(2022 IVC 行人再识别综述)Deep learning |
您所在的位置:网站首页 › 最新的图像识别算法 › (2022 IVC 行人再识别综述)Deep learning |
(2022 IVC 行人再识别综述)Deep learning
|
目录摘要1、引言2、数据集和度量标准2.1数据集2.1.1基于图像的行人再识别数据集2.1.2基于视频的行人再识别数据集2.2评估度量3、基于深度学习的Re-ID方法3.1深度度量方法3.1.1分类损失3.1.2验证损失3.1.3对比损失3.1.4Tripletloss3.1.5Quadrupletloss3.2局部特征学习3.2.1预定义的stripe分割3.2.2多尺度融合3.2.3软注意力3.2.4语义提取3.2.5全局-局部特征学习3.2.6对比和讨论3.3生成对抗学习3.3.1图像-图像风格转移3.3.2数据增强3.3.3不变特征学习3.3.4对比和讨论3.4序列特征学习3.4.1光流法3.4.2 3D卷积神经网络3.4.3 RNN或LSTM3.4.4时空注意力3.4.5图卷积网络3.4.6对比和讨论4、结论和未来方向
Deep learning-based person re-identification methods A survey and outlook of recent works
深度学习行人重识别综述与展望
论文地址:https://arxiv.org/abs/2110.04764 摘要近年来,随着公共安全需求的不断增加和智能监控网络的快速发展,行人再识别(Re-ID)已成为计算机视觉领域的研究热点之一。Person Re-ID的主要研究目标是从不同的摄像机中检索出具有相同身份的人。然而,传统的Person Re-ID方法需要对person target进行人工标记,耗费大量人力成本。随着深度神经网络的广泛应用,出现了很多基于深度学习的Person Re-ID方法。因此,本文旨在方便研究人员了解该领域的最新研究成果和未来趋势。首先,我们总结了最近发表的几项行人Re-ID调查的研究,并补充了最新的研究方法,以系统地对基于深度学习的行人Re-ID方法进行分类。其次,我们提出了一种多维分类法,将当前基于深度学习的Person Re-ID方法根据度量和表示学习分为四类,包括深度度量学习方法、局部特征学习方法、生成对抗学习方法和序列特征学习方法。此外,我们根据其方法和动机细分上述四个类别,讨论部分子类别的优点和局限性。最后,我们讨论了Person Re-ID的一些挑战和可能的研究方向。 1、引言近年来,随着智能监控设备的快速发展和公共安全需求的不断提高,在机场、社区、街道、校园等公共场所部署了大量摄像头。这些摄像头网络通常跨越覆盖范围不重叠的大地理区域,每天都会生成大量监控视频。我们使用这些视频数据来分析现实世界中行人的活动模式和行为特征,用于目标检测、多摄像头目标跟踪和人群行为分析等应用。PersonReID可以追溯到多目标多摄像头跟踪(MTMCTtracking)[1]的问题,其目的是判断不同摄像头捕捉到的行人或同一摄像头不同视频片段中的行人图像是否为同一行人[2]。图1说明了由多个具有非重叠视场的摄像机监控的监视区域的示例。 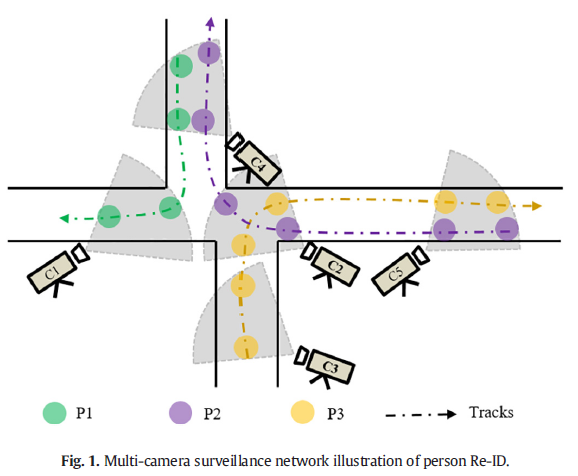
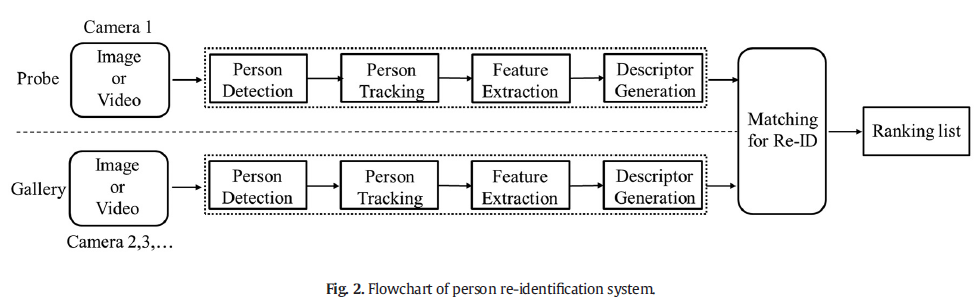
图2显示了Person Re-ID系统的完整流程,主要包括两个阶段:行人检测和重新识别[3]。对于行人检测,出现了很多检测精度高的算法,如YOLO[4]、SSD[5]和FastR-CNN[6]。Person Re-ID从检测到的行人图像中构建一个大型图像数据集(Gallery),并使用探测图像(Probe)从中检索匹配的行人图像,因此Person Re-ID也可以视为图像检索任务[7]。Person Re-ID的关键是学习行人的判别特征,以区分身份相同和身份不同的行人图像。 然而,在现实世界中,行人可能出现在多个区域的多个摄像头中,会增加学习行人判别特征的难度。 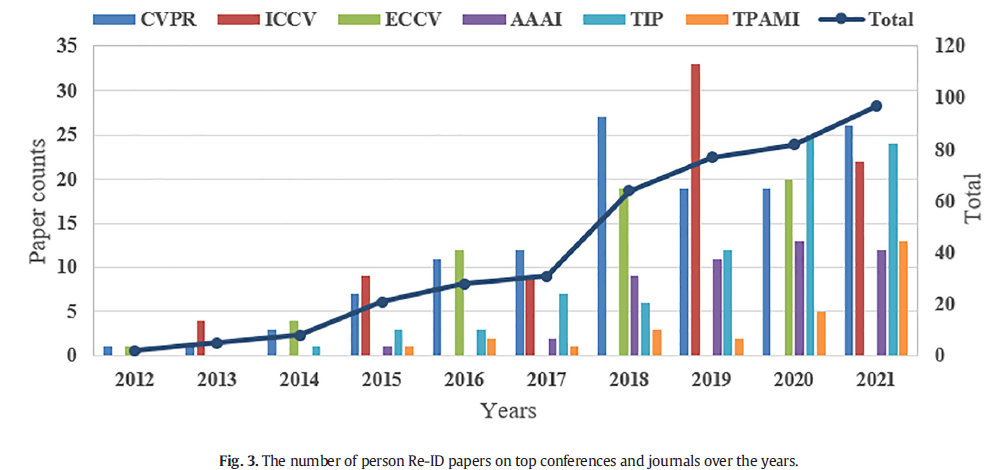
传统的Person Re-ID方法主要采用人工提取固定判别特征[8-12]或学习更好的相似性度量[13-16],容易出错且耗时,极大地影响了行人Re-ID的准确性和实时性-ID任务。2014年,深度学习首次应用于Person Re-ID领域[17,18]。图3表明,多年来收集的行人Re-ID论文的比例显着增加。一些研究人员设计了不同的损失函数来优化网络模型对判别特征的学习[19-23]。其他研究人员通过引入局部特征学习[24-28]或使用注意力机制关注身体部位的关键信息[29-34]来提取行人更稳健的特征。吴等人[35,36]探索了高级特征提取的方法,旨在通过建模概念间关系来探索基于上下文的概念融合,这些关系不是基于语义推理建模的[37]。一些工作通过结合行人的全局和局部特征来增强最终的特征表示[38-44]。由于GAN在生成图像和学习特征方面的良好表现,生成对抗学习被广泛用于行人Re-ID任务[45-55]。为了缓解单帧图像中信息的短缺,一些研究人员利用视频序列的互补空间和时间线索来有效地融合视频序列中的更多信息[56-61]。最近,基于图卷积网络的方法[60,62-65]也出现了,通过对行人图像上的图关系进行建模来学习更具辨别力和鲁棒性的特征。一些研究人员[66,67]通过利用行人3D形状的信息来提高行人ReID模型的鲁棒性。这些方法很多,并且有不同的侧重点。为了让研究人员快速了解Person Re-ID领域的发展现状和有价值的研究方向,我们对基于深度学习的Person Re-ID方法进行了深入调查,并总结了最近几年的相关研究成果。 在本次调查之前,一些研究人员[3,68–77,77–81]还审查了Person Re-ID字段。在表1中,我们总结了这些评论的主要贡献。其中一些调查[3,69]总结了基于图像和基于视频的行人重识别方法。其他调查[70,73,74,77-79]从不同维度总结了基于深度学习的Person Re-ID方法,在2014年后迅速发展,成为主要的研究手段。最近,王等人[81]概述了跨域行人重识别的方法,并比较了这些方法在公共数据集上的性能。亚古比等人[80]提出了一种多维分类法,根据不同的视角对最相关的研究进行分类。周等人[82]提供了一篇综述,总结了过去十年计算机视觉领域泛化的发展。贝赫拉等人[83]回顾了上下文和非上下文维度的传统和深度学习行人重识别方法。吴等人[84]提出了新的分类法,用于行人Re-ID的特征提取和度量学习这两个组成部分。贝赫拉等人[85]概念化了在物联网平台上解释各种未来线索以实现行人重识别的概述。 

