Elasticsearch实现检索词自动补全(检索词补全,自动纠错,拼音补全,繁简转换) 包含demo |
您所在的位置:网站首页 › 最拼音怎么拼写 › Elasticsearch实现检索词自动补全(检索词补全,自动纠错,拼音补全,繁简转换) 包含demo |
Elasticsearch实现检索词自动补全(检索词补全,自动纠错,拼音补全,繁简转换) 包含demo
|
Elasticsearch实现检索词自动补全
自动补全定义映射字段建立索引测试自动补全
自动纠错查询语句查询结果
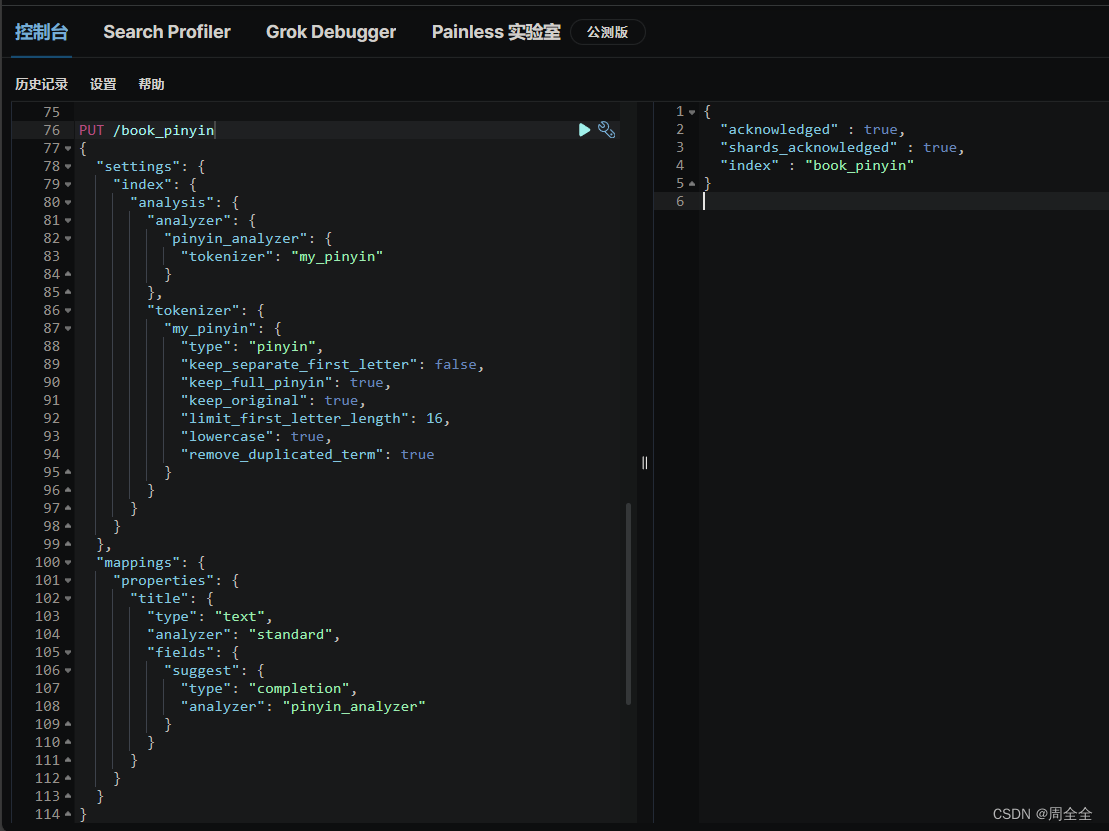
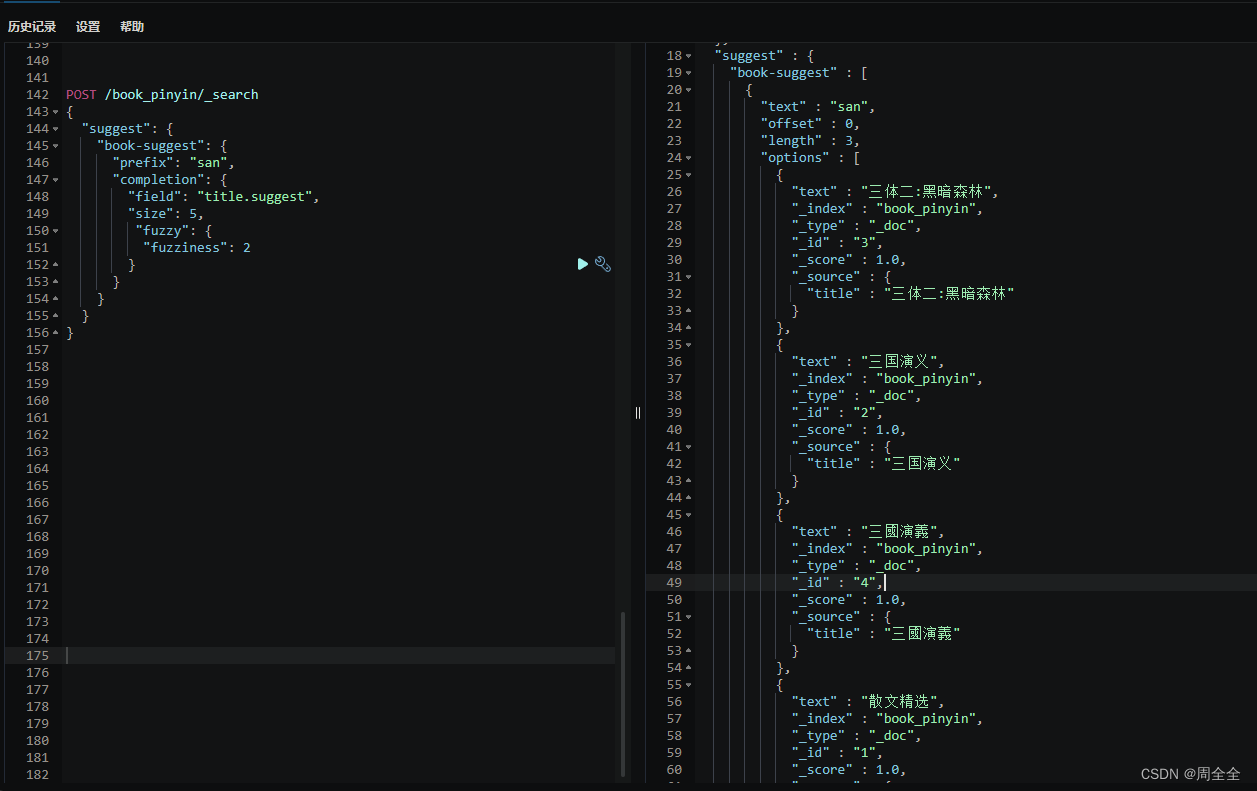
拼音补全与繁简转换安装 elasticsearch-analysis-pinyin 插件定义索引与映射建立拼音自动补全索引测试拼音自动补全测试繁简转换自动补全
代码实现demo结构demo获取
自动补全-官方文档映射(Mapping)索引(Indexing)查询(Querying)跳过重复建议模糊查询(自动纠错)正则表达式查询
自动补全
定义映射字段
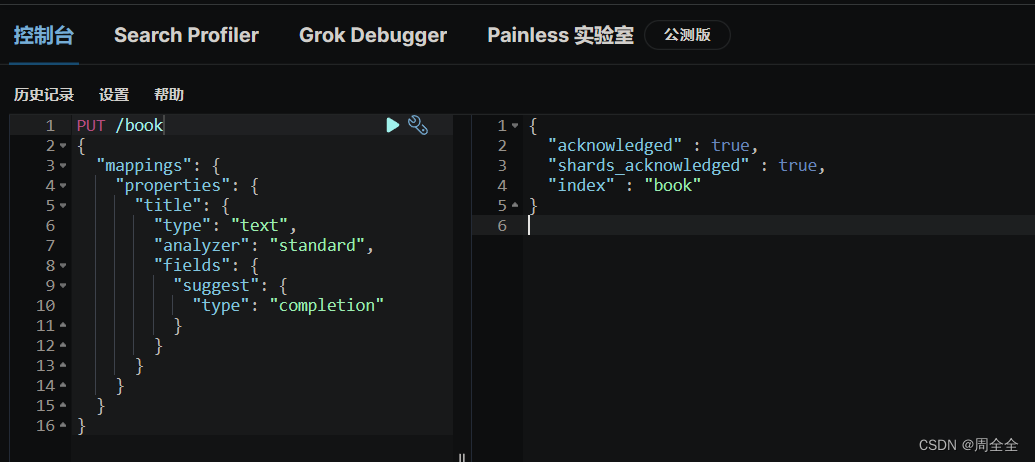
