统计学入门 |
您所在的位置:网站首页 › 最小样本数量表 › 统计学入门 |
统计学入门
|
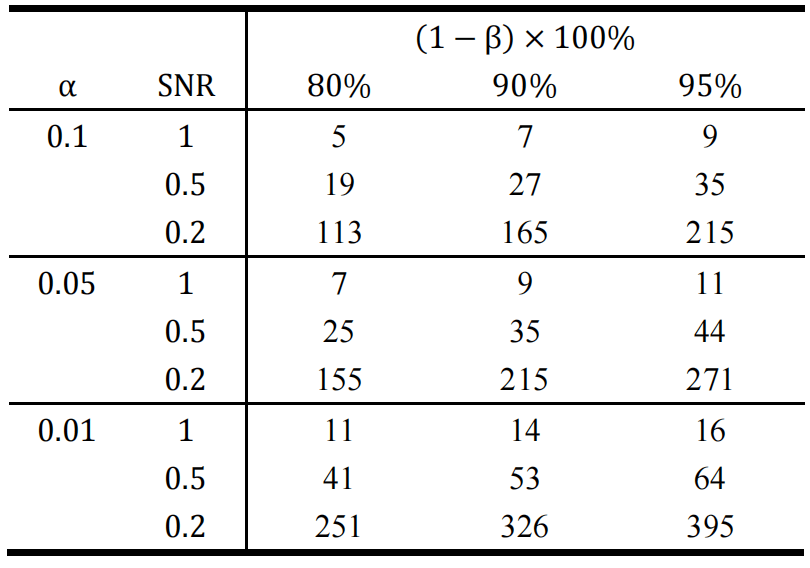
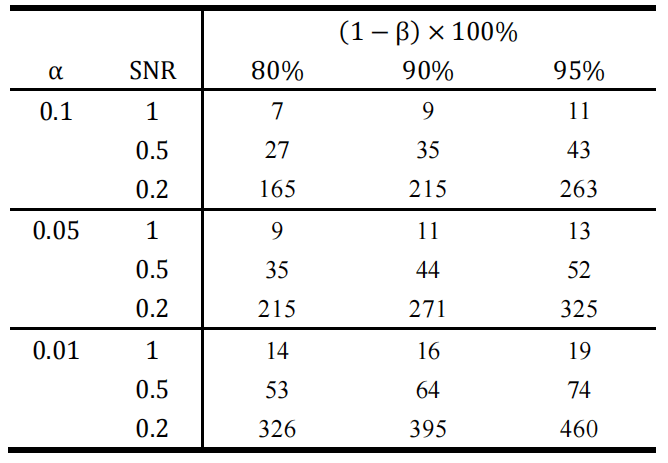
其中 为满足要求(即同时控制两类错误)的最小样本量,由于上述计算式的结果可能为非整数,因此在实际应用中通常使用不小于 的最小整数来作为最小样本量。基于上述最小样本量 的计算公式,可以定义信号强度(Signal to Noise Ratio,SNR)为: 。因此,最小样本量 仅与参数SNR、α和β有关。一些典型的样本量计算结果如下: 表3.7.1 单边均值假设检验中典型样本量计算结果
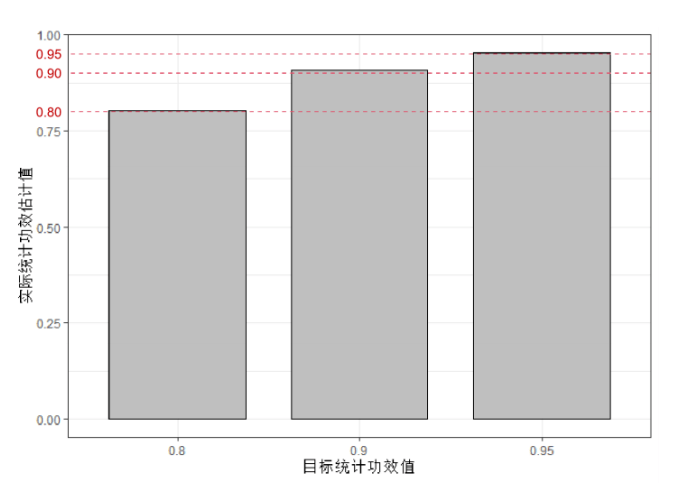
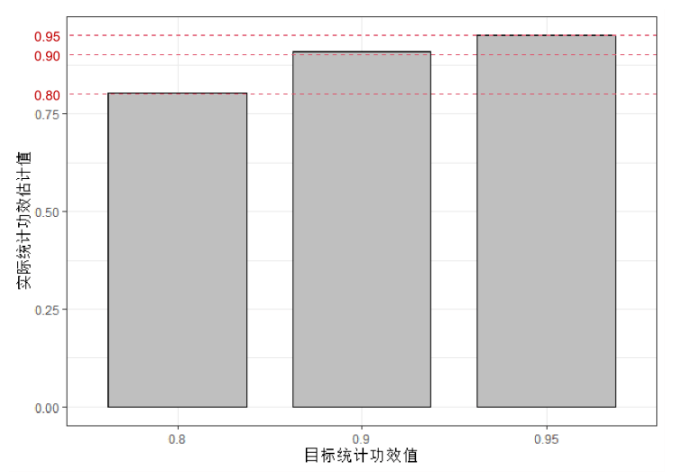
从表3.7.1可见,随着信号强度SNR的下降,人们所需要的样本量呈现上升的趋势。除此之外还值得一提的是:上述样本量的计算过程中用到了大量的近似公式。近似的效果如何?近似后样本量的计算结果还能否达到统计功效 的要求?这个问题可以通过随机模拟实验来进行验证。假设总体真实的均值为 ,方差 ,需要比较的原假设是 : ,因此SNR=0.5。假设显著性水平 。当统计功效的要求 分别为0.8,0.9和0.95时,按照上述典型样本量计算结果表可知,所需的最小样本量 分别为25,35和44。接着对于不同最小样本量 ,随机抽取 个服从正态分布的随机数(均值 ,方差 )。然后执行相应的假设检验,记录检验结果。将该实验重复10000次,由此得到10000个检验结果。由于抽取的正态分布随机数总体均值 ,因此实际上对立假设H1正确,因此在10000个检验结果中原假设被正确拒绝的比例就是对统计功效的一个合理估计。将该估计的结果绘制于图3.7.1的柱状图中:
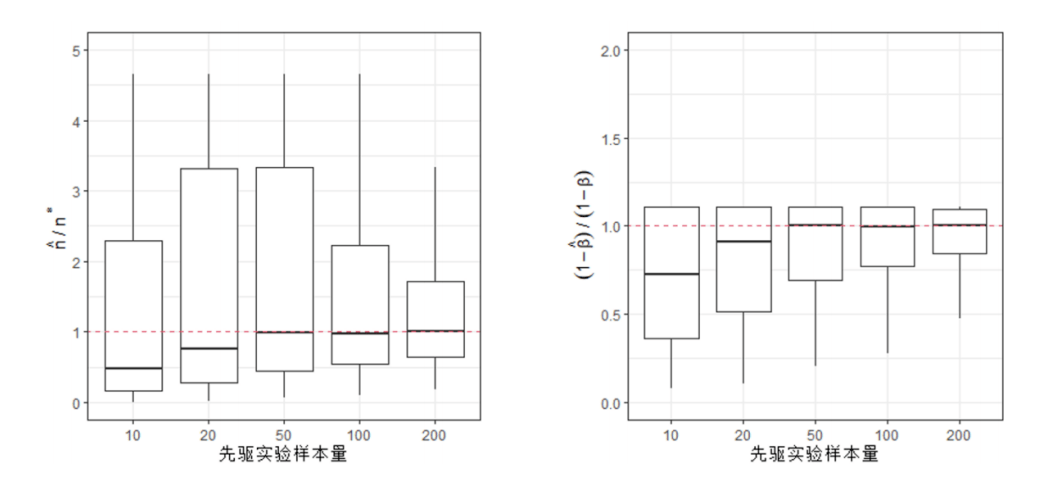
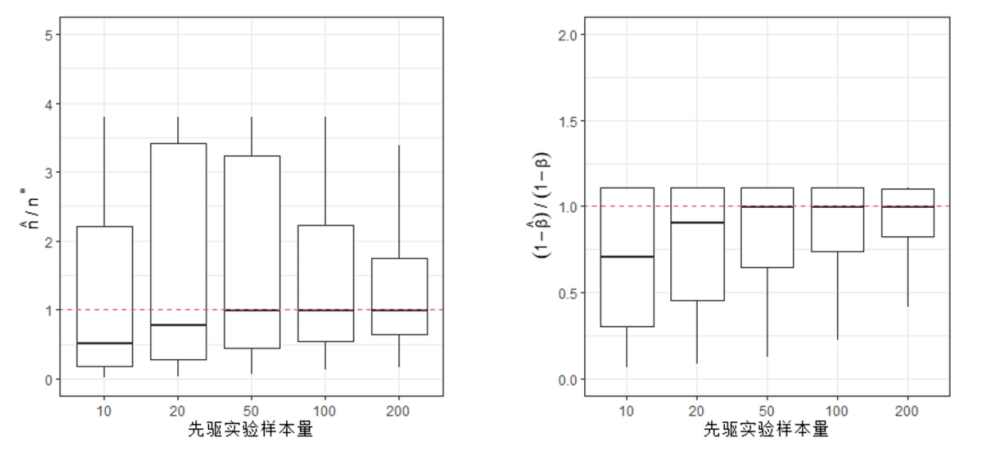
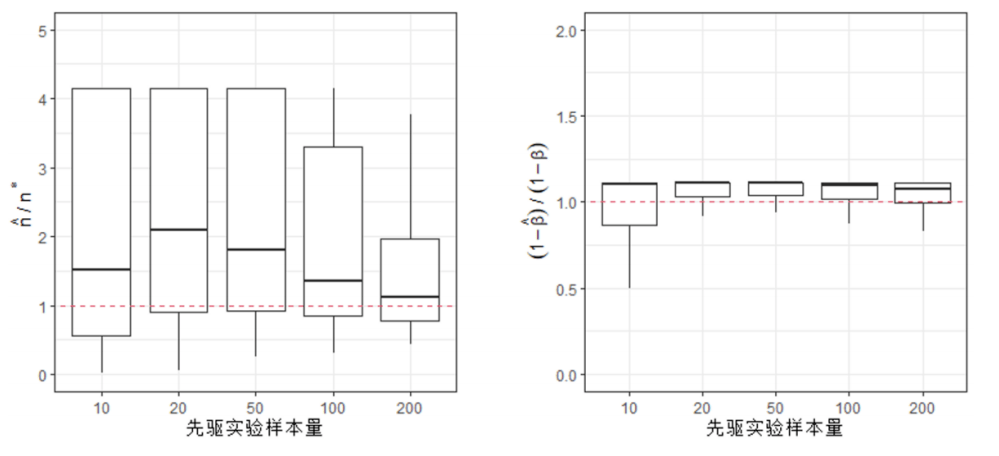