然而,这些调查仍有一些改进之处,缺乏对基于深度学习的行人重识别方法的系统分类和分析,也错过了许多关于行人重识别的讨论部分。在本文中,与上述综述相比,我们更侧重于Person Re-ID任务中深度学习方法的度量学习和表示学习,并补充了近年来的最新研究方法。我们对现有的基于深度学习的方法进行了深入和全面的回顾,并讨论了它们的优点和局限性。我们根据度量和表示学习维度对基于深度学习的行人重识别方法进行分类,包括四类:深度度量学习、局部特征学习、生成对抗学习和序列特征学习。 深度度量学习专注于为模型训练设计更好的损失函数。Person Re-ID的常见损失函数包括:分类损失、验证损失、对比损失、三重损失和四重损失。表征学习侧重于开发特征构建策略[78,86]。因此,我们讨论了近期Person Re-ID方法中常见的特征学习策略,主要分为三类:1)局部特征学习,它学习部分级别的局部特征来为每个人图像制定组合表示;2)生成对抗学习,它学习图像特定的风格表示或解开表示,以实现图像-图像的风格转移或提取不变特征;3)序列特征学习,它使用多个图像帧和时间信息来学习视频序列表示。此外,我们根据他们的方法和动机细分了上述四类。该分类结构清晰,全面反映了Re-ID任务中最常见的深度学习方法和各种表示学习方法。因此,适合研究人员根据实际需要探索Person Re-ID。此外,我们试图讨论几个挑战和研究方向。 具体来说,我们工作的主要贡献总结如下: •我们总结了最近发表的几项行人重识别调查的研究,并补充了最新的研究方法,以系统地对基于深度学习的行人重识别方法进行分类。 •我们全面回顾了近期基于深度学习的Person Re-ID的研究方法。然后,我们提出了一种多维分类法,根据度量和表示学习将这些方法分为四类,包括深度学习、局部特征学习、生成对抗学习和序列特征学习。 •我们根据它们的方法和动机细分上述四个类别,讨论部分子类别的优点和局限性。这种分类更适合研究人员从他们的实际需求出发去探索这些方法。 •我们总结了Person Re-ID领域的一些现有挑战,并认为仍有足够的必要性对其进行研究。此外,我们讨论了Person Re-ID研究行人的七个可能的研究方向。 本调查的其余部分结构如下。在第2节中,我们讨论了用于行人Re-ID基准的通用数据集和评估指标。在sec:Methods中,我们全面回顾了当前基于深度学习的Person Re-ID方法,并根据度量学习和表示学习将它们分为四类。此外,我们根据它们的方法和动机细分了上述四个类别,讨论了部分子类别的优点和局限性。最后,在sec:ConclusionAndFutureDirections中,我们总结了这篇论文,并讨论了Person Re-ID领域当前的挑战和未来的方向。 2、数据集和度量标准在本节中,我们展示了用于评估现有基于深度学习的人Re-ID方法在图像和视频维度上的通用数据集。此外,我们简要描述了行人Re-ID的常见评估指标。 2.1数据集近年来,出现了许多提高Person Re-ID性能的方法。然而,现实世界的不确定性带来的遮挡、光照变化、摄像机视角切换、姿态变化以及类似服装等问题仍然无法很好地解决。这些挑战使许多算法仍然无法用于实际应用。因此,探索覆盖更多真实场景的大规模行人重识别数据集至关重要。随着基于深度学习的特征提取方法逐渐取代传统的手动特征提取方法,深度神经网络需要大量的训练数据,这导致了大规模数据集的快速发展。数据集的类型和注释方法在数据集之间差异很大。通常,用于Person Re-ID的数据集可以分为两类,即基于图像的数据集和基于视频的数据集。以下小节将介绍两种常用的数据集。 2.1.1基于图像的行人再识别数据集VIPeR[87]数据集是第一个提出的小人物Re-ID数据集。VIPeR包含两个视点摄像头,每个摄像头仅捕获一张图像。VIPeR使用手动标记的行人,包含1264张图像,共632个不同的行人。每个图像都被裁剪并缩放为128x48的大小。VIPeR数据集具有多个视图、姿势和光照变化,已经有许多研究人员进行测试,但它仍然是最具挑战性的行人Re-ID数据集之一。 CUHK01[88]数据集有971个人和3884个手动裁剪的图像,每个人还至少有两个图像在两个不相交的相机视图中捕获。在CUHK01数据集中,cameraA的视点和姿态变化较多,cameraB主要包括前视图和后视图的图像。 CUHK02[89]数据集有1816个人和7264张手动裁剪的图像。CUHK02包含五对相机视图(十个相机视图),每个人还至少有两个图像在两个不相交的相机视图中捕获。与CUHK01[88]数据集相比,CUHK02数据集具有更多的身份和摄像机视图,并且可以获得更多的行人图像配置(即视点、姿势、图像分辨率、照明和光度设置的组合)。 CUHK03[14]数据集属于大规模Person Re-ID数据集,收集于香港中文大学。CUHK03由10个(5对)摄像头获取,并配备了一个手动标记和一个可变形部件模型(DPM)检测器[90],以检测行人边界框。CUHK03包含1360个不同的行人,共有13164张图像,每张图像的大小都是可变的。CUHK03对CUHK01[88]和CUHK02[89]进行了改进,增加了摄像头和捕获图像的数量,从而从更多视点捕获行人图像。CUHK03数据集使用行人检测算法DPM对行人进行标注,比使用单独的人工标注更能兼容现实世界中的Person Re-ID。 Market-1501[91]数据集是2015年发布的大规模行人Re-ID数据集,它是在清华大学一家超市前使用五个高分辨率相机和一个低分辨率相机获取的。Market-1501使用行人检测器DPM自动检测行人边界框。它包含1501个不同的行人,共有32,668张图像,每张图像的大小为128x64。与CUHK03相比,Market-1501的标注图像更多,包含2793+500k干扰因子,更接近真实世界。 DukeMTMC-reID[92]数据集属于MTMCT数据集DukeMTMC[93]的一个子集。DukeMTMC-reID数据集是在杜克大学使用八个静态高清摄像机收集的。它包含16522张训练图像(来自702人)、2228张查询图像(来自其他702人)和17661张图像的搜索库(Gallery)。 MSMT17[45]数据集是2018年发布的大规模行人Re-ID数据集,由十五台摄像机在校园内捕获。MSMT17使用行人检测器FasterR-CNN[94]自动检测行人标记的帧。它包含4101条不同的行人信息,共126,441张图像,是当前行人Re-ID任务中行人和标注图像的大型数据集之一。MSMT17数据集可以覆盖比早期数据集更多的场景,并包含更多视图和显着的照明变化。 Airport[71]数据集是使用来自美国商业机场中央后安全检查站安装的六个摄像头的视频数据构建的。Airport数据集由9651个身份、31238个干扰项、总共39902张图像组成,每张图像都被裁剪并缩放为128x64的大小。机场使用使用聚合通道特征(ACF)[95]检测器生成的预检测边界框,可以准确反映现实世界的行人重识别问题。 表2显示了上述数据集的详细信息。大多数早期的基于图像的行人Re-ID数据集(VIPeR、CUHK01、CUHK02、CUHK03、Market-1501)具有以下局限性:(1)覆盖单个场景;(2)时间跨度短,光照变化不明显;(3)昂贵的手动标注或过时的带有DPM检测的自动标注。CUHK03包含视点变化、检测错误、遮挡图像。Market-1501包含视点变化、检测错误和低分辨率图像。但他们对现实世界的模拟相对较弱。DukeMTMC-reID数据集包含更具挑战性的属性,包括视点变化、光照变化、检测错误、遮挡和背景杂波。MSMT17数据集收集了15台摄像机为室内和室外场景拍摄的图像。因此,它呈现出复杂的场景变换和背景。这些视频涵盖了很长时间,因此呈现出复杂的照明变化。Airport数据集包含大量带注释的身份和边界框。据我们所知,MSMT17和Airport是用于行人重识别的最大和最具挑战性的公共数据集。 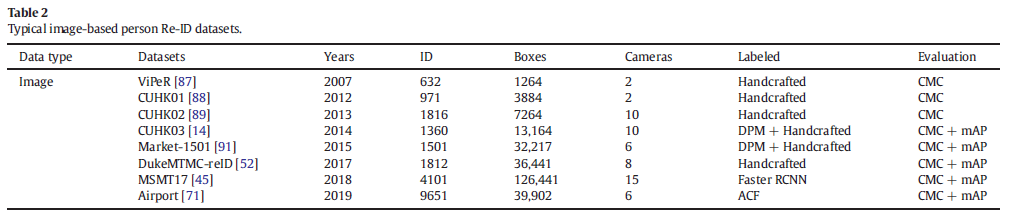 2.1.2基于视频的行人再识别数据集