下面的请求定义了一个名为 “book” 的 Elasticsearch 索引,其中包含一个 具有 “text” 数据类型和 “standard” 分析器且名为 “title” 的字段。此字段用于处理书籍标题的文本数据。定义了名为 “suggest” 的 “completion” 子字段,用于支持实时搜索建议的自动补全功能。 PUT /book { "mappings": { "properties": { "title": { "type": "text", "analyzer": "standard", "fields": { "suggest": { "type": "completion" } } } } } } 建立索引
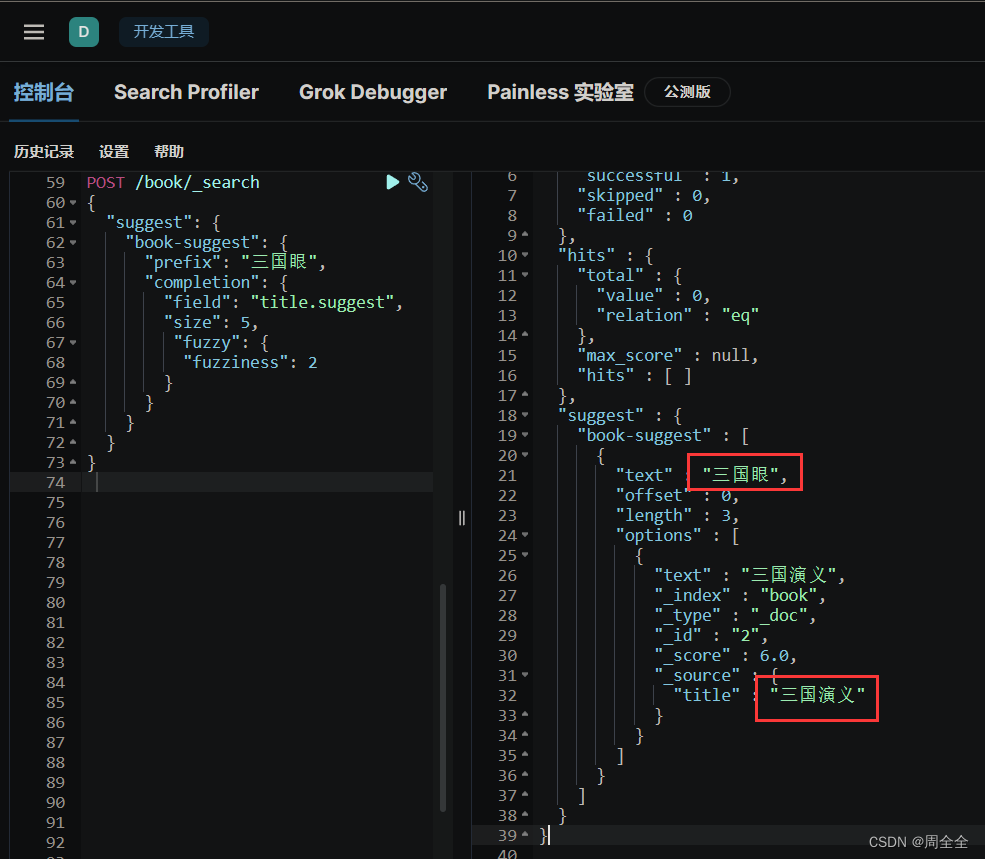
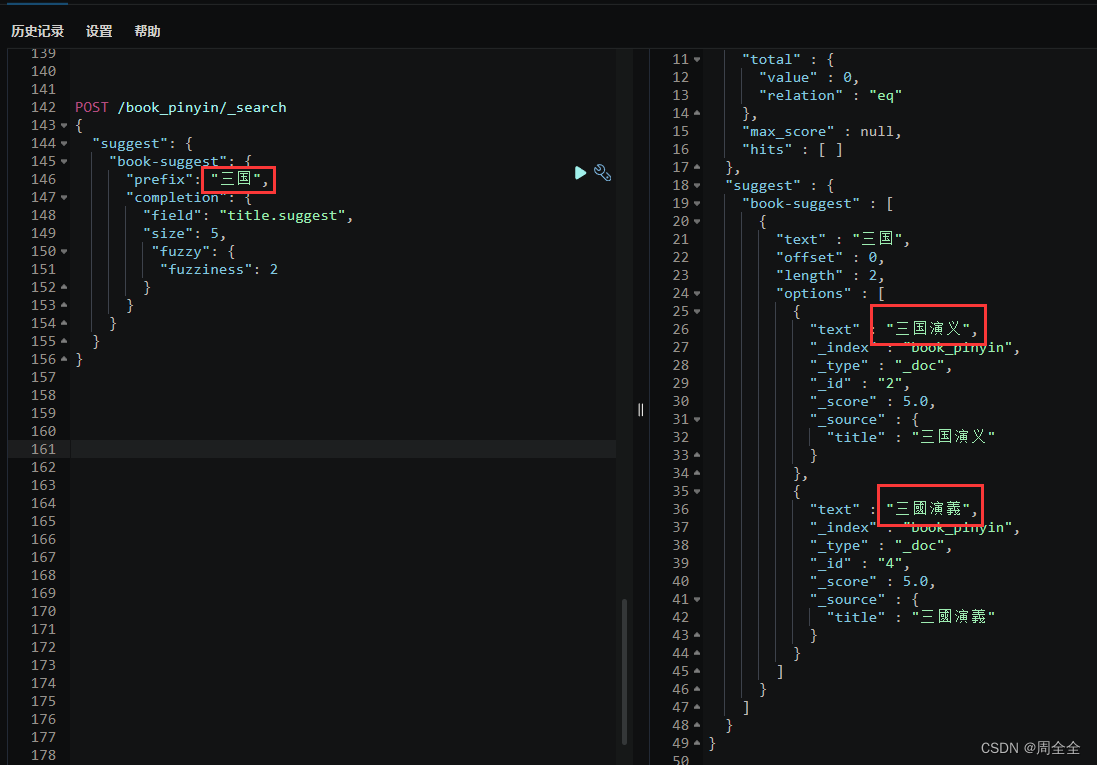
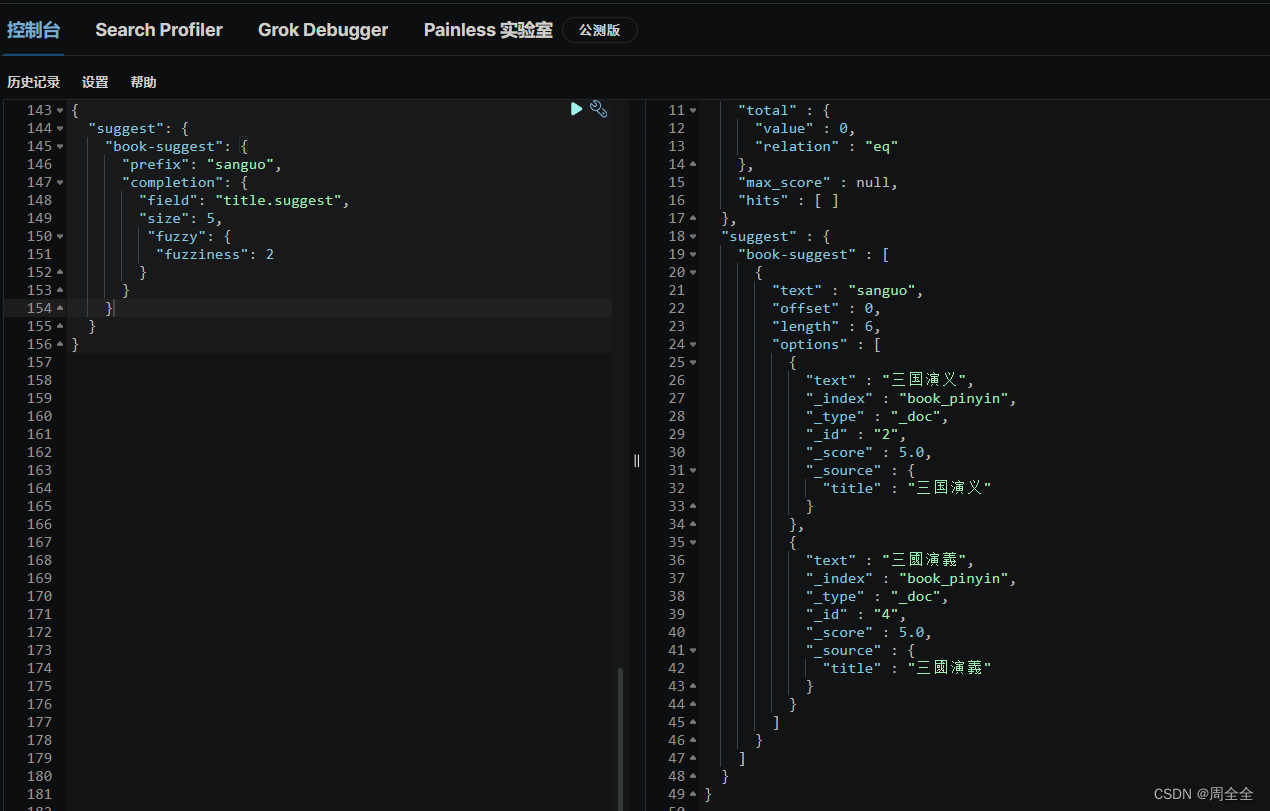
查询结果如下: 使用 “fuzzy” 参数来实现模糊匹配,即允许在查询中包含一定数量的拼写错误。可以根据需要调整 “fuzziness” 的值,以容忍更多或更少的拼写错误 POST /book/_search { "suggest": { "book-suggest": { "prefix": "三国眼", "completion": { "field": "title.suggest", "size": 5, "fuzzy": { "fuzziness": 2 } } } } } 查询结果