图3.7.1 随机模拟的统计功效值柱状图(单边假设) 从图中可以看出,在不同目标功效水平下(0.8,0.9,0.95),实际功效与目标功效之间的差距是很小的。这表明,虽然样本量计算公式的推导过程中用到了很多近似关系,但通过近似的样本量计算结果仍能基本满足统计功效的要求。 除此之外,由最小样本量 的计算式可以发现,最小样本量不仅和第一类、第二类错误概率有关,还和实际总体的均值 、标准差 有关。那么请问:在进行临床实验之前又如何对总体的均值和方差进行估计呢?答案和2.6节相同。人们可以根据先验知识(例如前人研究结果)进行主观判断,但一种更精确的办法是执行一个规模较小的先驱实验(例如前两期临床实验)。在2.6节置信区间的样本量计算中,关于先驱实验我们已经有这样的结论:先驱实验的样本量越大,正式样本量的估算结果就更加准确。这一结论在单边均值假设检验的样本量计算中仍然适用吗?为此可以借助一个随机模拟实验来验证。首先假设总体的真实均值为 ,真实方差 。原假设 : 。假设显著性水平 ,目标功效 。此时可以计算得: 因此在正式实验中所需要的最小样本量为215。接着设置一个先驱实验样本量为 ,对于 尝试五个不同的取值:10, 20, 50, 100以及200。对于每一个先驱实验样本量 ,随机生成 个正态分布样本(均值 ,方差 )。根据抽样样本估计总体的均值 和方差 ,然后带入公式 中计算得到样本量估计值 。接着再取 个随机生成的正态分布样本(均值 ,方差 ),然后模仿前面的过程,用随机模拟的方法计算实际统计功效 。对于每一个先驱实验样本量 ,将上述过程重复10000次,由此形成10000个 和 的对比结果,并将随机模拟实验的结果绘制于图3.7.2中。
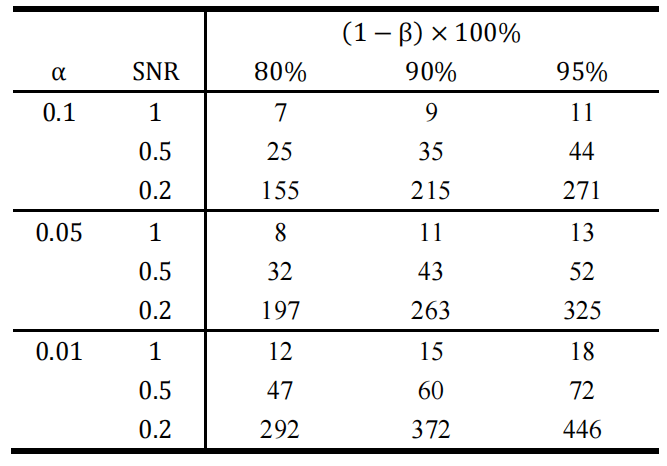
图3.7.2 先驱实验样本量 与 (左图)和 (右图)的箱线图(单边假设) 在图3.7.2中,左图绘制的是先驱实验样本量 和 的箱线图,右图绘制的是先驱实验样本量 和 的箱线图。图中红色虚线代表的是 和 。 高于该虚线表示估计样本量 大于目标样本量 ,即高估了所需的最小样本量。 高于该虚线表示实际统计功效 大于目标功效 。图3.7.2的结果表明:随着先驱实验样本量 的增加, 和 的中位值都越来越接近1。这意味着先驱实验样本量越大,样本量的估算结果就会越准确;但是在先驱样本不够的情况下,都倾向于低估样本量,并造成实际的统计功效偏低。 双边假设检验 除了单边假设检验问题外,有时也需要解决均值的双边假设检验问题。假设总体均值为参数 ,需要判断均值参数 和 是否有显著差异。那么假设检验问题可以设置为 : : 。和均值的单边假设问题类似,该双边假设检验问题的决策规则是:当 时,接受原假设 : ;反之当 时,接受对立假设 : 。由于样本量的取值需要使得第二类错误发生的概率得到控制,因此首先需要计算第二类错误发生概率的表达式。