2.1.2基于视频的行人再识别数据集
PRID2011[96]数据集是2011年提出的基于视频的行人Re-ID数据集,是从两个不重叠的相机采集中获得的,包含934个不同行人的总共24,541张图像和手动标记的行人边界框。每张图像的分辨率大小为128—64。 iLIDS-VID[97]数据集由机场的两个摄像头获取,包含300名行人和600条轨迹,共计42,495张行人图像。iLIDS-VID使用行人边界框的手动注释。 MARS[98]数据集是2016年提出的第一个基于视频的大规模行人重新识别数据集,其中包含1261个不同的行人以及从六个不同摄像机获取的大约20,000个行人轨迹的视频序列。DPM检测器和广义最大多角问题(GMMCP)跟踪器[100]分别用于MARS的行人检测和轨迹跟踪。MARS数据集包含3248条干扰轨迹,并固定有631和630个不同的行人,分别划分训练集和测试集。它可以被认为是Market-1501的扩展。 DukeMTMC-VideoReID[19]数据集属于MTMCT数据集DukeMTMC[93]的子集,用于基于视频的行人Re-ID。该数据集包含1812个不同的行人,4832个行人轨迹共815,420张图像,其中408个行人作为干扰项,702个行人用于训练,702个行人用于测试。 LPW(LabeledPersonintheWild)[99]数据集是一个基于视频序列的大型行人Re-ID数据集,它收集了三个不同的拥挤场景,包含2731个不同的行人和7694个行人轨迹,超过590,000张图像。LPW数据集是在拥挤的场景中收集的,并且有更多的遮挡,提供了更真实和更具挑战性的基准。 表3显示了基于视频的行人重识别数据集的详细信息。PRID2011和iLIDS-VID仅使用两个摄像头来捕捉视频,并标记了较少的身份。这意味着其他身份只是单个摄像机帧片段,并且这些身份在该数据集中的照明和拍摄角度可能不会有太大变化。MARS和DukeMTMC-ViedeReID是基于视频的大规模行人Re-ID数据集。它们的边界框和轨迹是自动生成的,并且包含几个自然检测或跟踪错误,并且每个标签可能有多个轨迹。LPW是可用且更接近现实世界的最具挑战性的基于视频的行人Re-ID数据集之一,它在三个方面与现有数据集不同:更多的身份和轨迹、自动检测的边界框以及更拥挤的场景和更大的时间跨度。 
图4显示了部分行人Re-ID数据集的一些示例图像。我们可以看到,随着大规模Person Re-ID数据集的发展,数据集中行人ID的数量和标注帧或轨迹的数量不断增加,数据集覆盖的场景也越来越丰富。这些数据集结合使用深度学习检测器和人工标注来检测行人边界框,使最新的数据集越来越接近现实世界,从而增强了行人重识别模型的鲁棒性。此外,几乎所有主流的人Re-ID数据集都使用平均精度(mAP)和累积匹配特征(CMC)曲线进行性能评估。  2.2评估度量
2.2评估度量
行人重识别算法常用的评价指标是累积匹配特征(CMC)曲线和平均精度(mAP)。 在模式识别系统中,CMC曲线是人脸、指纹、虹膜检测和行人Re-ID等领域的重要评价指标,可以综合评价模型算法的优劣。 此外,CMC曲线被认为是对Person Re-ID分类器性能的综合反映。在计算CMC曲线之前,通过对查询目标与待查询目标图像的相似度进行排序,得到图库中top-k检索图像(top-k)包含正确查询结果的概率Acck,计算得到如下: 
CMC曲线是通过将每个查询图像的Acck相加并除以查询图像的总数来计算的,通常表示为Rank-k。例如,Rank-1准确率表示正确匹配到匹配列表中的第一个目标的概率。 单一的评价指标往往不能综合评价Person Re-ID算法的综合性能。mAP可以反映所有查询正确的图像在查询结果中排在结果队列前面的程度。同时考虑查询过程的平均精度(AP)和精度召回曲线(PR)[91],而不是只关注命中率,可以更全面地衡量行人重识别算法的性能。’ 该算法通常需要在个人Re-ID任务中单独评估CMC曲线和mAP。郑等人[8]提出了Re-ranking方法,可以对查询结果进行重新排序,进一步提高Rank-k的有效性和mAP准确率。 3、基于深度学习的Re-ID方法在本节中,我们将基于深度学习的人Re-ID方法分为四类,分类结构如图5所示,包括深度度量学习、局部特征学习、生成对抗学习和序列特征学习的方法。此外,我们根据其方法和动机对上述四个类别进行细分,讨论和比较部分子类别的优点和局限性。 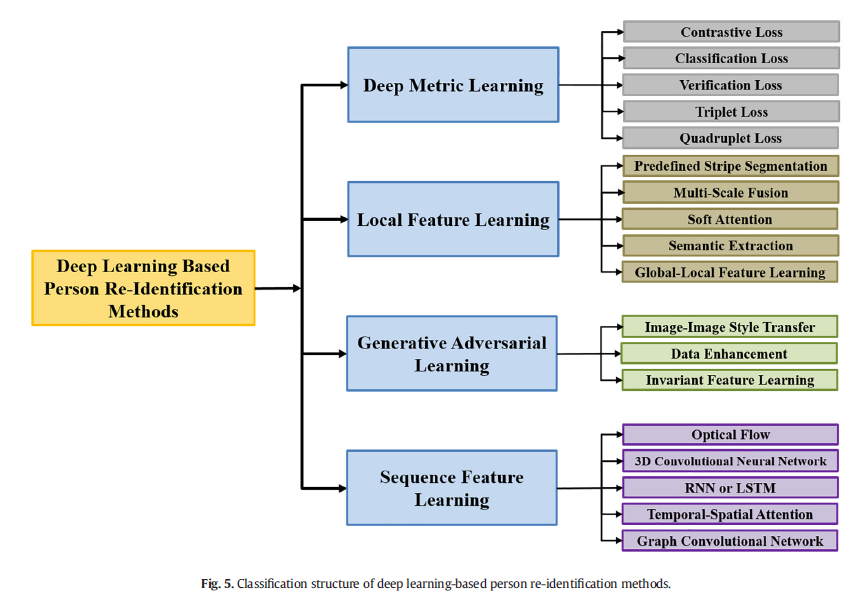 3.1深度度量方法
3.1深度度量方法
深度度量学习(DML)是度量学习(ML)方法之一,旨在学习两个行人对象之间的相似性或相异性。DML的主要目标是学习从原始图像到特征嵌入(FE)的映射,使得相同的行人使用特征空间上的距离函数具有更小的距离,而不同的行人特征彼此之间的距离更远[101,102]。随着深度神经网络(DNN)的兴起,DML已广泛应用于计算视觉,例如人脸识别、图像检索和行人Re-ID。DML主要用于通过为网络模型设计损失函数来约束判别特征的学习[78]。在本文中,我们重点关注Person Re-ID任务中常用的损失函数,包括分类损失[19,20,47,51,103-105],验证损失[20,78,106,107],对比损失[21,108,109],三元组损失[22,110,111]和四重损失[23]。五个损失函数的示意图如图6所示。这些深度度量学习方法使模型能够自动学习判别特征,这可以解决手动设计特征消耗大量劳动力成本的问题。 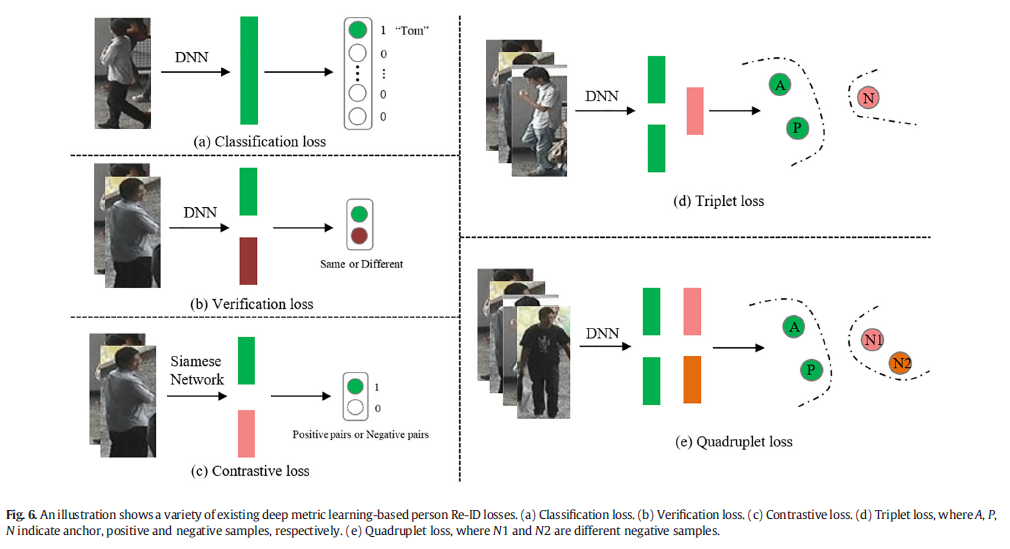 3.1.1分类损失
3.1.1分类损失
郑等人[3,112]将行人Re-ID的训练过程视为图像的多分类任务,并提出了一种ID判别嵌入(IDE)网络。IDE将每个行人视为不同的类别,并以行人的ID作为分类标签来训练深度神经网络,因此分类损失也称为ID损失。分类损失的训练网络通常输入一张图片并在网络末端连接一个全连接层(FC)进行分类,然后通过softmax激活函数将图像的特征向量映射到概率空间上。Person Re-ID任务多分类的交叉熵损失可以表示为:  其中K表示每批训练样本ID类别的数量,q(xa)表示样本图像xa的标签。如果xa被识别为ya,则q(xa)=1,否则q(xa)=0。p(ya|xa)是使用softmax激活函数将图片xa预测为类别ya的概率。分类损失被广泛用作Person Re-ID方法的深度度量学习,因为它具有易于训练模型和挖掘硬样本等优点[19,20,47,51,103-105]。然而,仅使用ID信息不足以学习具有足够泛化能力的模型。因此,ID损失通常需要结合其他损失来约束模型的训练。