拼音分词器(pinyin analyzer)通常需要自行引入,因为它不是 Elasticsearch 的默认分词器。可以使用 Elasticsearch 的插件来引入 pinyin 分词器,以便在索引中使用它。 安装 elasticsearch-analysis-pinyin 插件选择与自己版本一致的版本,插件地址: https://github.com/medcl/elasticsearch-analysis-pinyin/releases
然后在es的安装目录下plugins目录下新建pinyin目录,并将解压后的文件复制到该目录下
我们这里实现了拼音转换后已经实现了繁简转换
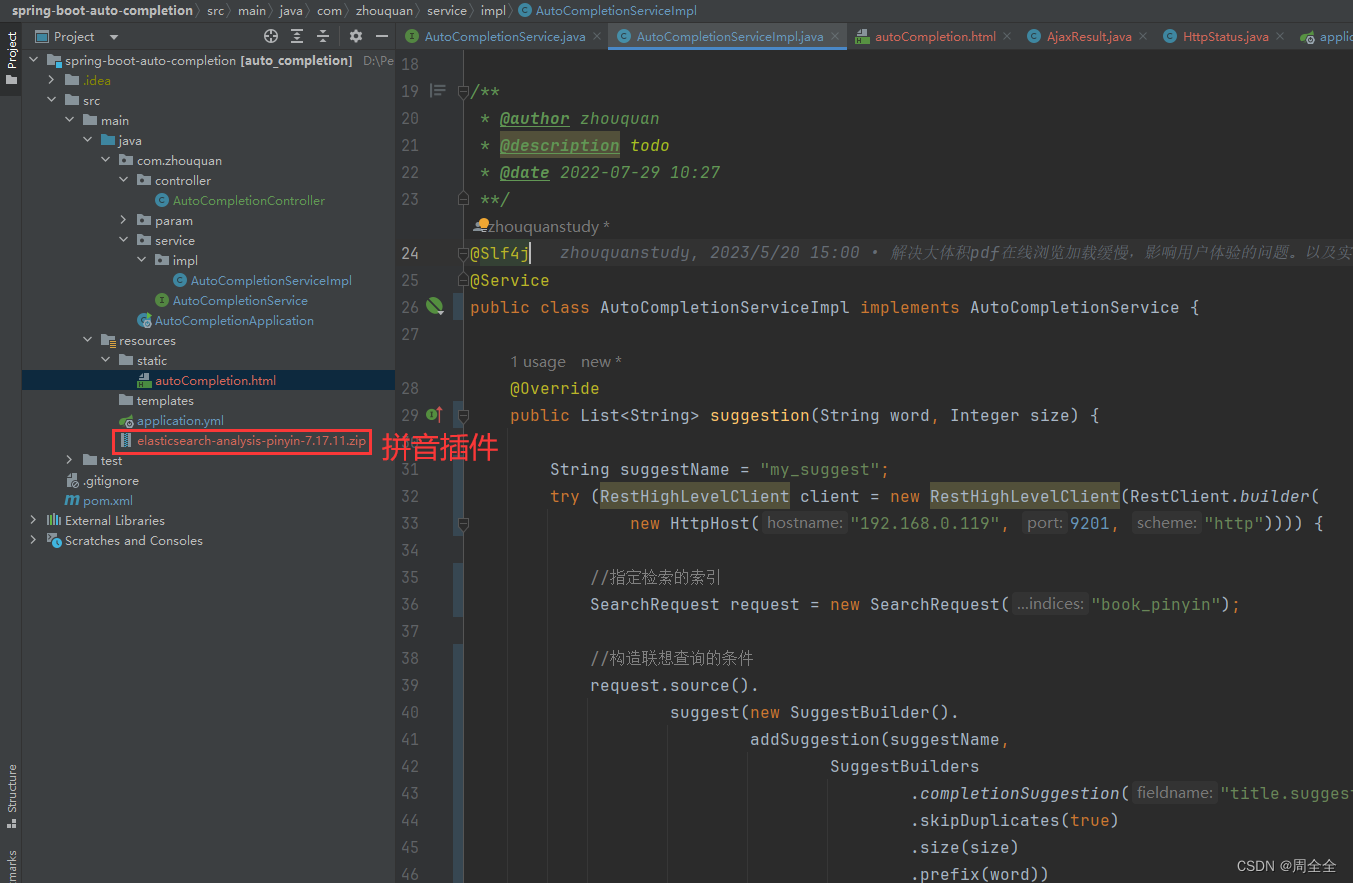
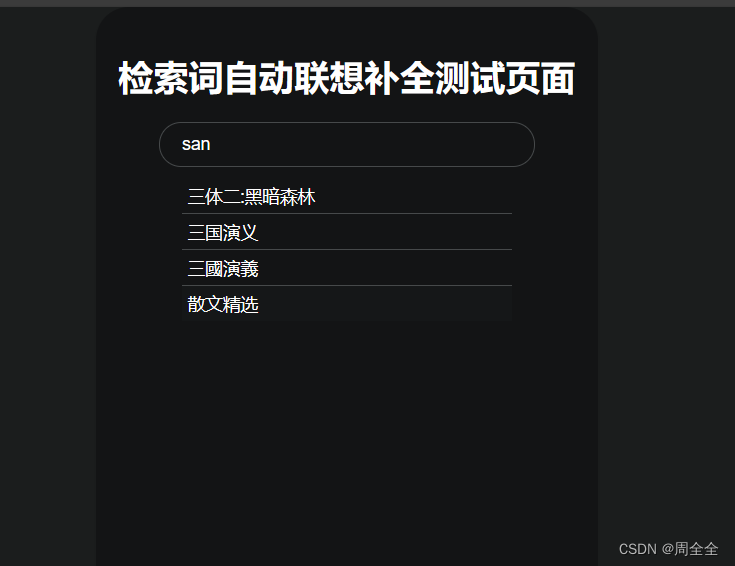
简单创建一个springboot项目,使用html实现了一个简单的demo 实现效果如下: Completion Suggester 是 Elasticsearch 提供的自动补全和搜索即时提示的功能。这是一种导航功能,可引导用户在键入时找到相关结果,从而提高搜索准确性。请注意,它不适用于拼写校正或类似 term 或 phrase suggesters 的“您是不是要这样说”功能。 理想情况下,自动补全功能应该与用户输入同步,以提供与用户已经键入的内容相关的即时反馈。因此,Completion Suggester 针对速度进行了优化。该建议器使用数据结构来实现快速查找,但构建和存储这些数据结构是昂贵的,并且存储在内存中。 