在备择假设 成立的条件下,第二类错误发生概率的计算过程如下: 同样请注意,虽然 近似服从标准正态分布,但是上式中由于接受了 的假设,因此 不再近似服从标准正态分布。故上式可继续化简为: 其中 表示标准正态分布函数。和单边假设的情形不同,上式中出现了两个标准正态分布函数,这给后续推导样本量造成不便,因此这里需要做进一步的简化。可以注意到上式中 和 互为相反数,这就意味着在 的假设下,二者一定有一个小于0。那么这会造成怎样的影响呢?不妨设小于0的是 ,即 ,那么可以得到: (注意到 同时为负数)。故第二类错误概率可以进一步简化为: 为了确定合适的样本量,首先需要确定能被接受的最大第二类错误概率,从而对其进行控制。假设最大可被接受的第二类错误概率为 ,那么可找到一个最小的样本量,使得第二类错误概率小于等于 ,计算过程如下: 其中即为所需的最小样本量,由于上述计算式的结果可能为非整数,因此在实际应用中通常使用不小于的最小整数来作为最小样本量。对比单边假设检验情形下的最小样本量表达式可以进一步发现:当面对的数据、参数和,以及均相同时,为保证两类错误都得到控制,考虑双边假设检验要比考虑单边假设检验需要更多的样本量。同样定义信号强度为,那么最小样本量仅与参数SNR、和有关。一些典型的样本量计算结果如下: 表3.7.2 双边均值假设检验中典型样本量计算结果
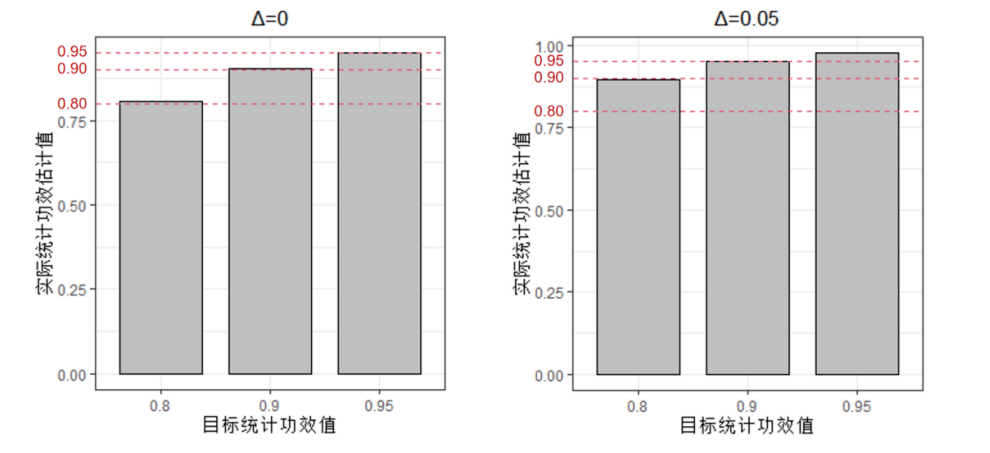
从表3.7.2中可见,随着信号强度SNR的下降,人们所需要的样本量呈现上升的趋势。除此之外,和单边假设检验的情况类似,上述样本量的计算过程中同样用到了大量的近似公式。近似的效果如何?近似后样本量的计算结果是否仍能达到统计功效 的要求?这个问题可以通过随机模拟实验来进行验证。假设总体的真实均值为 ,真实方差 ,需要比较的原假设是 : ,因此SNR=0.5。假设显著性水平参数 。当统计功效的要求 分别为0.8,0.9和0.95时,按照上述典型样本量计算结果表,所需的最小样本量 分别为32,43和52。接着对于不同最小样本量 ,随机抽取 个服从正态分布的随机数(均值 ,方差 )。然后执行相应的假设检验并记录检验结果。将该实验重复10000次,由此得到10000个检验结果。由于抽取的正态随机数总体均值 ,对立假设H1正确,因此10000个检验结果中原假设被正确拒绝的比例就是对统计功效的一个合理估计。将该估计结果绘制于图3.7.3的柱状图中:
图3.7.3 随机模拟的统计功效值柱状图(双边假设) 从图中可以看出,在不同目标功效水平下(0.8,0.9,0.95),实际功效与目标功效之间的差距是很小的。这表明虽然样本量计算式推导过程中用到了很多近似关系,但通过近似计算得到的样本量结果仍能基本满足统计功效的要求。 除此之外,和单边假设的情形相同,最小样本量 表达式中的总体均值以及总体标准差也可以通过执行一个小规模的先驱实验来进行估计。在单边均值假设检验问题的样本量计算中,关于先驱实验有这样的结论:先驱实验样本量越大,正式样本量的估算结果就越准确。这一结论在双边均值假设检验的样本量计算中仍然适用吗?为此同样可以借助一个随机模拟实验来验证。首先假设总体的真实均值为 ,真实方差 。需要比较的原假设是 : 。假设显著性水平 ,目标功效为 。此时可以计算得: 因此在正式实验中所需要的最小样本量为263。接着设置一个先驱实验样本量 ,对于 尝试五个不同的取值:10, 20, 50, 100以及200。对于每一个先驱实验样本量 ,随机生成 个正态分布样本(均值 ,方差 )。根据抽样样本估计总体的均值 和方差 ,然后带入公式 中计算得到样本量估计值 。接着再抽取 个随机生成的正态分布样本(均值 ,方差 ),然后模仿前面的过程,用随机模拟的方法计算实际统计功效 。对于每一个先驱实验样本量 ,将上述过程重复10000次,由此形成10000个 和 的计算值,并将随机模拟实验的结果绘制于图3.7.4中。
图3.7.4 先驱实验样本量 与 (左图)和 (右图)的箱线图(双边假设) 其中,左图绘制的是先驱实验样本量 和 的箱线图,而右图绘制的是先驱实验样本量 和 的箱线图。图中红色虚线代表的是 和 。 高于该虚线表示估计样本量 大于实际样本量 ,即高估了所需的最小样本量。 高于该虚线表示实际功效 大于目标功效 。图中的结果和单边假设情形下的结果一致,即随着先驱实验样本量 的增加, 和 的中位数值都越来越接近1。这意味着先驱实验样本量越大,样本量的估算结果会越来越准确。但是在先驱样本不够的情况下,都倾向于低估样本量,并造成实际功效偏低。 双单边假设检验 在3.5节的最后介绍了一个有趣而重要的案例:仿制药上市,并因此引出了双单边检验,这里再简单复习一下。当一款已上市的原创药专利失效时,医药公司可以申请研发该原创药的仿制药,以作为该原创药的替代品。当然两种药品的治疗效果不可能完全相同,因此在实际的仿制药审批过程中,通常需要验证两种药品的治疗效果的差异是否在可接受范围内,而这一验证过程就叫做生物等效性试验。自1984年起,美国FDA被授权通过生物利用度和等效性研究来审批仿制药。