3.1.2验证损失
其中K表示每批训练样本ID类别的数量,q(xa)表示样本图像xa的标签。如果xa被识别为ya,则q(xa)=1,否则q(xa)=0。p(ya|xa)是使用softmax激活函数将图片xa预测为类别ya的概率。分类损失被广泛用作Person Re-ID方法的深度度量学习,因为它具有易于训练模型和挖掘硬样本等优点[19,20,47,51,103-105]。然而,仅使用ID信息不足以学习具有足够泛化能力的模型。因此,ID损失通常需要结合其他损失来约束模型的训练。
3.1.2验证损失
Person Re-ID也可以看作是一个验证问题,提出验证损失来指导模型的训练。与分类损失相比,验证损失训练的网络需要两幅图像作为输入,通过融合两幅图像的特征信息计算出二元损失,进而确定输入的两幅图像是否为同一行人[20,78,106,107]。交叉熵验证损失函数的表达式如下: 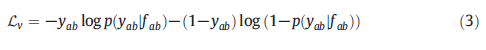
假设网络输入两幅图像xa和xb,我们分别得到这两幅图像的特征向量fa和fb,并计算出两幅特征向量的差异特征fab=(fa−fb)2。我们使用softmax激活函数计算图像对xa和xb具有相同行人ID的概率p,其中yab是两幅图像的行人ID标签。当图像xa和xb具有相同ID时,yab=1,否则,yab=0。 验证损失在识别方面效率较低,因为它在测试时只能输入一对图像来判断相似性,而忽略了图像对与数据集中其他图像之间的关系。出于这个原因,研究人员考虑将分类和验证网络结合起来[106,107],组合损失可以表示为L=Lid+Lv。混合损失可以结合分类损失和验证损失的优点,可以预测行人的身份ID并同时进行相似度度量,从而提高行人Re-ID的准确性。 3.1.3对比损失对比损失,主要约束数据对之间的相似性或相异性,通常用于人Re-ID任务中的孪生网络(SiameseNetwork)的模型训练[21,108,109]。其功能可表示为: 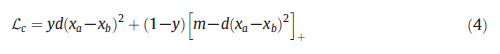
其中[z]+=max(0,z),xa和xb是同时输入到孪生网络的两个图像。d(xa,xb)通常表示两幅图像的欧式距离(相似度)。m是设定的训练阈值,y是每对训练图像是否匹配的标签。当y=1时,表示输入图像xa和xb属于具有相同ID的行人(正样本对)。当y=0时,表示输入图像xa和xb属于不同ID的行人(负样本对)。Lc很好地反映了样本对的匹配程度,通常用于训练模型进行行人Re-ID特征提取,并且经常与训练网络的分类损失组合一起使用[47]。 3.1.4TripletlossTripletloss是Person Re-ID任务中使用最广泛的depthmetricloss之一,它旨在最小化样本的类内距离和最大化样本的类间距离。随着深度神经网络的发展,出现了大量基于三元组损失的变体[22,110,111,113]。三元组损失函数可以表示为: 
与对比度损失不同,tripletloss的输入是由三个图像组成的三元组。每个三元组包含一对正样本和一个负样本,其中xa是Anchor图像,xp是Positive图像,xn是Negative图像,xa和xp的行人ID相同。xa和xn的行人有不同的ID。通过模型训练,使得欧几里得空间中xa和xp之间的距离比xn和xa之间的距离更近。为了提高模型的性能,一些基于深度学习的人Re-ID方法使用了分类损失和三元组损失的组合[114-118]。实验表明,将这两种损失结合起来有助于模型学习判别特征。传统的tripletloss在训练时会从训练集中随机选择三张图像,可能导致样本组合简单,缺乏对硬样本组合的训练,使训练模型泛化性较差。出于这个原因,一些研究人员考虑改进三重态损失以挖掘硬样本[22,119,120]。 3.1.5Quadrupletloss三元组损失的另一个改进是添加负样本图片Xn2以形成四元组损失[23],其中负样本Xn1和负样本Xn2具有不同的行人ID。四元组损失函数的表达式为: 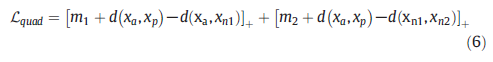
其中m1和m2是自定义训练阈值。正负样本对具有相同的锚定图像xa。Lquad的第一项与三元组损失函数相同,用于约束正负样本对之间的相对距离。传统的三元组损失函数往往会增加负样本对的类间距离,从而影响图像xa的特征学习。出于这个原因,Lquad引入了第二项来约束正负样本对之间的绝对距离。第二项中的正负样本对具有不同的锚图像,可以有效减小正样本对的类内距离,同时增加类间负样本对的距离。为了使第一项发挥主导作用,通常在训练过程中保证m1>m2是很重要的。然而,大多数使用tripletlossdrive的人Re-ID方法更侧重于区分外观差异,不能有效地学习细粒度特征。为了解决这个问题,Yan等人[121]引入了一种新颖的成对损失函数,使Re-ID模型能够通过自适应地执行指数惩罚来学习细粒度特征。 3.2局部特征学习基于从行人图像中提取的特征进行分类,Person Re-ID方法可以分为基于全局特征学习的方法和基于局部特征学习的方法。全局特征学习方法通常提取行人图像的一个特征[122-124],这种方法很难捕捉到行人的详细信息。因此,如何提取具有细微差异的行人的判别性局部特征成为研究人员关注的问题。 基于局部特征学习的方法旨在学习行人判别特征并确保每个局部特征的对齐。人工标注或神经网络通常用于自动关注具有关键信息的某些局部区域,并从这些区域中提取区别特征。常用的局部特征学习方法有预定义条纹分割[24,25,27,108,125,126]、多尺度融合[127-131]、软注意[26,29-34,132,133]、行人语义提取[27,28,31,132,133]和全局–局部特征学习[38-44]。这些方法可以缓解遮挡、边界检测错误、视图和姿势变化等问题。 3.2.1预定义的stripe分割基于预定义条带分割的方法的主要思想是根据一些预定义的划分规则对学习到的特征进行条带分割,这必须保证分区在空间上是对齐的。刘等人[125]提出了一种基于属性和外观的上下文注意网络,其中外观网络从行人的整个身体、水平和垂直部分学习空间特征。 瓦里尔等人[108]将行人图像均匀地分成几个条带,并从每个条带图像块中提取局部特征。孙等人[24]考虑了每个条带内的内容一致性,提出了一个局部卷积基线(PCB)。PCB采用统一特征划分策略学习局部特征,输出由多个条带组成的卷积特征,以增强每个划分的特征内容的一致性,从而保证条带在空间上对齐。 上述方法虽然可以提取条纹区域的判别特征,但由于模型无法区分遮挡区域和未遮挡区域,可能会导致检索结果不正确。为了缓解闭塞,Sun等人[25]提出了一种基于PCB的可见性感知局部模型,通过学习两个图像中可见的公共区域特征,确保局部特征在空间上对齐并避免因行人遮挡而造成的干扰。傅等人[126]使用各种金字塔尺度将深度特征图水平分割成多个空间条带,并使用全局平均池化和最大池化来获得每个条带的判别特征,称为水平金字塔池化(HPP)。HPP可以忽略这些干扰信息,主要来自相似的服装或背景。 