映射(Mapping)要使用此功能,需要为字段指定一个特殊的映射,以便为快速补全建议索引字段值。 PUT music { "mappings": { "properties": { "suggest": { "type": "completion" }, "title": { "type": "keyword" } } } }映射支持以下参数: analyzer:用于索引的分析器,默认为 simple。search_analyzer:用于搜索的分析器,默认为与 “analyzer” 相同。preserve_separators:保留分隔符,默认为 true。如果禁用,您可能会找到以 “Foo Fighters” 开头的字段,如果建议输入为 “foof”。preserve_position_increments:启用位置增量,默认为 true。如果禁用并使用停用词分析器,建议输入 “b” 时,您可能会得到以 “The Beatles” 开头的字段。请注意:如果能够丰富数据,也可以通过索引两个输入 “Beatles” 和 “The Beatles” 来实现,无需更改简单分析器。max_input_length:限制单个输入的长度,默认为 50 个 UTF-16 代码点。此限制仅在索引时使用,以减少每个输入字符串的字符总数,以防止底层数据结构膨胀。在大多数情况下,默认值不会对使用产生影响,因为前缀建议很少会增长到比一小撮字符长的前缀。 索引(Indexing)索引建议与索引其他字段的数据相似。建议由输入和可选的权重属性组成。输入是建议查询中预期匹配的文本,而权重确定建议的评分。索引建议的示例如下: PUT music/_doc/1?refresh { "suggest" : { "input": [ "Nevermind", "Nirvana" ], "weight" : 34 } }支持以下参数: input:要存储的输入,可以是字符串数组或仅为字符串。此字段是必需的。该值不能包含以下 UTF-16 控制字符:\u0000(null)、\u001f(信息分隔符一)、\u001e(信息分隔符二)。weight:正整数或包含正整数的字符串,用于定义权重,可用于排列建议。此字段是可选的。您还可以使用以下简化形式,但请注意,在简化形式中不能为建议指定权重。 PUT music/_doc/1?refresh { "suggest" : [ "Nevermind", "Nirvana" ] } 查询(Querying)建议查询与通常查询相似,不同之处在于您必须将建议类型指定为 “completion”。建议是近实时的,这意味着通过 “refresh” 可以立即显示新建议,已删除的文档永远不会被显示。 下面是一个查询的示例: POST music/_search?pretty { "suggest": { "song-suggest": { "prefix": "nir", "completion": { "field": "suggest" } } } }在查询结果中,Elasticsearch 将返回与用户输入前缀匹配的建议。