而根据我国药监局发布的《化学药生物等效性试验备案范围和程序》文件,在我国仿制已上市的原研化学药品,也都需要进行生物等效性试验备案。因此不论是在中国还是美国,生物等效性试验都是仿制药审批上市的重要环节。在试验设计方面,生物等效性研究通常采用交叉设计(Crossover Design)的方法。这种试验设计方法的特点在于:受试者将会先后接受多种干预措施。从而使得不同干预措施的结果可以基于同一个体,从而减小个体差异等因素对试验结果的影响。在收集了关于两类药品的试验数据之后,生物等效性试验最终可以转化为一个双单边假设检验问题。不妨假设这两类药品的样本量相等都为 ,第 个受试者使用仿制药后试验指标的测量值为 ,使用品牌药后试验指标的测量值为 , 。记两种药物试验指标测量值之差为 ,那么有 ,以 表示这两类药品治疗效果总体差异的均值,以 表示最大可接受差异。对应的假设检验问题为: : ,而对立假设为 : 。很遗憾的是,这样一个假设检验问题并不好处理,于是人们将其转化为两个单边假设检验问题如下: 当且仅当上述两个假设检验问题的原假设均被否定时,才能说明这两种药品治疗效果的差异在可接受范围内。具体而言,当样本数据同时满足 和 时,可以认为两种药品治疗效果差异可接受。在这类双单边均值假设检验问题中,样本量又该如何确定呢?和前面类似,为了求解使两类错误都得到控制时的最小样本量,也需要首先计算第二类错误发生概率的表达式。在备择假设 的条件下,第二类错误发生概率的一个近似计算过程如下: 其中 表示标准正态分布函数。和双边均值假设检验问题的情形类似,上式出现了两个标准正态分布函数,这将给后续推导样本量造成不便,因此这里需要做进一步的简化。考虑到 ,因此第二类错误概率可以通过这一关系式简化为如下的形式: 诚然在上述过程中,第二类错误概率被高估了,真实的第二类错误概率将小于上述近似值。但由于第二类错误概率本就是需要被尽量降低的,因此这种高估是可以接受的(虽然并不完美)。为了确定合适的样本量,首先需要确定能被接受的最大第二类错误概率,从而对其进行控制。假设最大可被接受第二类错误概率为 ,那么可找到一个最小的样本量,使得第二类错误概率小于等于 ,计算过程如下: 其中 即为所需的最小样本量,由于上述计算式的结果可能为非整数,因此在实际应用中通常使用不小于 的最小整数来作为最小样本量。基于上述最小样本量 的计算公式,可以定义信号强度(Signal to Noise Ratio,SNR)为 ,那么最小样本量 仅与SNR、 和 有关。一些典型的样本量计算结果如下: 表3.7.3 双单边假设检验中典型样本量计算结果