3.2.2多尺度融合小尺度特征图具有很强的空间几何信息表示能力,可以获得图像的详细信息。大规模特征图擅长表征语义信息,可以获得图像的轮廓信息。提取多尺度的行人特征进行融合,可以获得丰富的行人特征表示。 刘等人[127]提出了一种多尺度三重卷积神经网络,可以捕捉不同尺度的行人外观特征。由于在不同尺度学习的行人特征存在差异或冲突,多尺度特征直接融合可能无法达到最佳融合效果。因此,研究人员开始关注跨尺度内隐联想的互补优势。陈等人[128]研究了Person Re-ID多尺度特征学习的问题,提出了一种深度金字塔特征学习深度神经网络框架,可以在学习多尺度互补特征的同时克服跨尺度特征学习的差异。周等人[135]提出了一种称为全尺度网络(OSNet)的Re-IDCNN来学习不仅捕获不同空间尺度而且封装多个尺度的协同组合的特征。在传统的人Re-ID数据集中,OSNet尽管比现有的Re-ID模型小得多,但仍取得了令人赞叹的性能。大类内变异和小类间变异的挑战经常出现在跨相机的行人Re-ID任务中。例如,跨摄像机视点变化会掩盖具有辨别特征的人的部分,或者穿着相似衣服的行人出现在摄像机之间,这使得同一个人的匹配不正确。 3.2.3软注意力注意力的目标是找到对特征图有更大影响的区域,并将模型集中在身体外观的有区别的局部部位上,以纠正错位,消除背景干扰。由于注意力机制在计算机视觉领域的良好表现,经常被用作Person Re-ID任务中的局部特征学习。目前大多数基于注意力的人重识别方法倾向于使用软注意力,可分为空间注意力、通道注意力、混合注意力、非局部注意力和位置注意力。刘等人[29]提出了一种基于注意力的深度神经网络,能够捕获从底层到语义层的多个注意力特征,以学习行人的细粒度集成特征。李等人[30]使用平衡注意力卷积神经网络来最大化不同尺度的注意力特征的互补信息,以解决任意未对齐图像的行人Re-ID挑战。为了获得一个人的局部细粒度特征,Ning等人[136]提出了一种具有多样性损失的多分支注意力网络,通过去除干扰信息的自适应滤波获得局部特征。 上述基于空间注意力的方法往往只关注行人的局部判别特征,而忽略了特征多样性对行人检索的影响。陈等人[26]提出了一种注意多样性网络,该网络使用互补通道注意模块(CAM)和位置注意模块(PAM)来学习行人多样性的特征。考虑到从一阶注意力中提取的特征,如空间注意力和通道注意力,在复杂的相机视图和姿势变化场景中没有区别[32]。陈等人[33]提出了一个高阶注意模块,它对注意机制中复杂的高阶信息进行建模,以挖掘行人之间的判别注意特征。 3.2.4语义提取一些研究人员使用深度神经网络来提取身体部位或身体姿势等语义信息,而不是使用边界框从行人身体部位提取局部特征,以提高行人Re-ID的性能。赵等人[28]考虑了人体结构信息在行人Re-ID任务中的应用,并提出了一种新的CNN,称为SpindleNet。具体来说,首先,SpindleNet使用身体部位生成网络定位身体部位的14个关键点,提取行人的7个身体区域。其次,SpindleNet使用卷积神经网络从不同的身体区域捕获语义特征。最后,SpindleNet使用具有竞争策略的树融合网络来合并来自不同身体区域的语义特征。SpindleNet可以在整个图像上对齐身体部位的特征,并且可以更好地突出局部细节信息。 有时,不仅身体部位包含区分特征,而且非身体部位也可能包含某些关键特征,例如行人的区分背包或手提包。因此,一些研究人员考虑了非身体部位的对齐方式。郭等人[114]提出了一种双重部分对齐的表示方案,该方案使用注意机制捕获身体部位以外的区分信息,通过利用来自准确人体部位和粗略非人体部位的互补信息来更新表示。苗等人[27]提出了一种姿态引导的特征对齐方案,通过行人姿态边界标记来区分信息和遮挡噪声,从而对齐查询图像和查询图像的非遮挡区域。 3.2.5全局-局部特征学习局部特征学习可以捕获有关行人区域的详细信息,但局部特征的可靠性可能会受到姿势和遮挡变化的影响。因此,一些研究人员经常将细粒度的局部特征与粗粒度的全局特征结合起来,以增强最终的特征表示。Wang等人[38]提出了一种具有全局和局部信息的多粒度特征学习策略,包括一个全局特征学习分支和两个局部特征学习分支。明等人[137]设计了一个全局-局部动态特征对齐网络(GLDFA-Net)框架,其中包含全局和局部分支。在GLDFA-Net的本地分支中引入了局部滑动对齐(LSA)策略来指导距离度量的计算,可以进一步提高测试阶段的准确性。为了减轻不精确的边界框对行人匹配的影响,Zheng等人[43]提出了一种粗粒度到细粒度的金字塔模型,该模型不仅集成了行人的局部和全局信息,还集成了从粗粒度到细粒度的渐进线索。该模型可以匹配不同尺度的行人图像,即使在图像未对齐的情况下,也能检索到具有相同局部身份的行人图像。 3.2.6对比和讨论表4显示了局部特征学习方法在CUHK03、Market1501和DukeMTMC-reID数据集上的实验结果。这些结果都是没有重新排序的实验结果[8]。总的来说,语义提取和全局-局部特征学习方法的实验性能明显高于预定义条纹分割、多尺度融合和部分注意的方法。 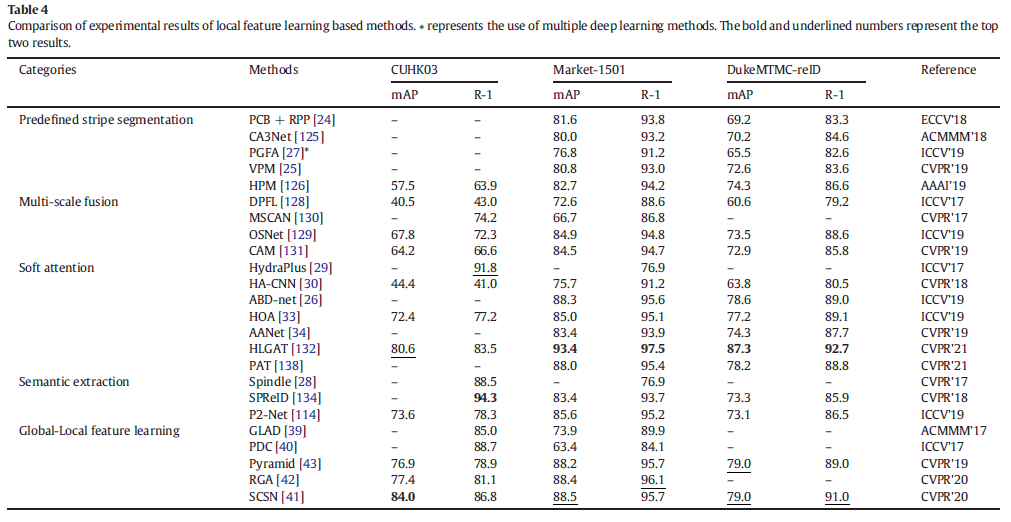
一般来说,预定义条纹分割方法简单易实现,但分割难度大,对图像对齐要求高。随着实景摄像机视图和行人姿态的变化,硬分割策略不能很好地解决行人未对齐的问题。多尺度融合方法可以学习到行人图像更深层次的线索,但在不同尺度上会出现冗余和特征冲突。注意力只关注行人关键部位的局部特征,容易忽略非焦点区域的显着特征。语义提取方法通过学习行人姿态的结构信息可以精确定位行人的局部特征,但需要额外的行人姿态模型计算。全局-局部特征学习方法可以有效地利用全局特征和局部特征的互补优势,是研究人员提高模型性能的常用方法之一。 3.3生成对抗学习
2014年,Goodfellow等人[139]首先提出了生成对抗网络(GAN),并在近年来迅速发展。出现了大量GAN的变体和应用[45,47,51,54,55,140–143]。图像生成作为GAN的重要应用之一,被广泛应用于Person Re-ID领域。图7显示了用于生成图像的GAN的工作流程图。在训练阶段,生成器GAB将图像A转换为带有随机噪声的图像B,生成器GBA将图像B转换为图像A,判别器DB确定生成的图像B是否近似于原始图像B的风格(Real或Fake)。生成器和判别器通过最小化判别器损失和L2损失[2]来保持对抗直到收敛。一些研究人员使用GAN来转换图像的风格或统一不同的图像风格,以减轻不同数据集之间或同一数据集中的图像风格差异[45,47–51,144–147]。一些工作使用GAN来合成具有不同姿势、外观、照明和分辨率的行人图像,以扩展数据集以提高模型的泛化能力[52–54,140,148–153]。 一些研究人员还使用GAN来学习与噪声无关但与身份相关的特征,以提高特征匹配的准确性[46,55,141,154]。这些方法可以缓解少量训练样本、分辨率、光照、视图和姿势变化。基于GAN的特点和应用场景,我们将基于生成对抗学习的Person Re-ID方法分为三类:图像-图像风格迁移、数据增强和不变特征学习。对于图像-图像风格转移方法,GAN学习了一张图像的背景、分辨率、光照等特征,并将这些特征转移到其他图像上,以赋予其他图像不同的风格。