生新规则 # 依次消除状态 states = self.states.copy() for state in states:# 先把自交的归成一个state_trans = trans[state] # 当前状态为头self_str = self._make_self_rule_into_one(state, state_trans)# 计算每一条到达的规则和所有离开的规则的笛卡尔积for k in trans.keys():out_list = []del_q = []for q in dict(trans[k]).keys():if trans[k][q] == state:del_q.append(q)# 找到所有出去的规则, (起点,入符号,出符号,终点)for out_q in trans[state].keys():out_list.append((k, q, out_q, trans[state][out_q]))# 为了不破坏key,先删除,后添加for q in del_q:del trans[k][q]for ol in out_list:if len(self_str) > 1:trans[k][ol[1] + "({})*".format(self_str) + ol[2]] = ol[3]elif len(self_str) == 1:trans[k][ol[1] + "{}*".format(self_str) + ol[2]] = ol[3]# 删除自身规则del trans[state]将每条连向该状态的转移,和所有从该状态出的转移结合,将其对应的字符串连接,同时中间加上上一步算出的自己到达自己的中间字符串结果。最后添加新规则。 示例分析将图中DFA转换为RE。 输出结果: a*b(a∪ba*ba*b)* 总结本项目主要实现了DFA与NFA相应的一些算法,以及与RE正则的转换,相对来说还算完整,有学编译原理或者计算理论整不明白的可以参考看看。 |

【本文地址】
今日新闻 |
推荐新闻 |