您可以使用这些建议为用户提供搜索建议。 自动补全建议还支持模糊查询和正则表达式查询,以处理用户输入中的拼写错误或其他变化。这些查询可以通过 "fuzzy" 和 "regex" 参数进行配置。 请注意,默认情况下,“_source” 元数据字段是启用的,以便返回建议的源数据。建议的权重通过 “_score” 返回。默认情况下,建议返回完整文档的 “_source”。如果 _source 大小会影响性能,可以使用源过滤来减小 _source 大小。 以上是使用 Completion Suggester 的基本概述。根据需求,您可以进一步配置和定制自动补全建议。 Completion Suggester 可以考虑索引中的所有文档。对于如何查询文档子集的详细信息,请查看上下文建议(Context Suggester)。 如果一个建议查询跨越多个分片,建议会在两个阶段执行,最后一个阶段从分片中获取相关文档,这意味着当建议跨多个分片时,在单个分片上执行建议请求会更有效,因为建议涵盖多个分片时需要执行文档提取开销。为了获得最佳的自动补全性能,建议将自动补全索引到单个分片索引中。如果由于分片大小而导致堆内存使用过高,仍建议将索引分成多个分片,而不是为了优化自动补全性能。 跳过重复建议查询可能会返回来自不同文档的重复建议。