对于数据增强方法,GAN可以生成的样本的多样性来扩展数据集,用于增强最终的特征表示。对于不变特征学习,GAN被用于解耦表示学习,它可以学习与身份相关但与噪声无关的特征(例如,姿势、光照、分辨率等)。 3.3.1图像-图像风格转移在行人重识别任务[45]中,不同数据集之间通常存在领域差距。当分别对各种数据集进行训练和测试时,模型的性能会严重下降,这阻碍了模型对新测试集的有效泛化[155,156]。解决诸如域间隙之类的常见策略是使用GAN跨数据域执行样式转换。由于CycleGAN[142]实现了任意两种图像风格的转换,研究人员考虑对此进行改进,以实现不同数据集之间的自适应行人风格转换,以减少或消除域像差。受CycleGAN的启发,Wei等人[45]提出了一种人转移生成对抗网络(PTGAN),将源域中的行人转移到目标数据集,同时保留源域中行人的身份,使源域中的行人具有背景和照明风格的目标域。将源域中的行人转移到目标数据集,使源域中的行人具有目标域的背景和光照模式。 邓等人[47]使用孪生网络和CycleGAN形成保持相似性的生成对抗网络(SPGAN),以无监督的方式将标记的行人从源域迁移到目标域。刘等人[48]提出了一种自适应传输网络(ATNet)。ATNet使用三个CycleGAN来实现相机视图、光照、分辨率的风格,并根据不同因素的影响程度自适应地为每个CycleGAN分配权重。钟等人[50]提出了异质同质学习(HHL)方法,该方法不仅考虑了各种数据集之间的域差异,还考虑了目标域内相机的风格差异对跨域自适应人Re-ID性能的影响。钟等人[51]引入了相机风格(CamStyle)来解决同一数据集中不同相机之间的风格变化问题。CamStyle使用CycleGAN将标记的训练数据迁移到各种相机,使合成的样本在保留行人标签的同时具有不同相机的风格。此外,CamStyle还可以平滑同一数据集中各个相机之间的风格差异。 3.3.2数据增强与使用GAN减少领域差距的风格转换不同,基于数据增强的方法从模型的训练开始,通过增加训练数据的多样性来提高模型的泛化能力。郑等人[52]是第一个使用深度卷积生成对抗网络(DCGAN)[157]生成样本数据的人。黄等人[53]提出了一种多伪正则化标签(MpRL),它为每个生成的样本分配一个适当的虚拟标签,以建立真实图像和生成图像之间的对应关系。MpRL有效区分了各种生成的数据,在Market-1501、DukeMTMC-Reid和CUHK03等数据集上取得了良好的识别效果。 刘等人[140]引入了行人姿势信息来帮助GAN生成样本。GAN用于生成具有MARS数据中行人姿态结构和现有数据集中行人外观的样本图像。钱等人[150]使用姿势归一化GAN(PN-GAN)生成具有统一身体姿势的行人图像。为了缓解早期方法生成的行人图像姿态容易出现较大偏差的问题,Zhuetal.[151]使用多层级联注意网络训练了鉴别器。判别器可以有效地利用姿态和外观特征优化行人的姿态变换,使生成的行人图像与输入图像具有更好的姿态和外观一致性。 3.3.3不变特征学习除了合成图像之外,GAN还可以用于特征学习。通常,现实世界中的行人重识别任务由高级和低级视觉变化组成[46]。前者主要包括行人遮挡、姿态、摄像头视野的变化,后者主要包括分辨率、光照、天气等方面的变化。从低级视力变化获得的图像通常称为退化图像。这些视觉变化可能导致判别特征信息的丢失,这可能导致特征不匹配并显着降低检索性能[158]。 对于高级视觉中的姿势变化,Ge等人[55]提出了特征提取生成对抗网络(FD-GAN)来学习与行人身份相关的特征,而不是行人的姿势。该方法不需要额外的计算成本或辅助姿态信息,并且在Market1501、CUHK03和DukeMTMC-reID上具有先进的实验结果。 一些研究人员考虑使用GAN来学习低分辨率和高分辨率行人图像的常见不变特征。陈等人[141]提出了一种端到端的分辨率适应和重新识别网络(RAIN),它通过在低分辨率和高分辨率图像特征中添加对抗性损失来学习和对齐不同分辨率行人图像的不变特征。李等人[154]提出了交叉分辨率的对抗性学习策略,不仅学习了不同分辨率行人图像的不变特征,还利用超分辨率(SR)恢复了低分辨率图像丢失的细粒度细节信息。 3.3.4对比和讨论表5显示了基于GAN的方法在CUHK03、Market1501和DukeMTMC-reID数据集上的实验结果。这些结果都是没有Re-ranking的实验结果。IDE[3]+CameraStyle[51]和IDE[3]+UnityGAN[145]方法都使用GAN在同一数据集中生成具有不同相机风格的行人图像,在Market-1501和DukeMTMC-reID数据集中获得了出色的实验性能.FD-GAN[55]在CUKH03中性能最高,它独立学习了与行人身份和姿势相关的特征,有效降低了姿势对Person Re-ID准确率的影响。 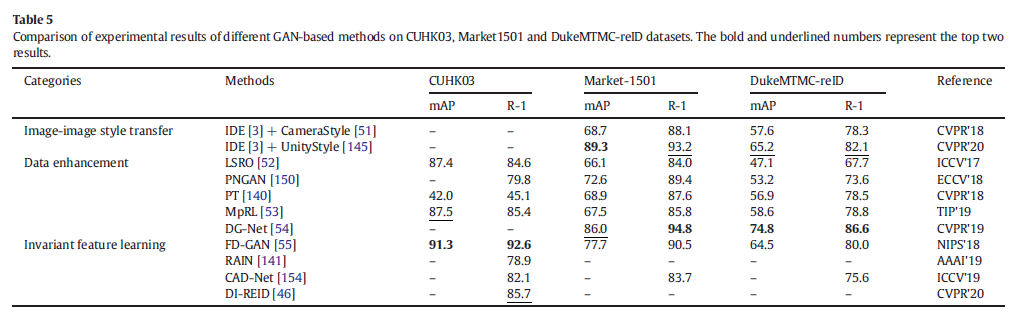
我们分别使用Market-1501(M)和DukeMTMC-reID(D)数据集作为源域和目标域。表6比较了传统的手动特征提取方法(LOMO[159]和Bow[91])、传统的无监督方法(UMDL[160]、CAMEL[16]和PUL[161])以及基于GAN的跨域风格迁移方法(CycleGAN(基础)[142]、PTGAN[47]、SPGAN[47]、HHL[50]、ATNet[48]和CR-GAN[49])。从实验结果来看,跨域风格变换方法明显优于传统的无监督学习和手动特征学习方法。 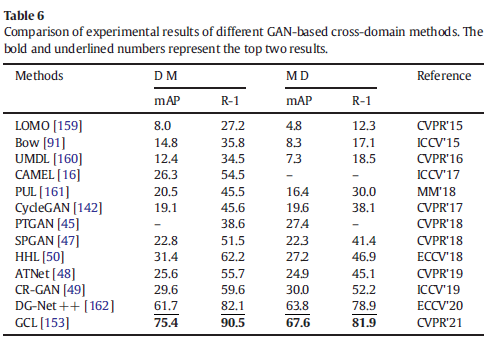
一般来说,图像到图像的风格转换方法可以平滑不同域中行人图像的风格变化。这种方法可以获得大量具有目标域风格的自动标记合成图像,可以与原始图像一起使用,以增强训练集并缓解不同数据集之间的域差距。这些方法的问题是合成图像中含有噪声,用于模型训练时可能与源域图像发生冲突,影响模型对判别特征的学习。使用GAN生成多样化行人图像的方法在一定程度上缓解了可用训练数据不足的问题。没有辅助信息引导的图像合成方法无法生成具有足够区分信息的高质量图像。辅助信息引导的图像合成方法需要复杂的网络结构来学习各种行人姿势,这增加了额外的训练成本。不变特征学习方法可以通过学习与行人身份相关而不是姿势、分辨率和光照的特征来缓解行人特征未对齐的问题并提高行人Re-ID的准确性。 3.4序列特征学习已经有许多研究人员利用视频序列中包含的丰富信息进行行人重识别。这些基于序列特征学习的方法以短视频为输入,同时使用空间和时间互补线索,可以缓解基于外观特征的局限性。这些方法中的大多数使用光流信息[56,163–166]、3维卷积神经网络(3DCNN)[57,167]、循环神经网络(RNN)或长期短期记忆(LSTM)[164,165,168,169]、时空注意[58,59,166,170–173]或图卷积网络(GCN)[60–62,174]对视频序列的时空信息进行建模。这些方法可以减轻遮挡、分辨率变化、光照变化、视图和姿势变化等。 