从表3.7.3中可见,随着信号强度SNR的下降,人们所需要的样本量呈现上升的趋势。除此之外,和单边假设检验以及双边假设检验的情况类似,上述样本量的计算过程中同样用到了大量的近似公式。近似的效果如何?近似后样本量的计算结果还能否达到统计功效 的要求?这个问题同样可以通过随机模拟实验来进行验证。假设两类药品治疗效果差异总体的真实均值 ,真实方差 。而根据我国药监局发布的《生物等效性研究的统计学指导原则》文件,最大可接受药效差异通常设置为 。假设显著性水平 。当统计功效的要求 分别为0.8,0.9和0.95时,按照上述样本量计算公式,所需的最小样本量 分别为172,218和261。接着对于不同最小样本量 ,随机抽取 个服从正态分布的随机数(均值 ,方差 )。然后执行相应的假设检验,记录检验结果。将该实验重复10000次,由此得到10000个检验结果。由于抽取的正态随机数总体均值 ,对立假设 和 正确,因此10000个检验结果中原假设被正确拒绝的比例就是对统计功效的一个合理估计。将该估计结果绘制于图3.6.5的左图中。除此之外,修改两类药品治疗效果差异总体的均值为 ,方差 ,最大可接受药效差异 ,参数 ,重复上述操作并将结果绘制于图3.7.5的右图中:
图3.7.5 (左图)和 (右图)时随机模拟的统计功效值柱状图(双单边假设) 从左图中可以看出,当 时,在不同目标功效水平下(0.8,0.9,0.95),实际功效与目标功效之间的差距很小。而右图的结果表明,当 时,在不同目标功效水平下,近似的样本量计算结果达到的实际统计功效明显超过目标功效,这是因为在最小样本量计算的推导过程中用到了不等式 。当 时,上述不等式中等号成立,不会影响最小样本量计算式的近似效果。而当 时,上述不等式中等号不成立,第二类错误发生的概率明显被高估。但值得注意的是,此时的样本量计算结果仍然满足统计功效的基本要求,只是有点浪费样本,所以并不是最优。 除此之外,和单边假设以及双边假设的情形相同,最小样本量 表达式中的总体均值以及总体标准差也可以通过执行一个小规模的先驱实验来进行估计。在单边和双边均值假设检验问题的样本量计算中,关于先驱实验有这样的结论:先驱实验样本量越大,正式样本量的估算结果也会越准确。下面,我们通过一个随机模拟实验来验证这一结论在双单边均值假设检验的样本量计算中是否仍然适用。首先假设两类药品治疗效果差异总体的真实均值 ,真实方差 ,最大可接受药效差异 。假设显著性水平 ,目标功效为 。此时可以计算得: 因此在正式实验中所需要的最小样本量为362。