通过将 "skip_duplicates" 设置为 true,可以修改此行为。设置为 true 时,此选项会减慢搜索,因为需要访问更多的建议以查找前 N 个。 模糊查询(自动纠错)Completion Suggester 还支持模糊查询,这意味着您可以在搜索中出现拼写错误,仍然可以获得结果。 例如,以下是一个使用模糊查询的查询示例: POST music/_search?pretty { "suggest": { "song-suggest": { "prefix": "nor", "completion": { "field": "suggest", "fuzzy": { "fuzziness": 2 } } } } }模糊查询会根据查询前缀与建议前缀的最长匹配来对建议进行评分。模糊查询支持各种参数,如 “fuzziness”、“transpositions”、“min_length”、“prefix_length” 和 “unicode_aware”,可以用于调整匹配的宽松程度和性能。 正则表达式查询Completion Suggester 还支持正则表达式查询,这意味着您可以使用正则表达式来表示前缀。 例如,以下是一个使用正则表达式查询的示例: POST music/_search?pretty { "suggest": { "song-suggest": { "regex": "n[ever|i]r", "completion": { "field": "suggest" } } } }正则表达式查询可以包含各种参数,如 “flags” 和 “max_determinized_states”,以用于调整匹配的方式和性能。 |
 增加测试数据
增加测试数据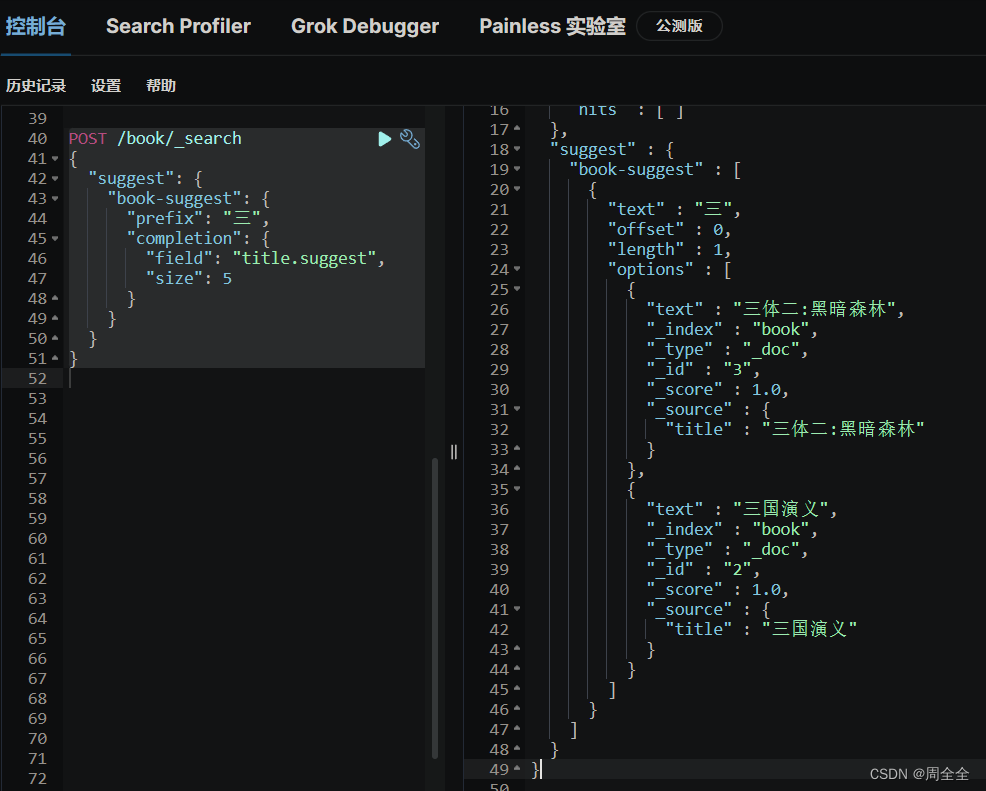
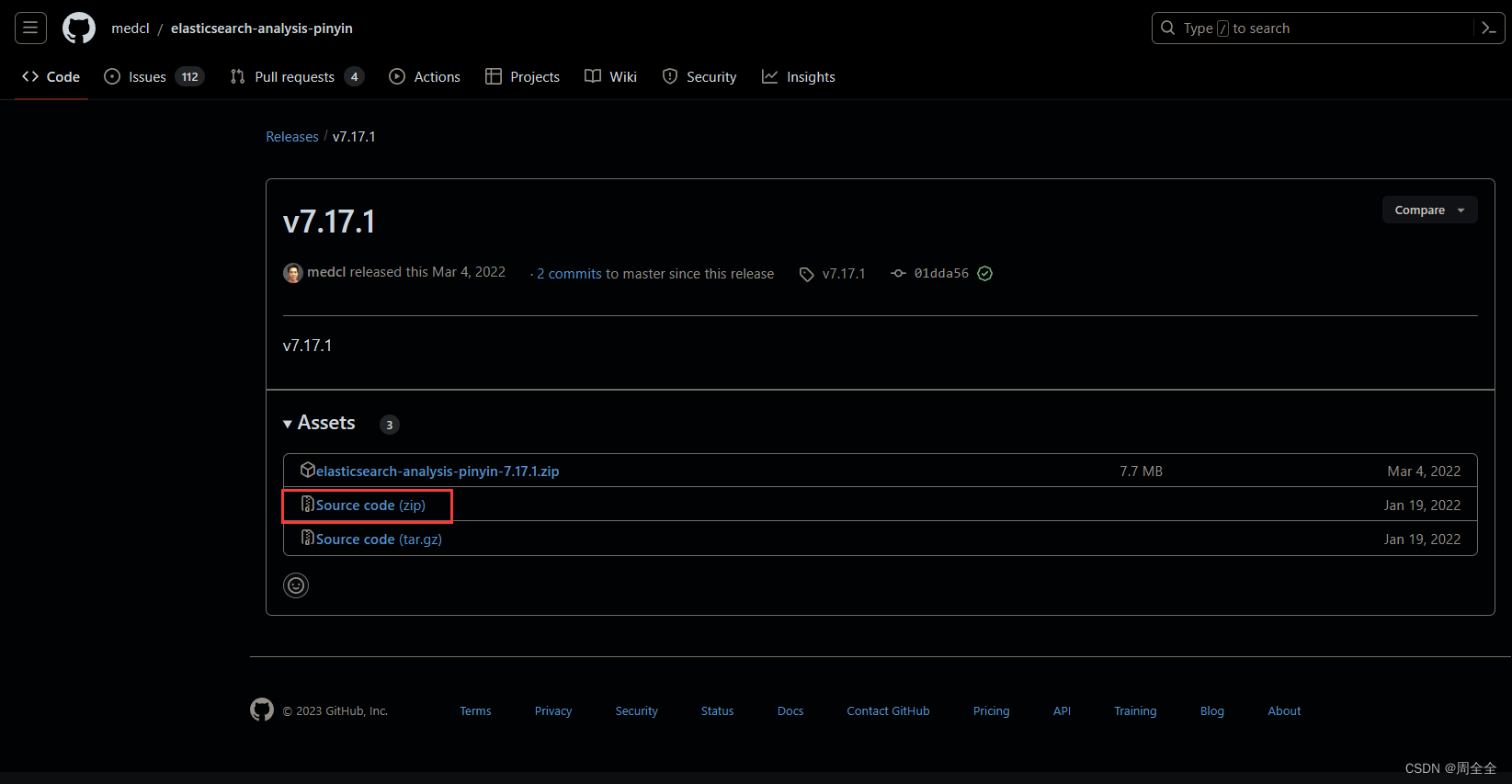 elasticsearch-analysis-pinyin分词器目前没有下载即可使用的安装包,需要自己下载源码进行编译。可以在项目目录elasticsearch-analysis-pinyin\target\releases看到编译后的结果elasticsearch-analysis-pinyin-7.17.11.zip
elasticsearch-analysis-pinyin分词器目前没有下载即可使用的安装包,需要自己下载源码进行编译。可以在项目目录elasticsearch-analysis-pinyin\target\releases看到编译后的结果elasticsearch-analysis-pinyin-7.17.11.zip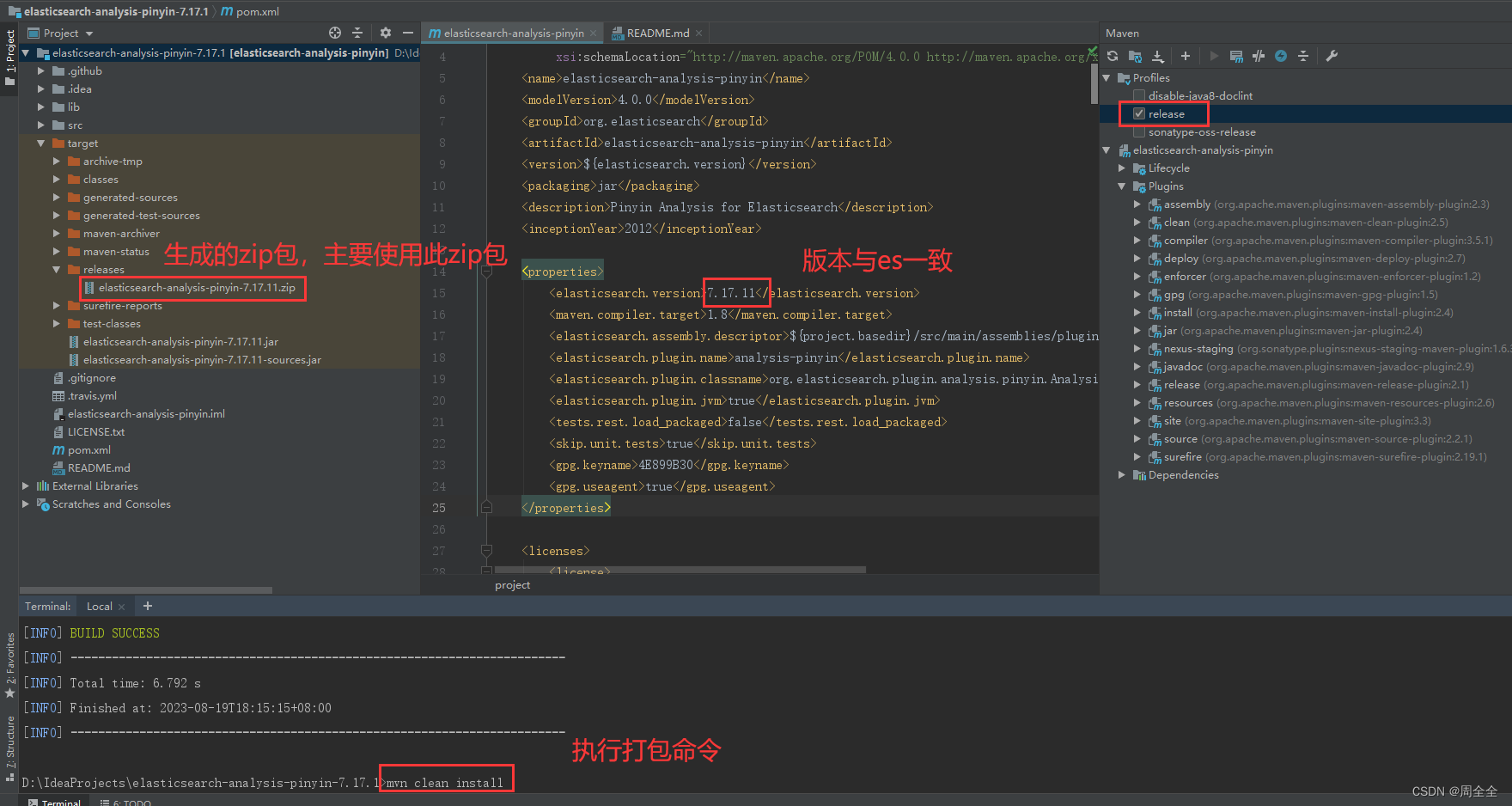
 重启es,启动日志中已经加载了拼音插件
重启es,启动日志中已经加载了拼音插件 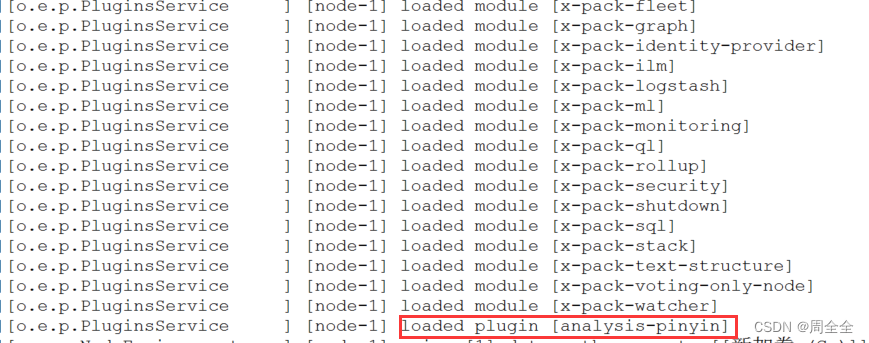
【本文地址】
今日新闻 |
推荐新闻 |