3.4.1光流法光流法是利用视频序列中像素在时域上的变化以及相邻帧的时空上下文的相关性来获得前一帧与当前帧的对应关系。该方法可以获得目标在相邻帧之间的运动信息。钟等人[56]提出了一种双流卷积神经网络(DSCNN),其中每个流都是一个连体网络。DSCNN可以对RGB图像和光流进行建模,分别学习空间和时间信息,允许每个连体网络提取最佳特征表示。刘等人[163]提出了一种累积上下文网络(AMOC),它由两个输入序列组成,分别输入原始RGB图像和包含运动信息的光流图像。AMOC通过学习视频序列的判别累积运动上下文信息来提高Person Re-ID的准确性。光流法经常与其他方法结合使用,例如McLaughlin等人[165]利用光流信息和图像的RGB颜色来捕捉运动和外观信息,结合RNN提取视频序列的完整行人外观特征。 3.4.2 3D卷积神经网络三维卷积神经网络(3DC-NN)能够捕获视频中的时间和空间特征信息。最近,一些研究人员将3DCNN应用于基于视频的行人Re-ID并取得了不错的效果。廖等人[57]提出了一种基于3DCNN和non-localattention相结合的视频Person Re-ID方法。3DCNN在视频序列上使用3D卷积来提取空间和时间特征的聚合表示,并使用非局部时空注意力来解决变形图像的对齐问题。尽管3DCNN表现出更好的性能,但堆叠的3D卷积导致参数显着增长。过多的参数不仅使3DCNN计算量大,而且导致模型训练和优化困难。这使得3DCNN不容易适用于基于视频序列的行人Re-ID,其中训练集通常很小并且行人ID注释很昂贵。为了在减轻现有3DCNN模型的缺点的同时探索行人Re-ID的丰富时间线索,Li等人[167]提出了一种双流多尺度3D卷积神经网络(M3DCNN),用于提取基于视频的行人Re-ID的时空线索。M3DCNN也比现有的3DCNN更高效、更容易优化。 3.4.3 RNN或LSTMRNN或LSTM可以提取时间特征,通常应用于基于视频的行人重识别任务。麦克劳克林等人[165]提出了一种新颖的递归卷积网络(RCN),它使用CNN提取视频帧的空间特征,使用RNN提取视频序列的时间特征。严等人[169]使用基于LSTM的循环特征聚合网络,获得从第一个LSTM节点到最深LSTM节点的累积判别特征,有效缓解了遮挡、背景杂波和检测失败造成的干扰。陈等人[164]将视频序列分解为多个片段,并使用LSTM学习探测图像在时间和空间特征中所在的片段。该方法减少了样本中相同行人的变化,有利于相似特征的学习。上述两种方法都独立处理每个视频帧。LSTM提取的特征通常受视频序列长度的影响。RNN仅在高级特征上建立时间关联,因此无法捕捉图像局部细节的时间线索[167]。因此,仍然需要探索一种更有效的时空特征提取方法。 3.4.4时空注意力该注意力机制可以选择性地关注有用的局部信息,在解决Person Re-ID任务中的摄像机视图切换、光照变化和遮挡问题方面具有良好的性能。最近,一些研究人员使用注意力机制在时间和空间维度上解决了基于视频的行人Re-ID任务。为解决视频序列中行人姿态变化和摄像头视角变化引起的不对齐和遮挡问题,Li等人[170]提出了一种时空注意力模型,其核心思想是利用多重空间注意力来提取关键身体部位的特征,并利用时间注意力来计算每个空间注意力模型提取的组合特征表示。该方法可以更好地挖掘视频序列中潜在的区别特征表示。同样,傅等人[58]提出了一种时空注意框架,可以通过视频帧选择、局部特征挖掘和特征融合,充分利用每个行人在时间和空间维度上的区别特征。该方法可以很好地解决行人姿势变化和部分遮挡等挑战。徐等人[166]提出了一种联合时空注意力池网络,通过视频序列之间的相互依赖关系来学习视频序列的特征表示。 3.4.5图卷积网络近年来,图卷积网络(GCN)由于其强大的自动关系建模能力[175]被广泛用于Person Re-ID任务,并且出现了大量的变体网络[60,62-65]。杨等人[60]提出了一个统一的时空图卷积神经网络,它在三个维度上对视频序列进行建模:时间、空间和外观,并挖掘更多的判别性和鲁棒性信息。Wu等人[62]提出了一种用于视频人物Re-ID的自适应图表示学习方案,使用姿势对齐连接和特征相似性连接来构建自适应结构感知邻接图。 严等人[63]提出了一个基于上下文图形卷积网络的行人检索框架。由于图像外观特征不足以区分不同的人,作者使用上下文信息来扩展实例级特征,以提高特征的判别力和人物检索的鲁棒性。沉等人[64]提出了一种相似性引导的图神经网络,它通过创建一个图并使用这种关系来增强判别特征的学习,来表示探针库图像对(节点)之间的成对关系。这个更新的探针库图像用于预测关系特征以进行准确的相似性估计。 表7的最后一组显示了基于GCN的序列特征学习方法在MARS、DukeMTMCVideoReIDiLIDS-VID和PRID-2011数据集上的实验结果。从上表的结果来看,基于GCN的方法的实验性能明显优于其他序列特征学习方法。特别是,CTL[174]在MARS上的Rank-1准确率为91.4%,mAP为86.7%。CTL利用CNNbackbone和关键点估计器从多个粒度的人体中提取语义局部特征作为图节点。CTL有效挖掘与外观信息互补的综合线索,增强表征能力。 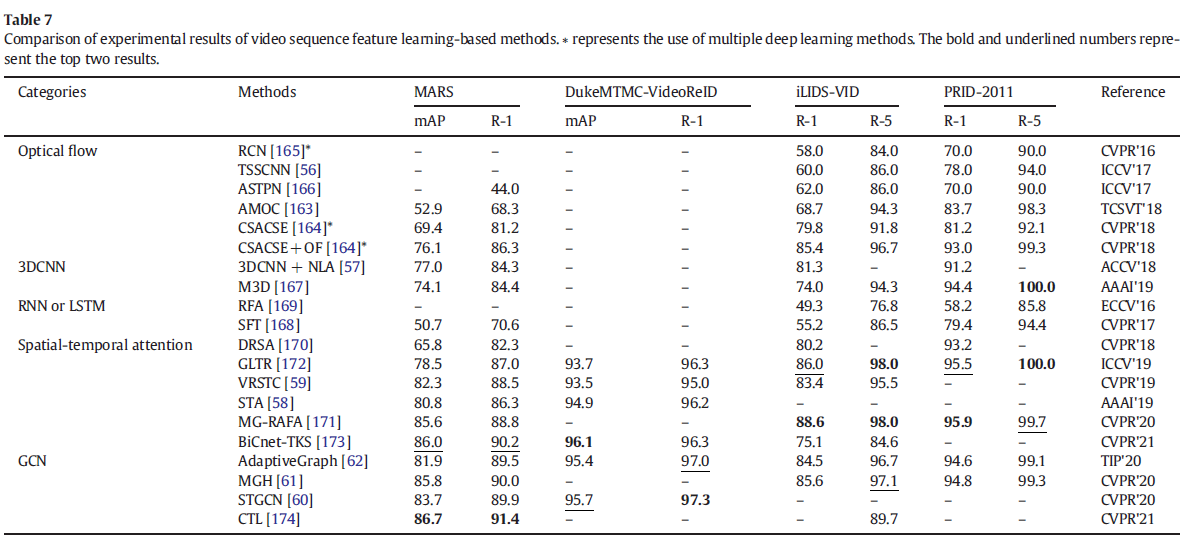 3.4.6对比和讨论
3.4.6对比和讨论
表7显示了基于序列特征学习的方法在MARS、DukeMTMC-VideoReID、iLIDS-VID和PRID-2011数据集上的实验结果。一些研究人员使用GCN对视频序列的时空关系进行建模,并取得了很好的效果。与光流、3DCNN和RNN或LSTM方法相比,基于时空注意力的方法可以获得更好的实验性能。AdaptiveGraph[62]、MGH[61]和STGCN[60]能够在上述数据集上获得较高的实验结果,与以前的方法相比,准确性有所提高。 基于序列特征学习的方法的核心思想是融合来自多个维度的更多时空信息,以减轻人重识别任务中的遮挡、光照和视点变化等一系列问题的影响。虽然光流可以提供视频序列帧的上下文信息,但它只表示相邻图像的局部动态,可能由于空间未对齐而引入噪声。计算光流的过程非常耗时。3DCNN可以捕获视频序列中的时间和空间特征信息。虽然3DCNN可以实现更好的性能,但这些方法计算耗时且难以优化。RNN或LSTM可以提取视频序列的时间特征,并在研究人员中流行了一段时间。在Person Re-ID任务中,RNN或LSTM的时间信息提取能力有限,并且由于复杂的网络结构[176]而在模型训练中遇到困难。虽然引入temporalattention和spatialattention可以缓解连续切换不同摄像机视图、光照变化和遮挡的问题,但由于不同帧中身体部位之间的时间关系不完全,影响了Person Re-ID的准确性考虑[60]。目前大部分Person Re-ID研究都是基于图像的,涌现了大量更接近现实世界的方法和数据集。与基于图像的方法相比,基于序列特征学习的方法仍然具有很大的研究前景。 4、结论和未来方向对近年来基于深度学习的行人重识别方法进行了全面的调查,并进行了深入的讨论。首先,我们总结了最近发布的几项行人Re-ID调查的主要贡献,并讨论了用于行人Re-ID基准的通用数据集。