接着设置一个先驱实验,样本量为 ,对于 尝试五个不同的取值:10, 20, 50, 100以及200。对于每一个先驱实验样本量 ,随机生成 个正态分布样本( ,方差 )。根据抽样样本估计总体的均值 和方差 ,然后带入公式 中计算得到样本量估计值 。接着再取 个随机生成的正态分布样本(均值 ,方差 ),然后模仿前面的过程,用随机模拟的方法计算实际统计功效 。对于每一个先驱实验样本量 ,将上述过程重复10000次,由此形成10000个 和 的计算值,并将随机模拟实验的结果绘制于图3.7.6中。
图3.7.6 先驱实验样本量 与 (左图)和 (右图)的箱线图(双单边检验) 其中,左图绘制的是先驱实验样本量 和 的箱线图,而右图绘制的是先驱实验样本量 和 的箱线图。图中红色虚线代表的是 和 。左图的结果表明随着先驱实验样本量 的增加, 的中位数值都越来越接近1。这表明,先驱实验样本量越大,正式实验样本量的估算结果会越来越准确。而右图结果表明,实际功效往往要高于目标功效。 本节首先推导了单边假设、双边假设和双单边假设检验问题中,同时控制两类错误时的最小样本量计算公式。然后针对计算公式推导中使用的近似公式可能造成的影响,通过随机模拟实验验证了:样本量的计算结果仍能基本满足统计功效的要求。最后讨论了先驱实验样本量对最终估计结果的影响。至此,我们对假设检验的讨论就告一段落了,下一章我们将开启一个重要的新内容:回归分析。什么是回归分析?回归分析是统计学中最重要的一套方法论,用于研究一个或者多个指标与一个感兴趣的因变量之间相关关系的方法论,有着极为广泛的应用场景,敬请期待。 内容索引 引言:从不确定性出发 第1章:不确定性的数学表达:连续型数据 第1章:不确定性的数学表达:正态概率密度 第1章:不确定性的数学表达:t-分布 第1章:不确定性的数学表达:指数分布 第1章:不确定性的数学表达:0-1分布 第1章:不确定性的数学表达:泊松分布 第2章:参数估计:矩估计 第2章:参数估计:极大似然估计 第2章:参数估计:正态分布均值的区间估计 第2章:参数估计:正态分布方差的区间估计 第2章:参数估计:其他分布参数的区间估计 第2章:参数估计:样本量的计算 第3章:假设检验:不确定性与决策 第3章:假设检验:两种不同类型的错误 第3章:假设检验:为什么推翻原假设 第3章:假设检验:关于均值的假设检验问题 第3章:假设检验:假设检验的各种推广 第3章:假设检验:假设检验中的p.Value 返回搜狐,查看更多 |
【本文地址】
今日新闻 |
推荐新闻 |