其次,我们全面回顾了当前基于深度学习的方法,这些方法按照度量学习和表征学习分为四大类,包括深度度量学习、局部特征学习、生成对抗学习和序列特征学习。四个类别根据其方法和动机,分析和讨论该方法的每个子类别的优点和局限性。这种分类更适合研究人员从他们的实际需求出发去探索这些方法。 尽管现有的基于深度学习的方法在Person Re-ID任务中取得了不错的效果,但它们仍然面临着许多挑战。目前应用于Person Re-ID训练的数据集大部分是处理过的可见图像或视频,但现实世界的数据往往表现出多种方式的组合。尽管半监督和无监督方法可以缓解高标注成本的问题,但它们的性能仍然不如监督方法。不同摄像机捕获的行人图像存在域差异,在一个数据集上训练的模型在另一个数据集上测试时可能会出现严重的性能下降。因为人们可能会换衣服或者不同的人可能穿着非常相似的衣服,所以行人的外观特征对于人ReID来说将变得不可靠。此外,如何提高模型检索的速度和准确性对于现实世界的模型部署至关重要。隐私场景的增加从根本上限制了传统的中心化Person Re-ID方法。大多数人重识别系统的检测和重识别模块相互分离,难以扩展到实际应用。 综上所述,基于深度学习的Person Re-ID方法还有很多挑战有待探索和研究。以下小节介绍了解决上述现有挑战的潜在解决方案,以及未来研究方向的前景。 (1)跨模态人Re-ID。大多数现有的Re-ID方法在基于图像或视频处理获得的公开可用数据集上评估其性能。然而,现实世界数据的获取是多种多样的,数据可能表现为不同模态(可见光、红外、深度图和文本描述等)的组合。例如,在缺乏足够的可见性信息(如图像或视频)的情况下,文本描述可以为行人Re-ID提供独特的属性辅助信息。几项研究工作[161,177]学习了有区别的跨模态视觉文本特征,以便在基于描述的行人Re-ID中进行更好的相似性评估。由于可见光相机很难在黑暗环境中捕获有效的外观信息,一些研究人员[178-182]使用热红外图像来学习丰富的视觉表示以进行跨模态匹配。现有的工作主要集中在通过对齐来自不同模态的特征分布来缓解模态差异。同时,如何将各种模态互补信息结合起来也值得今后研究。 (2)高性能的半监督和无监督人Re-ID。由于跨多个摄像头注释人物图像的成本很高,一些研究人员[183-188]专注于行人ReID的半监督和无监督方法。这些方法旨在从未标记或标记最少的人图像中学习判别特征。与监督学习相比,半监督和无监督方法减轻了对昂贵数据注释的需求,并显示出将行人Re-ID应用于实际应用的巨大潜力。 一些半监督人Re-ID方法[189,190]利用目标域中的图像聚类或轨迹聚类来使模型适应新域。一些无监督的人Re-ID方法[183-185]使用软标签或多标签来学习判别嵌入特征。虽然缺乏现实的标签学习判别特征,但Person Re-ID方法在半监督和无监督场景中的表现仍然不如监督方法,但它们在提高模型的泛化能力方面仍然保持着重要的研究价值和意义[2].在未来的研究中,应该考虑更好的聚类或标签分配策略来提高行人重识别的性能。 (3)域自适应Re-ID。现实世界中不同摄像机的背景、分辨率和光照环境差异很大,干扰了行人识别特征的学习,影响了Person Re-ID的性能。一些研究人员[45,47–49]将带有身份标签的图像从源域转移到目标域以学习判别模型,但他们在很大程度上忽略了未标记的样本和目标域中的大量样本分布。一些研究人员[155,191–194]使用聚类或图匹配方法来预测目标域中的伪标签以进行判别模型学习,但他们仍然面临着准确预测硬样本标签的挑战。领域适应对于在未知领域学习的行人Re-ID模型至关重要。因此,它仍然是未来的重要研究方向之一。 (4)3D空间中的Person Re-ID。在现实世界中,摄像机的空间位置是不确定的,新摄像机可能会临时插入到现有的摄像机网络中。考虑到人们可能会换衣服或不同的人可能穿着非常相似的衣服,行人的外观特征对于Re-ID[67]将变得不可靠。3D结构不依赖2D图像的外观信息可以有效缓解这一限制。然而,行人的3D点云数据的获取需要额外的辅助模型。一些研究人员[66,67]直接从2D图像中提取3D形状嵌入,通过对齐2D和3D局部特征来获得更稳健的结构和外观信息,或者将3D模型平面化回2D图像以在2D空间中进行表示学习以实现数据增强目的。尽管上述研究取得了很好的实验结果,但2D数据空间固有地限制了模型理解人的3D几何信息。因此,在3D空间中进一步探索Person Re-ID方法仍然是未来的一个重要研究方向。 (5)快速人重识别。目前大多数人Re-ID方法主要集中在先验知识或设计复杂的网络架构以学习鲁棒的身份不变特征表示。这些方法使用复杂的网络模型来提取高维特征以提高模型性能。但是,上述方法使用欧几里德距离计算特征的相似度并通过快速排序得到排名表,随着检索时间的大小,排名会随着检索时间的增加而增加。画廊图书馆增加。这种检索方法将非常耗时,使模型不适合实际应用。因此,一些研究人员[195-197]考虑引入散列来提高检索速度。可以通过补充长和短哈希码来实现从粗到细(CtF)[196]更快的行人Re-ID检索,以获得更快和更好的准确性。赵等人[197]提出了显着性引导的迭代非对称相互散列(SIAMH),以实现高质量的散列码生成和快速的特征提取。但是,如何设计具体的检索策略,减少模型间的信息冗余,提高检索速度和准确率,仍需进一步研究。 (6)去中心化学习者Re-ID。大多数现有的Person Re-ID方法都使用集中式学习范式,这需要从不同的摄像机视图或域中收集所有训练数据以进行集中式训练。尽管这些有监督或无监督的方法取得了重大进展,但集中式人Re-ID学习忽略了包含大量个人和私人信息的人的图像,这些信息可能不允许共享到中央数据集中。随着隐私场景的增加,它可以从根本上限制现实世界中的中心化学习人Re-ID方法。最近的几项工作[198-201]试图通过分散学习来解决上述问题。这些方法要么通过联邦学习构建全局泛化模型服务器,不需要访问本地训练数据和跨域数据共享,要么选择性地进行知识聚合以优化模型个性化和去中心化泛化之间的权衡。ID。在未来的工作中,如何在学习全局通用模型的同时确保理解跨域数据异质性仍然具有挑战性。 (7)端到端的人Re-ID系统。如本文介绍中的图2所示,当前大多数人Re-ID系统中的人检测和重新识别是两个独立的模块。Person Re-ID任务使用默认情况下已经检测到的正确行人,但一些实际的开放世界应用程序需要从原始图像或视频中进行端到端的行人搜索[202]。两阶段端到端行人重新识别框架是最常见的Re-ID系统之一,它系统地评估了结合不同检测器和Re-ID模型的优势和局限性[112]。蒙贾尔等人[203]提出了一种查询引导的端到端行人搜索网络(QEEPS)来加入行人检测和重新识别。 此外,端到端的人Re-ID也被广泛用于多目标多摄像机跟踪(MTMC跟踪)[110,204,205]。Person Re-ID算法不仅依赖于准确的行人检测算法,还依赖于检测到的未标记行人,这仍然是当前的挑战。因此,如何将行人检测和重识别有效地结合起来,设计一个端到端的行人Re-ID系统,也是未来研究人员需要关注的一个方向。 |
【本文地址】
今日新闻 |
推荐新闻 |